Respuestas Aproximadas, Decisiones Exactas: Nuevas Funciones de Sketch para Análisis
Cuatro nuevas funciones de sketch en Databricks aceleran los percentiles, los recuentos distintos y las consultas top-K por órdenes de magnitud
por Daniel Tenedorio, Kent Marten, Gengliang Wang y Chenhao Li
- Percentiles en milisegundos, no minutos: los sketches de cuantiles KLL calculan P50, P90, P99 sobre conjuntos de datos masivos en memoria constante. Almacene los sketches y fúndalos para actualizaciones incrementales instantáneas.
- Superposición de audiencia a una fracción del costo: los sketches Theta y Tuple realizan uniones, intersecciones y diferencias de conjuntos en conjuntos de valores distintos. Los sketches Tuple también asocian métricas (sumas, mínimos, máximos) con cada clave para el conteo y la agregación combinados.
- Tendencias en tiempo real sin reprocesamiento: las funciones aproximadas de top-K identifican los elementos más frecuentes en memoria limitada, fusionables en ventanas de tiempo.
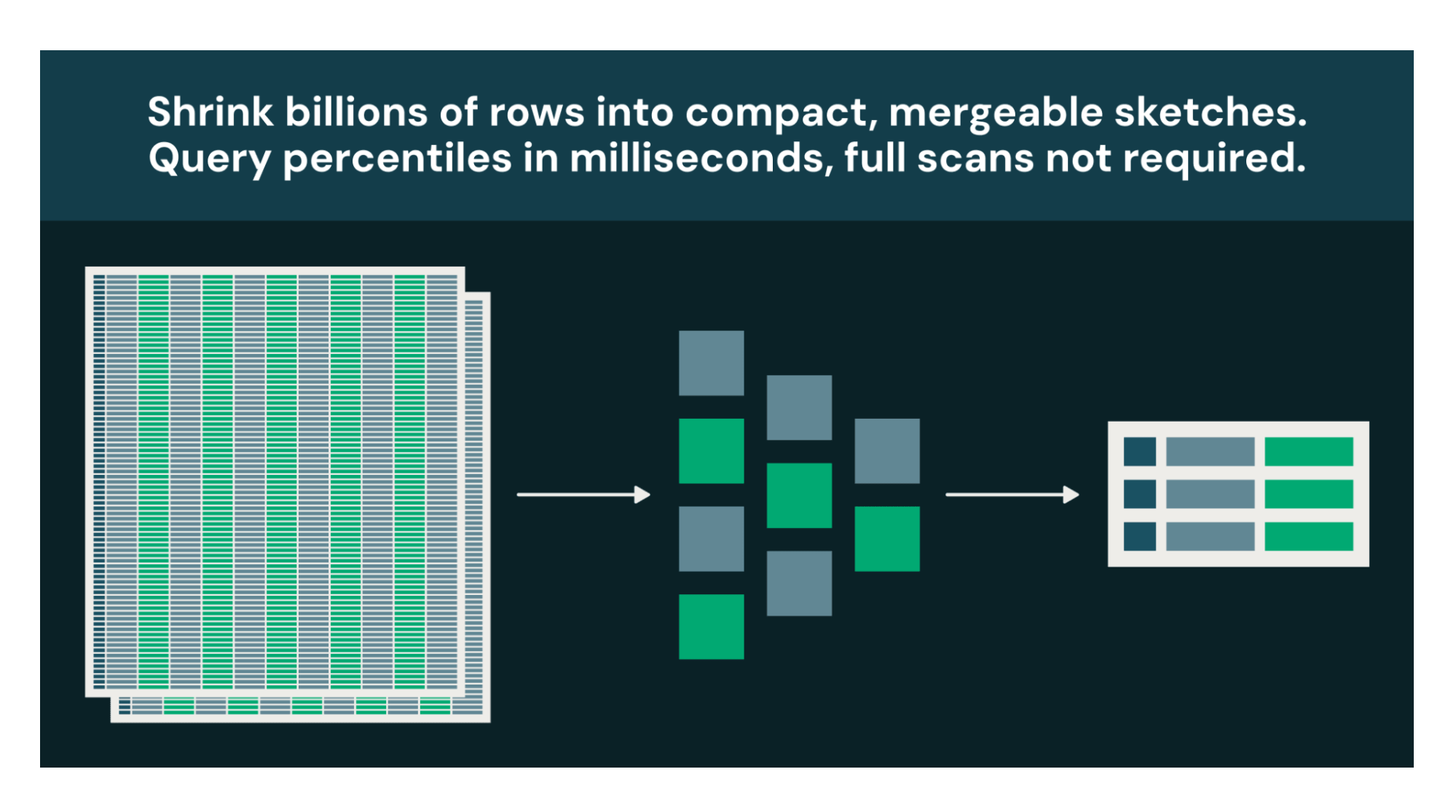
Muchas preguntas analíticas son de apoyo a la decisión, no de auditoría. Si saber "~4.7M usuarios únicos ±1%" conduce a la misma decisión que "4,712,389 usuarios únicos", la respuesta aproximada a una fracción del costo es estrictamente mejor.
Cada almacén de datos tiene un puñado de consultas que consumen la mayor parte de la computación: percentiles que fuerzan ordenamientos globales, recuentos distintos que rastrean cada valor único, clasificaciones top-K que reorganizan conjuntos de datos completos. Databricks ahora es compatible con cuatro nuevas familias de funciones de sketch, basadas en Apache DataSketches, que reemplazan estos cálculos exactos con aproximaciones de memoria limitada. La compensación: un error relativo configurable del 1-2%. La recompensa: órdenes de magnitud menos computación, además de sketches que puedes almacenar, fusionar y volver a consultar sin tocar los datos sin procesar.
Cálculos de percentiles en milisegundos, no minutos
Cuando llamas a PERCENTILE(response_time_ms, 0.99) en una tabla de mil millones de filas, el motor debe ordenar cada valor globalmente. Una reorganización completa del clúster podría llevar minutos y consumir gigabytes de memoria. Para un panel que se actualiza cada 5 minutos, estás pagando ese costo una y otra vez.
Los sketches KLL son resúmenes compactos y fusionables, creados para responder preguntas de cuantiles. Te permiten reemplazar esta ordenación utilizando la misma memoria limitada, ya sea que proceses mil valores o un billón. El error relativo típico es del 1-2% y es configurable, lo que está dentro del rango de acción para el monitoreo de latencia, la planificación de capacidad y la detección de anomalías.
La verdadera ventaja es el flujo de trabajo que los sketches permiten. Constrúyelos una vez durante tu ETL diario. Almacénalos como columnas en Delta tables. Cuando un panel necesite P50/P90/P99 para cualquier rango de tiempo, fusiona los sketches precalculados en milisegundos en lugar de volver a escanear los datos sin procesar. Extrae múltiples cuantiles de un solo sketch en una sola pasada con kll_get_quantile_bigint(sketch, ARRAY(0.5, 0.9, 0.99)).
Análisis de superposición de audiencia sin la factura de computación
¿Cuántos usuarios vieron tu anuncio del Super Bowl pero no tu campaña de Instagram? El análisis de superposición de audiencia es fundamental para la medición de marketing. Necesitas saber el alcance total (usuarios que vieron cualquier campaña), la superposición (usuarios que vieron varias campañas) y el alcance exclusivo (usuarios que vieron solo una campaña). Pero el cálculo exacto requiere recopilar cada ID de usuario en la memoria y realizar operaciones de conjunto en miles de millones de identificadores potenciales. A escala, esto se vuelve impráctico o imposible.
Los sketches Theta resumen un conjunto de valores distintos en memoria limitada y admiten álgebra de conjuntos completa: uniones, intersecciones y diferencias. Construye un sketch por campaña y luego combínalos matemáticamente:
El enfoque exacto requeriría un UNION para deduplicar, luego un JOIN para encontrar la superposición, posiblemente reorganizando los ID de usuario sin procesar dos veces en tu clúster. Con los sketches Theta, generas objetos binarios compactos medidos en kilobytes, y las operaciones de conjunto ocurren localmente en microsegundos. Esto hace que las curvas de alcance diarias, la medición de incrementalidad y la deduplicación multicanal sean prácticas.
Clasificaciones en tiempo real sin reprocesar datos sin procesar
¿Qué es tendencia ahora mismo? Es una pregunta simple con una respuesta exacta costosa: contar cada valor distinto, almacenar todos esos recuentos, reorganizarlos en tu clúster, ordenar globalmente. Para flujos de eventos de alta cardinalidad como registros de búsqueda o clickstreams, esto es un trabajo por lotes, no una consulta en vivo.
Los sketches top-K aproximados rastrean tus elementos más frecuentes en memoria limitada y te permiten fusionar particiones y ventanas de tiempo para extraer resultados al instante. Los elementos raros podrían descartarse, lo cual está bien, porque eso no es lo que buscas.
Con approx_top_k_combine, tu panel de "tendencias de esta semana" se convierte en una fusión de 168 sketches precalculados en lugar de un escaneo de miles de millones de eventos sin procesar. Para cargas de trabajo de streaming, fusiona el sketch de cada micro-lote en un total acumulado y muestra los resultados en tiempo real. Lo que antes era un trabajo por lotes se convierte en una clasificación en vivo.
Cardinalidad y atribución de ingresos en una sola pasada
Contar clientes distintos es una consulta. Sumar sus ingresos es otra. Hacer ambas cosas correctamente, sin contar dos veces a los clientes que aparecen en múltiples períodos, es el desafío.
Considera una pregunta analítica común: “¿Cuántos clientes únicos realizaron una compra este mes y cuál fue su ingreso total por región?” Típicamente, comenzarías con un GROUP BY grande, deduplicando los ID de cliente mientras sumas las compras a través de miles de millones de transacciones. Y no puedes simplemente sumar los resultados anteriores, los clientes que aparecen en ambos períodos se cuentan dos veces y sus ingresos se sobreestiman.
Los sketches de tuplas resuelven esto combinando el recuento distinto y la agregación de métricas en una única estructura fusionable.
Cada sketch mapea un cliente distinto a su gasto agregado. Cuando fusionas a través de los días, los recuentos de clientes se deduplican automáticamente y las sumas de ingresos se acumulan. La computación incremental exacta te haría reprocesar desde datos sin procesar cada vez que cambiara el rango de datos.
Comenzando con el sketch adecuado
Familia de funciones | Casos de uso |
Sketches de cuantiles KLL | Percentiles (P50, P90, P99) |
Sketches Theta | Operaciones de conjunto en valores distintos |
Top-K aproximado | Elementos más frecuentes |
Sketches de tuplas | Recuentos distintos y agregaciones de métricas |
Cuándo usar sketches: Paneles de control, análisis de tendencias, monitoreo, atribución de marketing: cualquier consulta donde las respuestas aproximadas sean aceptables. Cuanto más grande sea su conjunto de datos, mejor. Si no está seguro de qué sketch usar, pregunte a Genie Code para que le ayude a saber cuál es la elección correcta.
Cuándo mantener la exactitud: Auditorías financieras, informes de cumplimiento o cualquier caso de uso donde los requisitos regulatorios o comerciales exijan valores precisos.
Estas cuatro familias de funciones convierten las consultas de larga duración en las más económicas de su almacén. Cree sketches una vez durante el ETL, guárdelos en Delta, fúndalos en la lectura. Los datos sin procesar siguen ahí cuando los auditores los solicitan. Para todo lo demás, un margen de error del 1% y una aceleración de 1000x es una compensación bienvenida.
Todas las funciones funcionan en pipelines de SQL, DataFrame y Structured Streaming. Los sketches creados en Spark son interoperables con otros sistemas en el ecosistema de Apache DataSketches. Consulte la documentación (1, 2, 3, 4) para ver las firmas de las funciones y ejemplos, y empiece a usar sketches hoy mismo.
Mención especial a Christopher Boumalhab (cboumalh en GitHub) por implementar y contribuir con las familias de funciones Theta sketch y Tuple sketch en Apache Spark.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.