AiChemy: Agente de Próxima Generación con MCP, Habilidades y Datos Personalizados para el Descubrimiento de Fármacos
AiChemy acelera el descubrimiento de fármacos integrando datos personalizados y externos (OpenTargets, PubChem, PubMed) a través de un sistema multiagente que utiliza MCP, AI Search y Genie en Databricks
por Yen Low y Sean Zhang
- Una guía para construir AiChemy, un sistema multiagente en Databricks que integra bases de conocimiento externas (OpenTargets, PubChem, PubMed) a través del Protocolo de Contexto del Modelo (MCP) con datos estructurados y no estructurados en Databricks.
- El desafío que resuelve: Acelera la investigación de descubrimiento de fármacos interdisciplinaria al permitir la colaboración autónoma entre diversos agentes de IA, permitiéndoles examinar conjuntos de datos masivos y dispares y proporcionar hallazgos rastreables y respaldados por evidencia.
- Resultados: Los investigadores pueden identificar dianas de enfermedades, evaluar candidatos a fármacos, recuperar propiedades detalladas y realizar evaluaciones de seguridad, lo que conduce a un descubrimiento de fármacos y generación de leads más eficientes.
Los sistemas multiagente aceleran la investigación interdisciplinaria
Imagine sistemas de IA multiagente colaborando como un equipo de expertos interdisciplinarios, analizando de forma autónoma grandes conjuntos de datos para descubrir patrones e hipótesis novedosas. Esto es ahora fácilmente posible con el Protocolo de Contexto de Modelo (MCP), un nuevo estándar para integrar fácilmente diversas fuentes de datos y herramientas. El creciente ecosistema de servidores MCP, desde bases de conocimiento hasta generadores de informes, ofrece infinitas capacidades.
Lo que hace AiChemy
Conozca AiChemy, un asistente multiagente que combina servidores MCP externos como OpenTargets, PubChem y PubMed con sus propias bibliotecas químicas en Databricks, de modo que las bases de conocimiento combinadas puedan analizarse e interpretarse mejor juntas. También tiene Skills que se pueden cargar opcionalmente para proporcionar instrucciones detalladas para la producción de informes específicos de tareas, formateados de manera consistente para necesidades de investigación, regulatorias o comerciales.
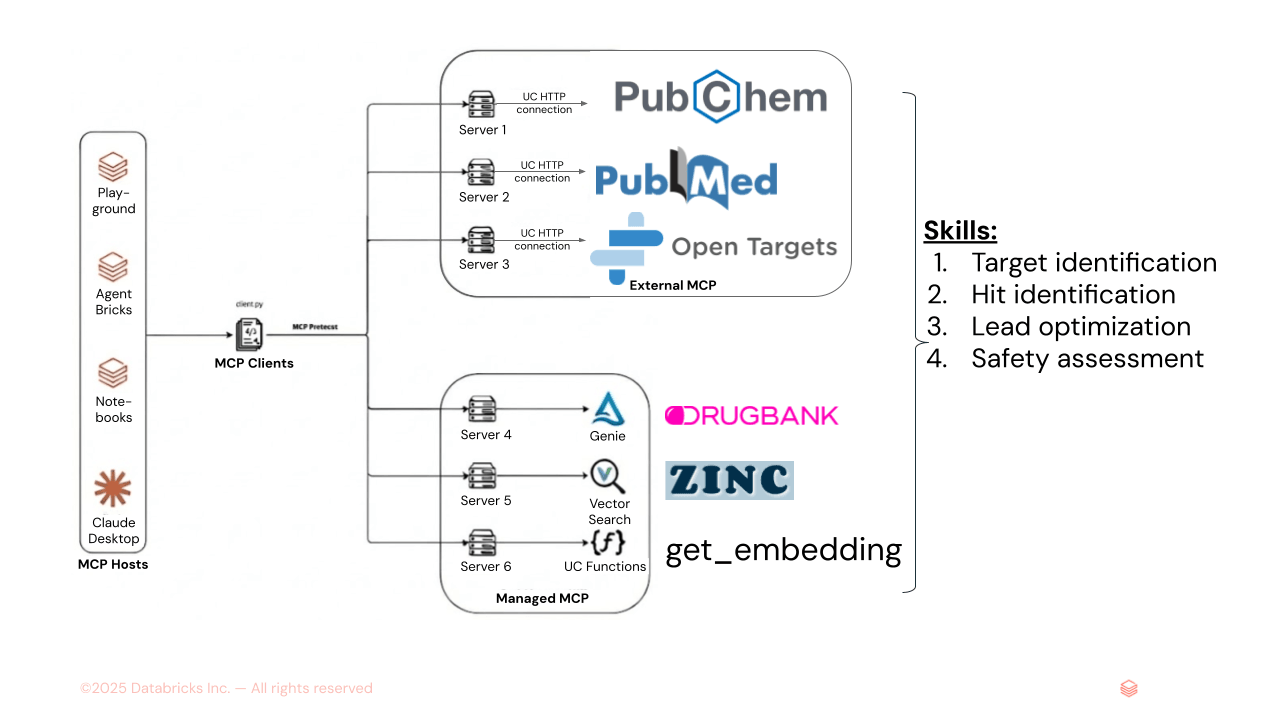
Figura 1. AiChemy es un supervisor multiagente que comprende servidores MCP externos PubChem, PubMed y OpenTargets, y servidores MCP de Databricks de Genie Space (texto a SQL para datos estructurados de DrugBank) y de AI Search (para datos no estructurados como incrustaciones moleculares ZINC). También se pueden cargar Skills para especificar la secuencia de tareas y el formato y estilo del informe para garantizar una salida consistente.
Sus capacidades clave incluyen la identificación de dianas de enfermedades y candidatos a fármacos, la recuperación de sus propiedades químicas y farmacocinéticas detalladas, y la provisión de evaluaciones de seguridad y toxicidad. Fundamentalmente, AiChemy respalda sus hallazgos con evidencia de respaldo rastreable a fuentes de datos verificables, lo que lo hace ideal para la investigación.
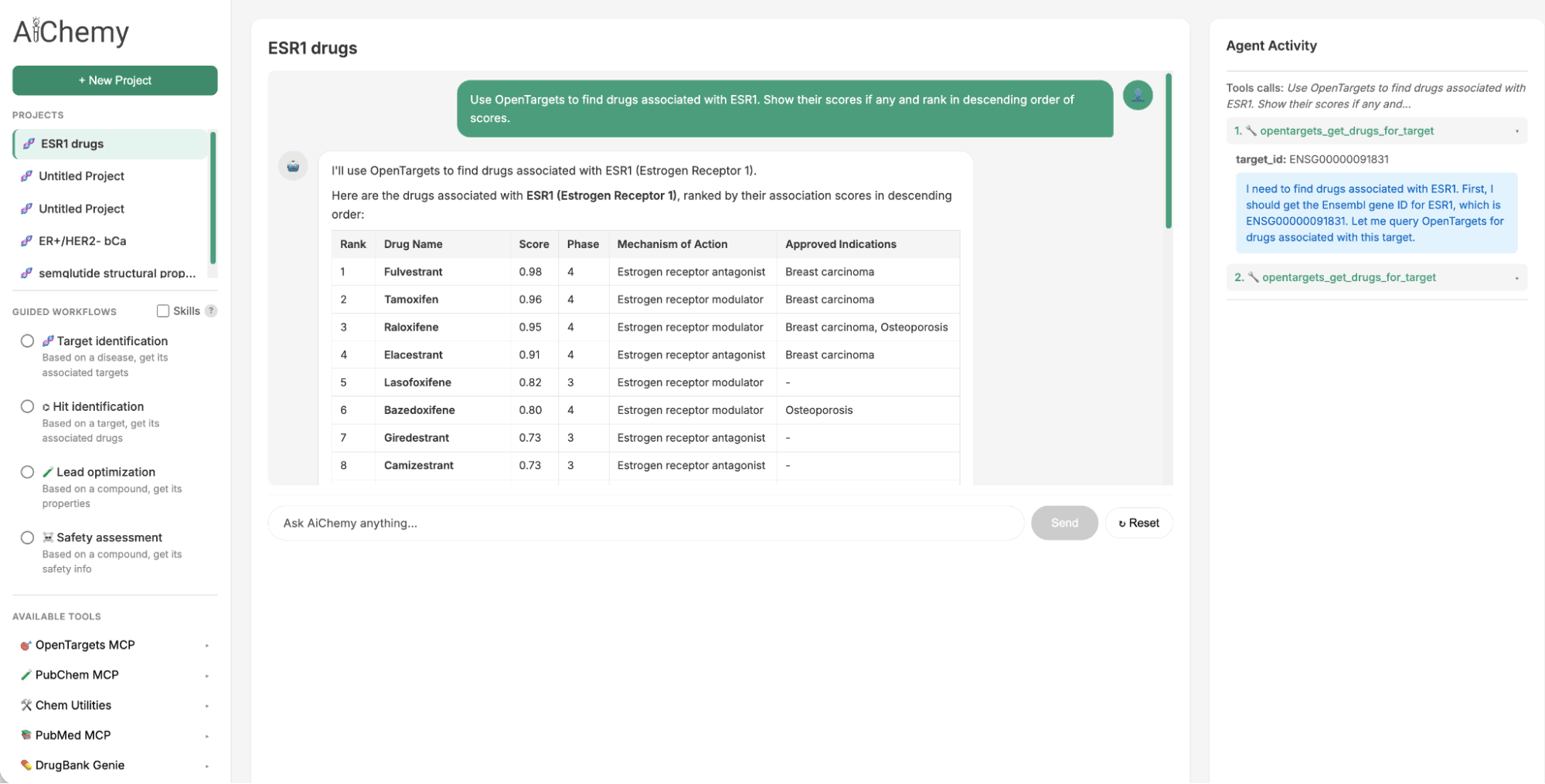
Caso de uso 1: Comprender los mecanismos de las enfermedades, encontrar dianas farmacológicas y generación de leads
El panel Guided Tasks proporciona las indicaciones y los Skills de agente necesarios para realizar los pasos clave en un flujo de trabajo de descubrimiento de fármacos de enfermedad -> diana -> fármaco -> validación de literatura.
- Identificar dianas terapéuticas: Comenzando con un subtipo de enfermedad específico, como el cáncer de mama con receptores de estrógeno positivos (ER+)/HER2 negativo (HER2-) (donde ER y HER2 son biomarcadores proteicos clave), encontrar dianas terapéuticas asociadas (por ejemplo, ESR1).
- Encontrar fármacos asociados: Utilizar la diana identificada (por ejemplo, ESR1) para encontrar posibles candidatos a fármacos.
- Validar con literatura: Para un candidato a fármaco dado (por ejemplo, camizestrant), verificar la literatura científica en busca de evidencia de respaldo.
Caso de uso 2: Generación de leads por similitud química
Para identificar un seguimiento del Modulador Selectivo del Receptor de Estrógeno (SERM) oral aprobado en 2023, Elacestrant, podemos aprovechar la similitud química. Buscamos en la gran biblioteca química ZINC15 moléculas similares a Elacestrant en cuanto a su naturaleza de fármaco, ya que los principios de Relación Cuantitativa Estructura-Actividad (QSAR) sugieren que compartirán propiedades similares. Esto se logra consultando Databricks AI Search, que utiliza la incrustación molecular de 1024 bits del Extended-Connectivity Fingerprint (ECFP) de Elacestrant (como vector de consulta) para encontrar las incrustaciones más similares dentro del índice de 250.000 moléculas de ZINC.
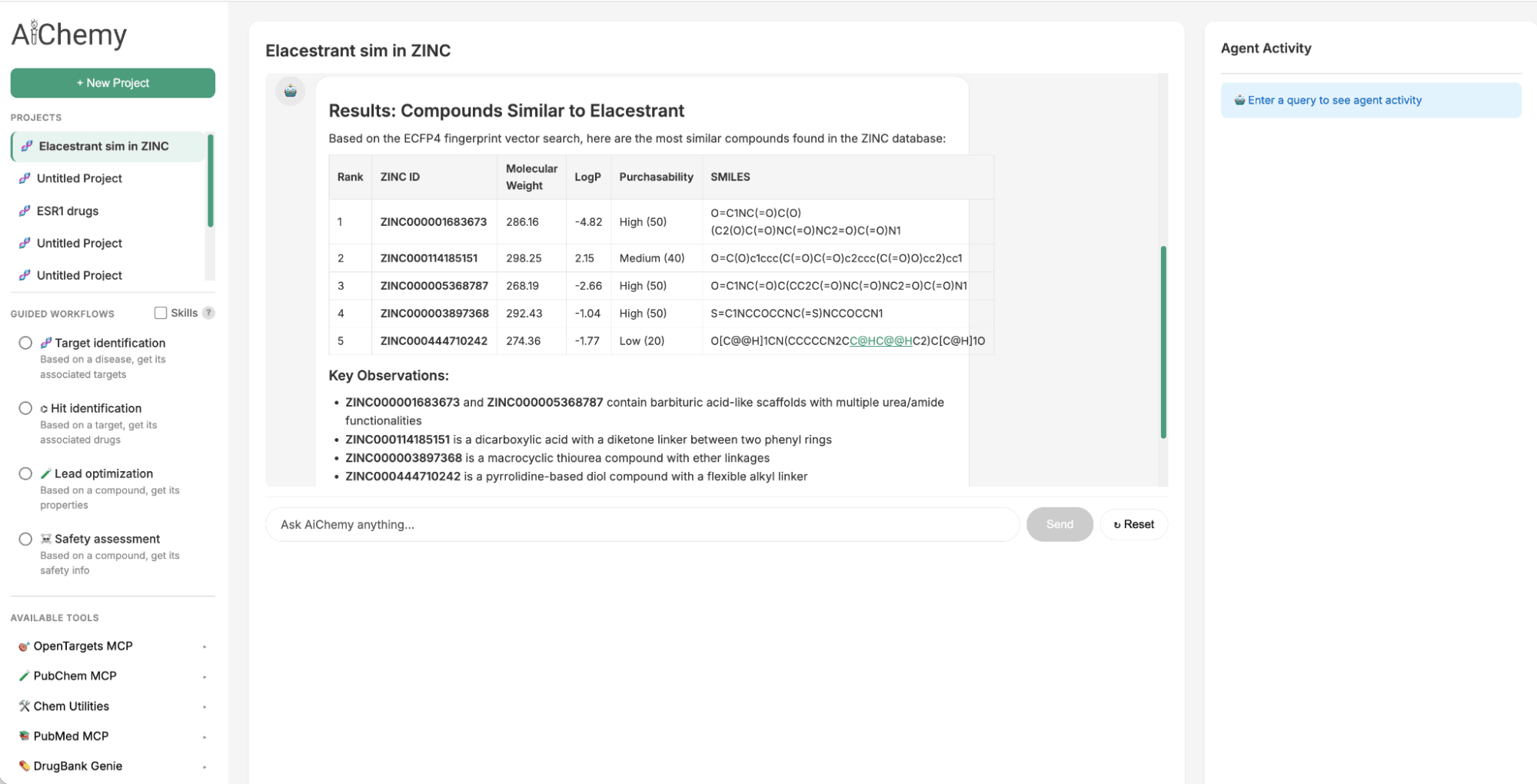
Figura 2. AiChemy incluye la búsqueda vectorial de la base de datos ZINC de 250.000 moléculas disponibles comercialmente. Esto nos permite generar compuestos líderes por similitud química. En esta captura de pantalla, le pedimos a AiChemy que encuentre en la búsqueda vectorial de ZINC los compuestos más similares a Elacestrant basándose en la incrustación molecular ECFP4.
Cree su propio supervisor multiagente de investigación
Personalizaremos un supervisor multiagente en Databricks integrando servidores MCP públicos con datos propietarios en Databricks. Para lograr esto, tiene la opción de usar Agent Bricks sin código o opciones de codificación como Notebooks. El Databricks Playground permite la creación rápida de prototipos e iteración de sus agentes.
Paso 1: Preparar los componentes necesarios para el supervisor multiagente
El sistema multiagente tiene 5 trabajadores:
- OpenTargets: servidor MCP externo de un grafo de conocimiento de enfermedades-dianas-fármacos
- PubMed: servidor MCP externo de literatura biomédica
- PubChem: servidor MCP externo de compuestos químicos
- Biblioteca de Fármacos (Genie): Una biblioteca química con propiedades de fármacos estructuradas, convertida en un espacio Genie para proporcionar capacidades de texto a SQL.
- Biblioteca Química (AI Search): Una biblioteca propietaria de datos químicos no estructurados con incrustaciones de huellas dactilares moleculares, preparada como un índice vectorial para facilitar la búsqueda de similitud por incrustaciones.
Paso 1a: Conéctese de forma segura a los servidores MCP públicos a través de las conexiones de Unity Catalog (UC) en la UI o en un Databricks Notebook (por ejemplo, 4_connect_ext_mcp_opentarget.py).
Paso 1b: Asegúrese de que su(s) tabla(s) estructurada(s) (por ejemplo, DrugBank) se transforme(n) en un espacio Genie con funcionalidad de texto a SQL utilizando la UI. Consulte 1_load_drugbank and descriptors.py
Paso 1c: Asegúrese de que su biblioteca química no estructurada se cree como un índice vectorial en la UI o en un Notebook para habilitar la búsqueda de similitud. Consulte 2_create VS zinc15.py
Paso 2 (Opción fácil): Cree el supervisor multiagente utilizando el Supervisor Agent sin código en 2 minutos
Para ensamblarlos, prueba los Agent Bricks sin código que crean un agente supervisor con los componentes anteriores a través de la interfaz de usuario y lo implementan en un punto final de API REST, todo en pocos minutos.
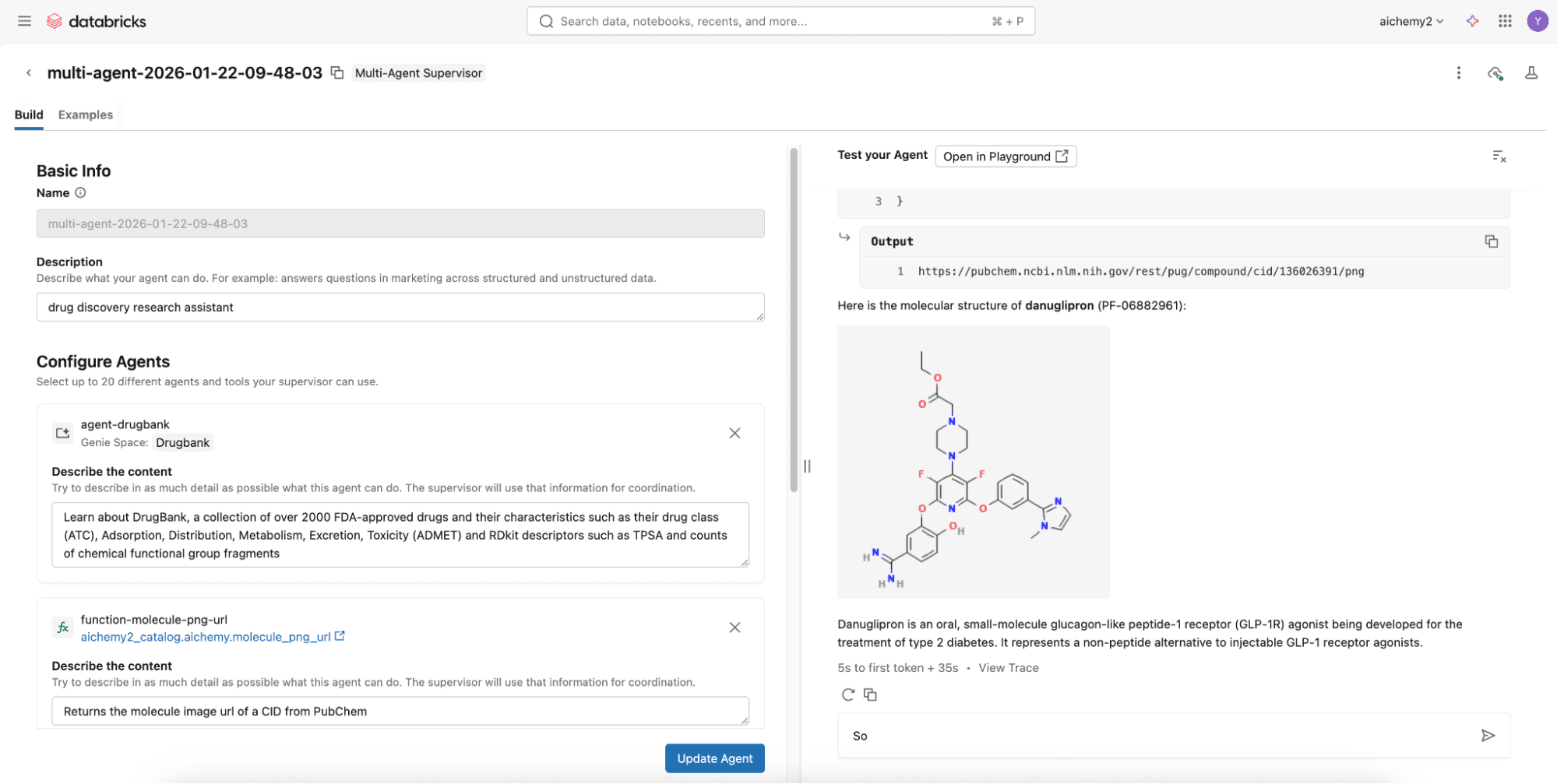
Paso 2 (Opción avanzada): Crea el supervisor multiagente usando Databricks Notebooks
Para capacidades más avanzadas como memoria de agente y Skills, desarrolla un supervisor Langgraph en Databricks Notebooks para integrarlo con Lakebase, la base de datos Postgres Serverless de Databricks. Consulta este repositorio de código donde puedes definir simplemente los componentes multiagente (ver Paso 1) en el config.yml.
Una vez que se define config.yml, puedes implementar el supervisor multiagente como un MLflow AgentServer (envoltorio FastAPI) con una interfaz de usuario web React (UI). Implementa ambos en Databricks Apps a través de la UI o Databricks CLI. Establece los permisos apropiados para que los usuarios utilicen la Databricks App y para que el principal de servicio de la aplicación acceda a los recursos subyacentes (por ejemplo, experimento para registrar rastreos, ámbito secreto si lo hay).
Paso 3: Evalúa y monitoriza tu agente
Cada invocación al agente se registra automáticamente y se rastrea en un experimento de Databricks MLflow utilizando los estándares de OpenTelemetry. Esto permite una fácil evaluación de las respuestas sin conexión o en línea para mejorar el agente con el tiempo. Además, tu multiagente implementado utiliza el LLM detrás de AI Gateway para que puedas disfrutar de los beneficios de la gobernanza centralizada, las salvaguardas integradas y la observabilidad completa para la preparación de producción.
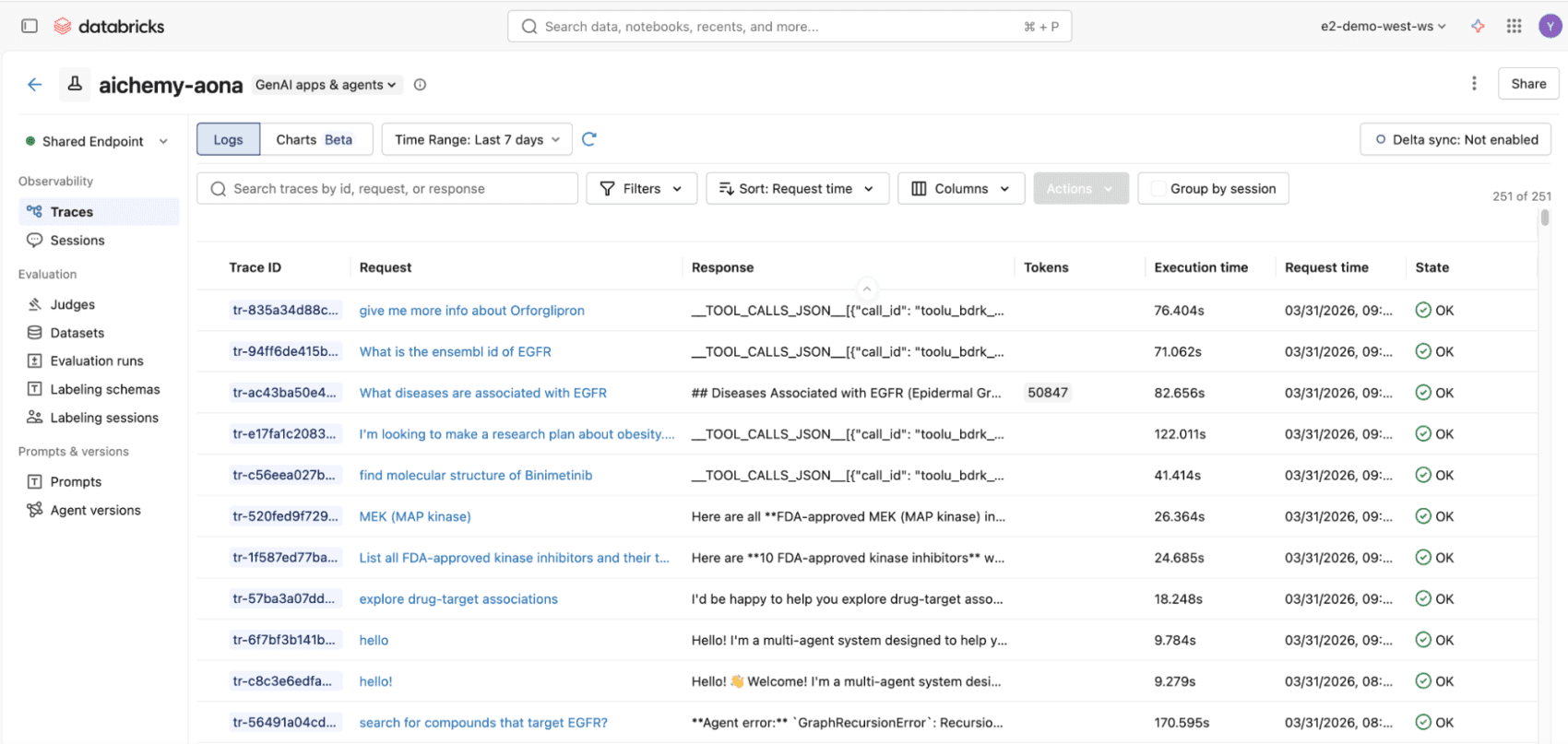
Figura 3. Todas las invocaciones al multiagente, ya sea a través de la UI de React o la API REST, se registrarán en rastreos de MLflow, compatibles con los estándares de OpenTelemetry, para una observabilidad de extremo a extremo.
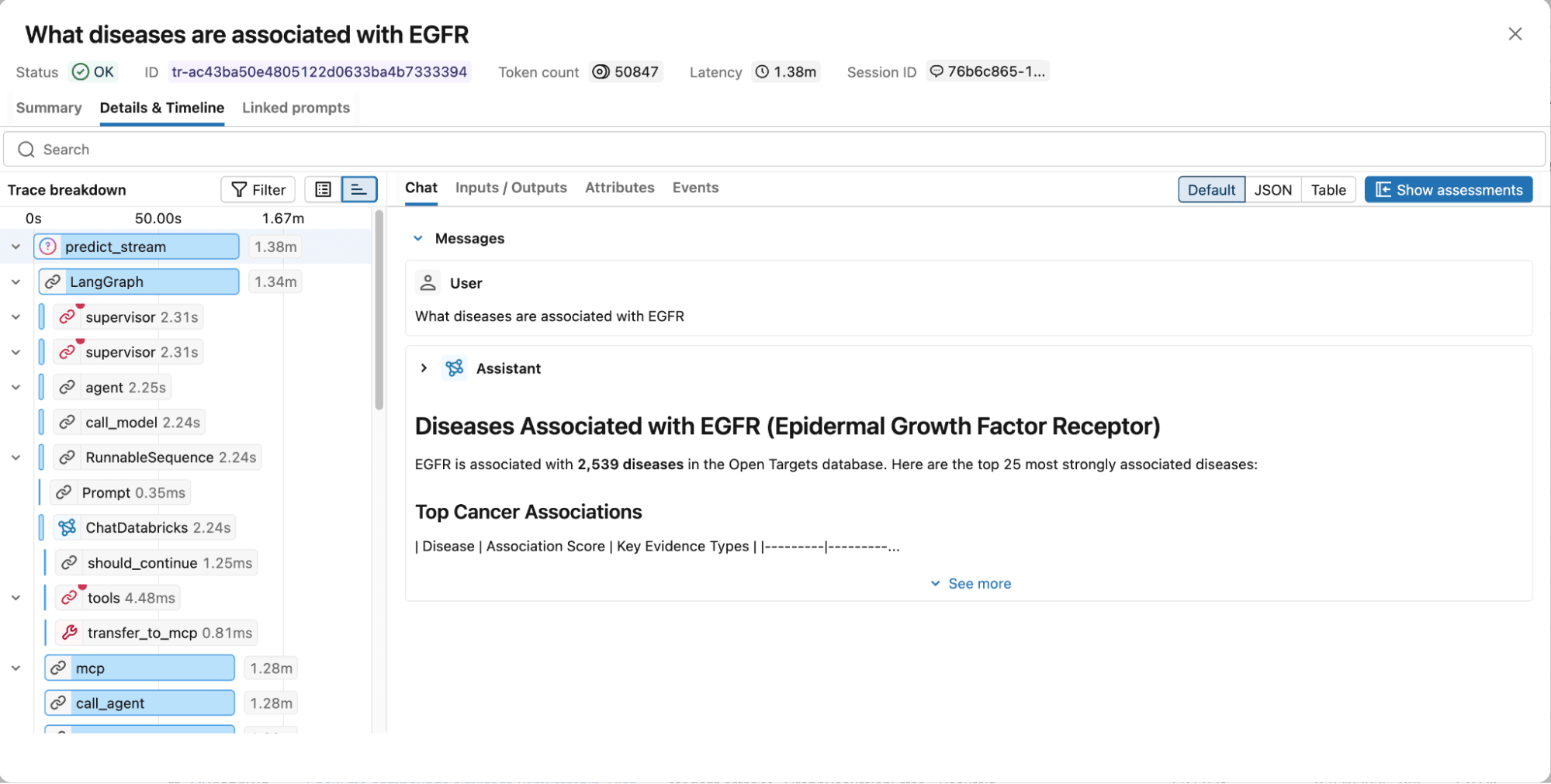
Figura 4. Los rastreos de MLflow capturan el gráfico de ejecución completo, incluidos los pasos de razonamiento, las llamadas a herramientas, los documentos recuperados, la latencia y el uso de tokens para facilitar la depuración y la optimización.
Próximos pasos
Te invitamos a explorar la aplicación web AiChemy y el repositorio de Github. Comienza a construir tu sistema multiagente personalizado con el marco intuitivo y sin código Agent Bricks en Databricks para que puedas dejar de buscar y empezar a descubrir.

(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.