ArcGIS GeoAnalytics Engine en Databricks
Análisis Geoespacial Escalable en un Flujo de Trabajo de Ciencia de Datos
por Kent Marten y Arif Masrur
Esta es una publicación colaborativa de Esri y Databricks. Agradecemos al Ingeniero de Soluciones Senior Arif Masrur, Ph.D. en Esri por sus contribuciones.
Los avances en big data han permitido a las organizaciones de todas las industrias abordar problemas científicos, sociales y de negocio críticos. El desarrollo de infraestructura de big data ayuda a los analistas, ingenieros y científicos de datos a abordar los desafíos centrales de trabajar con big data: volumen, velocidad, veracidad, valor y variedad. Sin embargo, el procesamiento y análisis de datos geoespaciales masivos presenta su propio conjunto de desafíos. Cada día se generan cientos de exabytes de datos con información de ubicación. Estos conjuntos de datos contienen una amplia gama de conexiones y relaciones complejas entre entidades del mundo real, lo que requiere herramientas avanzadas capaces de vincular eficazmente estas relaciones multifacéticas a través de operaciones optimizadas como uniones espaciales y espaciotemporales. Los numerosos formatos geoespaciales que deben ingerirse, verificarse y estandarizarse para un análisis escalado eficiente aumentan la complejidad.
Algunas de las dificultades de trabajar con datos geográficos se abordan con el soporte recientemente anunciado para expresiones H3 integradas en Databricks. Sin embargo, existen muchos casos de uso geoespaciales, algunos de los cuales son más complejos o se centran en la geometría en lugar de en índices de cuadrícula. Los usuarios pueden trabajar con una variedad de herramientas y bibliotecas en la plataforma Databricks mientras aprovechan las numerosas capacidades de Lakehouse.
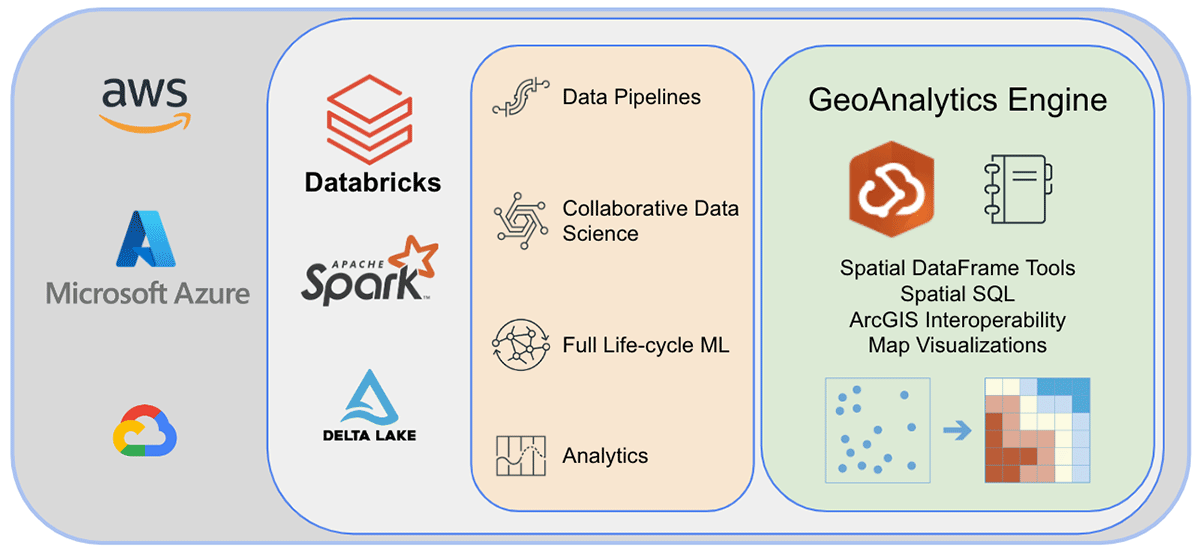
Esri, el proveedor líder mundial de software GIS, ofrece un conjunto completo de herramientas, que incluyen ArcGIS Enterprise, ArcGIS Pro y ArcGIS Online, para resolver los desafíos de geoanálisis mencionados anteriormente. Las organizaciones y los profesionales de datos que utilizan Databricks necesitan acceso a las herramientas donde realizan su trabajo diario fuera del entorno ArcGIS. Es por eso que nos complace anunciar la primera versión de ArcGIS GeoAnalytics Engine (en adelante, GA Engine), que permite a los científicos, ingenieros y analistas de datos analizar sus datos geoespaciales dentro de sus entornos de análisis de big data existentes. Específicamente, este motor es un complemento para Apache Spark™ que extiende los dataframes con procesamiento y análisis espacial muy rápidos, listo para ejecutarse en Databricks.
Beneficios del ArcGIS GeoAnalytics Engine
El GA Engine de Esri permite a los científicos de datos acceder a funciones y herramientas geoanalíticas dentro de su entorno Databricks. Las características clave del GA Engine son:
- Más de 120 funciones SQL espaciales: cree geometrías, pruebe relaciones espaciales y más usando sintaxis de Python o SQL
- Potentes herramientas de análisis: ejecute flujos de trabajo comunes de análisis espaciotemporal y estadístico con solo unas pocas líneas de código
- Indexación espacial automática: realice uniones espaciales optimizadas y otras operaciones de inmediato
- Interoperabilidad con fuentes de datos GIS comunes: cargue y guarde datos de shapefiles, servicios de entidades y mosaicos vectoriales
- Nativo en la nube y nativo de Spark: probado y listo para instalar en Databricks
- Fácil de usar: cree canalizaciones de big data con habilitación espacial utilizando una API intuitiva de Python que extiende PySpark
Funciones SQL y herramientas de análisis
Actualmente, el GA Engine proporciona más de 120 funciones SQL y más de 15 herramientas de análisis espacial que admiten análisis espacial y espaciotemporal avanzado. Esencialmente, las funciones del GA Engine extienden la API de Spark SQL al permitir consultas espaciales en columnas de DataFrame. Estas funciones se pueden llamar con funciones de Python o en una declaraci�ón de consulta PySpark SQL y permiten crear geometrías, operar sobre geometrías, evaluar relaciones espaciales, resumir geometrías y más. A diferencia de las funciones SQL que operan fila por fila utilizando una o dos columnas, las herramientas del GA Engine conocen todas las columnas de un DataFrame y utilizan todas las filas para calcular un resultado si es necesario. Estas amplias herramientas de análisis le permiten administrar, enriquecer, resumir o analizar conjuntos de datos completos.
|
|
El GA Engine es una potente herramienta analítica. Sin embargo, no hay que pasar por alto la facilidad con la que el GA Engine permite trabajar con formatos GIS comunes. La documentación del GA Engine incluye múltiples tutoriales para leer y escribir desde y hacia Shapefiles y Servicios de Entidades. La capacidad de procesar datos geoespaciales utilizando formatos GIS proporciona una gran interoperabilidad entre Databricks y los productos de Esri.
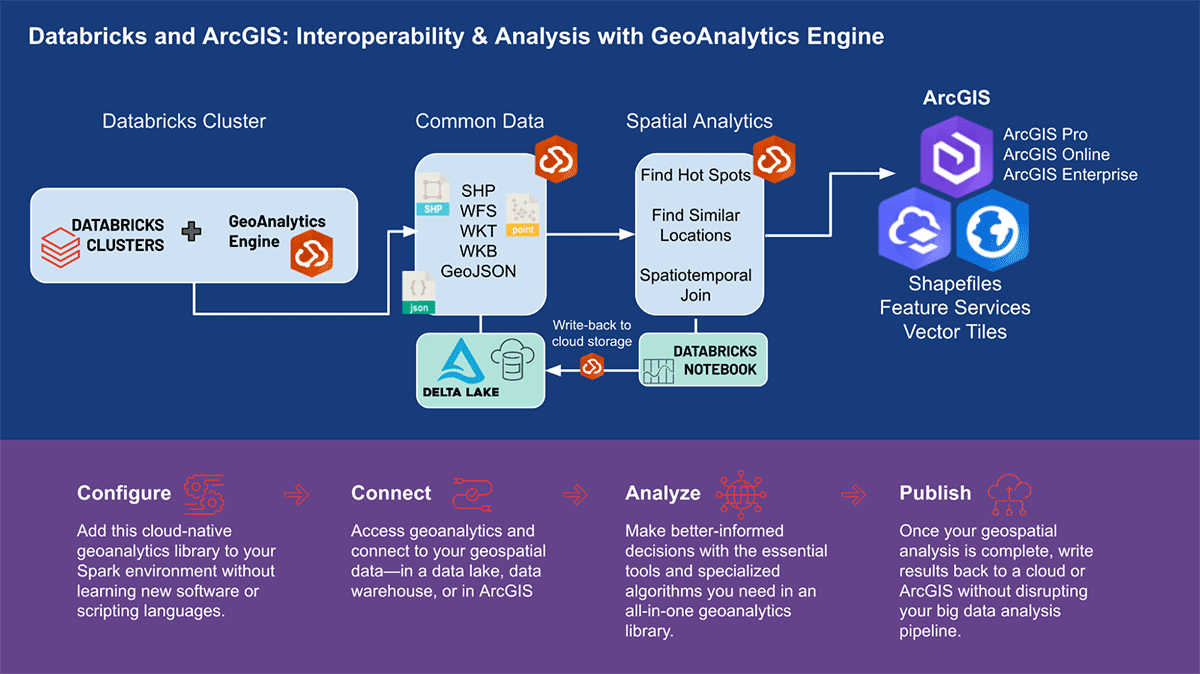
Motor GA para diferentes casos de uso
Repasemos algunos escenarios de uso de diversas industrias para mostrar cómo el GA Engine de ESRI maneja grandes cantidades de datos espaciales. El soporte para análisis espacial y espaciotemporal escalable está diseñado para ayudar a cualquier empresa a tomar decisiones críticas. En tres dominios diversos de análisis de datos: movilidad, transacciones de consumidores y servicio público, nos centraremos en revelar información geográfica.
Análisis de datos de movilidad
Los datos de movilidad están en constante crecimiento y se pueden dividir en dos categorías: movimiento humano y movimiento de vehículos. Los datos de movilidad humana recopilados de usuarios de teléfonos inteligentes en áreas de servicio de telefonía móvil brindan una visión más profunda de los patrones de actividad humana. El movimiento de millones de vehículos conectados proporciona información detallada en tiempo real sobre volúmenes de tráfico direccional, flujos de tráfico, velocidades promedio, congestión y más. Estos conjuntos de datos suelen ser grandes (miles de millones de registros) y complejos (cientos de atributos). Estos datos requieren un análisis espacial y espaciotemporal que va más allá del análisis espacial básico, con acceso inmediato a herramientas estadísticas avanzadas y funciones geoanalíticas especializadas.
Comencemos analizando un ejemplo de movimiento humano basado en datos de Cell Analytics™ de nuestro socio Esri, Ookla®. Ookla® recopila big data sobre el rendimiento del servicio inalámbrico global, la cobertura y las mediciones de señal basadas en la aplicación Speedtest®. Los datos incluyen información sobre el dispositivo de origen, la conectividad de la red móvil, la ubicación y la marca de tiempo. En este caso, trabajamos con un subconjunto de datos que contiene aproximadamente 16 mil millones de registros. Con herramientas no optimizadas para operaciones paralelas en Apache Spark™, leer estos datos de alto volumen y habilitarlos para operaciones espaciotemporales podría incurrir en horas de tiempo de procesamiento. Usando una sola línea de código con GeoAnalytics Engine, estos datos se pueden ingerir desde archivos parquet en segundos.
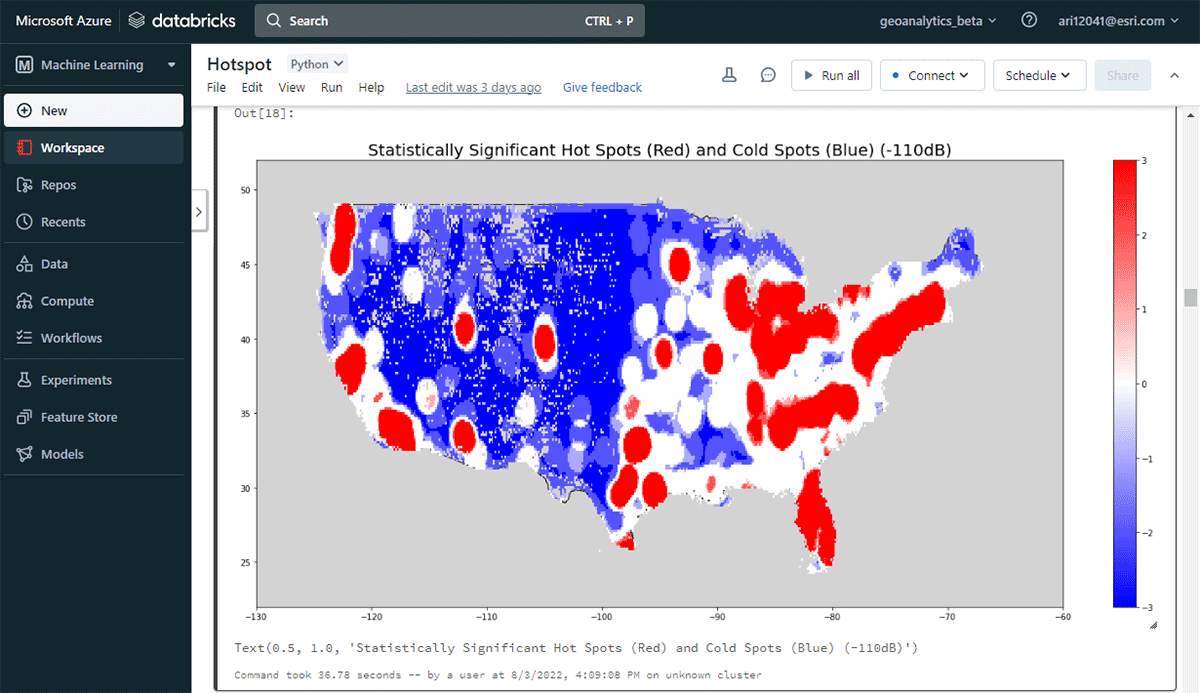
Para comenzar a obtener información útil, profundizaremos en los datos con una pregunta simple: ¿Cuál es el patrón espacial de los dispositivos móviles en los Estados Unidos contiguos? Esto nos permitirá comenzar a caracterizar la presencia y actividad humana. La herramienta FindHotSpots se puede utilizar para identificar clústeres espaciales estadísticamente significativos de valores altos (puntos calientes) y valores bajos (puntos fríos).
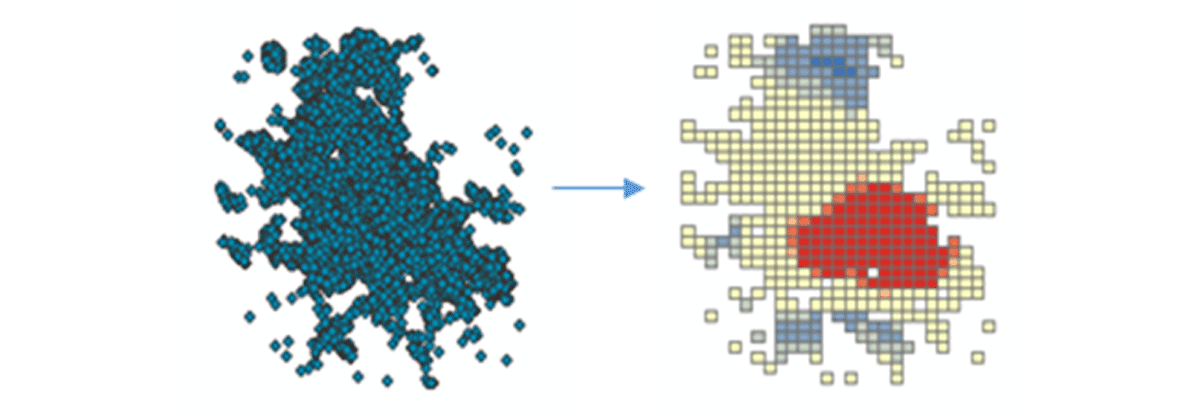
El DataFrame resultante de puntos críticos se visualizó y se le dio estilo usando Matplotlib (Figura 2). Mostró muchos registros de conexiones de dispositivos (rojo) en comparación con ubicaciones con baja densidad de dispositivos conectados (azul) en los Estados Unidos contiguos. Como era de esperar, las principales áreas urbanas indicaron una mayor densidad de dispositivos conectados.
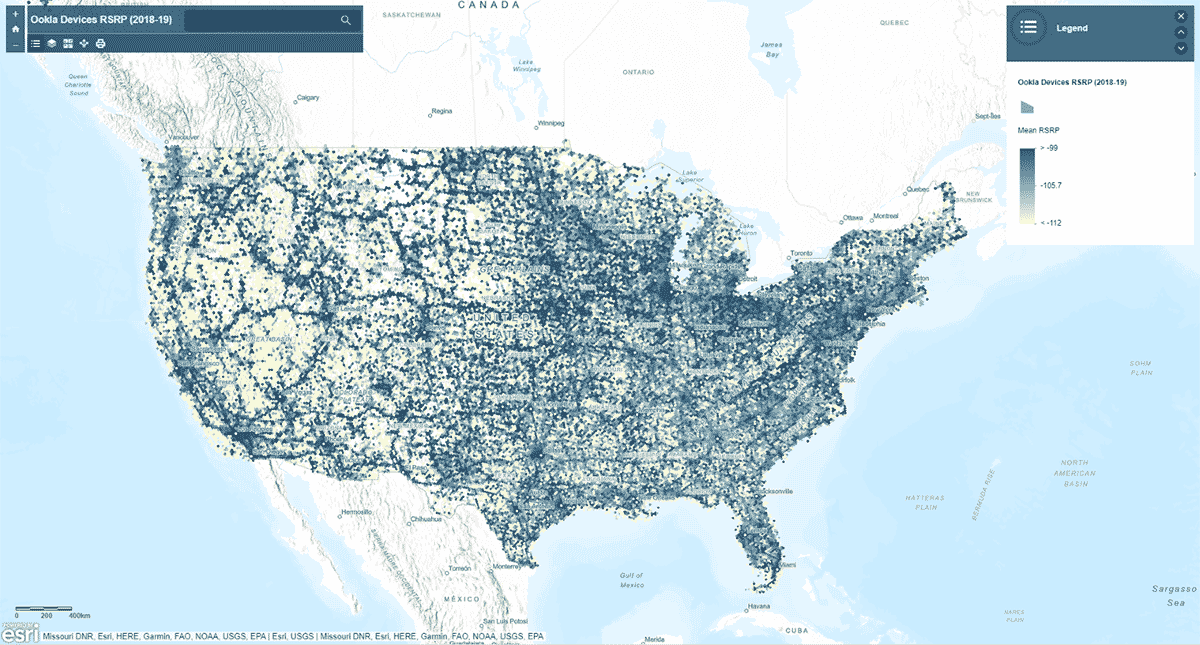
A continuación, preguntamos: ¿la intensidad de la señal de la red móvil sigue un patrón homogéneo en todos los Estados Unidos? Para responder a eso, se utilizó la herramienta AggregatePoints para resumir las observaciones de dispositivos en contenedores hexagonales e identificar áreas con servicio celular particularmente fuerte y particularmente débil (Figura 3). Usamos rsrp (potencia de señal de referencia recibida), un valor utilizado para medir la intensidad de la señal de la red móvil, para calcular la estadística media en contenedores de 15 km. Este análisis iluminó que la intensidad de la señal del servicio celular no es consistente; en cambio, tiende a ser más fuerte a lo largo de las principales redes de carreteras y áreas urbanas.
Además de graficar el resultado usando st_plotting, utilizamos el módulo arcgis, publicamos el DataFrame resultante como una capa de entidades en ArcGIS Online y creamos una visualización interactiva basada en mapas.
Ahora que entendemos los patrones espaciales generales de los dispositivos móviles, ¿cómo podemos obtener una visión más profunda de los patrones de actividad humana? ¿Dónde pasa la gente su tiempo? Para responder a eso, utilizamos FindDwellLocations para buscar dispositivos en Denver, CO que pasaron al menos 5 minutos en la misma ubicación general el 31 de mayo de 2019 (viernes). Este análisis puede ayudarnos a comprender las ubicaciones con actividad más prolongada, es decir, destinos de consumidores, y separarlas de la actividad de viaje general.
El DataFrame result_dwell nos proporciona dispositivos o individuos que permanecieron en diferentes ubicaciones. El mapa de calor de duración de permanencia en la Figura 4 proporciona una visión general de dónde pasa la gente su tiempo en Denver.
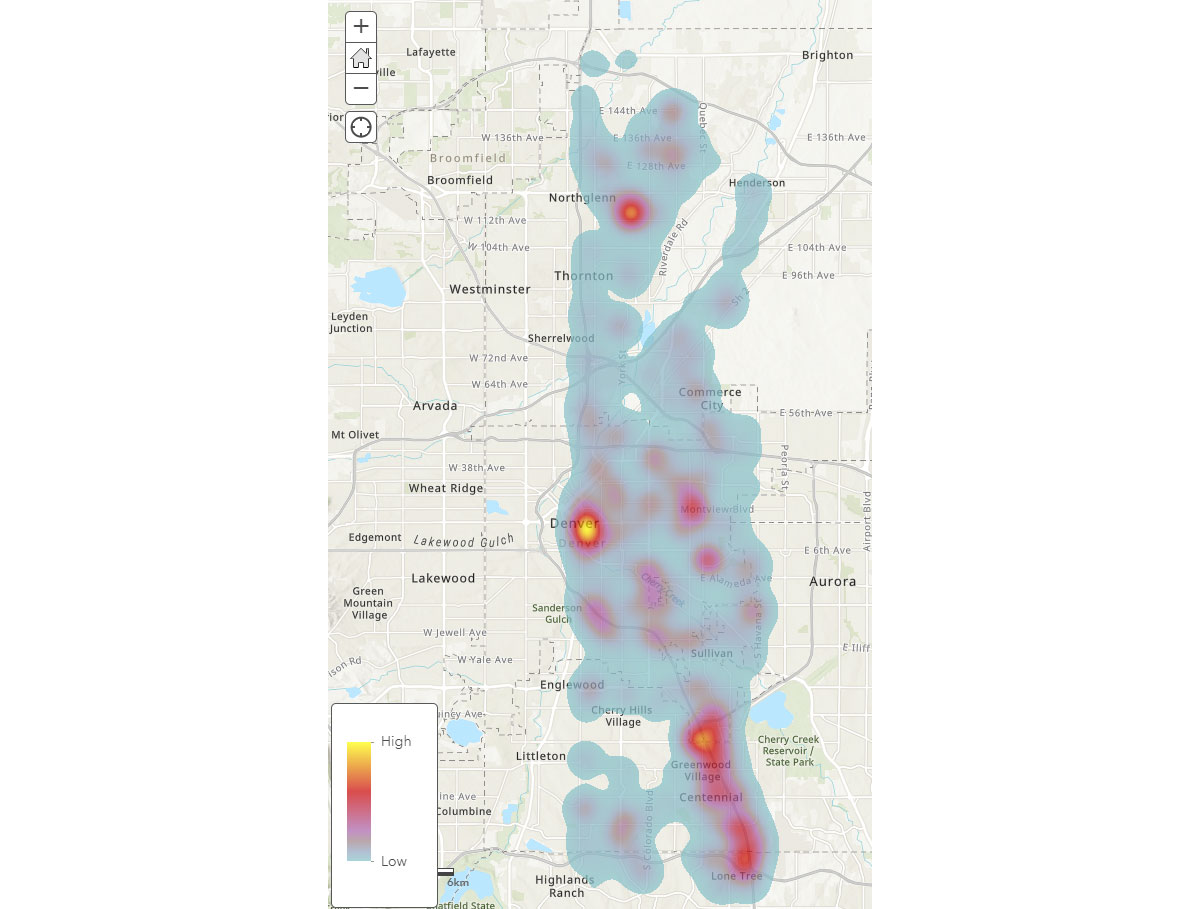
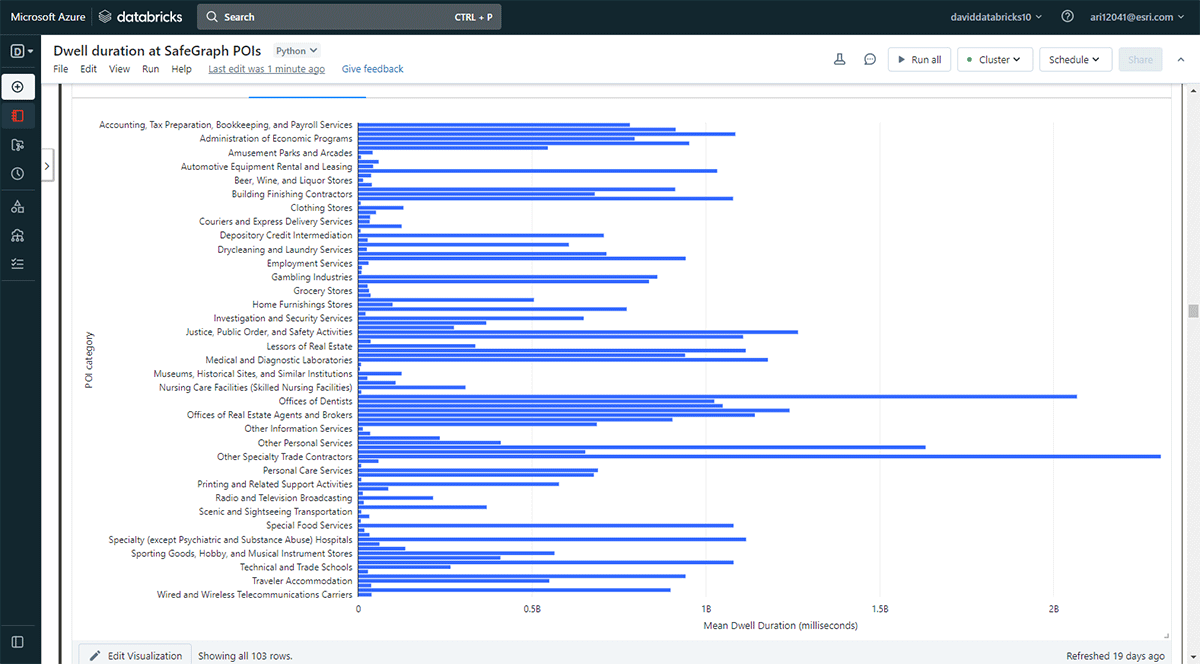
También queríamos explorar las ubicaciones que la gente visita durante períodos más largos. Para lograrlo, utilizamos Overlay para identificar qué huellas de puntos de interés (POI) de los datos de Geometría de SafeGraph Geometry se cruzaron con las ubicaciones de permanencia (del DataFrame result_dwell) el 31 de mayo de 2019. Usando la función groupBy, contamos los tiempos de permanencia de los dispositivos conectados para cada una de las principales categorías de POI. La Figura 5 destaca que algunos POI urbanos en Denver coincidieron con tiempos de permanencia más largos, incluyendo tiendas de suministros de oficina, papelerías y regalos, y oficinas de contratistas comerciales.
Este flujo de trabajo analítico de ejemplo con datos de Cell AnalyticsTM podría aplicarse o reutilizarse para caracterizar las actividades de las personas de manera más específica. Por ejemplo, podríamos utilizar los datos para obtener información sobre el comportamiento del consumidor en torno a las ubicaciones minoristas. ¿A qué restaurantes o cafeterías visitaron estos dispositivos o individuos después de comprar en Walmart o Costco? Además, estos conjuntos de datos pueden ser útiles para gestionar pandemias y desastres naturales. Por ejemplo, ¿siguen las personas las pautas de emergencia de salud pública durante una pandemia? ¿Qué ubicaciones urbanas podrían ser los próximos puntos críticos de COVID-19 o de mala calidad del aire inducida por incendios forestales? ¿Vemos disparidades en las movilidades y actividades humanas debido a la desigualdad de ingresos a una escala geográfica más amplia?
Análisis de datos de transacciones
Los datos de transacciones agregados en puntos de interés contienen información rica sobre cómo y cuándo las personas gastan su dinero en ubicaciones específicas. El gran volumen y la velocidad de estos datos requieren herramientas analíticas espaciales avanzadas para comprender claramente el comportamiento del gasto del consumidor: ¿Cómo difiere el comportamiento del consumidor según la geografía? ¿Qué negocios tienden a co-ubicarse para ser rentables? ¿Qué mercancía compran los consumidores en una tienda física (por ejemplo, Walmart) en comparación con los productos que compran en línea? ¿Cambia el comportamiento del consumidor durante eventos extremos como el COVID-19?
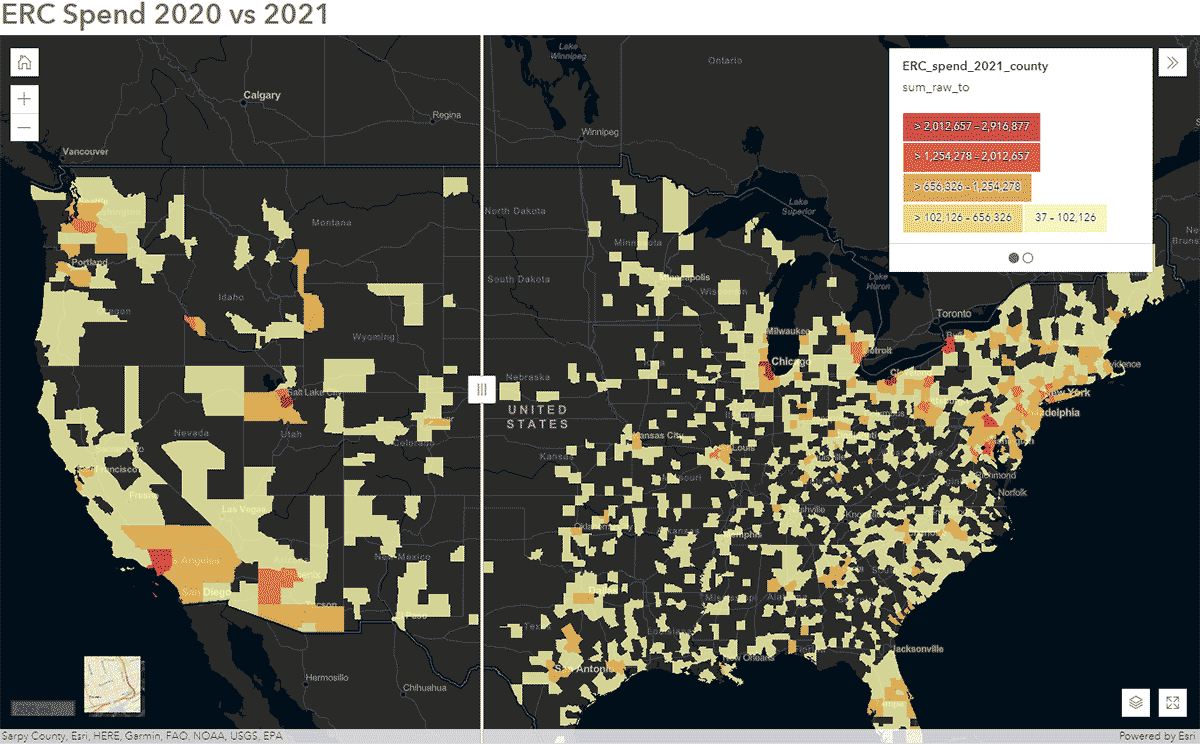
Estas preguntas se pueden responder utilizando los datos de SafeGraph Spend SafeGraph Spend y GeoAnalytics Engine. Por ejemplo, queríamos identificar cómo los patrones de viaje de las personas se vieron afectados durante el COVID-19 en los Estados Unidos. Para lograrlo, analizamos datos nacionales de SafeGraph Spend de 2020 y 2021. A continuación, mostramos el gasto anual (USD) de los consumidores en alquiler de coches para empresas, agregado a los condados de EE. UU. Después de publicar el DataFrame en ArcGIS Online, creamos un mapa interactivo utilizando el widget Swipe de ArcGIS Web AppBuilder para explorar rápidamente qué condados mostraron cambios a lo largo del tiempo (Figura 6).
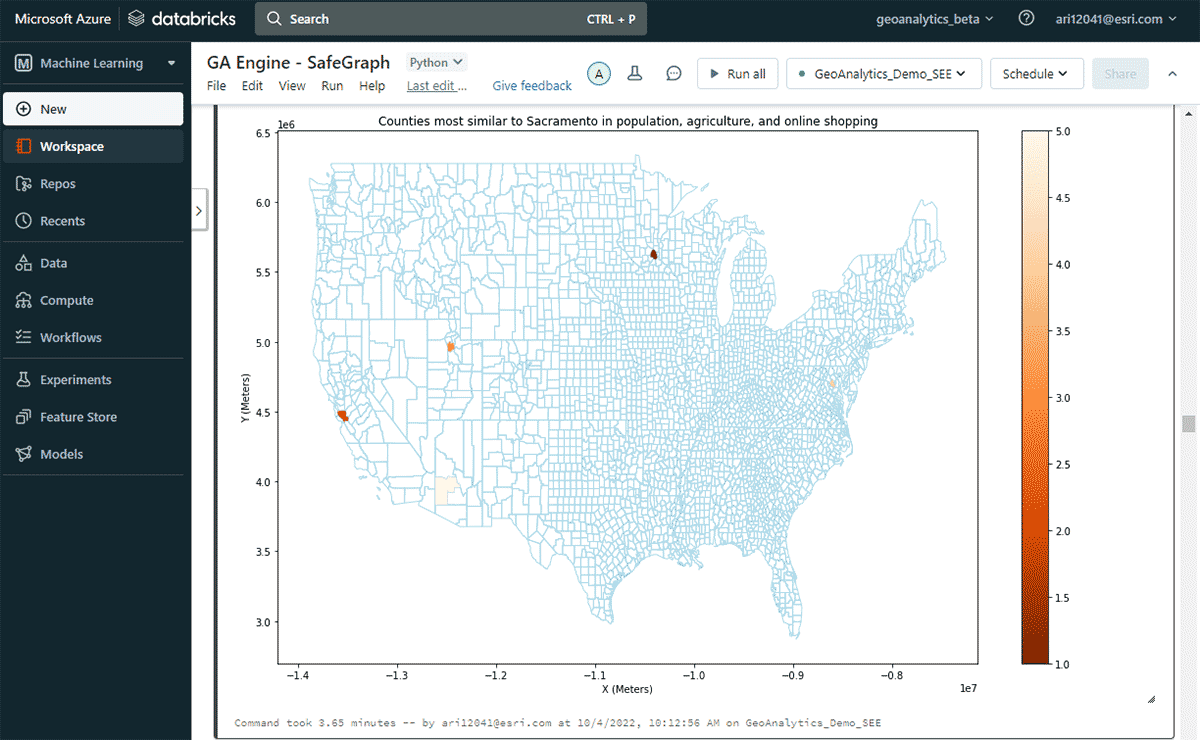
A continuación, exploramos qué condado de EE. UU. tuvo el mayor gasto en línea en un año y otros condados con patrones de gasto de compras en línea similares, considerando las similitudes en la población y los patrones de venta de productos agrícolas. Basándonos en el filtrado de atributos del DataFrame de gastos, identificamos que Sacramento encabezó la lista en gastos de compras en línea en 2020. Para buscar áreas similares, utilizamos la herramienta FindSimilarLocations para identificar los condados que son más similares o disímiles a Sacramento en términos de compras y gastos en línea, pero en relación con las similitudes en población y agricultura (área total de tierras de cultivo y ventas promedio de productos agrícolas) (Figura 7).
Análisis de datos de servicios públicos
Los conjuntos de datos de servicios públicos, como los registros de llamadas al 311, contienen información valiosa sobre los servicios no urgentes proporcionados a los residentes. El monitoreo oportuno y la identificación de patrones espaciotemporales en estos datos pueden ayudar a los gobiernos locales a planificar y asignar recursos para una resolución eficiente de las llamadas al 311.
En este ejemplo, nuestro objetivo fue leer, procesar/limpiar y filtrar rápidamente ~27 millones de registros de solicitudes de servicio 311 de Nueva York de 2010 a febrero de 2022, y luego responder las siguientes preguntas para el área de la ciudad de Nueva York:
- ¿Cuáles son las áreas con los tiempos de respuesta promedio más largos del 311?
- ¿Existen patrones en los tipos de quejas con tiempos de respuesta promedio largos?
Para responder a la primera pregunta, se identificaron las llamadas con los tiempos de respuesta más largos. Luego, los datos se filtraron para incluir registros que fueran más largos que la media más tres desviaciones estándar.
Para responder a la segunda pregunta de encontrar grupos significativos de quejas, aprovechamos la herramienta GroupByProximity para buscar quejas del mismo tipo que cayeron dentro de 500 pies y 5 días una de la otra. Luego filtramos por grupos con más de 10 registros y creamos una envolvente convexa para cada grupo de quejas, lo que será útil para visualizar sus patrones espaciales (Figura 8). Usando st.plot(), un método de trazado ligero incluido con ArcGIS GeoAnalytics Engine, las geometrías almacenadas en un DataFrame se pueden ver instantáneamente.
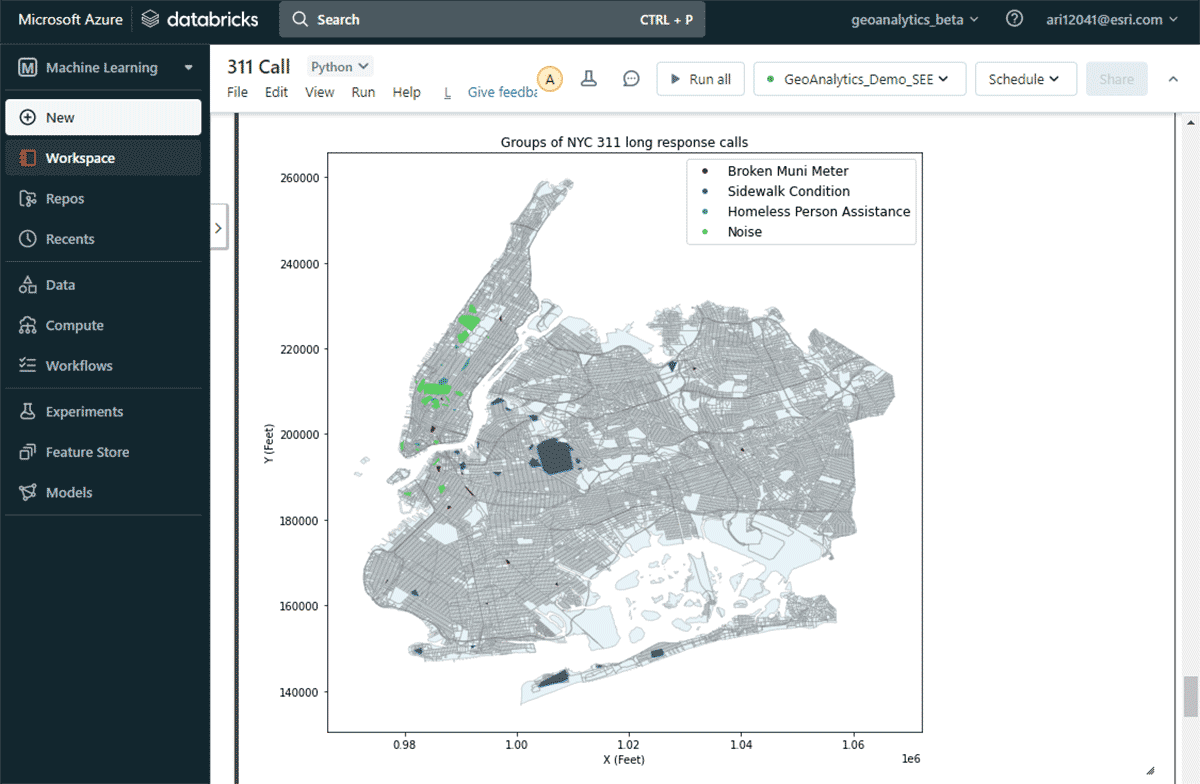
Con este mapa, fue fácil identificar las distribuciones espaciales de los diferentes tipos de quejas en la ciudad de Nueva York. Por ejemplo, hubo un número considerable de quejas por ruido en las áreas media y baja de Manhattan, mientras que las condiciones de las aceras son una preocupación importante en Brooklyn y Queens. Estas rápidas perspectivas basadas en datos pueden ayudar a los responsables de la toma de decisiones a iniciar medidas prácticas.
Benchmarks
El rendimiento es un factor decisivo para muchos clientes que intentan elegir una solución de análisis. Las pruebas de referencia de Esri han demostrado que GA Engine proporciona un rendimiento significativamente mejor al ejecutar análisis espaciales de big data en comparación con los paquetes de código abierto. Las mejoras de rendimiento aumentan a medida que aumenta el tamaño de los datos, por lo que los usuarios verán un rendimiento aún mejor para conjuntos de datos más grandes. Por ejemplo, la siguiente tabla muestra los tiempos de cómputo para una tarea de intersección espacial que une dos conjuntos de datos de entrada (puntos y polígonos) con tamaños variados de hasta millones de registros de datos. Cada escenario de unión se probó en un clúster Databricks de una sola máquina y de varias máquinas.
| Entradas de Intersección Espacial | Tiempo de Cómputo (segundos) | ||
|---|---|---|---|
| Conjunto de Datos Izquierdo | Conjunto de Datos Derecho | Máquina Única | Múltiples Máquinas |
| 50 polígonos | 6K puntos | 6 | 5 |
| 3K polígonos | 6K puntos | 10 | 5 |
| 3K polígonos | 2M puntos | 19 | 9 |
| 3K polígonos | 17M puntos | 46 | 16 |
| 220K polígonos | 17M puntos | 80 | 29 |
| 11M polígonos | 17M puntos | 515 (8.6 min) | 129 (2.1 min) |
| 11M polígonos | 19M puntos | 1,373 (22 min) | 310 (5 min) |
Arquitectura e Instalación
Antes de terminar, echemos un vistazo a la arquitectura del GeoAnalytics Engine y exploremos cómo funciona. Dado que es nativo de la nube y nativo de Spark, podemos usar fácilmente la biblioteca GeoAnalytics en un entorno Spark basado en la nube. La instalación de la implementación de GeoAnalytics Engine en el entorno Databricks requiere una configuración mínima. Cargará el módulo a través de un archivo JAR y luego se ejecutará utilizando los recursos proporcionados por el clúster.
La instalación tiene 2 pasos básicos que se aplican en AWS, Azure y GCP:
- Preparar el espacio de trabajo
- Crear o lanzar un espacio de trabajo Databricks
- Cargar el archivo JAR de GeoAnalytics en DBFS
- Agregar y habilitar un script de inicialización
- Crear un clúster
Después de la instalación, los usuarios analizarán utilizando un notebook de Python adjunto al entorno Spark. Puede acceder instantáneamente a los datos de la plataforma Databricks Lakehouse y realizar análisis. Después del análisis, puede persistir los resultados escribiéndolos de nuevo en su data lake, SQL Warehouse, servicios de BI (Business Intelligence) o ArcGIS.
Próximos pasos
En este blog, hemos presentado el poder de ArcGIS GeoAnalytics Engine en Databricks y hemos demostrado cómo podemos abordar juntos los casos de uso geoespaciales más desafiantes. Consulte este Notebook de Databricks para obtener una referencia detallada de los ejemplos mostrados anteriormente. En el futuro, GeoAnalytics Engine se mejorará con funcionalidad adicional que incluye exportación de GeoJSON, soporte de H3 binning y algoritmos de clustering como K-Nearest Neighbor.
GeoAnalytics Engine funciona con Databricks en Azure, AWS y GCP. Póngase en contacto con sus equipos de cuentas de Databricks y Esri para obtener detalles sobre la implementación de la biblioteca GeoAnalytics en su entorno Databricks preferido. Para obtener más información sobre GeoAnalytics Engine y explorar cómo acceder a este potente producto, visite el sitio web de Esri.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.