Anuncio de disponibilidad general del modo en tiempo real para Apache Spark Structured Streaming en Databricks
Potencie sus cargas de trabajo más críticas en cuanto a tiempo, desde la detección de fraudes hasta la personalización, con latencia inferior a un segundo
- Latencia inferior a un segundo en Spark: el modo en tiempo real (RTM) en Apache Spark Structured Streaming ya está disponible de forma general, lo que proporciona un rendimiento de milisegundos de extremo a extremo a las API de Spark conocidas y elimina la necesidad de otro motor especializado, como Apache Flink.
- Innovación arquitectónica: RTM logra velocidades de procesamiento inferiores a 100 ms a través de tres innovaciones: flujo de datos continuo, planificación de canalizaciones y shuffle de streaming.
- Probado a escala: líderes de la industria como Coinbase, DraftKings y MakeMyTrip están utilizando RTM para potenciar casos de uso operativos de misión crítica, logrando algunos una reducción de latencia de más del 80 %.
Durante años, Apache Spark Structured Streaming ha impulsado algunas de las cargas de trabajo de streaming más exigentes del mundo. Sin embargo, para casos de uso de latencia ultrabaja, los equipos necesitaban mantener motores separados y especializados —lo más común era Apache Flink, junto con Spark, duplicando bases de código, modelos de gobernanza y sobrecarga operativa. Ahora, Databricks elimina esta carga para los clientes.
Hoy, nos complace anunciar la Disponibilidad General del Modo en Tiempo Real (RTM) en Spark Structured Streaming, que aporta latencia de nivel de milisegundo a las API de Spark que ya utiliza. Ya sea para detectar fraudes en tiempo real o para generar contexto fresco en tiempo real para dirigir sus agentes de IA, ahora puede usar Spark para potenciar todos estos casos de uso.
Impulsando a clientes y casos de uso líderes en la industria
El RTM ya ha sido adoptado por equipos en organizaciones líderes en la industria de servicios financieros, comercio electrónico, medios y tecnología publicitaria para potenciar la detección de fraudes, la personalización en vivo, la computación de características de ML y la atribución de anuncios.
Coinbase, una de las principales bolsas de criptomonedas del mundo, utiliza RTM para escalar sus motores de gestión de riesgos y detección de fraudes de alta frecuencia, procesando volúmenes masivos de eventos de blockchain y de la bolsa con la latencia inferior a 100 ms necesaria para proteger millones de transacciones de activos digitales.
Al aprovechar el Modo en Tiempo Real en Spark Structured Streaming, hemos logrado una reducción de más del 80 % en las latencias de extremo a extremo, alcanzando P99 inferiores a 100 ms, y optimizando nuestra estrategia de ML en tiempo real a gran escala. Este rendimiento nos permite calcular más de 250 características de ML, todas impulsadas por un motor Spark unificado.”—Daniel Zhou, Ingeniero Principal de Plataforma de Machine Learning, Coinbase
DraftKings, una de las plataformas de apuestas deportivas y deportes de fantasía más grandes de América del Norte, utiliza el modo en tiempo real para potenciar la computación de características para sus modelos de detección de fraudes, procesando flujos de eventos de apuestas de alto rendimiento con la latencia y confiabilidad requeridas para decisiones de apuestas con dinero real.
En las apuestas deportivas en vivo, la detección de fraudes exige una velocidad extrema. La introducción del Modo en Tiempo Real junto con la API transformWithState en Spark Structured Streaming ha sido un punto de inflexión para nosotros. Logramos mejoras sustanciales tanto en la latencia como en el diseño de pipelines, y por primera vez, construimos pipelines de características unificadas para entrenamiento de ML e inferencia en línea, logrando latencias ultrabajas que simplemente no eran posibles antes.”—Maria Marinova, Ingeniera de Software Líder Principal, DraftKings
MakeMyTrip, una de las principales plataformas de viajes en línea de la India para hoteles, vuelos y experiencias, adoptó el Modo en Tiempo Real para potenciar experiencias de búsqueda personalizadas. RTM procesó búsquedas de viajeros de alto volumen para ofrecer recomendaciones en tiempo real.
En la búsqueda de viajes, cada milisegundo cuenta. Al aprovechar el Modo en Tiempo Real (RTM) de Spark, ofrecimos experiencias personalizadas con latencias P50 inferiores a 50 ms, lo que generó un aumento del 7 % en las tasas de clics. RTM también ha transformado nuestras operaciones de datos, permitiendo una arquitectura unificada donde Spark maneja todo, desde ETL de alto rendimiento hasta pipelines de latencia ultrabaja. A medida que avanzamos hacia la era de los agentes de IA, dirigirlos de manera efectiva requiere construir contexto en tiempo real a partir de flujos de datos. Estamos experimentando con Spark RTM para proporcionar a nuestros agentes el contexto más rico y reciente necesario para tomar las mejores decisiones posibles. —Aditya Kumar, Director Asociado de Ingeniería, MakeMyTrip
RTM puede admitir cualquier carga de trabajo que se beneficie de convertir datos en decisiones en milisegundos. Algunos casos de uso de ejemplo incluyen:
- Experiencias personalizadas en comercio minorista y medios: Un proveedor de streaming OTT actualiza las recomendaciones de contenido inmediatamente después de que un usuario termina de ver un programa. Una plataforma líder de comercio electrónico recalcula las ofertas de productos mientras los clientes navegan, manteniendo el compromiso alto con bucles de retroalimentación de menos de un segundo.
- Monitoreo de IoT: Una empresa de transporte y logística ingiere telemetría en vivo para impulsar la detección de anomalías, pasando de la toma de decisiones reactiva a la proactiva en milisegundos.
- Detección de fraudes: Un banco global procesa transacciones con tarjetas de crédito de Kafka en tiempo real y marca actividades sospechosas, todo dentro de 200 milisegundos, reduciendo el riesgo y el tiempo de respuesta sin replataformar.
¿Qué es el Modo en Tiempo Real (RTM)?
RTM es una evolución del motor Spark Structured Streaming que le permite lograr un rendimiento inferior a un segundo en la evaluación comparativa de cargas de trabajo de clientes exigentes de ingeniería de características.
El modo de microbatching predeterminado (MBM) de Structured Streaming es como un autobús lanzadera de aeropuerto que espera a que aborden un cierto número de pasajeros antes de partir. Por otro lado, RTM opera como una pasarela móvil de alta velocidad, eliminando la limitación de esperar a que la lanzadera se llene. RTM procesa cada evento a medida que llega, proporcionando latencia de extremo a extremo de milisegundos sin salir del ecosistema Spark.
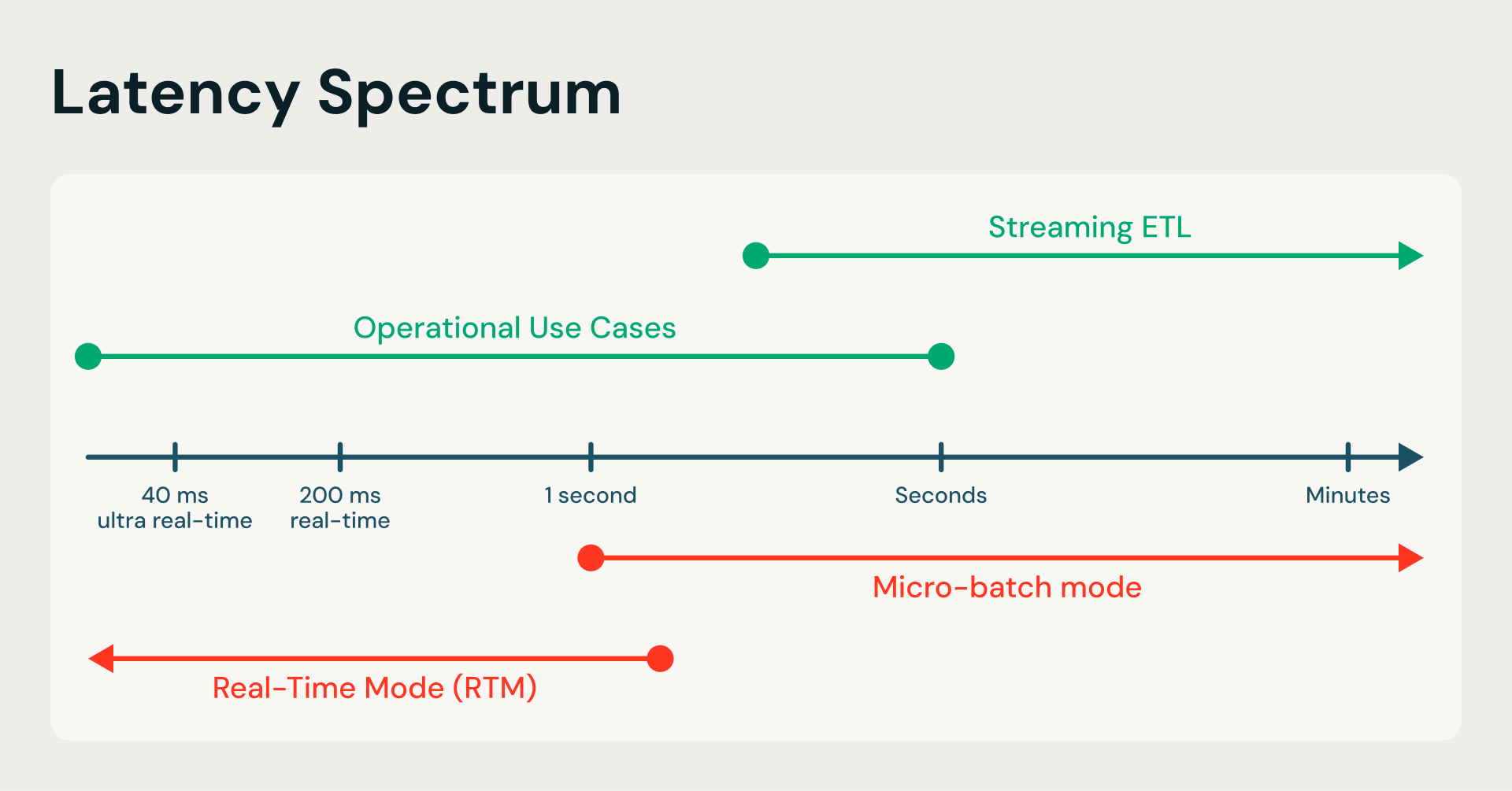
De segundos a milisegundos: RTM transforma el motor Spark al reemplazar el batching periódico con un flujo de datos continuo, eliminando los cuellos de botella de latencia del ETL tradicional.
Las ganancias de rendimiento de RTM provienen de tres innovaciones arquitectónicas clave:
- Flujo de datos continuo: Los datos se procesan a medida que llegan en lugar de en fragmentos discretos y periódicos.
- Programación de pipelines: Las etapas se ejecutan simultáneamente sin bloqueo, lo que permite que las tareas posteriores procesen los datos inmediatamente sin esperar a que las etapas anteriores finalicen.
- Shuffle de streaming: Los datos se pasan entre tareas de inmediato, evitando los cuellos de botella de latencia de los shuffles tradicionales basados en disco.
Juntos, transforman Spark en un motor de alto rendimiento y baja latencia capaz de manejar los casos de uso operativos más exigentes.
Spark RTM: Hasta un 92 % más rápido que Flink, lo que permite a los equipos operar menos infraestructura y moverse más rápido
Para validar el rendimiento de Spark RTM, comparamos el rendimiento con un motor especializado popular, Apache Flink, basándonos en cargas de trabajo reales de clientes que realizan computación de características. Estos patrones de computación de características son representativos de la mayoría de los casos de uso de ETL de baja latencia, como detección de fraudes, personalización y análisis operativos. Al comparar Spark RTM con Flink, los resultados demuestran que la arquitectura evolucionada de Spark proporciona un perfil de latencia comparable a los frameworks de streaming especializados. Para obtener más información sobre los conjuntos de datos y las consultas a las que se hace referencia, consulte este repositorio de GitHub.
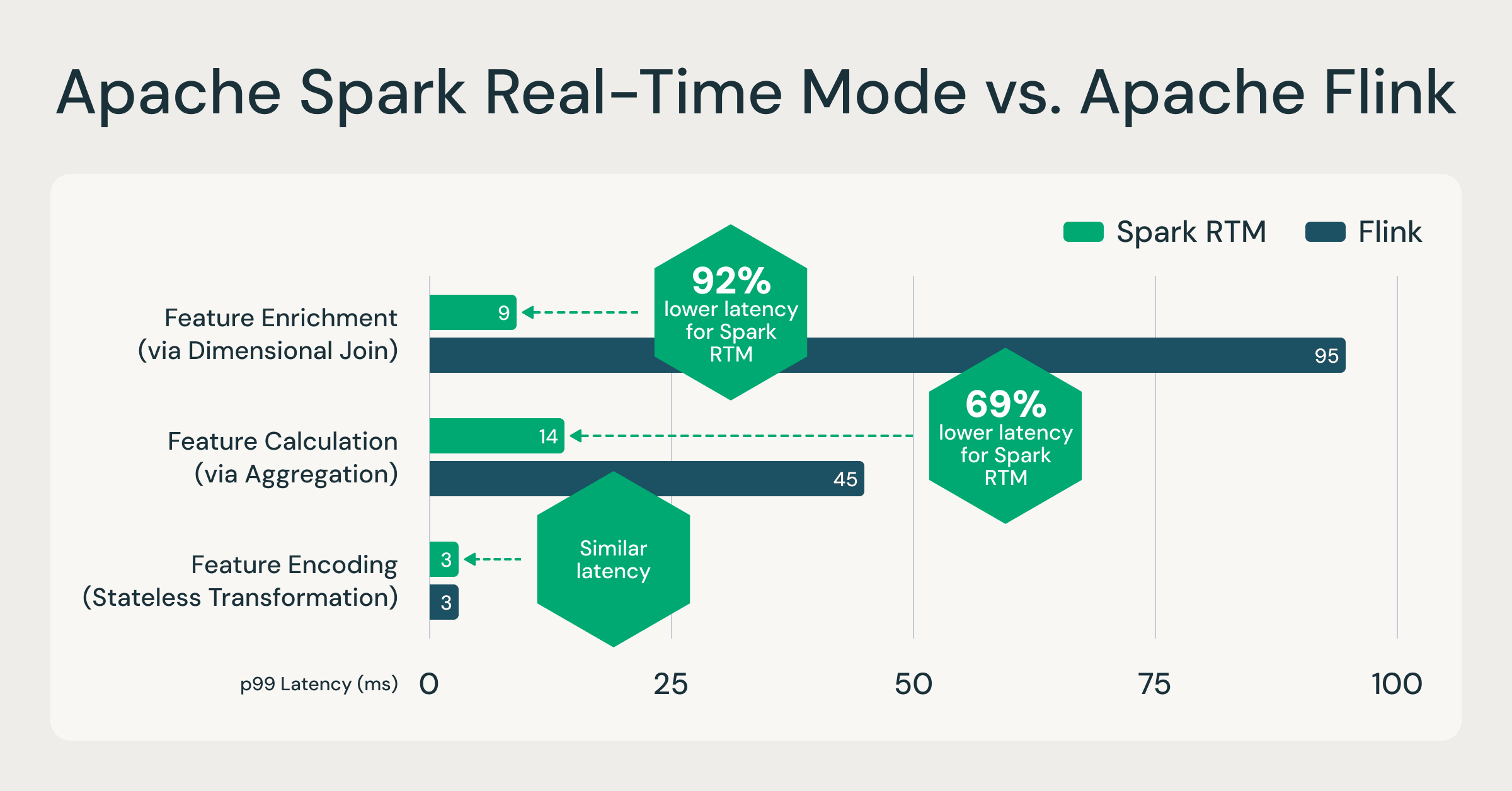
Un motor, hasta un 92 % más rápido: RTM supera a motores especializados como Flink, lo que demuestra que el análisis operativo a nivel de milisegundo ya no requiere un motor de streaming separado. Fuente: Benchmarks internos basados en patrones de computación de características de clientes. Consultas completas disponibles en GitHub.
Si bien la velocidad bruta importa, la mayor ventaja de Spark RTM sobre motores como Flink es la simplicidad que ofrece a los desarrolladores. Permite a los equipos usar la misma API de Spark tanto para entrenamiento batch como para inferencia en tiempo real, eliminando efectivamente la "deriva lógica" y la duplicación de código. Spark RTM permite una escalabilidad fluida, donde un cambio de código de una sola línea puede cambiar un pipeline de batches por hora a streaming de menos de un segundo sin ajuste manual de la infraestructura. En última instancia, al reducir la complejidad operativa y la necesidad de múltiples sistemas especializados, los equipos pueden desarrollar e implementar aplicaciones en tiempo real significativamente más rápido con Spark RTM.
Comenzar con Spark RTM
Ponerse en marcha con RTM es sencillo. Si ya está utilizando Structured Streaming, puede habilitarlo con una sola actualización de configuración, sin necesidad de reescrituras.
Paso 1: Configurar su clúster
RTM está actualmente disponible en Classic compute, en modos de acceso Dedicado y Estándar. RTM es compatible con Databricks Runtime (DBR) 16.4 y superior; sin embargo, recomendamos DBR 18.1 para las últimas características y optimizaciones. Durante la creación del clúster, agregue la siguiente configuración de Spark:
Paso 2: Usar el nuevo Real-Time Trigger en su consulta de streaming
Novedades de Spark RTM
Desde su lanzamiento en vista previa pública en agosto de 2025, Databricks ha continuado expandiendo las capacidades de RTM, basándose en los comentarios de los clientes.
Novedades de esta versión GA:
- Soporte OSS en Apache Spark 4.1 (transformaciones sin estado): RTM para transformaciones sin estado ya está disponible en Apache Spark 4.1 de código abierto. Los equipos que trabajan con OSS Spark pueden aprovechar el modo en tiempo real para canalizaciones de proyección, filtrado y basadas en UDF.
- Soporte del modo de acceso estándar: RTM ahora funciona en los modos de acceso dedicado y estándar en el cómputo clásico en Python, lo que brinda a los equipos más flexibilidad en cómo utilizan los recursos de cómputo en cargas de trabajo de streaming.
- Puntos de control asíncronos del estado y seguimiento del progreso: Los puntos de control del estado y del progreso de las consultas ahora se realizan de forma asíncrona, desacoplados de la ruta crítica del procesamiento de eventos. Esto mejora la latencia del modo en tiempo real para canalizaciones sin estado y con estado.
- Carga inicial del estado en transformWithState: transformWithState es un potente operador de Spark Structured Streaming para crear lógica personalizada con estado. Los usuarios ahora pueden cargar el estado inicial desde el punto de control de una consulta preexistente o desde una tabla delta al usar transformWithState con el modo en tiempo real. Esta capacidad es fundamental para la ingeniería de características con estado, ya que le permite pre-poblar consultas en línea con contexto histórico sin "empezar desde cero".
- Métricas y observabilidad mejoradas para UDFs: Métricas de latencia más precisas para la ejecución de UDFs de Python expuestas a través del oyente StreamingQueryProgress.
- Mejoras de rendimiento para UDFs con estado en Python: Se agregaron optimizaciones para mejorar el rendimiento de las operaciones con estado en transformWithState de Python, específicamente para consultas RTM.
Conclusión
RTM extiende Apache Spark Structured Streaming a una nueva clase de cargas de trabajo: aplicaciones operativas sensibles a la latencia que exigen una respuesta inmediata a los datos en streaming. Al aportar latencia subsegunda a las API de Spark que su equipo ya utiliza, elimina la necesidad de operar un motor especializado separado para sus canalizaciones más críticas en cuanto a tiempo. Ya sea que esté creando canalizaciones de detección de fraude, motores de personalización o sistemas de cálculo de características de ML, el modo en tiempo real le brinda la latencia que su aplicación exige con la simplicidad y la amplitud del ecosistema de Spark.
Recursos técnicos
Consulte los siguientes recursos para comenzar hoy mismo con RTM:
- Documentación: Modo en tiempo real en Structured Streaming
- Vídeo bajo demanda: Introducción al modo en tiempo real
- Blog: Cómo lograr la detección de fraude en tiempo real: configuración de Spark RTM con Databricks Lakebase
- Ejemplos de código: Ejemplos del modo en tiempo real
- Seminario web bajo demanda: Inmersión técnica en el modo en tiempo real
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.