Ingeniería de Datos Agente con Genie Code y Lakeflow
Genie Code agiliza el desarrollo, la orquestación y el despliegue de pipelines de datos
por Gal Oshri, Camiel Steenstra, Lennart Kats y Joanna Zouhour
- Genie Code es un socio de IA autónomo construido específicamente para datos
- Los ingenieros de datos pueden usar Genie Code directamente dentro de Lakeflow, desde la construcción de pipelines en el Pipeline Editor hasta la orquestación de flujos de trabajo en Lakeflow Jobs
- Genie Code soporta el ciclo de vida completo de la ingeniería de datos, desde el desarrollo y la orquestación hasta la monitorización y depuración, dentro de una única experiencia de agente
Con Genie Code, los ingenieros de datos pueden usar lenguaje natural para generar pipelines de datos listos para producción, orquestarlos con trabajos y depurar fallos. Tareas que antes llevaban semanas (encontrar datos, construir transformaciones, unir trabajos y corregir fallos) ahora se pueden hacer en horas, manteniéndose alineadas con los estándares de gobernanza y operacionales.
A continuación, veremos cómo funciona en la práctica: descubrimiento de datos, construcción de pipelines, orquestación de trabajos y depuración de fallos, todo desde una única conversación.
Construye y orquesta pipelines y trabajos completos, listos para producción, usando lenguaje natural
Genie Code ahora puede llevarte desde la exploración hasta pipelines y trabajos programados en un solo hilo, ayudándote a crearlos y operarlos de extremo a extremo.
Acelera el desarrollo de Lakeflow Spark Declarative Pipelines y simplifica cómo se orquestan y ejecutan los pipelines y notebooks a través de Lakeflow Jobs. Genie Code entiende el contexto de tu pipeline y trabajo, accediendo al código, la configuración y los resultados de ejecución.
Genie Code ayuda en las etapas clave del ciclo de vida de la ingeniería de datos:
- Busca en activos de datos, no solo en código: Genie Code utiliza popularidad, linaje, ejemplos de código y metadatos de Unity Catalog para identificar los conjuntos de datos más relevantes para tu tarea. Por ejemplo, puedes pedirle a Genie Code que explique cómo se relacionan las tablas o que rastree cómo fluyen los datos a través de un pipeline. En SiriusXM, los equipos usan Genie Code para entender las relaciones de tablas más rápidamente.
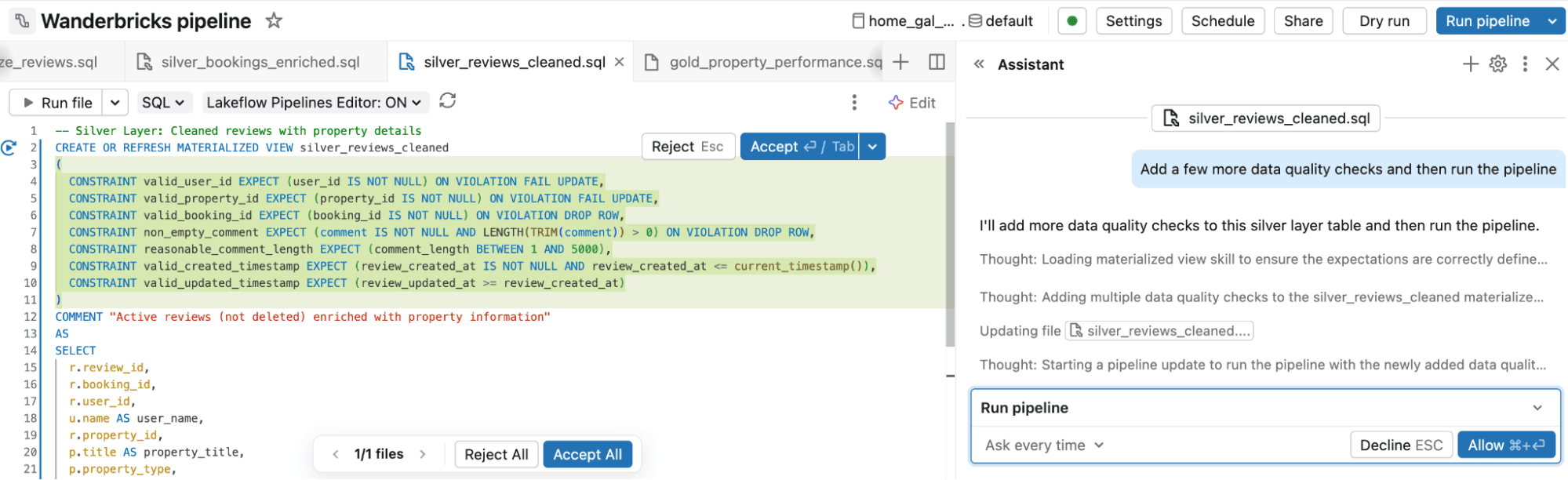
- Construye y modifica pipelines: Empieza describiendo el pipeline que deseas en lenguaje natural, como un pipeline de detección de fraude construido sobre una arquitectura medallion. Genie Code genera un Spark Declarative Pipeline con capas Bronze, Silver y Gold, incluyendo fuentes, transformaciones, expectativas de calidad de datos y salidas. A partir de ahí, puedes solicitar cambios, revisar las diferencias propuestas, y ejecutar y probar el pipeline.
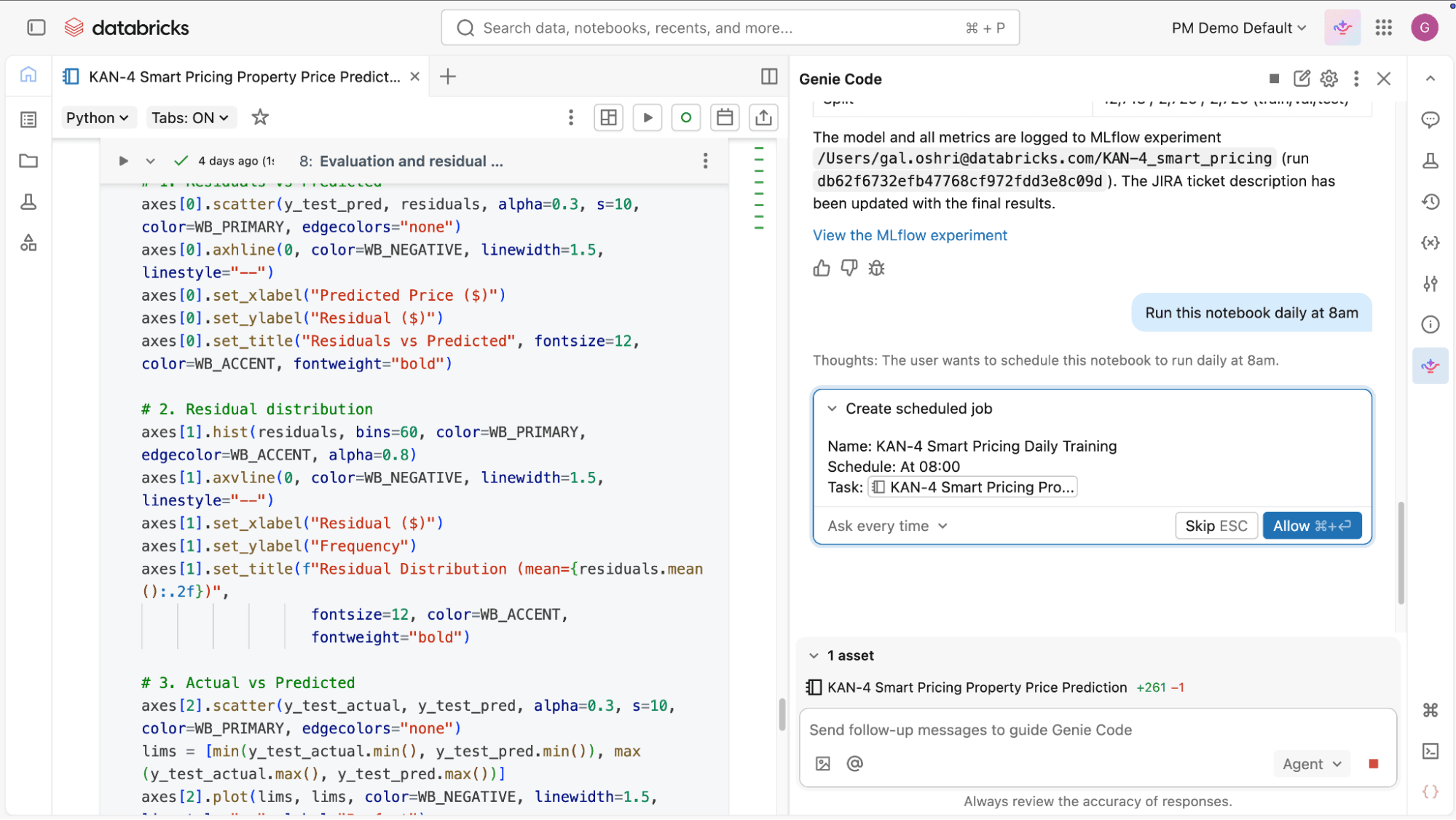
- Define y orquesta trabajos: No es necesario definir y mantener manualmente la lógica de orquestación. Describes el trabajo que deseas, incluyendo tareas, dependencias y programación. Genie Code lo configura por ti, y luego ayuda a modificar, depurar y corregir problemas de orquestación en lenguaje natural.
- Extiende y evoluciona flujos de trabajo existentes: A medida que cambian los requisitos, Genie Code te ayuda a actualizar pipelines y trabajos con nuevos conjuntos de datos y transformaciones. Entiende la estructura actual y los resultados de tus pipelines, y puede extenderlos escribiendo flujos AutoCDC para captura de datos de cambios, configurando Auto Loader, aplicando expectativas de calidad de datos y siguiendo la arquitectura medallion.
- Adopta las mejores prácticas con Declarative Automation Bundles (DABs): Genie Code puede trabajar directamente dentro de tus proyectos DABs existentes: añadiendo recursos, actualizando configuraciones, validando bundles y desplegando a tus destinos. Así puedes adoptar mejores prácticas de ingeniería de software como control de código fuente, pruebas y CI/CD para tus proyectos de datos sin escribir YAML manualmente.
- Trabaja más rápido sin bajar los estándares: Estas capacidades reducen el esfuerzo manual mientras mantienen los flujos de trabajo alineados con los requisitos empresariales. Los pipelines permanecen gobernados a través de Unity Catalog y siguen patrones establecidos para el rendimiento y la calidad de los datos, mientras que los trabajos heredan una configuración consistente para la programación, reintentos y dependencias. Los ingenieros de datos mantienen el control, pero dedican menos tiempo a tareas repetitivas.
Monitoriza, diagnostica y depura pipelines y trabajos
- Comprende y mejora el comportamiento del pipeline: Genie Code puede inspeccionar conjuntos de datos y salidas de pipelines para ayudarte a entender un pipeline de extremo a extremo. Por ejemplo, puede resumir transformaciones, rastrear cómo fluyen los datos a tablas descendentes y resaltar cambios inesperados en recuentos de filas o esquemas.
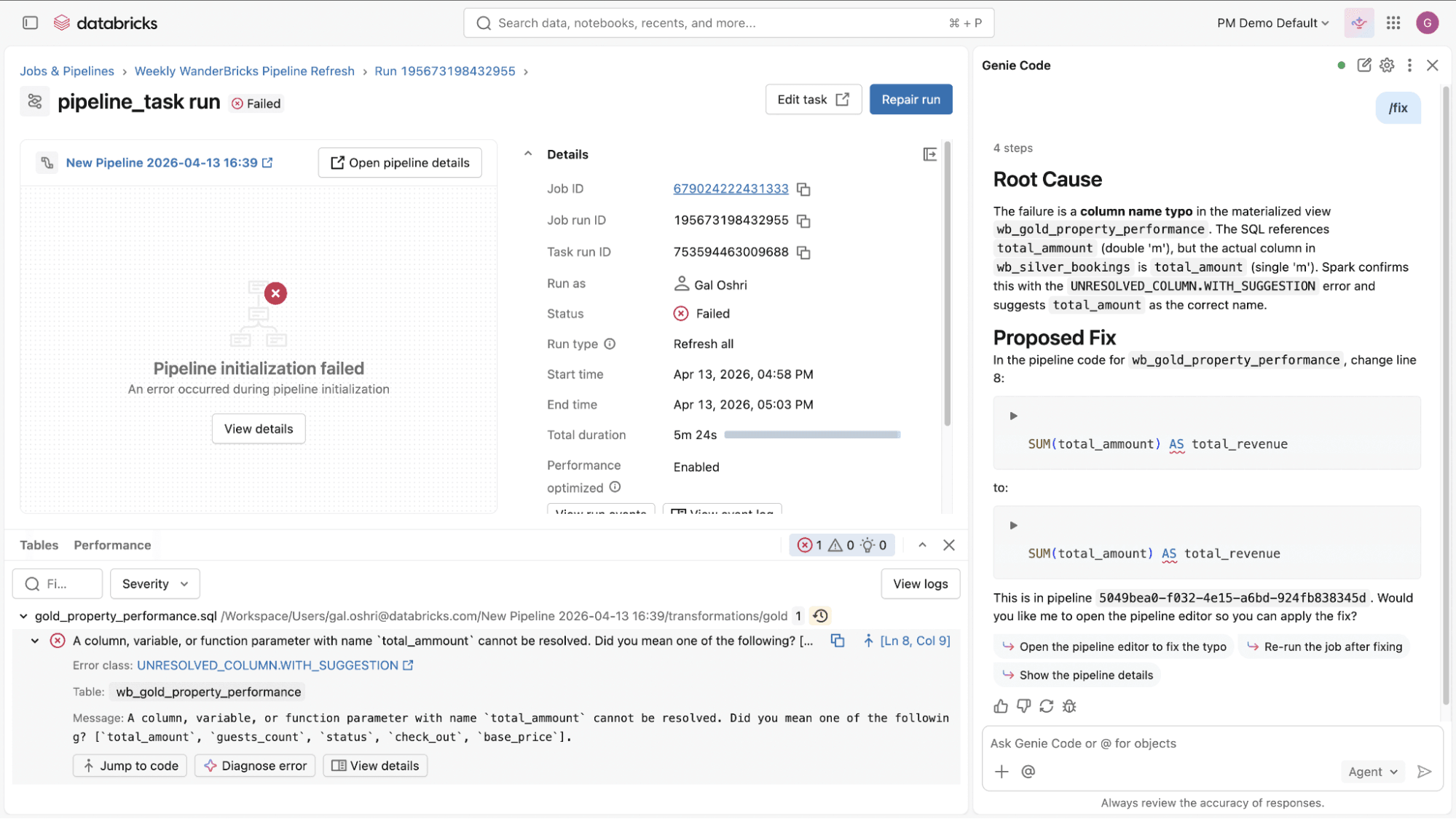
- Depura y diagnostica fallos de trabajos y pipelines: Cuando un pipeline o trabajo falla, Genie Code te ayuda a resolver el problema. Analiza errores, propone actualizaciones en los archivos relevantes y te muestra las diferencias antes de aplicar cualquier cambio. Puedes revisar cada actualización y decidir qué avanza. Esto convierte ciclos de depuración largos y manuales en iteraciones guiadas más rápidas.
- Extiende y personaliza Genie Code: Genie Code no se limita a las capacidades integradas. Los equipos pueden extenderlo con instrucciones personalizadas, habilidades de agente e integrar sistemas externos a través de servidores MCP, permitiendo que Genie Code opere con lógica específica del dominio, herramientas internas y flujos de trabajo personalizados. Esto asegura que Genie Code se adapte a tu entorno y conocimiento del dominio.
¿Qué sigue?
Más capacidades llegarán para extender Genie Code a través de pipelines, trabajos y la plataforma en general. Una característica emocionante en el horizonte son las cargas de trabajo optimizadas por IA. En el futuro, puedes permitir que Genie Code también se ejecute en segundo plano para mantener tu plataforma funcionando eficientemente, para que puedas delegar esas tareas repetitivas y que consumen mucho tiempo. Esto incluye responder a fallos de trabajos y gestionar actualizaciones rutinarias, pero también ajustar automáticamente el uso de clústeres.
¿Curioso por saber más sobre estas actualizaciones y mejores prácticas? ¡Asegúrate de registrarte para Data+AI Summit donde tenemos cientos de sesiones que cubren Genie Code, Lakeflow y mucho más!
Prueba las capacidades de ingeniería de datos de Genie Code
Abre Genie Code en modo agente y pídele que te ayude a construir o actualizar tus pipelines y trabajos. Consulta la demo para más detalles.
Revisa la documentación para aprender más.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.