Implementación de recuperación ante desastres para un área de trabajo de Databricks
por Ankit Shah y Lorin Dawson
Esta publicación es una continuación de Descripción general, estrategias y evaluación de la recuperación ante desastres y Automatización y herramientas de recuperación ante desastres para un espacio de trabajo de Databricks.
La recuperación ante desastres (DR) se refiere a un conjunto de políticas, herramientas y procedimientos que permiten la recuperación o continuación de la infraestructura y los sistemas tecnológicos críticos después de un desastre natural o provocado por el hombre. A pesar de que los proveedores de servicios en la nube como AWS, Azure, Google Cloud y las empresas SaaS implementan salvaguardas contra puntos únicos de falla, ocurren fallas. La gravedad de la interrupción y su impacto en una organización pueden variar. Para las cargas de trabajo nativas de la nube, un patrón de recuperación ante desastres claro es fundamental.
Configuración de recuperación ante desastres para Databricks
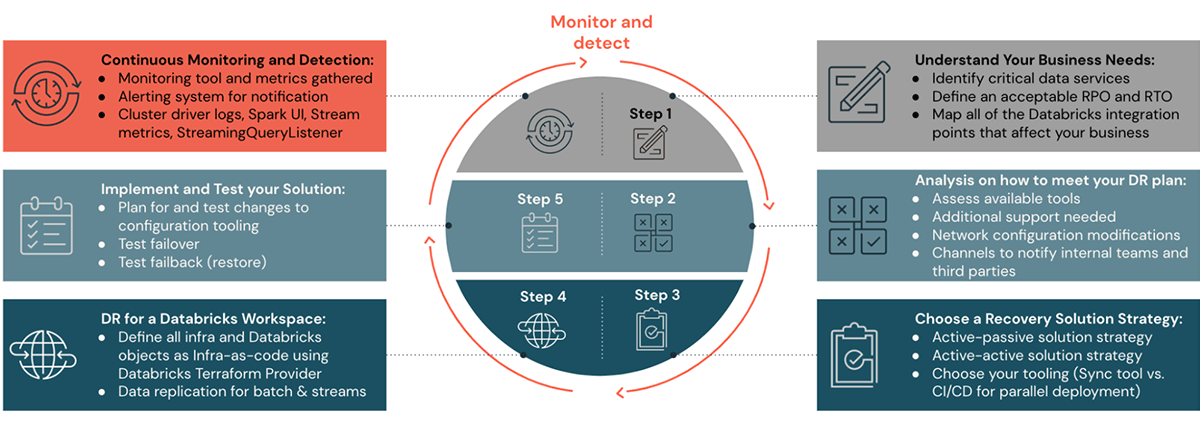
Consulte las publicaciones anteriores del blog en esta serie de blogs de DR para comprender los pasos uno a cuatro sobre cómo planificar, configurar una estrategia de solución de DR y automatizar. En los pasos cinco y seis de esta publicación del blog, veremos cómo monitorear, ejecutar y validar una configuraci�ón de DR.
Solución de recuperación ante desastres
Una implementación típica de Databricks incluye una serie de activos críticos, como el código fuente de los cuadernos, consultas, configuraciones de trabajos y clústeres, que deben recuperarse sin problemas para garantizar una interrupción mínima y la continuidad del servicio para los usuarios finales.
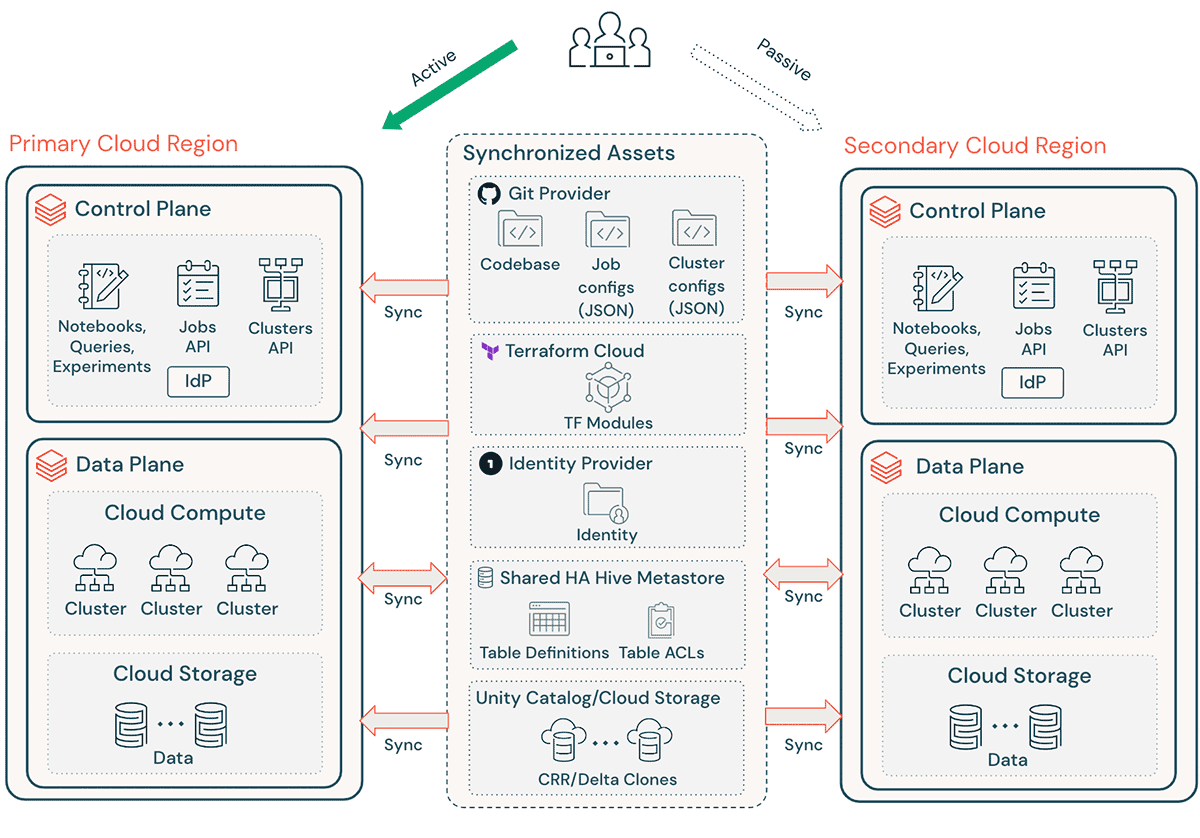
Consideraciones generales de DR:
- Asegúrese de que su arquitectura sea replicable a través de Terraform (TF), lo que permite crear y recrear este entorno en otro lugar.
- Utilice Databricks Repos (AWS | Azure | GCP) para sincronizar cuadernos y código de aplicación en archivos arbitrarios compatibles (AWS | Azure | GCP).
- Utilice Terraform Cloud para activar ejecuciones de TF (planificar y aplicar) para canalizaciones de infraestructura y aplicaciones mientras mantiene el estado
- Replique datos de cuentas de almacenamiento en la nube como Amazon S3, Azure ADLS y GCS a la región de DR. Si está en AWS, también puede almacenar datos utilizando Puntos de acceso multirregión de S3 para que los datos abarquen varios depósitos S3 en diferentes regiones de AWS.
- Las definiciones de clústeres de Databricks pueden contener información específica de la zona de disponibilidad. Utilice el atributo de clúster “auto-az” al ejecutar Databricks en AWS para evitar problemas durante la conmutación por error regional.
- Gestione la deriva de configuración en la Región de DR. Asegúrese de que su infraestructura, datos y configuración estén según sea necesario en la Región de DR.
- Para código y activos de producción, utilice herramientas de CI/CD que envíen cambios a los sistemas de producción simultáneamente a ambas regiones. Por ejemplo, al enviar código y activos de staging/desarrollo a producción, un sistema de CI/CD los hace disponibles en ambas regiones al mismo tiempo.
- Utilice Git para sincronizar archivos TF y la base de código de infraestructura, configuraciones de trabajos y configuraciones de clústeres.
- Será necesario actualizar las configuraciones específicas de la región antes de ejecutar la aplicación de TF en una región secundaria.
Nota: Ciertos servicios como Feature Store, canalizaciones de MLflow, seguimiento de experimentos de ML, administración de modelos y despliegue de modelos no se consideran factibles en este momento para la recuperación ante desastres. Para Structured Streaming y Delta Live Tables, se necesita un despliegue activo-activo para mantener garantías de exactamente una vez, pero la canalización tendrá consistencia eventual entre las dos regiones.
Se pueden encontrar consideraciones generales adicionales en las publicaciones anteriores de esta serie.
Monitoreo y detección
Es crucial saber lo antes posible si sus cargas de trabajo no están en un estado saludable para poder declarar rápidamente un desastre y recuperarse de un incidente. Este tiempo de respuesta, junto con la información adecuada, es fundamental para cumplir con los agresivos objetivos de recuperación. Es fundamental tener en cuenta la detección de incidentes, la notificación, la escalada, el descubrimiento y la declaración en su planificación y objetivos para proporcionar objetivos realistas y alcanzables.
Notificaciones de estado del servicio
La Página de estado de Databricks proporciona una descripción general de todos los servicios principales de Databricks para el plano de control. Puede ver fácilmente el estado de un servicio específico al ver la página de estado. Opcionalmente, también puede suscribirse a actualizaciones de estado en componentes de servicio individuales, lo que envía una alerta cada vez que cambia el estado al que está suscrito.
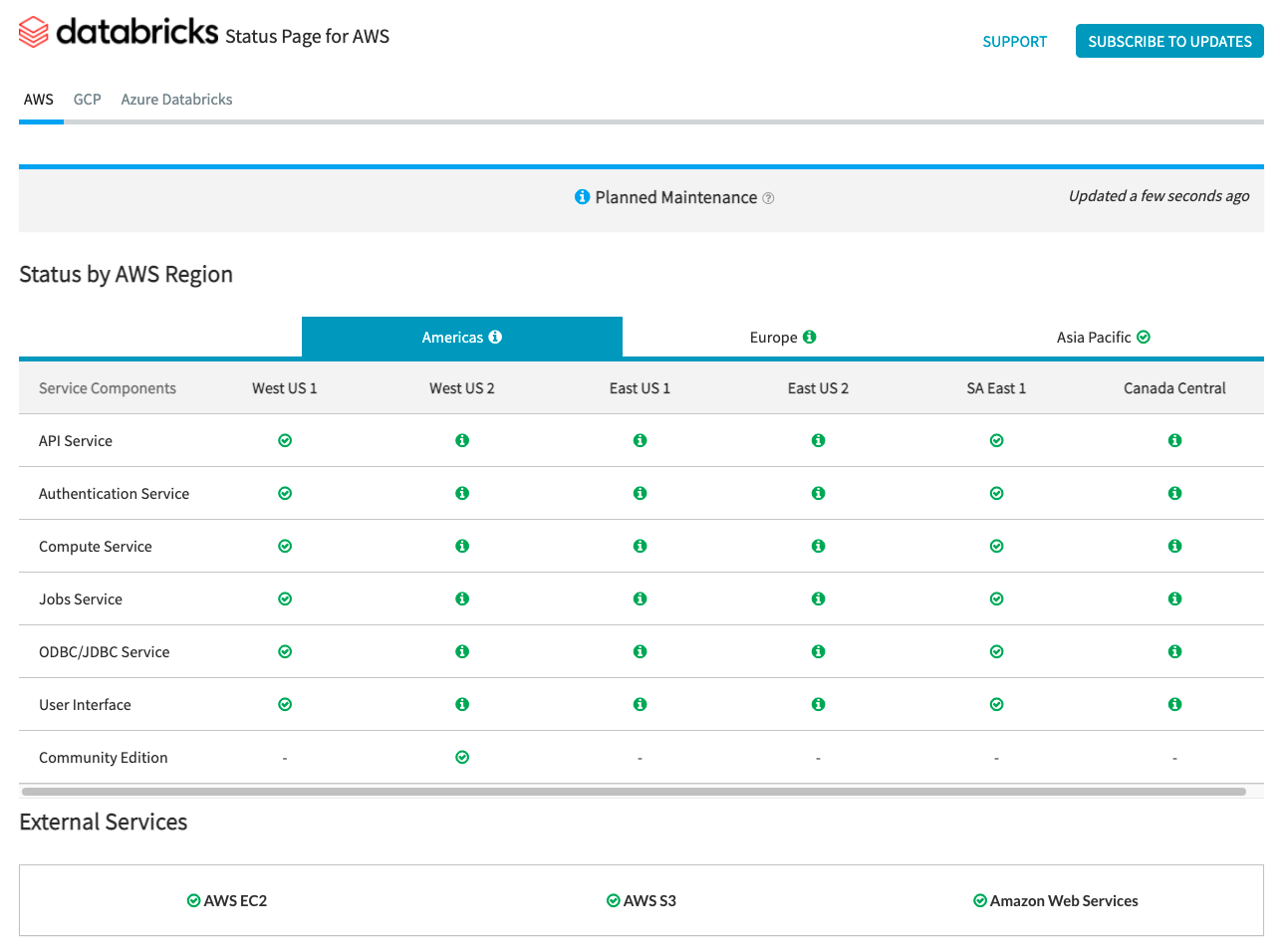
Para verificaciones de estado relacionadas con el plano de datos, se deben utilizar el Panel de estado de AWS Health, la Página de estado de Azure y la Página de estado del servicio de GCP para el monitoreo.
AWS y Azure ofrecen puntos finales de API que las herramientas pueden usar para ingerir y alertar sobre verificaciones de estado.
Monitoreo y alertas de infraestructura
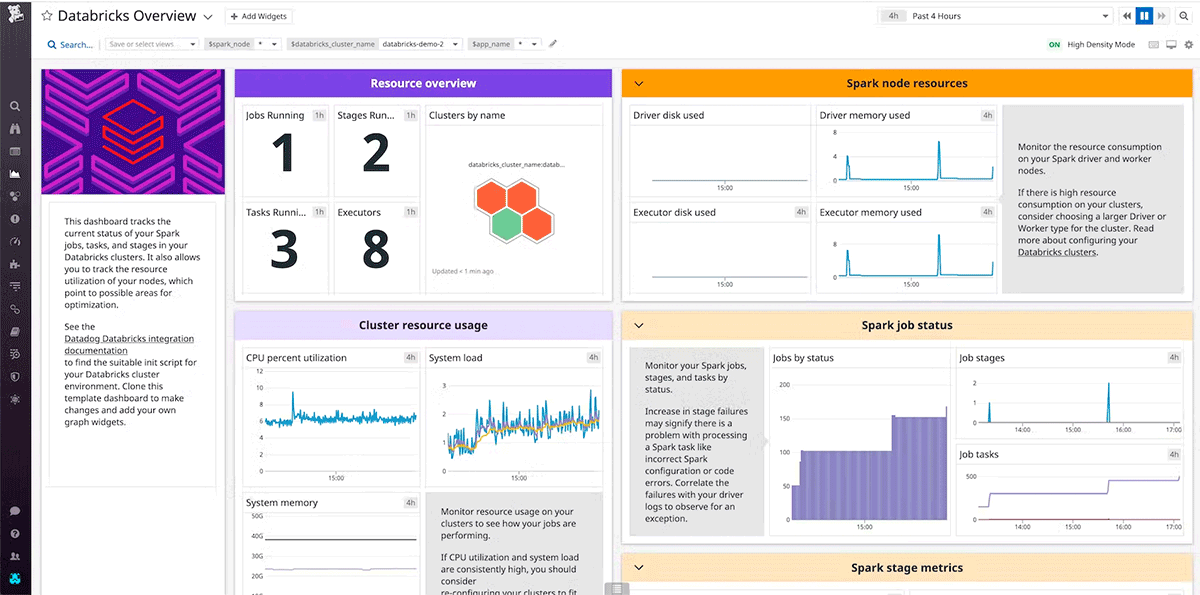
El uso de una herramienta para recopilar y analizar datos de la infraestructura permite a los equipos rastrear el rendimiento a lo largo del tiempo. Esto empodera proactivamente a los equipos para minimizar el tiempo de inactividad y la degradación del servicio en general. Además, el monitoreo a lo largo del tiempo establece una línea de base para el rendimiento máximo que se necesita como referencia para optimizaciones y alertas.
En el contexto de DR, una organización puede no poder esperar alertas de sus proveedores de servicios. Incluso si los requisitos de RTO/RPO son lo suficientemente permisivos como para esperar una alerta del proveedor de servicios, notificar al equipo de soporte del proveedor sobre la degradación del rendimiento con anticipación abrirá una línea de comunicación más temprana.
Tanto DataDog como Dynatrace son herramientas de monitoreo populares que proporcionan integraciones y agentes para AWS, Azure, GCP y clústeres de Databricks.
Verificaciones de estado
Para los requisitos de RTO más estrictos, puede implementar la conmutación por error automática basada en verificaciones de estado de los servicios de Databricks y otros servicios con los que la carga de trabajo interactúa directamente en el Plano de Datos, por ejemplo, almacenes de objetos y servicios de VM de los proveedores de la nube.
Diseñe verificaciones de estado que sean representativas de la experiencia del usuario y se basen en Indicadores Clave de Rendimiento. Las verificaciones de latido superficiales pueden evaluar si el sistema está operativo, es decir, si el clúster se está ejecutando. Mientras que las verificaciones de estado profundas, como las métricas del sistema de la CPU de nodos individuales, el uso del disco y las métricas de Spark en cada etapa activa o partición en caché, van más allá de las verificaciones de latido superficiales para determinar una degradación significativa del rendimiento. Utilice verificaciones de estado profundas basadas en múltiples señales según la funcionalidad y el rendimiento base de la carga de trabajo.
Ten cuidado si automatizas completamente la decisión de conmutar ante desastres utilizando comprobaciones de estado. Si se producen falsos positivos o se activa una alarma, pero la empresa puede absorber el impacto, no es necesario conmutar ante desastres. Una conmutación ante desastres falsa introduce riesgos de disponibilidad y riesgos de corrupción de datos, y es una operación costosa en tiempo. Se recomienda tener un humano en el bucle, como un gestor de incidentes de guardia, para tomar la decisión si se activa una alarma. Una conmutación ante desastres innecesaria puede ser catastrófica, y la revisión adicional ayuda a determinar si la conmutación ante desastres es necesaria.
Ejecución de una Solución de Recuperación ante Desastres
Existen dos escenarios de ejecución a alto nivel para una solución de Recuperación ante Desastres. En el primer escenario, el sitio de Recuperación ante Desastres se considera temporal. Una vez que el servicio se restaura en el sitio principal, la solución debe orquestar una conmutación ante desastres del sitio de Recuperación ante Desastres al sitio principal permanente. Se debe desaconsejar limitar la creación de nuevos artefactos mientras el sitio de Recuperación ante Desastres está activo, ya que es temporal y complica la reversión en este escenario. Por el contrario, en el segundo escenario, el sitio de Recuperación ante Desastres será promovido al nuevo sitio principal, permitiendo a los usuarios reanudar el trabajo más rápido, ya que no necesitan esperar a que se restauren los servicios. Además, este escenario no requiere reversión, pero el sitio principal anterior debe prepararse como el nuevo sitio de Recuperación ante Desastres.
En cualquiera de los escenarios, cada región dentro del alcance de la solución de Recuperación ante Desastres debe soportar todos los servicios requeridos, y debe existir un proceso que valide que el espacio de trabajo de destino está en buenas condiciones operativas como salvaguarda. La validación puede incluir autenticación simulada, consultas automatizadas, llamadas a la API y comprobaciones de ACL.
Conmutación ante desastres
Al activar la conmutación ante desastres al sitio de Recuperación ante Desastres, la solución no puede asumir que la capacidad de apagar el sistema de forma controlada es posible. La solución debe intentar apagar los servicios en ejecución en el sitio principal, registrar el estado de apagado de cada servicio, y luego continuar intentando apagar los servicios sin el estado apropiado en un intervalo de tiempo definido. Esto reduce el riesgo de que los datos se procesen simultáneamente en ambos sitios, el principal y el de Recuperación ante Desastres, minimizando la corrupción de datos y facilitando el proceso de reversión una vez que los servicios se restauran.
Los pasos de alto nivel para activar el sitio de Recuperación ante Desastres incluyen:
- Ejecutar un proceso de apagado en el sitio principal para deshabilitar pools, clústeres y trabajos programados en la región principal para que, si el servicio fallido vuelve a estar en línea, la región principal no comience a procesar nuevos datos.
- Confirmar que la infraestructura y las configuraciones del sitio de Recuperación ante Desastres están actualizadas.
- Comprobar la fecha de los últimos datos sincronizados. Consulte Terminología de la industria de recuperación ante desastres. Los detalles de este paso varían según cómo sincronice los datos y las necesidades empresariales únicas.
- Estabilizar sus fuentes de datos y asegurarse de que todas estén disponibles. Incluya todas las fuentes de datos externas críticas, como almacenamiento de objetos, bases de datos, sistemas de publicación/suscripción, etc.
- Informar a los usuarios de la plataforma.
- Iniciar los pools relevantes (o aumentar el número de instancias inactivas mínimas a los números relevantes).
- Iniciar los clústeres, trabajos y SQL Warehouses relevantes (si no están terminados).
- Cambiar la ejecución concurrente de los trabajos y ejecutar los trabajos relevantes. Estos podrían ser ejecuciones únicas o periódicas.
- Activar los horarios de los trabajos.
- Para cualquier herramienta externa que utilice una URL o nombre de dominio para su espacio de trabajo de Databricks, actualice las configuraciones para tener en cuenta el nuevo plano de control. Por ejemplo, actualice las URL para las API REST y las conexiones JDBC/ODBC. La URL de cara al cliente de la aplicación web de Databricks cambia cuando cambia el plano de control, así que notifique a los usuarios de su organización la nueva URL.
Reversión
El regreso al sitio principal durante la reversión es más fácil de controlar y se puede hacer en una ventana de mantenimiento. La reversión seguirá un plan muy similar al de la conmutación ante desastres, con cuatro excepciones importantes:
- La región de destino será la región principal.
- Dado que la reversión es un proceso controlado, el apagado es una actividad única que no requiere comprobaciones de estado para apagar los servicios a medida que vuelven a estar en línea.
- El sitio de Recuperación ante Desastres deberá restablecerse según sea necesario para futuras conmutaciones ante desastres.
- Cualquier lección aprendida debe incorporarse a la solución de Recuperación ante Desastres y probarse para futuros eventos de desastre.
Conclusión
Pruebe su configuración de recuperación ante desastres con regularidad en condiciones del mundo real para asegurarse de que funciona correctamente. De poco sirve mantener una solución de recuperación ante desastres que no se puede utilizar cuando se necesita. Algunas organizaciones prueban su infraestructura de Recuperación ante Desastres realizando conmutaciones ante desastres y reversiones entre regiones cada pocos meses. Regularmente, la conmutación ante desastres al sitio de Recuperación ante Desastres pone a prueba sus suposiciones y procesos para garantizar que cumplen los requisitos de recuperación en términos de RPO y RTO. Esto también garantiza que las políticas y procedimientos de emergencia de su organización estén actualizados. Pruebe cualquier cambio organizacional que sea necesario en sus procesos y configuraciones en general. Su plan de recuperación ante desastres tiene un impacto en su canal de implementación, así que asegúrese de que su equipo sea consciente de lo que debe mantenerse sincronizado.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.