Delta Live Tables anuncia nuevas capacidades y optimizaciones de rendimiento
DLT anuncia que está desarrollando Enzyme, una optimización de rendimiento diseñada específicamente para cargas de trabajo ETL, y lanza varias capacidades nuevas, incluido el escalado automático mejorado.
por Paul Lappas y Michael Armbrust
Desde la disponibilidad de Delta Live Tables (DLT) en todas las nubes en abril (anuncio), hemos introducido nuevas funciones para facilitar el desarrollo, hemos mejorado la gestión automatizada de la infraestructura, hemos anunciado una nueva capa de optimización llamada Project Enzyme para acelerar el procesamiento ETL y hemos habilitado varias capacidades empresariales y mejoras de UX.
DLT permite a los analistas y ingenieros de datos crear rápidamente pipelines ETL de streaming o batch listos para producción en SQL y Python. DLT simplifica el desarrollo ETL al permitirle definir su pipeline de procesamiento de datos de forma declarativa. DLT comprende las dependencias de su pipeline y automatiza casi todas las complejidades operativas.
Delta Live Tables ha crecido para potenciar casos de uso de ETL en producción en empresas líderes de todo el mundo desde su inicio. DLT es utilizado por más de 1.000 empresas, desde startups hasta grandes corporaciones, incluyendo ADP, Shell, H&R Block, Jumbo, Bread Finance y JLL.
Con DLT, los ingenieros pueden concentrarse en entregar datos en lugar de operar y mantener pipelines y aprovechar las características clave. Hemos habilitado varias capacidades empresariales y mejoras de UX, incluido el soporte para Change Data Capture (CDC) para capturar datos que llegan continuamente de manera eficiente y fácil, y hemos lanzado una vista previa de Enhanced Auto Scaling que proporciona un rendimiento superior para cargas de trabajo de streaming. Veamos las mejoras en detalle:
Facilitar el desarrollo
Hemos ampliado nuestra UI para que sea más fácil gestionar el ciclo de vida completo de ETL.
Mejoras de UX. Hemos ampliado nuestra UI para facilitar la gestión de pipelines DLT, ver errores y proporcionar acceso a los miembros del equipo con ACLs de pipeline enriquecidas. También hemos añadido una UI de observabilidad para ver métricas de calidad de datos en una sola vista, y hemos facilitado la programación de pipelines directamente desde la UI. Más información.
Botón Programar Pipeline. DLT le permite ejecutar pipelines ETL de forma continua o en modo activado. Los pipelines continuos procesan nuevos datos a medida que llegan y son útiles en escenarios donde la latencia de los datos es crítica. Sin embargo, muchos clientes optan por ejecutar pipelines DLT en modo activado para controlar la ejecución del pipeline y los costos más de cerca. Para facilitar la activación de pipelines DLT en un horario recurrente con Databricks Jobs, hemos añadido un botón 'Programar' en la UI de DLT para permitir a los usuarios configurar un horario recurrente con solo unos pocos clics sin salir de la UI de DLT. También puede ver un historial de ejecuciones y navegar rápidamente a los detalles de su trabajo para configurar notificaciones por correo electrónico. Más información.
Change Data Capture (CDC). Con DLT, los ingenieros de datos pueden implementar fácilmente CDC con una nueva API declarativa APPLY CHANGES INTO, ya sea en SQL o Python. Esta nueva capacidad permite a los pipelines ETL detectar fácilmente los cambios en los datos de origen y aplicarlos a los conjuntos de datos en todo el lakehouse. DLT procesa los cambios de datos en Delta Lake de forma incremental, marcando los registros para insertar, actualizar o eliminar al manejar eventos de CDC. Más información.
CDC Slowly Changing Dimensions—Type 2. Al tratar con datos cambiantes (CDC), a menudo necesita actualizar registros para realizar un seguimiento de los datos más recientes. SCD Type 2 es una forma de aplicar actualizaciones a un destino para que se conserven los datos originales. Por ejemplo, si una entidad de usuario en la base de datos se muda a una dirección diferente, podemos almacenar todas las direcciones anteriores de ese usuario. DLT soporta SCD tipo 2 para organizaciones que requieren mantener un rastro de auditoría de los cambios. SCD2 conserva un historial completo de valores. Cuando el valor de un atributo cambia, el registro actual se cierra, se crea un nuevo registro con los valores de datos cambiados, y este nuevo registro se convierte en el registro actual. Más información.
Gestión automatizada de infraestructura
Autoscaling Mejorado (vista previa). Dimensionar clústeres manualmente para un rendimiento óptimo dados los volúmenes de datos cambiantes e impredecibles, como con las cargas de trabajo de streaming, puede ser un desafío y llevar a un aprovisionamiento excesivo. El autoscaling actual del clúster no es consciente de los SLO de streaming y puede no escalar rápidamente incluso si el procesamiento se está quedando atrás de la tasa de llegada de datos, o puede no escalar hacia abajo cuando la carga es baja. DLT emplea un algoritmo de autoscaling mejorado diseñado específicamente para streaming. El Autoscaling Mejorado de DLT optimiza la utilización del clúster al tiempo que garantiza que la latencia general de extremo a extremo se minimice. Lo hace detectando las fluctuaciones de las cargas de trabajo de streaming, incluyendo los datos que esperan ser ingeridos, y aprovisionando la cantidad correcta de recursos necesarios (hasta un límite especificado por el usuario). Además, el Autoscaling Mejorado apagará elegantemente los clústeres cuando la utilización sea baja, garantizando la evacuación de todas las tareas para evitar afectar al pipeline. Como resultado, las cargas de trabajo que utilizan el Autoscaling Mejorado ahorran costos porque se utilizan menos recursos de infraestructura. Más información.
Actualización y Canales de Lanzamiento Automatizados. Los clústeres de Delta Live Tables (DLT) utilizan un runtime DLT basado en Databricks runtime (DBR). Databricks actualiza automáticamente el runtime DLT aproximadamente cada 1-2 meses. DLT actualizará automáticamente el runtime DLT sin requerir la intervención del usuario final y monitorizará la salud del pipeline después de la actualización. Si DLT detecta que el Pipeline DLT no puede iniciarse debido a una actualización del runtime DLT, revertiremos el pipeline a la versión anterior conocida. Puede recibir advertencias tempranas sobre cambios que rompen scripts de inicialización u otro comportamiento de DBR aprovechando los canales DLT para probar la versión de vista previa del runtime DLT y ser notificado automáticamente si hay una regresión. Databricks recomienda usar el canal CURRENT para cargas de trabajo de producción. Más información.
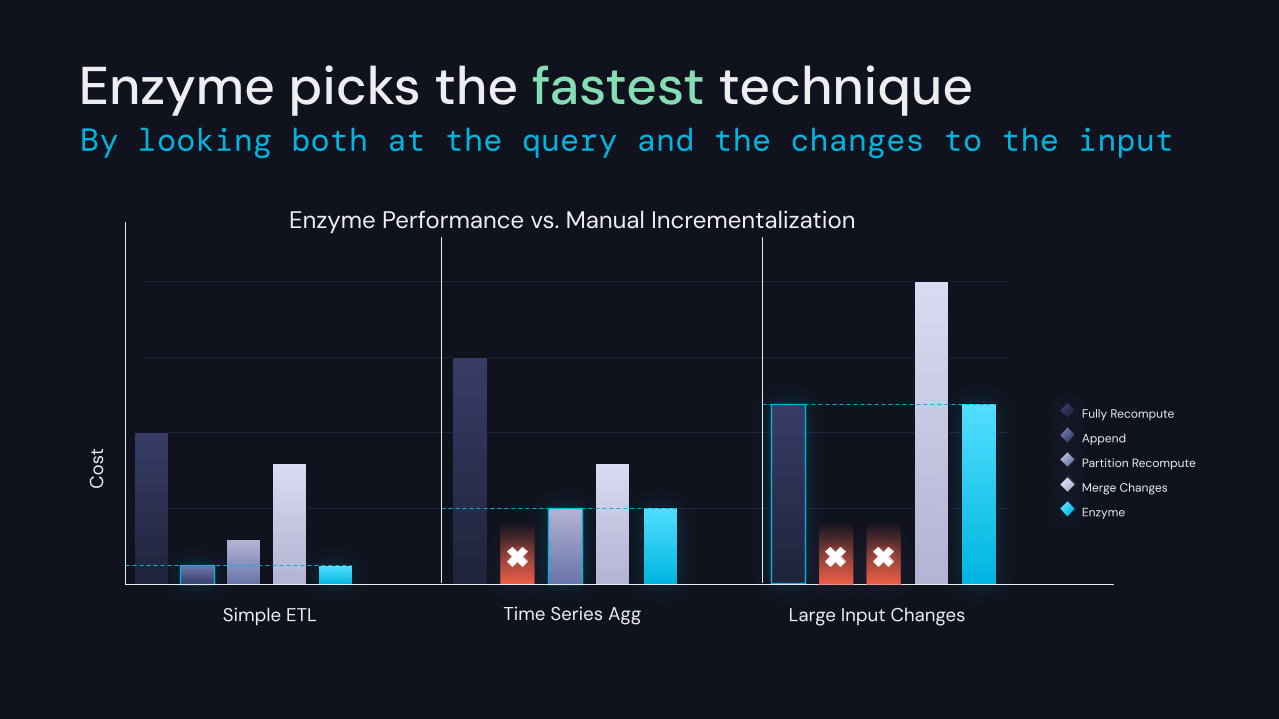
Anunciando Enzyme, una nueva capa de optimización diseñada específicamente para acelerar el proceso de hacer ETL
Transformar datos para prepararlos para el análisis downstream es un requisito previo para la mayoría de las otras cargas de trabajo en la plataforma Databricks. Si bien SQL y DataFrames facilitan relativamente a los usuarios la expresión de sus transformaciones, los datos de entrada cambian constantemente. Esto requiere la recomputación de las tablas producidas por ETL. Recalcular los resultados desde cero es simple, pero a menudo prohibitivo en cuanto a costos a la escala en la que operan muchos de nuestros clientes.
Nos complace anunciar que estamos desarrollando el proyecto Enzyme, una nueva capa de optimización para ETL. Enzyme mantiene eficientemente actualizada una materialización de los resultados de una consulta dada almacenada en una tabla Delta. Utiliza un modelo de costos para elegir entre varias técnicas, incluyendo técnicas utilizadas en vistas materializadas tradicionales, streaming delta-a-delta y patrones ETL manuales comúnmente utilizados por nuestros clientes.
Comience con Delta Live Tables en el Lakehouse
Vea la demostración a continuación para descubrir la facilidad de uso de DLT tanto para ingenieros de datos como para analistas:
Si usted es un cliente de Databricks, simplemente siga la guía para comenzar. Lea las notas de la versión para obtener más información sobre lo que se incluye en esta versión GA. Si no es un cliente de Databricks existente, regístrese para una prueba gratuita, y puede ver nuestros precios detallados de DLT aquí.
Únase a la conversación en la Comunidad Databricks donde compañeros apasionados por los datos están charlando sobre los anuncios y actualizaciones de Data + AI Summit 2022. Aprenda. Conéctese. Celebre.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.