Cómo acelerar el flujo de datos entre Databricks y SAS
por Oleg Mikhov y Satish Garla
Esta es una publicación colaborativa entre Databricks y T1A. Agradecemos a Oleg Mikhov, Arquitecto de Soluciones en T1A, por sus contribuciones.
Esta es la primera publicación de una serie de blogs sobre las mejores prácticas para unir la Plataforma Databricks Lakehouse y SAS. Una publicación anterior de Databricks blog post presentó Databricks y PySpark a los desarrolladores de SAS. En esta publicación, analizamos formas de intercambiar datos entre SAS y la Plataforma Databricks Lakehouse, y formas de acelerar el flujo de datos. En futuras publicaciones, exploraremos la creación de pipelines de datos y análisis eficientes que involucren ambas tecnologías.
Las organizaciones impulsadas por datos están adoptando rápidamente la plataforma Lakehouse para mantenerse al día con las crecientes demandas comerciales. La plataforma Lakehouse se ha convertido en la nueva norma para las organizaciones que desean construir plataformas y arquitecturas de datos. La modernización implica mover datos, aplicaciones u otros elementos comerciales a la nube. Sin embargo, la transición a la nube es un proceso gradual y es fundamental para el negocio seguir aprovechando las inversiones heredadas durante el mayor tiempo posible. Con esto en mente, muchas empresas tienden a tener múltiples plataformas de datos y análisis, donde las plataformas coexisten y se complementan entre sí.
Una de las combinaciones que vemos es el uso de SAS con Databricks Lakehouse. Existen muchos beneficios al permitir que las dos plataformas trabajen juntas de manera eficiente, tales como:
- Capacidades de almacenamiento de datos mayores y escalables de las plataformas en la nube
- Mayor capacidad de cómputo utilizando tecnologías, como Apache Spark™, creadas de forma nativa con capacidades de procesamiento paralelo
- Lograr un mayor cumplimiento normativo con la gobernanza y gestión de datos utilizando Delta Lake
- Reducir el costo de la infraestructura de análisis de datos con arquitecturas simplificadas
Algunos casos de uso y razones comunes de ciencia de datos y análisis de datos observados son:
- Los profesionales de SAS aprovechan SAS por sus paquetes estadísticos principales para desarrollar resultados de análisis avanzados que cumplen con los requisitos regulatorios, mientras utilizan Databricks Lakehouse para la gestión de datos, procesamiento de tipos ELT y gobernanza de datos
- Los modelos de aprendizaje automático desarrollados en SAS se puntúan en cantidades masivas de datos utilizando la arquitectura de procesamiento paralelo del motor Apache Spark en la plataforma Lakehouse
- Los analistas de datos de SAS obtienen acceso más rápido a grandes cantidades de datos en la Plataforma Lakehouse para análisis ad hoc e informes utilizando puntos de conexión de Databricks SQL y conectores de alto ancho de banda
- Facilitar el viaje de modernización y migración a la nube estableciendo un flujo de trabajo híbrido que involucre tanto la arquitectura en la nube como la plataforma SAS local
Sin embargo, un desafío clave de esta coexistencia es cómo se comparten los datos de manera performante entre las dos plataformas. En este blog, compartimos las mejores prácticas implementadas por T1A para sus clientes y los resultados de referencia que comparan diferentes métodos de movimiento de datos entre Databricks y SAS.
Escenarios
El caso de uso más popular es un desarrollador de SAS que intenta acceder a datos en el lakehouse. Los pipelines de análisis que involucran ambas tecnologías requieren flujo de datos en ambas direcciones: datos movidos de Databricks a SAS y datos movidos de SAS a Databricks.
- Acceder a Delta Lake desde SAS: Un usuario de SAS desea acceder a big data en Delta Lake utilizando el lenguaje de programación SAS.
- Acceder a conjuntos de datos SAS desde Databricks: Un usuario de Databricks desea acceder a conjuntos de datos SAS, generalmente los conjuntos de datos sas7bdat como un DataFrame para procesar en pipelines de Databricks o almacenar en Delta Lake para acceso a nivel empresarial.
En nuestras pruebas de referencia, utilizamos la siguiente configuración del entorno:
- Microsoft Azure como plataforma en la nube
- SAS 9.4M7 en Azure (VM estándar D8s v3 de un solo nodo)
- Databricks runtime 9.0, Apache Spark 3.1.2 (clúster estándar DS4v2 de 2 nodos)
La Figura 1 muestra el diagrama de arquitectura conceptual con los componentes discutidos. Databricks Lakehouse se asienta sobre el almacenamiento de Azure Data Lake con arquitectura de medallón de Delta Lake. SAS 9.4 instalado en Azure VM se conecta a Databricks Lakehouse para leer/escribir datos utilizando las opciones de conexión discutidas en las siguientes secciones.
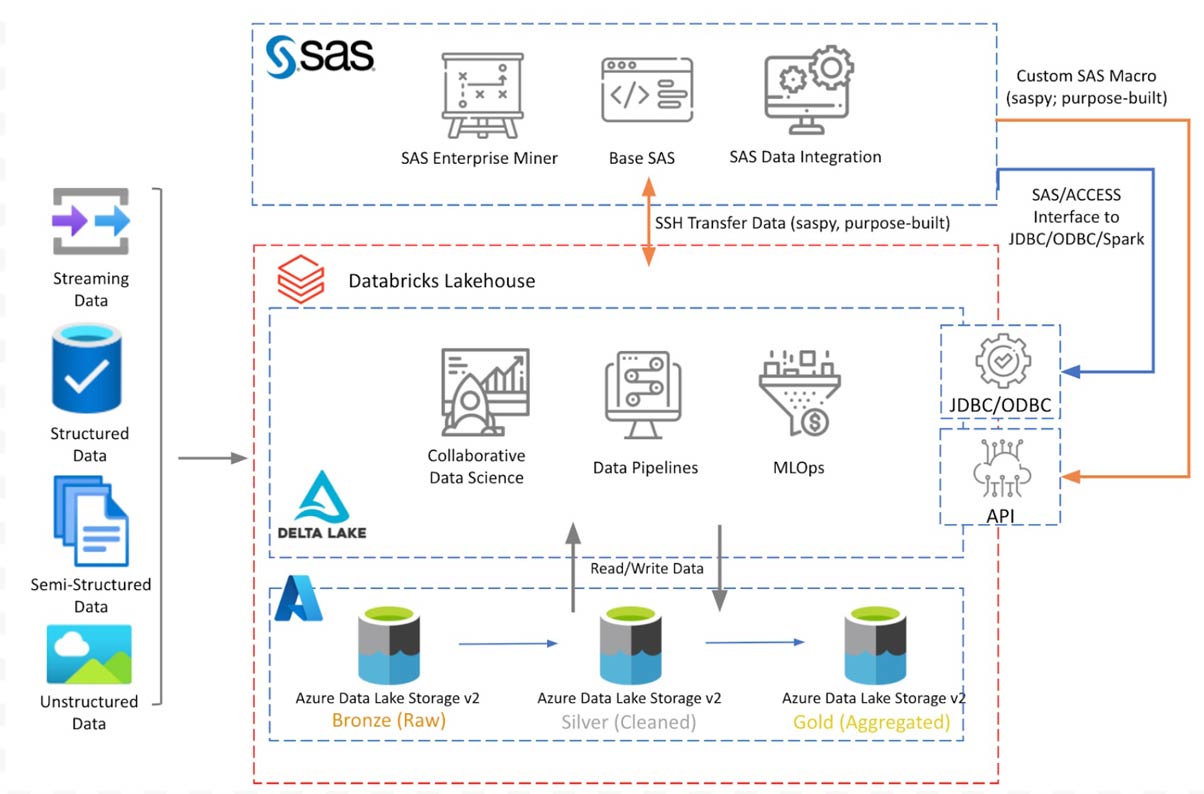
El diagrama anterior muestra una arquitectura conceptual de Databricks implementado en Azure. La arquitectura será similar en otras plataformas en la nube. En este blog, solo discutimos la integración con la plataforma SAS 9.4. En una futura publicación de blog, extenderemos esta discusión para acceder a datos del lakehouse desde SAS Viya.
Acceder a Delta Lake desde SAS
Imaginemos que tenemos una tabla de Delta Lake que necesita ser procesada en un programa SAS. Queremos el mejor rendimiento al acceder a esta tabla, al mismo tiempo que evitamos cualquier posible problema con la integridad de los datos o la compatibilidad de tipos de datos. Existen diferentes formas de lograr la integridad y compatibilidad de los datos. A continuación, analizamos algunos métodos y los comparamos en cuanto a facilidad de uso y rendimiento.
En nuestras pruebas, utilizamos el conjunto de datos de comportamiento de comercio electrónico (5.67GB, 9 columnas, ~ 42 millones de registros) de Kaggle.
Crédito de la fuente de datos: Datos de comportamiento de comercio electrónico de tiendas multimarca y Plataforma de Marketing REES46.
Métodos probados
1. Usando conectores de la interfaz SAS/ACCESS
Tradicionalmente, los usuarios de SAS aprovechan el software SAS/ACCESS para conectarse a fuentes de datos externas. Puede usar una declaración LIBNAME de SAS apuntando al clúster de Databricks o usar la instalación de paso a través de SQL. Actualmente, para SAS 9.4, hay tres opciones de conexión disponibles.
La interfaz SAS/ACCESS a Spark se ha cargado recientemente con capacidades y soporte exclusivo para clústeres de Databricks. Vea este video para una breve demostración. El video menciona SAS Viya, pero lo mismo es aplicable a SAS 9.4.
Los ejemplos de código sobre cómo usar estos conectores se pueden encontrar en este repositorio de git: T1A Git - Ejemplos de bibliotecas SAS.
2. Usando el paquete saspy
La biblioteca de código abierto, saspy, de SAS Institute permite a los usuarios de Databricks Notebook ejecutar sentencias SAS desde una celda de Python en el notebook para ejecutar código en el servidor SAS, así como para importar y exportar datos de conjuntos de datos SAS a Pandas DataFrame.
Dado que el enfoque de esta sección es el acceso a datos del lakehouse por parte de un programador SAS utilizando programación SAS, este método se encapsuló en un programa macro SAS similar al método de integración diseñado específicamente que se discute a continuación.
Para lograr un mejor rendimiento con este paquete, probamos la configuración con una opción char_length definida (detalles disponibles aquí). Con esta opción, podemos definir longitudes para los campos de caracteres en el conjunto de datos. En nuestras pruebas, el uso de esta opción generó un aumento adicional del 15% en el rendimiento. Para la capa de transporte entre entornos, utilizamos la configuración de saspy con una conexión SSH al servidor SAS.
3. Usando una integración diseñada específicamente
Aunque los dos métodos mencionados anteriormente tienen sus ventajas, el rendimiento se puede mejorar aún más abordando algunas deficiencias, discutidas en la siguiente sección (Resultados de la prueba), de los métodos anteriores. Con esto en mente, desarrollamos una utilidad de integración basada en macros SAS con un enfoque principal en el rendimiento y la usabilidad para los usuarios de SAS. La macro SAS se puede integrar fácilmente en el código SAS existente sin ningún conocimiento sobre la plataforma Databricks, Apache Spark o Python.
La macro orquesta un proceso de varios pasos utilizando la API de Databricks:
- Instruye al clúster de Databricks para consultar y extraer datos según la consulta SQL proporcionada y almacenar en caché los resultados en DBFS, aprovechando sus capacidades de procesamiento distribuido de Spark SQL.
- Comprime y transfiere de forma segura el conjunto de datos al servidor SAS (CSV en GZIP) a través de SSH
- Descomprime e importa datos en SAS para que estén disponibles para el usuario en la biblioteca SAS. En este paso, aprovecha los metadatos de columna del catálogo de datos de Databricks (tipos de columna, longitudes y formatos) para una presentación de datos coherente, correcta y eficiente en SAS
Ten en cuenta que para los tipos de datos de longitud variable, la integración admite diferentes opciones de configuración, dependiendo de lo que mejor se adapte a los requisitos del usuario, como:
- la necesidad de usar un valor predeterminado configurable
- el perfilado de hasta 10,000 filas (+ añadir margen) para identificar el valor más grande
- el perfilado de toda la columna en el conjunto de datos para identificar el valor más grande
Una versión simplificada del código está disponible aquí T1A Git - Integración personalizada SAS DBR.
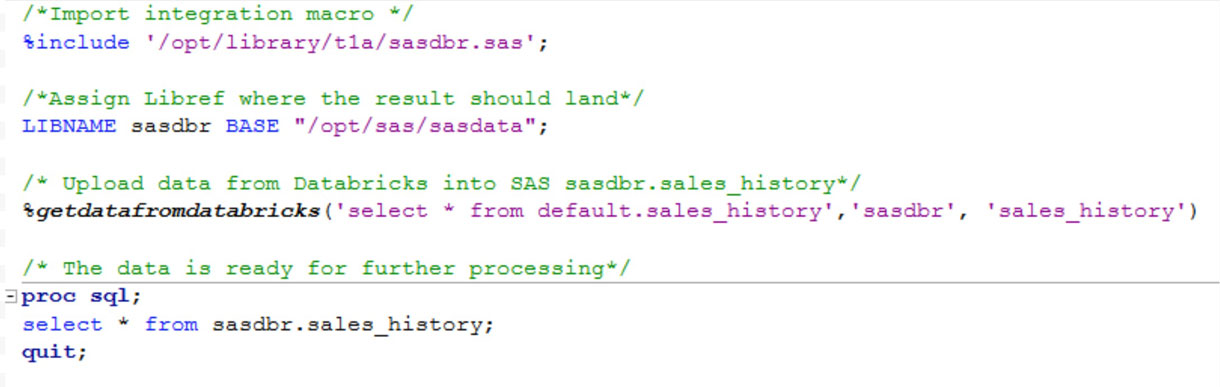
El uso por parte del usuario final de esta macro SAS se muestra a continuación y requiere tres entradas:
- Consulta SQL, según la cual se extraerán los datos de Databricks
- Libref de SAS donde aterrizarán los datos
- Nombre que se le dará al conjunto de datos SAS
Resultados de la prueba
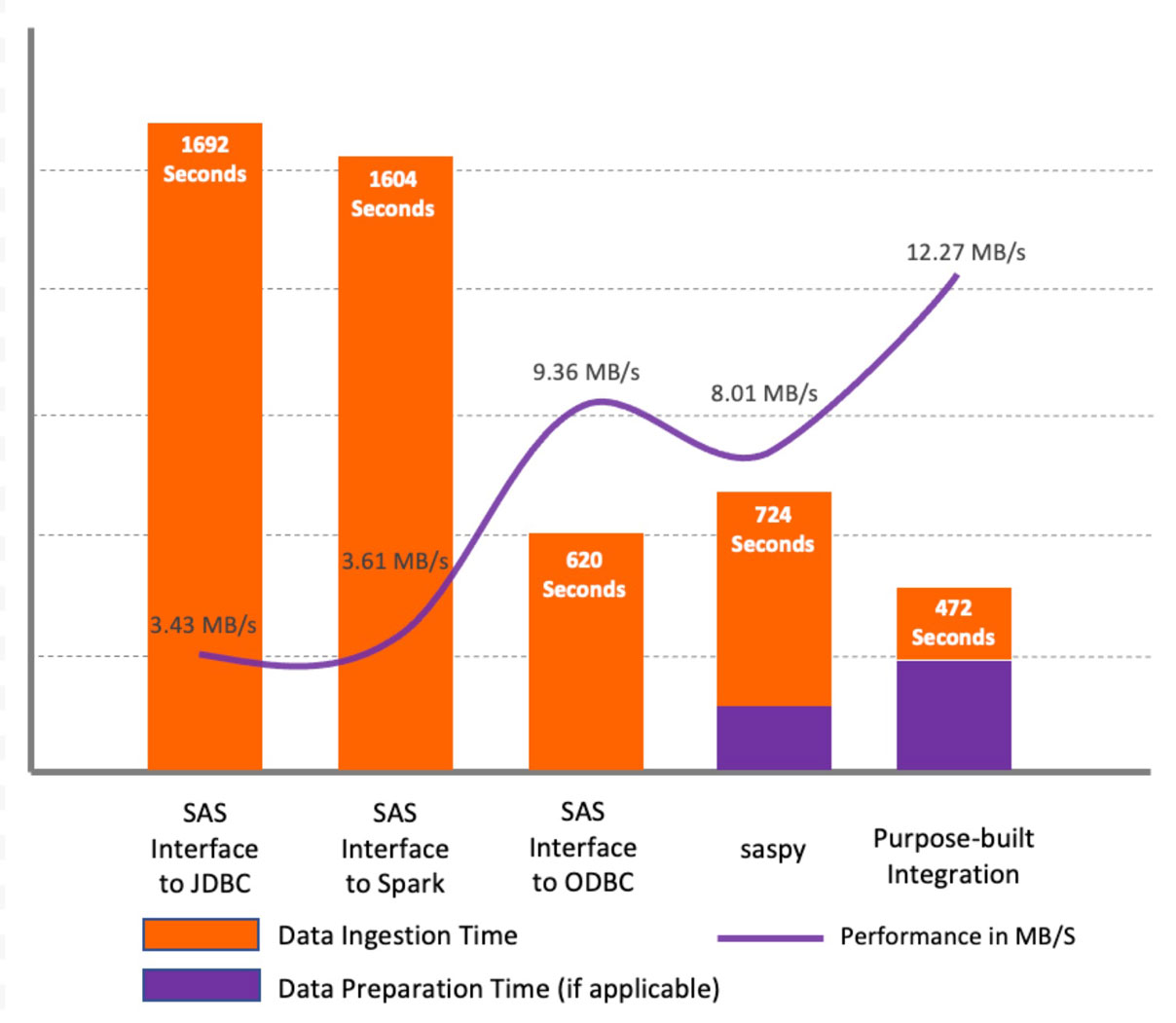
Como se muestra en el gráfico anterior, para el conjunto de datos de prueba, los resultados indican que SAS/ACCESS Interface to JDBC y SAS/ACCESS Interface to Apache Spark mostraron un rendimiento similar y un rendimiento inferior en comparación con otros métodos. La razón principal es que los métodos JDBC no perfilan las columnas de caracteres en los conjuntos de datos para establecer una longitud de columna adecuada en el conjunto de datos SAS. En su lugar, definen la longitud predeterminada para todos los tipos de columna de caracteres (String y Varchar) como 765 símbolos. Esto causa no solo problemas de rendimiento durante la recuperación inicial de datos, sino para todo el procesamiento posterior. Además, consume un almacenamiento adicional significativo. En nuestras pruebas, para el conjunto de datos de origen de 5.6 GB, terminamos con un archivo de 216 GB en la biblioteca WORK. Sin embargo, con SAS/ACCESS Interface to ODBC, la longitud predeterminada fue de 255 símbolos, lo que resultó en un aumento significativo del rendimiento.
El uso de los métodos SAS/ACCESS Interface es la opción más conveniente para los usuarios de SAS existentes. Hay algunas consideraciones importantes al usar estos métodos:
- Ambas soluciones admiten el paso implícito de consultas, pero con algunas limitaciones:
- SAS/ACCESS Interface to JDBC/ODBC solo admite el paso de sentencias PROC SQL
- Además del paso de PROC SQL, SAS/ACCESS Interface to Apache Spark admite el paso de la mayoría de las funciones SQL. Este método también permite enviar procedimientos SAS comunes a los clústeres de Databricks.
- El problema con el establecimiento de la longitud de las columnas de caracteres descrito anteriormente. Como solución alternativa, sugerimos usar la opción DBSASTYPE para establecer explícitamente la longitud de la columna para las tablas SAS. Esto ayudará con el procesamiento posterior del conjunto de datos, pero no afectará la recuperación inicial de los datos de Databricks
- SAS/ACCESS Interface to Apache Spark/JDBC/ODBC no permite combinar tablas de diferentes bases de datos (esquemas) de Databricks asignadas como diferentes librefs en la misma consulta (uniéndolas) con la facilidad de paso. En su lugar, provocará la exportación de tablas completas en SAS y el procesamiento en SAS. Como solución alternativa, sugerimos crear un esquema dedicado en Databricks que contendrá vistas basadas en tablas de diferentes bases de datos (esquemas).
El uso del método saspy mostró un rendimiento ligeramente mejor en comparación con los métodos SAS/ACCESS Interface to JDBC/Spark; sin embargo, el principal inconveniente es que la biblioteca saspy solo funciona con DataFrames de pandas y ejerce una carga significativa en el programa controlador de Apache Spark y requiere que todo el DataFrame se cargue en la memoria.
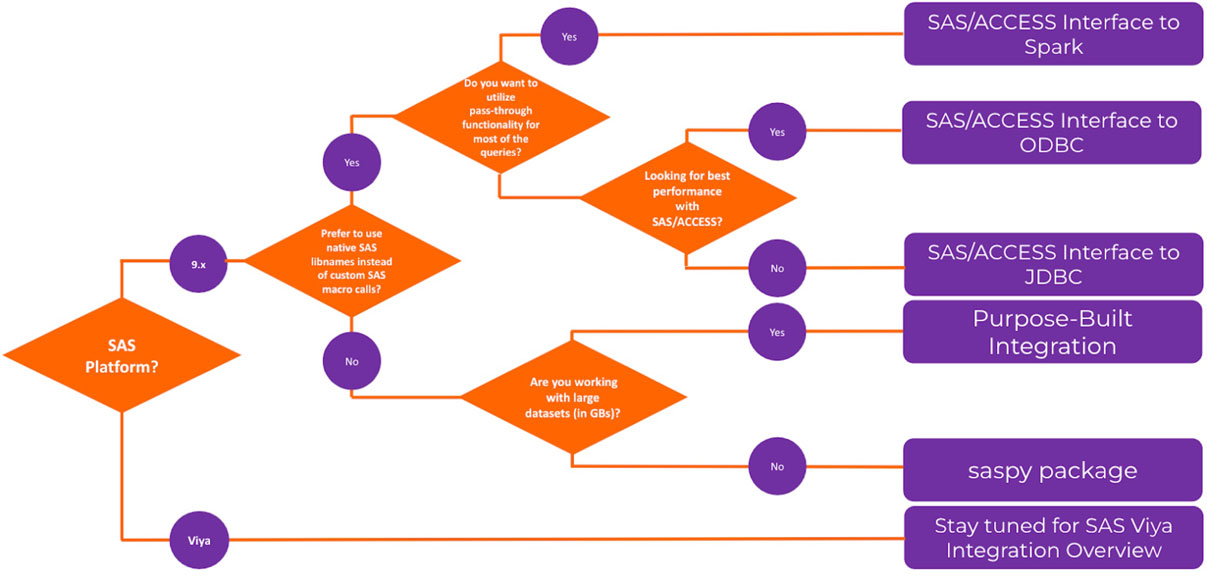
El método de integración diseñada específicamente mostró el mejor rendimiento en comparación con otros métodos probados. La Figura 3 muestra un diagrama de flujo con orientación general para elegir entre los métodos discutidos.
Acceder a conjuntos de datos SAS desde Databricks
Esta sección aborda la necesidad de los desarrolladores de Databricks de ingerir un conjunto de datos SAS en Delta Lake y hacerlo disponible en Databricks para inteligencia empresarial, análisis visual y otros casos de uso de análisis avanzados, mientras que algunos de los métodos descritos anteriormente son aplicables aquí, se discuten algunos métodos adicionales.
En la prueba, comenzamos con un conjunto de datos SAS (en formato sas7bdat) en el servidor SAS, y al final, tenemos este conjunto de datos disponible como Spark DataFrame (si la invocación perezosa es aplicable, forzamos la carga de datos en un DataFrame y medimos el tiempo total) en Databricks.
Utilizamos el mismo entorno y el mismo conjunto de datos para este escenario que se utilizó en el escenario anterior. Las pruebas no consideran el caso de uso en el que un usuario SAS escribe un conjunto de datos en Delta Lake utilizando programación SAS. Esto implica tener en cuenta las herramientas y capacidades del proveedor de la nube que se discutirán en una futura publicación de blog.
Métodos probados
1. Uso del paquete saspy de SAS
El método sd2df en la biblioteca saspy convierte un conjunto de datos SAS en un pandas DataFrame, utilizando SSH para la transferencia de datos. Ofrece varias opciones para el almacenamiento provisional (Memoria, CSV, DISK) durante la transferencia. En nuestra prueba, la opción CSV, que utiliza el archivo CSV de PROC EXPORT y los métodos read_csv() de pandas, que es la opción recomendada para conjuntos de datos grandes, mostró el mejor rendimiento.
2. Uso del método pandas
Desde las primeras versiones, pandas ha permitido a los usuarios leer archivos sas7bdat utilizando la API pandas.read_sas. El archivo SAS debe ser accesible para el programa de Python. Los métodos comúnmente utilizados son FTP, HTTP o la transferencia a almacenamiento de objetos en la nube como S3. Nosotros preferimos usar un enfoque más simple para mover un archivo SAS del servidor SAS remoto al clúster de Databricks usando SCP.
3. Uso de spark-sas7bdat
Spark-sas7bdat es un paquete de código abierto desarrollado específicamente para Apache Spark. Similar al método pandas.read_sas(), el archivo SAS debe estar disponible en el sistema de archivos. Descargamos el archivo sas7bdat de un servidor SAS remoto usando SCP.
4. Uso de una integración diseñada específicamente
Otro método que se exploró es el uso de técnicas convencionales con un enfoque en el equilibrio entre conveniencia y rendimiento. Este método abstrae las integraciones principales y se pone a disposición del usuario como una biblioteca de Python que se ejecuta desde el Notebook de Databricks.
- Use el paquete saspy para ejecutar un código de macro SAS (en un servidor SAS) que hace lo siguiente:
- Exportar sas7bdat a archivo CSV usando código SAS
- Comprimir el archivo CSV a GZIP
- Mover el archivo comprimido al nodo controlador del clúster de Databricks usando SCP
- Descomprimir el archivo CSV
- Leer el archivo CSV en un DataFrame de Apache Spark
Resultados de la prueba
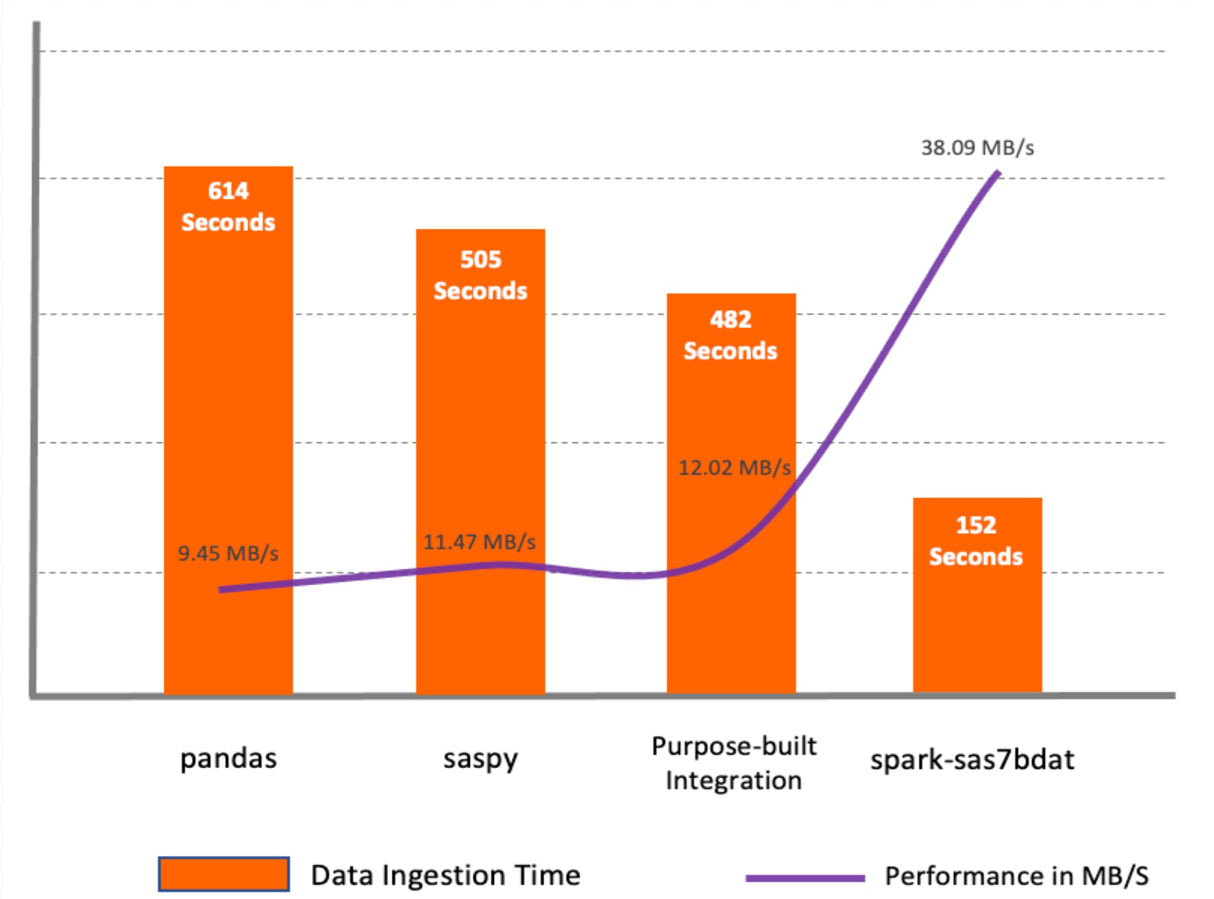
El paquete spark-sas7bdat mostró el mejor rendimiento entre todos los métodos. Este paquete aprovecha al máximo el procesamiento paralelo en Apache Spark. Distribuye bloques de archivos sas7bdat en los nodos trabajadores. El principal inconveniente de este método es que sas7bdat es un formato binario propietario, y la biblioteca se construyó basándose en la ingeniería inversa de este formato binario, por lo que no admite todos los tipos de archivos sas7bdat, además de que no cuenta con soporte oficial (comercial) del proveedor.
Los métodos saspy y pandas son similares en el sentido de que ambos están diseñados para un entorno de un solo nodo y ambos leen datos en un DataFrame de pandas, lo que requiere un paso adicional antes de que los datos estén disponibles como un DataFrame de Spark.
La macro integración específica para el propósito mostró un mejor rendimiento en comparación con saspy y pandas porque lee datos de CSV a través de las API de Apache Spark. Sin embargo, no supera el rendimiento del paquete spark-sas7bdat. El método específico para el propósito puede ser conveniente en algunos casos, ya que permite agregar transformaciones de datos intermedias en el servidor SAS.
Conclusión
Cada vez más empresas se están volcando hacia la construcción de un Databricks Lakehouse y existen múltiples formas de acceder a los datos del Lakehouse a través de otras tecnologías. Este blog analiza cómo los desarrolladores de SAS, los científicos de datos y otros usuarios empresariales pueden aprovechar los datos del Lakehouse y escribir los resultados en la nube. En nuestro experimento, probamos varios métodos diferentes para leer y escribir datos entre Databricks y SAS. Los métodos varían no solo en rendimiento, sino también en conveniencia y capacidades adicionales que proporcionan.
Para esta prueba, utilizamos la plataforma SAS 9.4M7. SAS Viya admite la mayoría de los enfoques discutidos, pero también ofrece opciones adicionales. Si desea obtener más información sobre los métodos u otros enfoques de integración especializados no cubiertos aquí, no dude en contactarnos en Databricks o databricks@t1a.com.
En las próximas publicaciones de esta serie de blogs, analizaremos las mejores prácticas para implementar pipelines de datos integrados, flujos de trabajo de extremo a extremo, utilizando SAS y Databricks, y cómo aprovechar las tecnologías In-Database de SAS para puntuar modelos SAS en clústeres de Databricks.
SAS® y todos los demás nombres de productos o servicios de SAS Institute Inc. son marcas registradas o marcas comerciales de SAS Institute Inc. en EE. UU. y otros países. ® indica registro en EE. UU.
Comenzar
Pruebe el curso, Databricks para usuarios de SAS, en Databricks Academy para obtener una experiencia práctica básica con la programación PySpark para construcciones del lenguaje de programación SAS y contáctenos para obtener más información sobre cómo podemos ayudar a su equipo de SAS a incorporar sus cargas de trabajo de ETL en Databricks y habilitar las mejores prácticas.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.