Simplificación de los pipelines de datos confiables
Simplifica el ETL por lotes y de transmisión con confiabilidad automatizada y calidad de datos i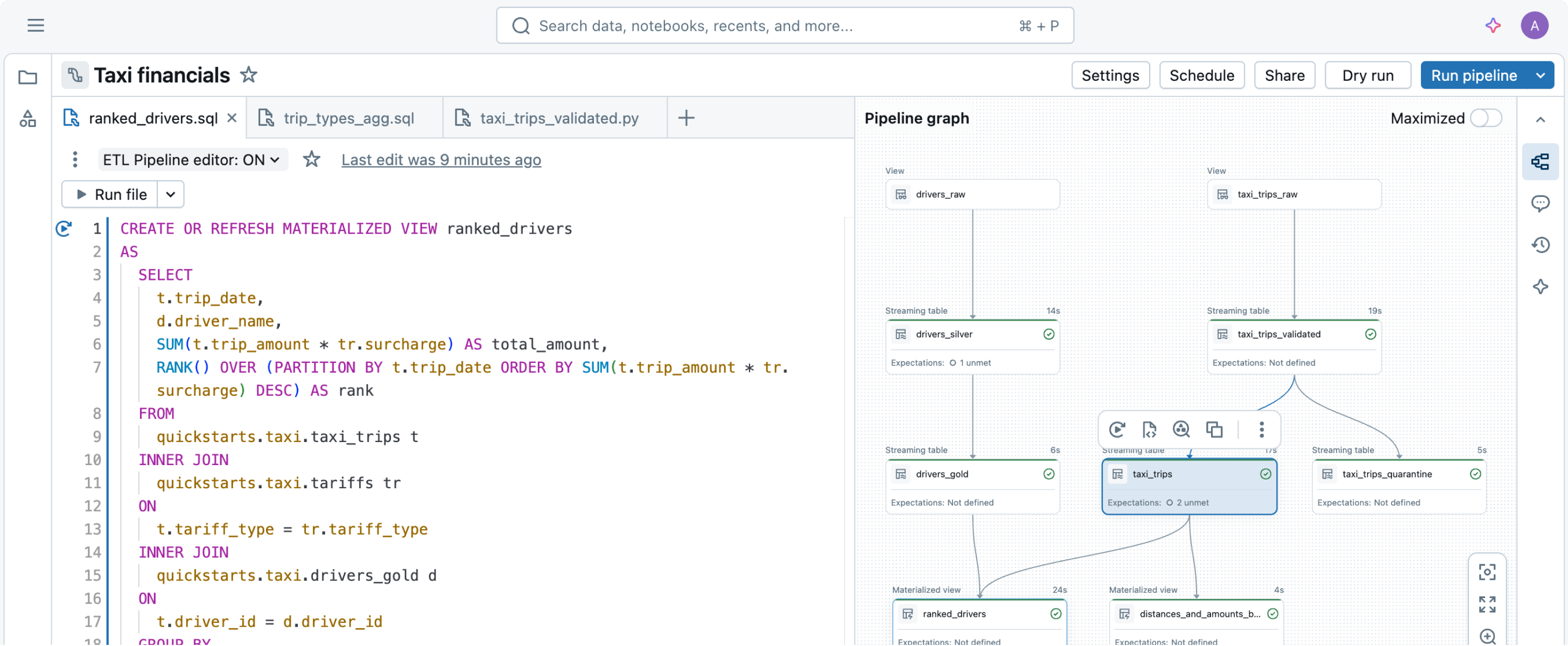
LOS MEJORES EQUIPOS TRIUNFAN CON PIPELINES DE DATOS INTELIGENTES
Mejores prácticas de pipelines de datos codificadas
Solo tienes que declarar las transformaciones de datos que necesitas, y deja que Spark Declarative Pipelines se encargue del resto.Ingesta eficiente
La creación de pipelines de datos listos para producción comienza con la ingesta. Spark Declarative Pipelines permite una ingesta eficiente para ingenieros de datos, desarrolladores de Python, científicos de datos y analistas de SQL. Carga datos desde cualquier fuente compatible con Apache Spark™ en Databricks, ya sea por lotes, transmisión o CDC.
Transformación inteligente
A partir de unas pocas líneas de código, Spark Declarative Pipelines determina la manera más eficiente de construir y ejecutar tus pipelines de datos por lotes o de transmisión, al optimizar automáticamente el costo o el rendimiento, al tiempo que se minimiza la complejidad.
Operaciones automatizadas
Spark Declarative Pipelines simplifica el desarrollo de pipelines al codificar las mejores prácticas listas para usar, automatizar la gestión de dependencias, el escalado y la recuperación, las reglas de calidad de datos y más. Con Spark Declarative Pipelines, los ingenieros pueden centrarse en proporcionar datos de alta calidad en lugar de operar y mantener la infraestructura de los pipelines.
Diseñado para simplificar el pipeline de datos
Diseñar y operar pipelines de datos puede ser difícil, pero no tiene por qué serlo. Spark Declarative Pipelines está diseñado para ofrecer una simplicidad poderosa, de modo que puedas realizar un ETL robusto con tan solo unas pocas líneas de código.Usa Genie Code para automatizar las cargas de trabajo de ETL, optimizar las consultas y crear pipelines a través de conversaciones naturales.
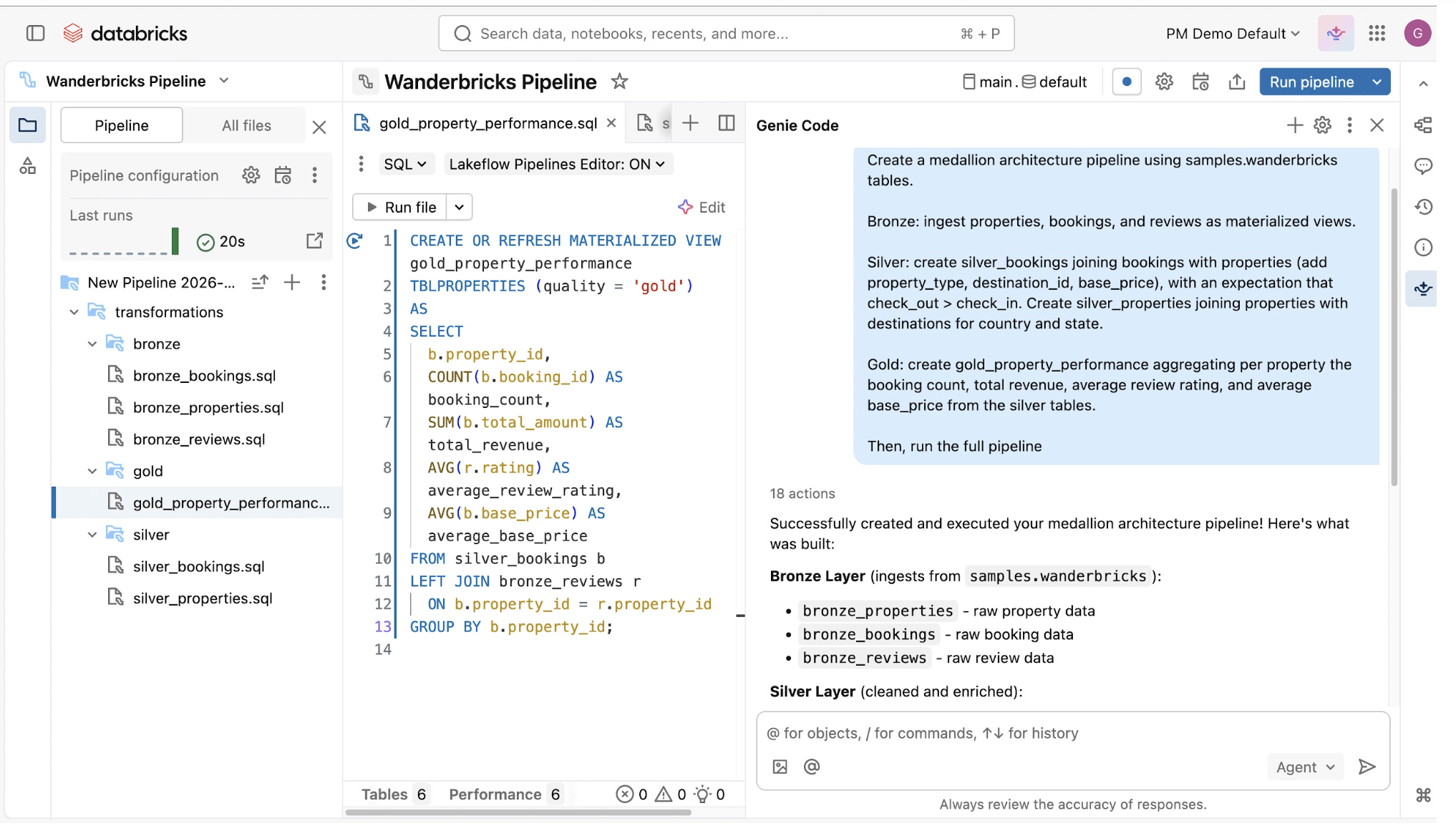
Al aprovechar la API unificada de Spark para el procesamiento por lotes y de transmisión, Spark Declarative Pipelines te permite alternar fácilmente entre los modos de procesamiento.

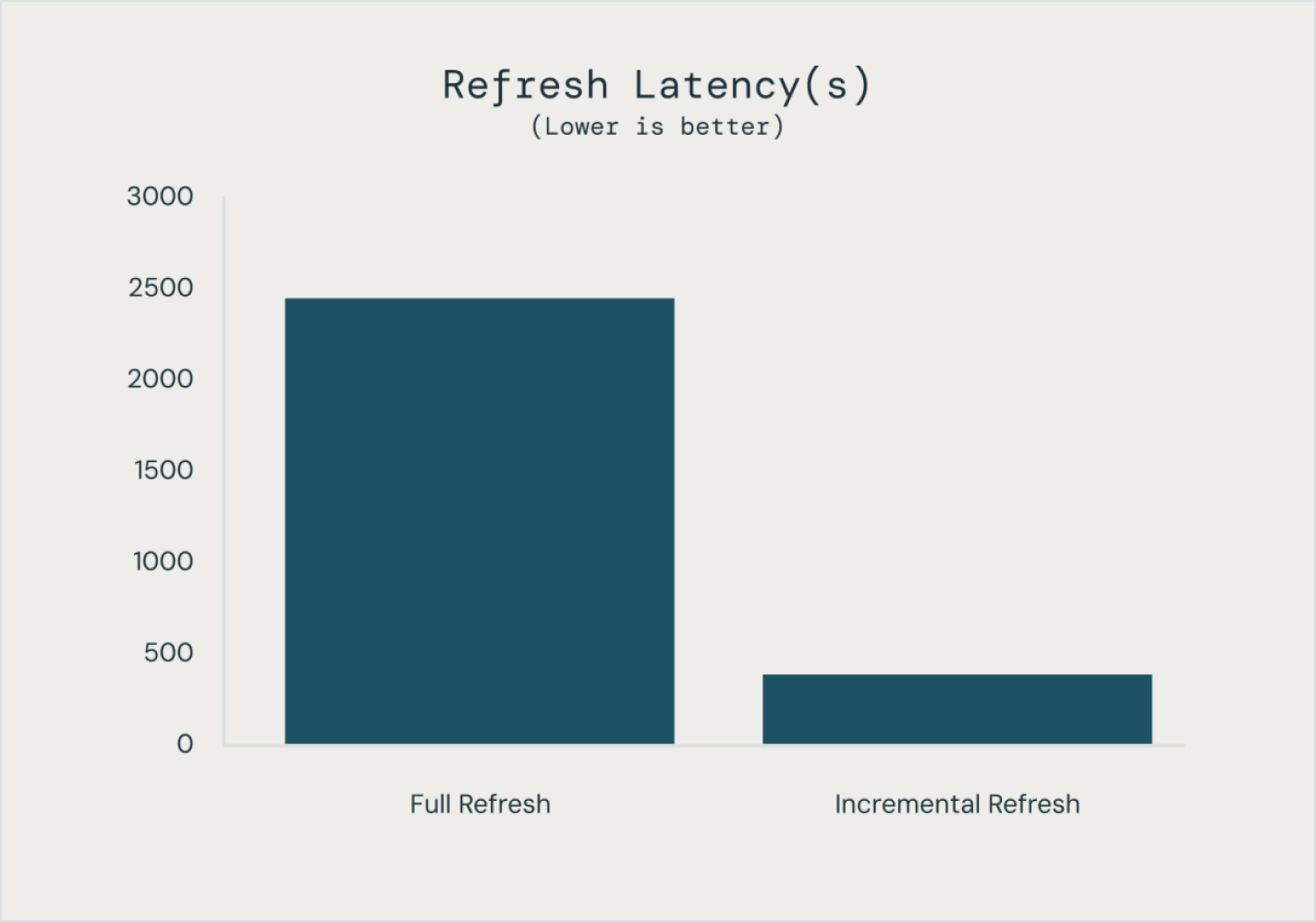
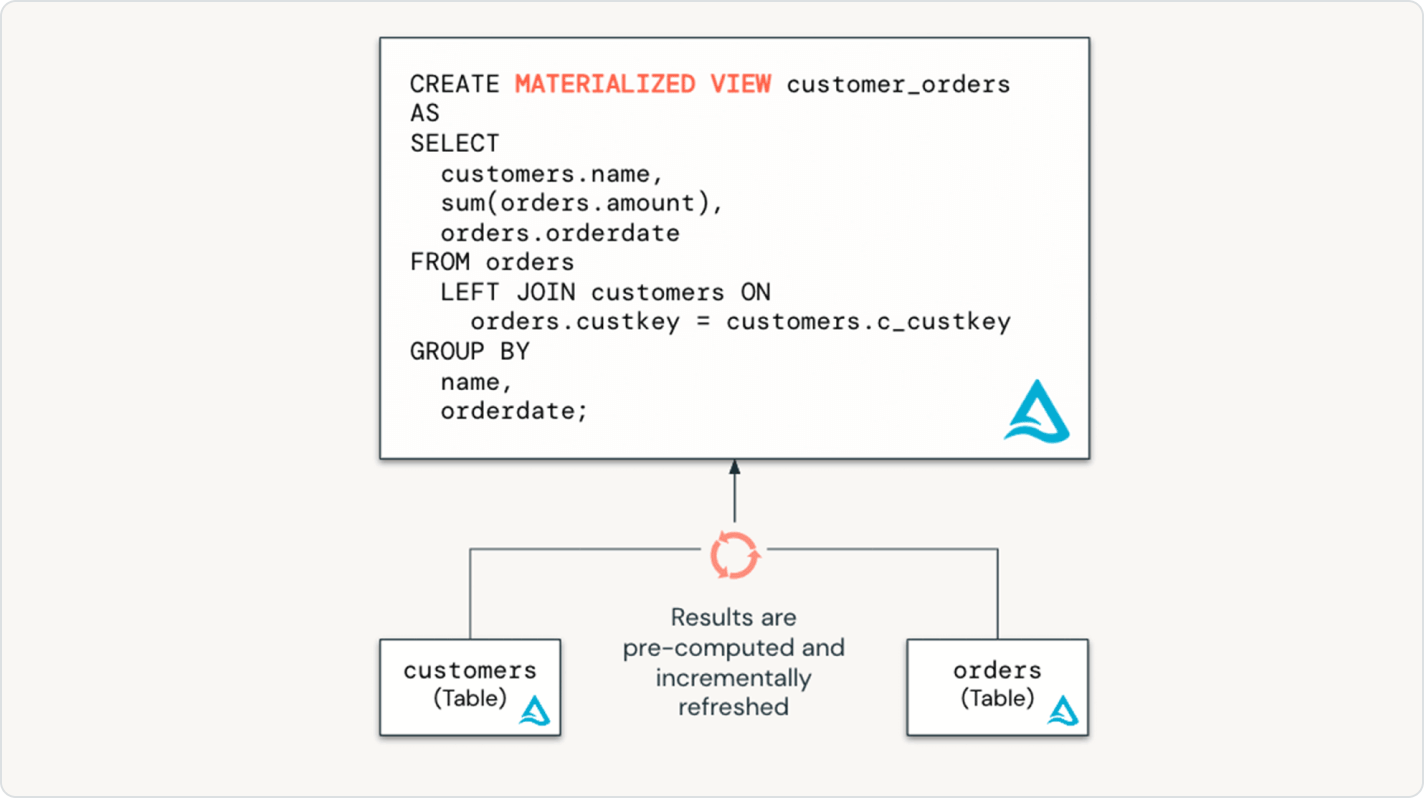
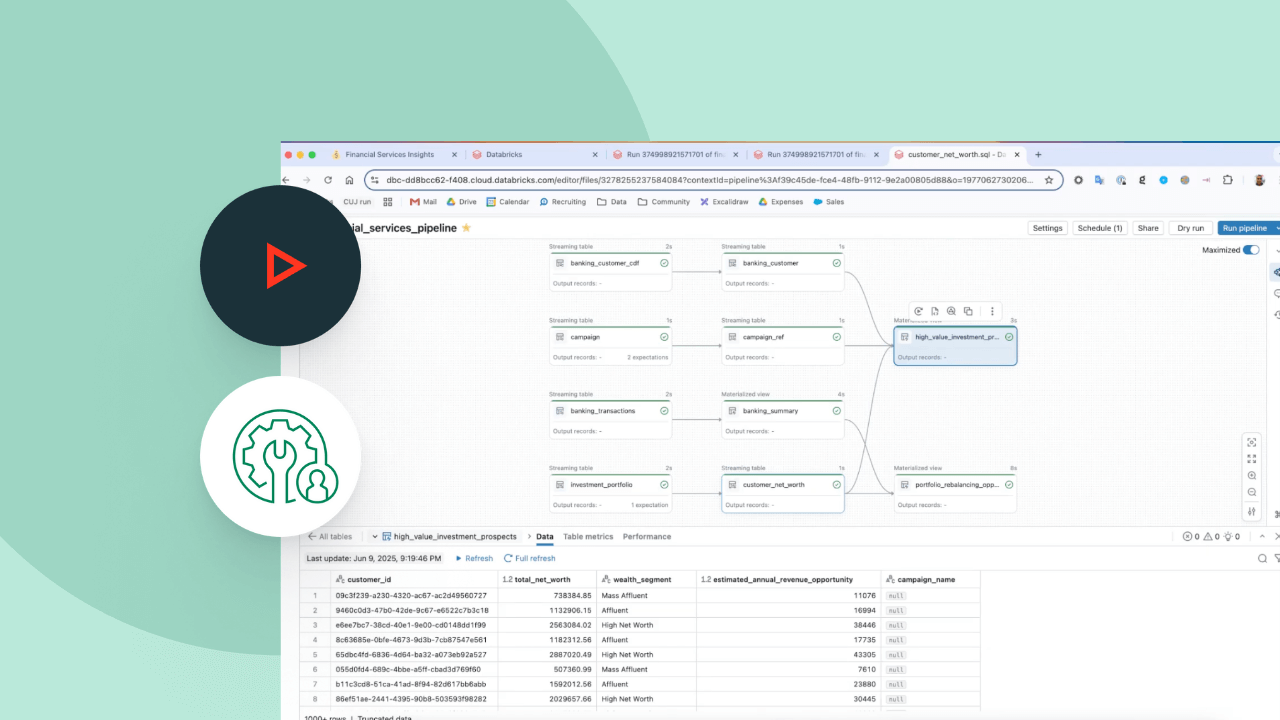
Spark Declarative Pipelines facilita la optimización del rendimiento del pipeline al declarar un pipeline de datos incremental completo con tablas de transmisión y vistas materializadas.
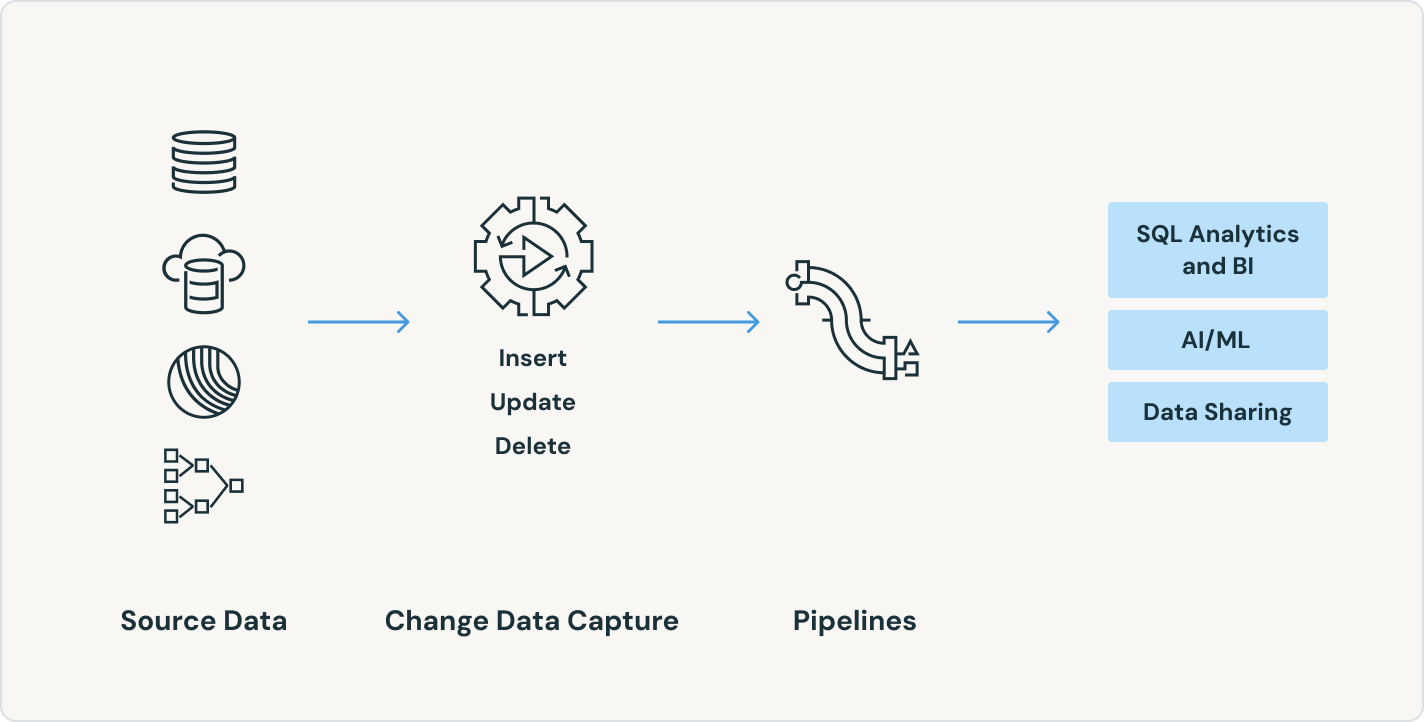
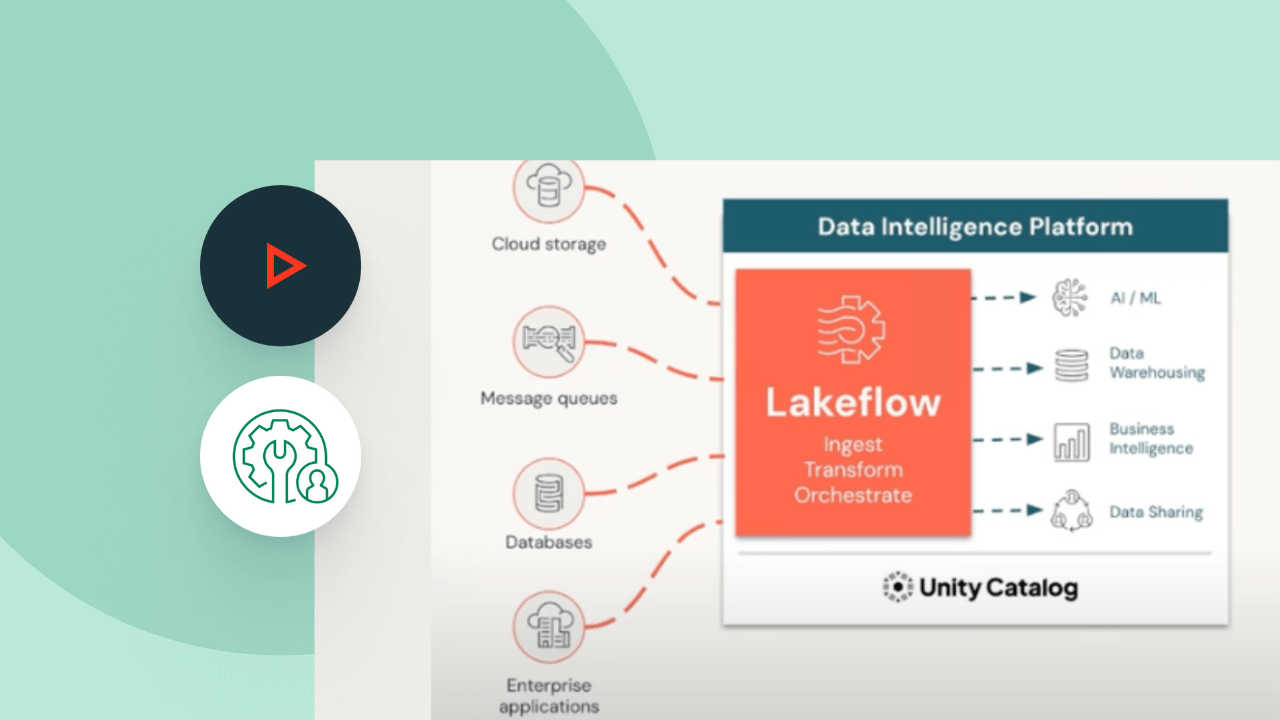
Spark Declarative Pipelines es compatible con un amplio ecosistema de fuentes y destinos. Carga datos desde cualquier fuente, incluidos el almacenamiento en la nube, los buses de mensajes, las fuentes de datos modificados, las bases de datos y las aplicaciones empresariales.
Las expectativas te permiten garantizar que los datos que llegan a las tablas cumplen con los requisitos de calidad de los datos y, a la vez, proporcionan insights sobre la calidad de los datos con cada actualización del pipeline.
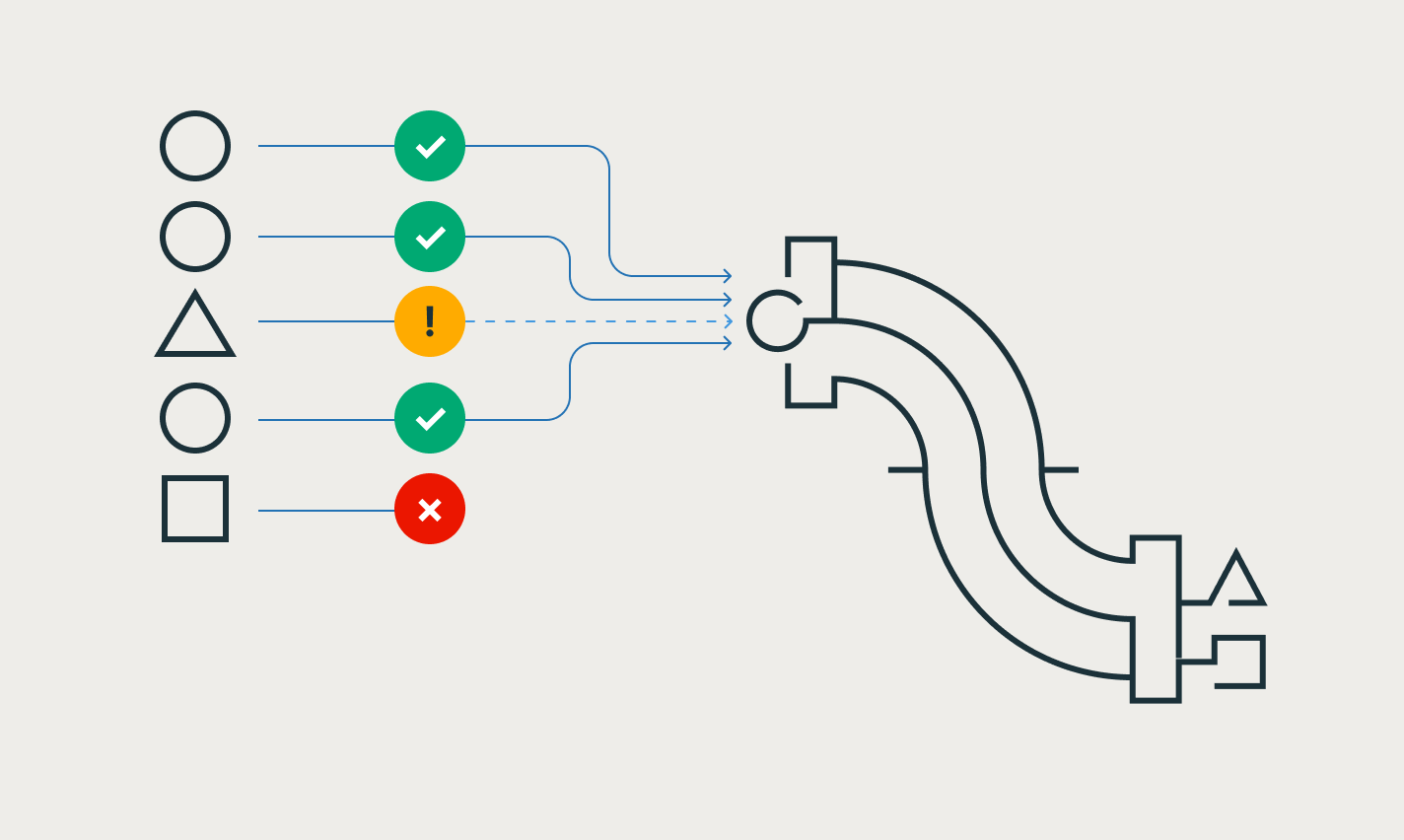
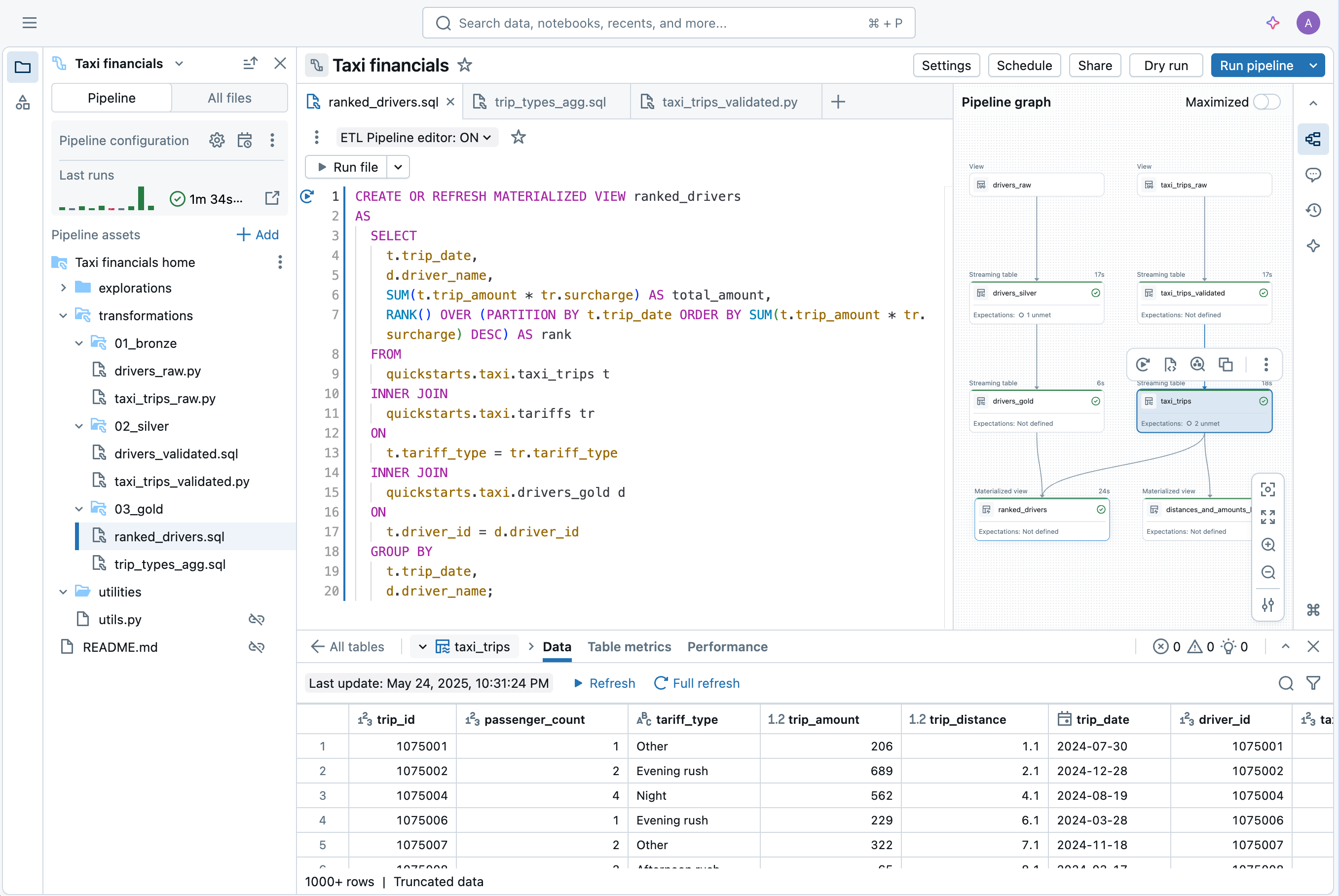
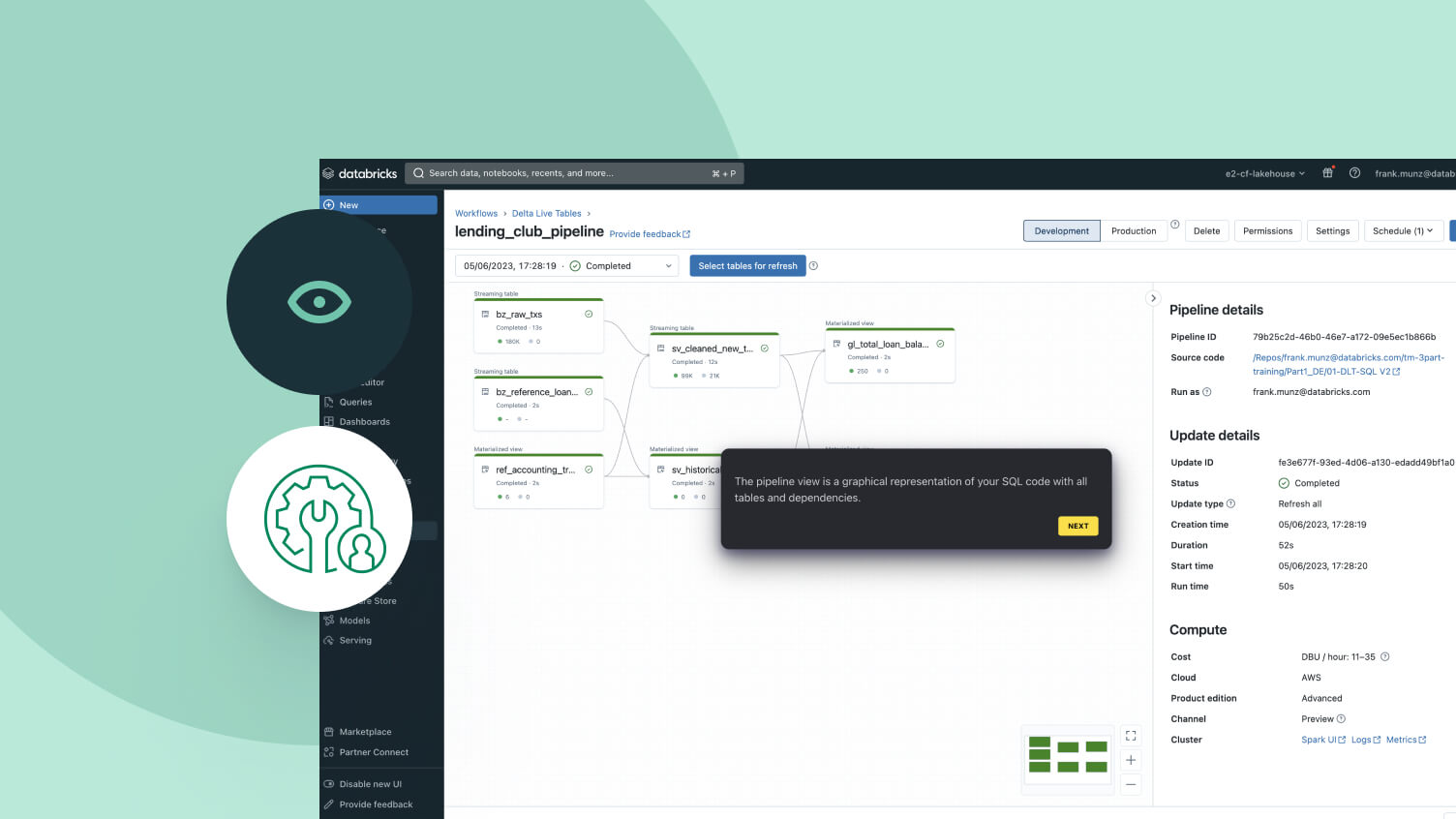
Desarrolla pipelines en el IDE para ingeniería de datos sin cambiar de contexto. Visualiza el DAG, la vista previa de los datos y los insights de ejecución en una sola IU. Desarrolla código fácilmente con autocompletado, errores en línea y diagnóstico.
Más características
Optimiza tus pipelines de datos

Simplifica las fuentes, las transformaciones y los destinos
La programación declarativa significa que puedes aprovechar el poder de ETL en la plataforma de inteligencia de datos con solo unas pocas líneas de código.
Los precios basados en el uso mantienen el gasto bajo control
Paga solo por los productos que usas, con granularidad por segundo.Descubre más
Explora otras ofertas integradas e inteligentes en la plataforma de inteligencia de datos.
Lakeflow Connect
Los conectores de ingesta de datos eficientes de cualquier fuente y la integración nativa con la plataforma de inteligencia de datos desbloquean un fácil acceso a la analítica y la IA, con una gobernanza unificada.

Trabajos de Lakeflow
Define, gestiona y supervisa fácilmente flujos de trabajo multitarea para pipelines de ETL, analítica y aprendizaje automático. Con una amplia gama de tipos de tareas compatibles, capacidades de observabilidad profundas y alta confiabilidad, tus equipos de datos están capacitados para automatizar y orquestar mejor cualquier pipeline y ser más productivos.

GENIE CODE
Tu socio autónomo de IA para el trabajo con datos.

Almacenamiento en lakehouse
Unifica los datos en tu lakehouse, en todos los formatos y tipos, para todas tus cargas de trabajo de analítica e IA.

Unity Catalog
Controla sin problemas todos tus activos de datos con la única solución de gobernanza abierta y unificada de la industria para datos e IA, integrada en la plataforma de inteligencia de datos de Databricks.
La plataforma Databricks
Descubra cómo la plataforma de Databricks permite sus cargas de trabajo de datos e IA.
Da el siguiente paso
Contenido relacionado




Preguntas frecuentes de Spark Declarative Pipelines
¿Estás listo para convertirte en una empresa de datos + IA?
Da los primeros pasos en tu transformación