Uso de un grafo de conocimiento para potenciar una capa semántica de datos para Databricks
por Prasad Kona y Aaron Wallace
Esta es una publicación colaborativa entre Databricks y Stardog. Agradecemos a Aaron Wallace, Gerente Principal de Producto en Stardog, por su contribución.
Los Grafos de Conocimiento se han vuelto omnipresentes, solo que no lo sabemos. Lo experimentamos todos los días cuando buscamos en Google o vemos los feeds que recorren nuestras cuentas de redes sociales de personas que conocemos, empresas que seguimos o el contenido que nos gusta. De manera similar, los Grafos de Conocimiento Empresarial proporcionan una base para estructurar el contenido, los datos y los activos de información de su organización extrayendo, relacionando y entregando conocimiento como respuestas, recomendaciones e insights a cada aplicación impulsada por datos, desde chatbots hasta motores de recomendación o potenciando su BI y Analítica.
En este blog, aprenderá cómo Databricks y Stardog resuelven el desafío de la última milla en la democratización de datos e insights. Databricks proporciona una plataforma lakehouse para cargas de trabajo de datos, análisis e inteligencia artificial (IA) en una plataforma multicloud. Stardog proporciona una plataforma de grafo de conocimiento que puede modelar relaciones complejas contra datos amplios, y no solo grandes, para describir personas, lugares, cosas y cómo se relacionan. La Plataforma Databricks Lakehouse, junto con la capa semántica habilitada por Grafos de Conocimiento de Stardog, brindan a las organizaciones una base para una arquitectura de tejido de datos empresarial que permite a los equipos multifuncionales, interempresariales o interorganizacionales hacer y responder consultas complejas a través de silos de dominio.
La creciente necesidad de una Arquitectura de Tejido de Datos
La rápida innovación y disrupción en el espacio de gestión de datos están ayudando a las organizaciones a desbloquear valor de los datos disponibles tanto dentro como fuera de la empresa. Las organizaciones que operan a través de límites físicos y digitales están encontrando nuevas oportunidades para servir a los clientes de la manera en que desean ser servidos.
Estas organizaciones han conectado todos los datos relevantes a través de la cadena de suministro de datos para crear una imagen completa y precisa en el contexto de sus casos de uso. La mayoría de las industrias que buscan operar y compartir datos a través de límites organizacionales para armonizar datos y permitir el intercambio de datos están adoptando estándares abiertos en forma de ontologías prescritas, desde FIBO en Servicios Financieros hasta D3FEND en el dominio de la Ciberseguridad. Estas ontologías de negocio (o modelos semánticos) reflejan cómo pensamos sobre los datos con significado adjunto, es decir, "cosas" en lugar de cómo se estructuran y almacenan los datos, es decir, "cadenas", y hacen posible el intercambio y la reutilización de datos.
La idea de una capa semántica no es nueva. Ha existido durante más de 30 años, a menudo promovida por proveedores de BI que ayudan a las empresas a crear dashboards personalizados. Sin embargo, la adopción generalizada se ha visto obstaculizada, dada la naturaleza integrada de esa capa como parte de un sistema de BI propietario. Esta capa a menudo es demasiado rígida y compleja, sufriendo las mismas limitaciones que un sistema de base de datos relacional físico que modela datos para optimizar su lenguaje de consulta estructurado en lugar de cómo los datos se relacionan en el mundo real, de muchos a muchos. Una capa de datos semántica impulsada por grafos de conocimiento que opera entre sus capas de almacenamiento y consumo proporciona ese pegamento y multiplicador que conecta todos los datos para entregar valor en el contexto del caso de uso de negocio a científicos de datos ciudadanos y analistas que de otro modo no podrían participar y colaborar en arquitecturas centradas en datos fuera de un puñado de especialistas.
Habilitar un caso de uso en torno a los seguros
Veamos un ejemplo del mundo real de una organización de seguros multilínea para ilustrar cómo Stardog y Databricks trabajan juntos. Como la mayoría de las grandes empresas, muchas compañías de seguros luchan con desafíos similares en lo que respecta a los datos, como la falta de amplia disponibilidad de datos de fuentes internas y externas para la toma de decisiones por parte de partes interesadas críticas. Todos, desde la evaluación de riesgos de suscripción hasta la administración de pólizas, la gestión de reclamaciones y las agencias, luchan por aprovechar los datos e insights correctos para tomar decisiones críticas. Todos necesitan un tejido de datos empresarial que reúna los elementos de una arquitectura moderna de datos y análisis para hacer que los datos sean FAIR: Encontrables, Accesibles, Interoperables y Reutilizables. La mayoría de las empresas comienzan su viaje trayendo todas las fuentes de datos a un data lake. El enfoque de lakehouse de Databricks proporciona a las empresas una excelente base para almacenar todos sus datos analíticos y hacer que todos los datos sean accesibles para cualquier persona dentro de la empresa. En esta capa de datos, se realiza toda la limpieza, transformación y desambiguación. El siguiente paso en ese viaje es la armonización de datos, conectando datos según su significado para proporcionar un contexto más rico. Una capa semántica, entregada por un grafo de conocimiento, cambia el enfoque al análisis y procesamiento de datos y proporciona un tejido conectado de insights entre dominios a suscriptores, analistas de riesgos, agentes y equipos de servicio al cliente para gestionar el riesgo y ofrecer una experiencia excepcional al cliente.
Examinaremos cómo esto funcionaría con un modelo semántico simplificado como punto de partida.
Modele fácilmente entidades específicas del dominio y relaciones entre dominios
Crear visualmente un modelo de datos semántico a través de una experiencia similar a una pizarra es el primer paso para crear una capa de datos semántica. Dentro del proyecto Designer de Stardog, simplemente haga clic para crear clases (o entidades) específicas que son críticas para responder a sus preguntas de negocio. Una vez creada una clase, puede agregar todos los atributos y tipos de datos necesarios para describir esta nueva entidad. Vincular clases (o entidades) es fácil. Con una entidad seleccionada, simplemente haga clic para agregar un enlace y arrastre el punto de la nueva relación hasta que se ajuste a la otra entidad. Dé a esta nueva relación un nombre que describa el significado del negocio (por ejemplo, un "Cliente" "posee" un "Vehículo").
Agregue una nueva clase y vincúlela a una clase existente para crear una relación
Mapee metadatos de la Plataforma Databricks Lakehouse
¿Qué es un modelo sin datos? Los usuarios de Stardog pueden conectarse a una variedad de fuentes de datos estructuradas, semiestructuradas y no estructuradas persistiendo o virtualizando datos, o alguna combinación, cuándo y dónde tenga sentido. En Designer, es fácil conectar datos de fuentes existentes como Delta Lake para conectar los metadatos de tablas especificadas por el usuario. Esto permite el acceso inicial a esos datos a través de su capa de virtualización sin moverlos ni copiarlos al grafo de conocimiento. La capa de virtualización traduce automáticamente las consultas entrantes de Stardog de SPARQL basado en estándares abiertos a consultas SQL optimizadas de push-down en Databricks SQL.
Agregue una nueva fuente de datos como recurso del proyecto
Haga clic para agregar un nuevo recurso de proyecto y seleccione de una de las conexiones disponibles, como Databricks. Esta conexión aprovecha el nuevo punto final SQL lanzado recientemente por Databricks. Defina un alcance para los datos y especifique cualquier propiedad adicional. Utilice el panel de vista previa para echar un vistazo rápido a los datos antes de agregarlos a su proyecto.
Incorpore datos adicionales de una variedad de ubicaciones
Designer simplifica la incorporación de datos de otras fuentes de datos y archivos como CSV, para equipos que buscan realizar análisis de datos ad hoc, combinando datos de Delta con esta nueva información. Una vez agregado como recurso, simplemente agregue un enlace y arrastre y suelte a una clase para mapear los datos. Dé al mapeo un nombre significativo, especifique una columna de datos para el identificador principal, la etiqueta y cualquier otra columna de datos que coincida con los atributos de la entidad.
Mapee datos de un recurso de proyecto a una clase
Publique su trabajo
Dentro de Designer, puede publicar el modelo y los datos de este proyecto directamente en su servidor Stardog para su uso en Explorer de Stardog. El diseñador también le permite publicar y consumir la salida del grafo de conocimiento de diversas maneras. Puede publicar directamente en una carpeta comprimida de archivos, incluido su modelo y mapeos, en su sistema de control de versiones.
Publica directamente en una base de datos Stardog
Una vez que los datos se han publicado en Stardog, los analistas de datos también pueden usar herramientas populares de BI como Tableau para conectarse a través del Endpoint de BI/SQL de Stardog para extraer datos a través de la capa semántica en un informe o panel. El esquema generado automáticamente dentro de cualquier herramienta compatible con SQL permite a los usuarios escribir consultas SQL contra el Knowledge Graph. Las consultas que provienen de la capa SQL se traducen automáticamente a SPARQL, el lenguaje de consulta del Knowledge Graph, y se envían utilizando consultas optimizadas de origen generadas automáticamente, a través de la capa virtual, para su cálculo en el origen, en este caso, Databricks a través del endpoint de Databricks SQL. La misma información también puede estar disponible para los usuarios de Databricks en un notebook utilizando la API de Python de Stardog, pystardog. También puedes incrustar el grafo virtual para usarlo directamente dentro de tus aplicaciones utilizando la API GraphQL de Stardog. La capa semántica sobre el lakehouse proporciona un entorno único para todo tipo de usuarios y sus herramientas preferidas, manteniendo las operaciones respaldadas por un conjunto coherente de datos.
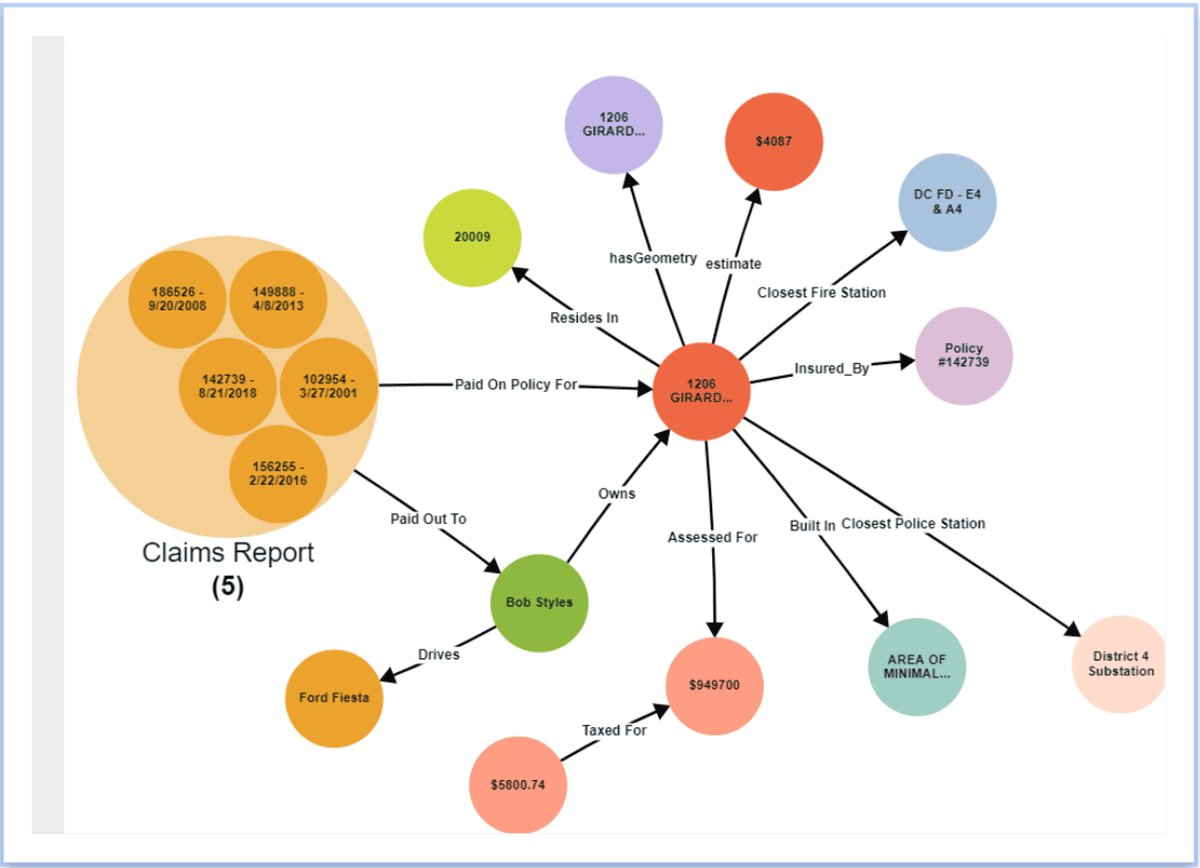
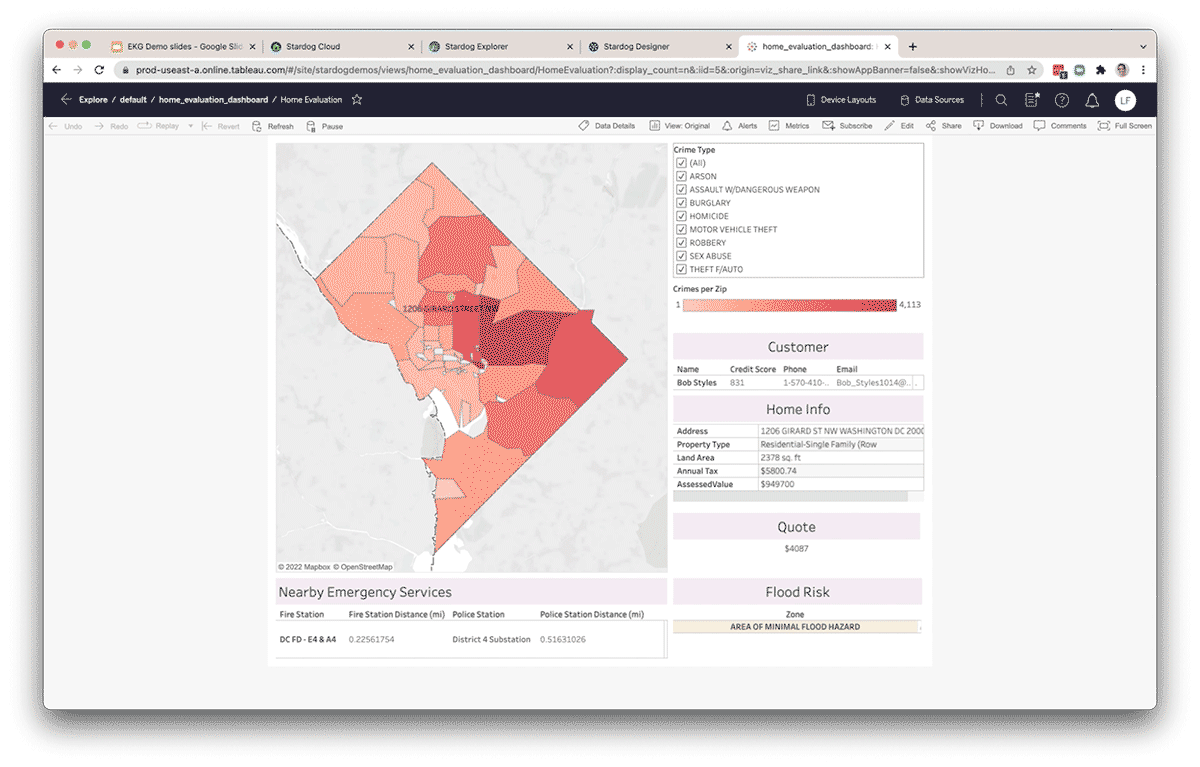
Aumenta la productividad y desarrolla nuevas perspectivas
Al organizar los datos en un Knowledge Graph, los equipos de datos aumentan su productividad al disminuir el tiempo que dedican a manipular datos de fuentes externas en apoyo del análisis de datos ad hoc. Los datos fuera de Databricks pueden federarse a través de la capa de virtualización de Stardog y conectarse a los datos dentro de Databricks. Además, se pueden inferir nuevas relaciones entre entidades sin modelarlas explícitamente en el knowledge graph utilizando técnicas como la inferencia estadística y/o lógica. Dado que Databricks y Stardog funcionan juntos sin problemas, la combinación proporciona una experiencia integral real que simplifica las consultas y el análisis complejos entre dominios. Además, la capa semántica se convierte en una capa viva, compartible y fácil de usar como parte de una base de datos de tejido de datos empresarial, proporcionando conocimiento a nivel empresarial en apoyo de nuevas iniciativas basadas en datos.
Comienza con Databricks y Stardog
En este blog, hemos proporcionado una descripción general de alto nivel de cómo Stardog habilita una capa de datos semántica impulsada por knowledge graph sobre la Plataforma Databricks Lakehouse. Para obtener una descripción general detallada, consulta nuestra demostración detallada. Stardog proporciona a los trabajadores del conocimiento información crítica justo a tiempo sobre un universo conectado de activos de datos para potenciar sus análisis y acelerar el valor de sus inversiones en data lake. Al usar Databricks y Stardog juntos, los equipos de datos y análisis pueden establecer rápidamente un tejido de datos que evoluciona con las crecientes necesidades de tu organización.
Para empezar con Databricks y Stardog, solicita una prueba gratuita a continuación:
https://www.databricks.com/try-databricks
https://cloud.stardog.com/get-started
https://www.stardog.com/learn-stardog/
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.