Simplificando la captura de datos de cambios con Databricks Delta Live Tables
por Mojgan Mazouchi
Esta guía te mostrará cómo puedes aprovechar la Captura de Datos de Cambios (Change Data Capture) en pipelines de Delta Live Tables para identificar nuevos registros y capturar los cambios realizados en el conjunto de datos de tu data lake. Los pipelines de Delta Live Tables te permiten desarrollar pipelines de datos escalables, confiables y de baja latencia, mientras realizas la Captura de Datos de Cambios en tu data lake con recursos de cómputo mínimos requeridos y un manejo transparente de datos fuera de orden.
Antecedentes sobre la Captura de Datos de Cambios
La Captura de Datos de Cambios (Change Data Capture, CDC) es un proceso que identifica y captura cambios incrementales (eliminaciones, inserciones y actualizaciones de datos) en bases de datos, como el seguimiento del estado de clientes, pedidos o productos para aplicaciones de datos casi en tiempo real. CDC proporciona la evolución de datos en tiempo real procesando datos de forma incremental continua a medida que ocurren nuevos eventos.
Dado que más del 80% de las organizaciones planean implementar estrategias multi-nube para 2025, es fundamental elegir el enfoque correcto para tu negocio que permita la centralización transparente en tiempo real de todos los cambios de datos en tu pipeline de ETL a través de múltiples entornos.
Al capturar eventos de CDC, los usuarios de Databricks pueden volver a materializar la tabla de origen como una Delta Table en el Lakehouse y ejecutar sus análisis sobre ella, mientras pueden combinar datos con sistemas externos. El comando MERGE INTO en Delta Lake en Databricks permite a los clientes insertar y eliminar registros de manera eficiente en sus data lakes; puedes consultar nuestro análisis anterior en profundidad sobre el tema aquí. Este es un caso de uso común que observamos que muchos clientes de Databricks están aprovechando Delta Lakes para realizar, y mantener sus data lakes actualizados con datos comerciales en tiempo real.
Si bien Delta Lake proporciona una solución completa para la sincronización de CDC en tiempo real en un data lake, ahora nos complace anunciar la función de Captura de Datos de Cambios en Delta Live Tables que hace que tu arquitectura sea aún más simple, eficiente y escalable. DLT permite a los usuarios ingerir datos de CDC sin problemas usando SQL y Python.
Las soluciones de CDC anteriores con tablas delta utilizaban la operación MERGE INTO, que requiere ordenar manualmente los datos para evitar fallos cuando varias filas del conjunto de datos de origen coinciden al intentar actualizar las mismas filas de la tabla Delta de destino. Para manejar datos fuera de orden, se requería un paso adicional para preprocesar la tabla de origen utilizando una implementación foreachBatch para eliminar la posibilidad de múltiples coincidencias, conservando solo el último cambio para cada clave (ver el ejemplo de captura de datos de cambios). La nueva operación APPLY CHANGES INTO en los pipelines de DLT maneja automáticamente y sin problemas los datos fuera de orden sin necesidad de intervención manual de ingeniería de datos.
CDC con Databricks Delta Live Tables
En este blog, demostraremos cómo usar el comando APPLY CHANGES INTO en pipelines de Delta Live Tables para un caso de uso común de CDC donde los datos de CDC provienen de un sistema externo. Hay una variedad de herramientas de CDC disponibles, como Debezium, Fivetran, Qlik Replicate, Talend y StreamSets. Si bien las implementaciones específicas difieren, estas herramientas generalmente capturan y registran el historial de cambios de datos en registros; las aplicaciones posteriores consumen estos registros de CDC. En nuestro ejemplo, los datos se cargan en el almacenamiento de objetos en la nube desde una herramienta de CDC como Debezium, Fivetran, etc.
Tenemos datos de varias herramientas de CDC que llegan a un almacenamiento de objetos en la nube o a una cola de mensajes como Apache Kafka. Típicamente vemos que CDC se usa en una ingesta a lo que nos referimos como la arquitectura medallion. Una arquitectura medallion es un patrón de diseño de datos utilizado para organizar lógicamente los datos en un Lakehouse, con el objetivo de mejorar incremental y progresivamente la estructura y calidad de los datos a medida que fluyen a través de cada capa de la arquitectura. Delta Live Tables te permite aplicar cambios de forma transparente desde feeds de CDC a tablas en tu Lakehouse; combinar esta funcionalidad con la arquitectura medallion permite que los cambios incrementales fluyan fácilmente a través de cargas de trabajo analíticas a escala. Usar CDC junto con la arquitectura medallion proporciona múltiples beneficios a los usuarios, ya que solo se deben procesar los datos cambiados o agregados. Por lo tanto, permite a los usuarios mantener de manera rentable las tablas gold actualizadas con los últimos datos comerciales.
NOTA: El ejemplo aquí se aplica a las versiones SQL y Python de CDC y también a una forma específica de usar las operaciones; para evaluar variaciones, consulta la documentación oficial aquí.
Prerrequisitos
Para aprovechar al máximo esta guía, deberías tener familiaridad básica con:
- SQL o Python
- Delta Live Tables
- Desarrollo de pipelines ETL y/o trabajo con sistemas de Big Data
- Notebooks interactivos y clusters de Databricks
- Debes tener acceso a un Workspace de Databricks con permisos para crear nuevos clusters, ejecutar trabajos y guardar datos en una ubicación en almacenamiento de objetos en la nube o en DBFS.
- Para el pipeline que estamos creando en este blog, se debe seleccionar la edición de producto "Advanced", que admite la aplicación de restricciones de calidad de datos.
El Conjunto de Datos
Aquí estamos consumiendo datos de CDC realistas de una base de datos externa. En este pipeline, usaremos la biblioteca Faker para generar el conjunto de datos que una herramienta de CDC como Debezium puede producir y llevar al almacenamiento en la nube para la ingesta inicial en Databricks. Usando Auto Loader, cargamos incrementalmente los mensajes desde el almacenamiento de objetos en la nube y los almacenamos en la tabla Bronze, ya que almacena los mensajes sin procesar. Las tablas Bronze están destinadas a la ingesta de datos, lo que permite un acceso rápido a una única fuente de verdad. Luego, realizamos APPLY CHANGES INTO desde la tabla Bronze limpiada para propagar las actualizaciones a la tabla Silver. A medida que los datos fluyen a las tablas Silver, generalmente se vuelven más refinados y optimizados ("just-enough") para proporcionar a una empresa una visión de todas sus entidades comerciales clave. Ver el diagrama a continuación.
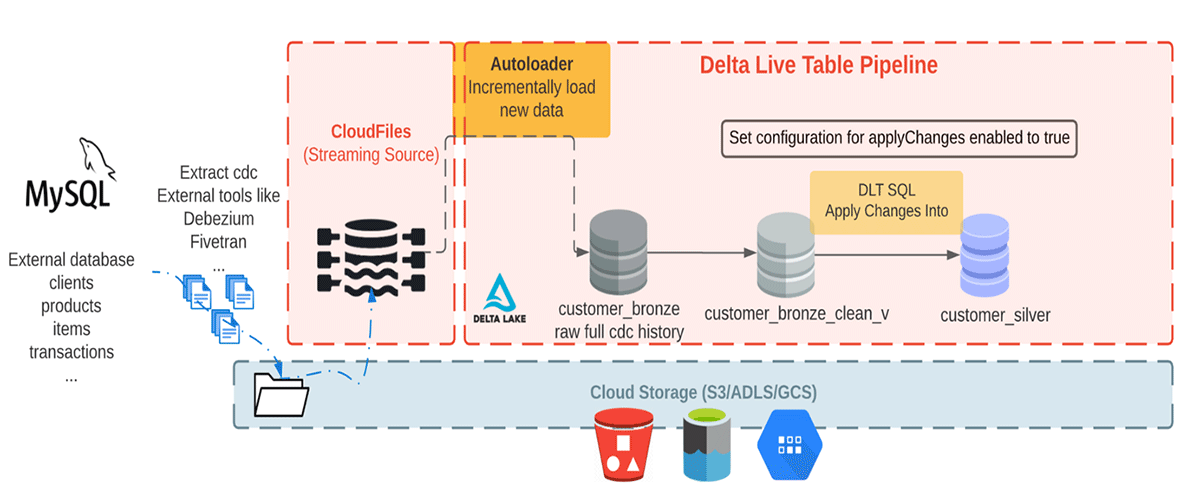
Este blog se centra en un ejemplo simple que requiere un mensaje JSON con cuatro campos: nombre del cliente, correo electrónico, dirección e ID, junto con dos campos: operation (que almacena el código de operación (DELETE, APPEND, UPDATE, CREATE) y operation_date (que almacena la fecha y hora en que llegó el registro para cada acción de operación) para describir los datos cambiados.
Para generar un conjunto de datos de ejemplo con los campos anteriores, estamos utilizando un paquete de Python que genera datos falsos, Faker. Puedes encontrar el notebook relacionado con esta sección de generación de datos aquí. En este notebook proporcionamos el nombre y la ubicación de almacenamiento para escribir los datos generados allí. Estamos utilizando la funcionalidad DBFS de Databricks, consulta la documentación de DBFS para obtener más información sobre cómo funciona. Luego, usamos una función definida por el usuario de PySpark para generar el conjunto de datos sintético para cada campo y escribimos los datos de vuelta a la ubicación de almacenamiento definida, a la que nos referiremos en otros notebooks para acceder al conjunto de datos sintético.
Ingesta del conjunto de datos sin procesar usando Auto Loader
Según el paradigma de la arquitectura Medallion, la capa bronze contiene la calidad de datos más cruda. En esta etapa, podemos leer incrementalmente nuevos datos usando Autoloader desde una ubicación en el almacenamiento en la nube. Aquí estamos agregando la ruta a nuestro conjunto de datos generado a la sección de configuración en la configuración del pipeline, lo que nos permite cargar la ruta de origen como una variable. Así que ahora nuestra configuración en la configuración del pipeline se ve así:
Luego cargamos esta propiedad de configuración en nuestros notebooks.
Echemos un vistazo a la tabla Bronze que ingeriremos, a. En SQL, y b. Usando Python
a. SQL
b. Python
Las declaraciones anteriores utilizan Auto Loader para crear una tabla de Streaming en vivo llamada customer_bronze a partir de archivos JSON. Cuando se utiliza Autoloader en Delta Live Tables, no es necesario proporcionar ninguna ubicación para el esquema o el punto de control, ya que esas ubicaciones serán administradas automáticamente por su canalización de DLT.
Auto Loader proporciona una fuente de Structured Streaming llamada cloud_files en SQL y cloudFiles en Python, que toma una ruta de almacenamiento en la nube y el formato como parámetros.
Para reducir los costos de cómputo, recomendamos ejecutar la canalización de DLT en modo Activado como un micro-lote, asumiendo que no tiene requisitos de latencia muy bajos.
Expectativas y datos de alta calidad
En el siguiente paso para crear un conjunto de datos de alta calidad, diverso y accesible, imponemos criterios de verificación de calidad de expectativas utilizando Restricciones. Actualmente, una restricción puede ser retener, eliminar o fallar. Para más detalles, ver aquí. Todas las restricciones se registran para permitir un monitoreo de calidad optimizado.
a. SQL
b. Python
Uso de la declaración APPLY CHANGES INTO para propagar cambios a la tabla de destino descendente
Antes de ejecutar la consulta Apply Changes Into, debemos asegurarnos de que exista una tabla de streaming de destino que contendrá los datos más actualizados. Si no existe, debemos crearla. Las celdas siguientes son ejemplos de cómo crear una tabla de streaming de destino. Tenga en cuenta que en el momento de publicar este blog, la declaración de creación de la tabla de streaming de destino es necesaria junto con la consulta Apply Changes Into, y ambas deben estar presentes en la canalización, de lo contrario, su consulta de creación de tabla fallará.
a. SQL
b. Python
Ahora que tenemos una tabla de streaming de destino, podemos propagar los cambios a la tabla de destino descendente utilizando la consulta Apply Changes Into. Si bien el feed de CDC viene con eventos INSERT, UPDATE y DELETE, el comportamiento predeterminado de DLT es aplicar eventos INSERT y UPDATE de cualquier registro en el conjunto de datos de origen que coincida con las claves primarias, y secuenciados por un campo que identifica el orden de los eventos. Más específicamente, actualiza cualquier fila en la tabla de destino existente que coincida con la(s) clave(s) primaria(s) o inserta una nueva fila cuando no existe un registro coincidente en la tabla de streaming de destino. Podemos usar APPLY AS DELETE WHEN en SQL, o su argumento equivalente apply_as_deletes en Python para manejar eventos DELETE.
En este ejemplo, usamos "id" como mi clave primaria, que identifica de forma única a los clientes y permite que los eventos CDC se apliquen a esos registros de clientes identificados en la tabla de streaming de destino. Dado que "operation_date" mantiene el orden lógico de los eventos CDC en el conjunto de datos de origen, usamos "SEQUENCE BY operation_date" en SQL, o su equivalente "sequence_by = col("operation_date")" en Python para manejar eventos de cambio que llegan fuera de orden. Tenga en cuenta que el valor del campo que usamos con SEQUENCE BY (o sequence_by) debe ser único entre todas las actualizaciones de la misma clave. En la mayoría de los casos, la columna de secuencia será una columna con información de marca de tiempo.
Finalmente, usamos "COLUMNS * EXCEPT (operation, operation_date, _rescued_data)" en SQL, o su equivalente "except_column_list"= ["operation", "operation_date", "_rescued_data"] en Python para excluir tres columnas de "operation", "operation_date", "_rescued_data" de la tabla de streaming de destino. Por defecto, todas las columnas se incluyen en la tabla de streaming de destino, cuando no especificamos la cláusula "COLUMNS".
a. SQL
b. Python
Para consultar la lista completa de cláusulas disponibles, consulte aquí.
Tenga en cuenta que, en el momento de publicar este blog, una tabla que lee desde el destino de una consulta APPLY CHANGES INTO o la función apply_changes debe ser una tabla en vivo y no puede ser una tabla de streaming en vivo.
Una notebook en SQL y Python está disponible como referencia para esta sección. Ahora que tenemos todas las celdas listas, creemos una canalización para ingerir datos del almacenamiento de objetos en la nube. Abra Trabajos en una nueva pestaña o ventana en su espacio de trabajo y seleccione "Delta Live Tables".
La canalización asociada con este blog tiene la siguiente configuración de canalización DLT:
- Seleccione "Crear canalización" para crear una nueva canalización
- Especifique un nombre como "Retail CDC Pipeline"
- Especifique las rutas de las notebooks que ya creó anteriormente, una para el conjunto de datos generado usando el paquete Faker y otra ruta para la ingesta de los datos generados en DLT. La segunda ruta de notebook puede hacer referencia a la notebook escrita en SQL o Python, dependiendo de su elección de idioma.
- Para acceder a los datos generados en el primer notebook, agregue la ruta del conjunto de datos en la configuración. Aquí almacenamos los datos en "/tmp/demo/cdc_raw/customers", por lo que establecemos "source" en "/tmp/demo/cdc_raw/" para hacer referencia a "source/customers" en nuestro segundo notebook.
- Especifique el Destino (que es opcional y se refiere a la base de datos de destino), donde puede consultar las tablas resultantes de su pipeline.
- Especifique la Ubicación de Almacenamiento en su almacenamiento de objetos (que es opcional), para acceder a sus conjuntos de datos producidos por DLT y a los registros de metadatos de su pipeline.
- Establezca el Modo del Pipeline en Activado. En modo Activado, el pipeline DLT consumirá nuevos datos en la fuente de una vez, y una vez que el procesamiento se complete, terminará automáticamente el recurso de cómputo. Puede alternar entre los modos Activado y Continuo al editar la configuración de su pipeline. Establecer "continuous": false en el JSON es equivalente a establecer el pipeline en modo Activado.
- Para esta carga de trabajo, puede deshabilitar la escalabilidad automática en Opciones de Autopilot y usar solo 1 worker cluster. Para cargas de trabajo de producción, recomendamos habilitar la escalabilidad automática y establecer el número máximo de workers necesarios para el tamaño del cluster.
- Seleccione "Iniciar"
- ¡Su pipeline se ha creado y se está ejecutando ahora!
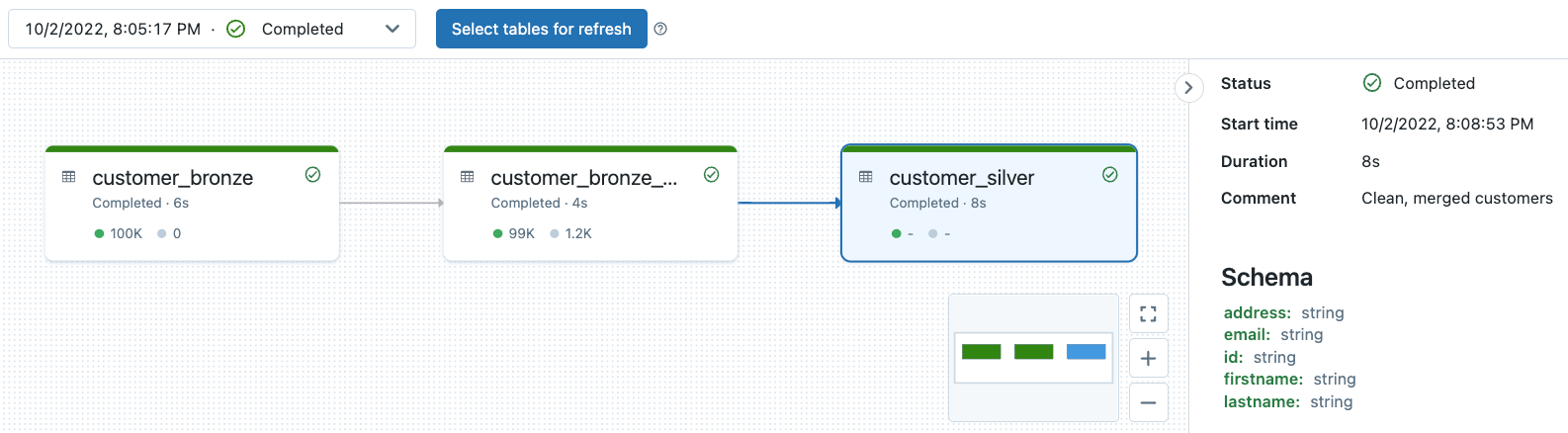
Observabilidad del linaje del pipeline DLT y monitoreo de la calidad de los datos
Todos los registros del pipeline DLT se almacenan en la ubicación de almacenamiento del pipeline. Puede especificar su ubicación de almacenamiento solo cuando esté creando su pipeline. Tenga en cuenta que una vez creado el pipeline, ya no podrá modificar la ubicación de almacenamiento.
Puede consultar nuestra anterior inmersión profunda sobre el tema aquí. Pruebe este notebook para ver la observabilidad del pipeline y el monitoreo de la calidad de los datos en el pipeline DLT de ejemplo asociado con este blog.
Conclusión
En este blog, mostramos cómo hicimos que fuera sencillo para los usuarios implementar de manera eficiente la captura de datos de cambios (CDC) en su plataforma Lakehouse con Delta Live Tables (DLT). DLT proporciona controles de calidad integrados con una visibilidad profunda de las operaciones del pipeline, observando el linaje del pipeline, monitoreando el esquema y las verificaciones de calidad en cada paso del pipeline. DLT admite el manejo automático de errores y la mejor capacidad de escalabilidad automática de su clase para cargas de trabajo de streaming, lo que permite a los usuarios tener datos de calidad con los recursos óptimos requeridos para su carga de trabajo.
Los ingenieros de datos ahora pueden implementar fácilmente CDC con una nueva API declarativa APPLY CHANGES INTO con DLT en SQL o Python. Esta nueva capacidad permite a sus pipelines ETL identificar fácilmente los cambios y aplicarlos en decenas de miles de tablas con soporte de baja latencia.
Por favor, vea este webinar para aprender cómo Delta Live Tables simplifica la complejidad de la transformación de datos y ETL, y consulte nuestro documento Captura de datos de cambios con Delta Live Tables, el github oficial y siga los pasos en este video para crear su pipeline!
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.