¿Son los agentes LLM buenos en la optimización del orden de unión?
por Eric Liang, Ryan Marcus, Sid Taneja y Yuhao Zhang
- Qué es: Exploramos la aplicación de agentes de modelos de lenguaje grandes (LLM) de vanguardia al problema clásico de la optimización del orden de las uniones en bases de datos.
- El Desafío: Los optimizadores de consultas tradicionales a menudo tienen dificultades con el orden de las uniones, donde el número de planes posibles crece exponencialmente con el número de tablas, lo que a menudo conduce a un rendimiento deficiente debido a una cardinalidad mal estimada. Los agentes LLM abordan esto actuando como un DBA impulsado por datos, razonando a través de estadísticas de tiempo de ejecución reales y contexto semántico que las heurísticas automatizadas a menudo pasan por alto.
- Resultados y Conclusiones: En puntos de referencia experimentales, el agente prototipo mejoró el optimizador de Databricks en el 80% de los casos, mejorando la latencia de las consultas en un factor de 1.3x en general.
Introducción
En la plataforma de inteligencia Databricks, exploramos y utilizamos regularmente nuevas técnicas de IA para mejorar el rendimiento del motor y simplificar la experiencia del usuario. Aquí presentamos resultados experimentales sobre la aplicación de modelos de vanguardia a uno de los desafíos más antiguos de las bases de datos: el ordenamiento de uniones (join ordering).
Este blog es parte de una colaboración de investigación con UPenn.
El Problema: Ordenamiento de Uniones (Join Ordering)
Desde su creación, los optimizadores de consultas en bases de datos relacionales han tenido dificultades para encontrar buenos ordenamientos de uniones para consultas SQL. Para ilustrar la dificultad del ordenamiento de uniones, considere la siguiente consulta:
¿Cuántas películas fueron producidas por Sony y protagonizadas por Scarlett Johansson?
Supongamos que queremos ejecutar esta consulta sobre el siguiente esquema:
| Nombre de la tabla | Columnas de la tabla |
|---|---|
| Actor | actorID, actorName, actorDOB, … |
| Company | companyID, companyName, … |
| Stars | actorID, movieID |
| Produces | companyID, movieID |
| Movie | movieID, movieName, movieYear , … |
Las tablas de entidades Actor, Company y Movie están conectadas a través de las tablas de relación Produces y Stars (por ejemplo, mediante claves externas). Una versión de esta consulta en SQL podría ser:
Lógicamente, queremos realizar una operación de unión simple: Actor ⋈ Stars ⋈ Movie ⋈ Produces ⋈ Company. Pero físicamente, dado que cada una de estas uniones son conmutativas y asociativas, tenemos muchas opciones. El optimizador de consultas podría optar por:
- Primero encontrar todas las películas protagonizadas por Scarlett Johansson, luego filtrar solo las películas producidas por Sony,
- Primero encontrar todas las películas producidas por Sony, luego filtrar aquellas protagonizadas por Scarlett Johansson,
- En paralelo, calcular las películas de Sony y las películas de Scarlett Johansson, luego tomar la intersección.
Qué plan es óptimo depende de los datos: si Scarlett Johansson ha protagonizado significativamente menos películas de las que Sony ha producido, el primer plan podría ser óptimo. Desafortunadamente, estimar esta cantidad es tan difícil como ejecutar la consulta misma (en general). Aún peor, normalmente hay muchos más de 3 planes para elegir, ya que el número de planes posibles crece exponencialmente con el número de tablas, y las consultas analíticas unen regularmente 20-30 tablas diferentes.
¿Cómo funciona el ordenamiento de uniones hoy en día? Los optimizadores de consultas tradicionales resuelven este problema con tres componentes: un estimador de cardinalidad diseñado para adivinar rápidamente el tamaño de las subconsultas (por ejemplo, para adivinar cuántas películas ha producido Sony), un modelo de costos para comparar diferentes planes potenciales y un procedimiento de búsqueda que navega por el espacio exponencialmente grande. La estimación de cardinalidad es especialmente difícil y ha dado lugar a una amplia gama de investigaciones que buscan mejorar la precisión de la estimación utilizando una amplia gama de enfoques [A].
Todas estas soluciones añaden una complejidad significativa a un optimizador de consultas y requieren un esfuerzo de ingeniería considerable para integrar, mantener y poner en producción. ¿Pero qué pasa si los agentes impulsados por LLM, con sus capacidades para adaptarse a nuevos dominios mediante indicaciones (prompting), tienen la clave para resolver este problema de décadas?
Ordenamiento de uniones agéntico
Cuando los optimizadores de consultas seleccionan un mal ordenamiento de uniones1, los expertos humanos pueden solucionarlo diagnosticando el problema (a menudo una cardinalidad mal estimada) e instruyendo al optimizador de consultas para que elija un ordenamiento diferente. Este proceso a menudo requiere múltiples rondas de pruebas (por ejemplo, ejecutando la consulta) e inspeccionando manualmente los resultados intermedios.
Los optimizadores de consultas normalmente necesitan elegir ordenamientos de uniones en unos pocos cientos de milisegundos, por lo que integrar un LLM en la ruta crítica (hot path) del optimizador de consultas, aunque potencialmente prometedor, no es posible hoy en día. ¡Pero el proceso iterativo y manual de optimizar el ordenamiento de uniones para una consulta, que podría llevar a un experto humano varias horas, podría automatizarse potencialmente con un agente LLM! Este agente intenta automatizar ese proceso de ajuste manual.
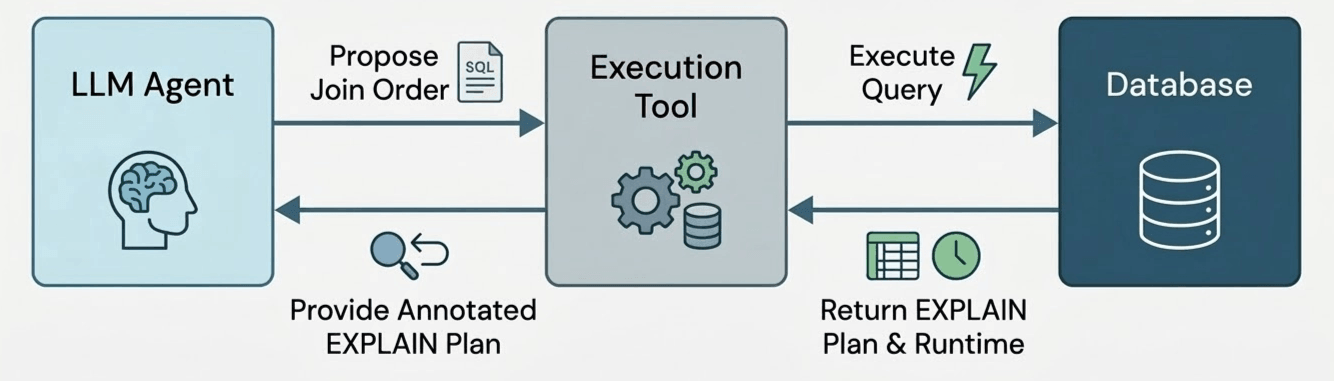
Para probar esto, desarrollamos un prototipo de agente de optimización de consultas. El agente tiene acceso a una única herramienta, que ejecuta un ordenamiento de uniones potencial para una consulta y devuelve el tiempo de ejecución del ordenamiento de uniones (con un tiempo de espera del tiempo de ejecución de la consulta original) y el tamaño de cada subplan calculado (por ejemplo, el plan EXPLAIN EXTENDED).
Dejamos que el agente se ejecute durante 50 iteraciones, permitiendo que el agente pruebe libremente diferentes ordenamientos de uniones. El agente es libre de usar estas 50 iteraciones para probar planes prometedores ("explotación") o para explorar alternativas arriesgadas pero informativas ("exploración"). Después, recopilamos el ordenamiento de uniones de mejor rendimiento probado por el agente, que se convierte en nuestro resultado final. Pero, ¿cómo sabemos que el agente eligió un ordenamiento de uniones válido? Para garantizar la corrección, cada llamada a la herramienta genera un ordenamiento de uniones utilizando salidas de modelo estructuradas, lo que obliga a que la salida del modelo coincida con una gramática que especificamos para admitir solo reordenamientos de uniones válidos. Tenga en cuenta que esto difiere del trabajo anterior [B] que pide al LLM que elija un ordenamiento de uniones instantáneamente en la "ruta crítica" del optimizador de consultas; en cambio, el LLM actúa como un experimentador fuera de línea que prueba muchos planes candidatos y aprende de los resultados observados, ¡igual que un humano ajustando un ordenamiento de uniones manualmente!.
Para evaluar nuestro agente en DBR, utilizamos el Join Order Benchmark (JOB), un conjunto de consultas diseñadas para ser difíciles de optimizar. Dado que el conjunto de datos utilizado por JOB, el conjunto de datos de IMDb, es de solo alrededor de 2 GB (y, por lo tanto, Databricks podía procesar incluso ordenamientos de uniones deficientes con bastante rapidez), escalamos el conjunto de datos duplicando cada fila 10 veces [C].
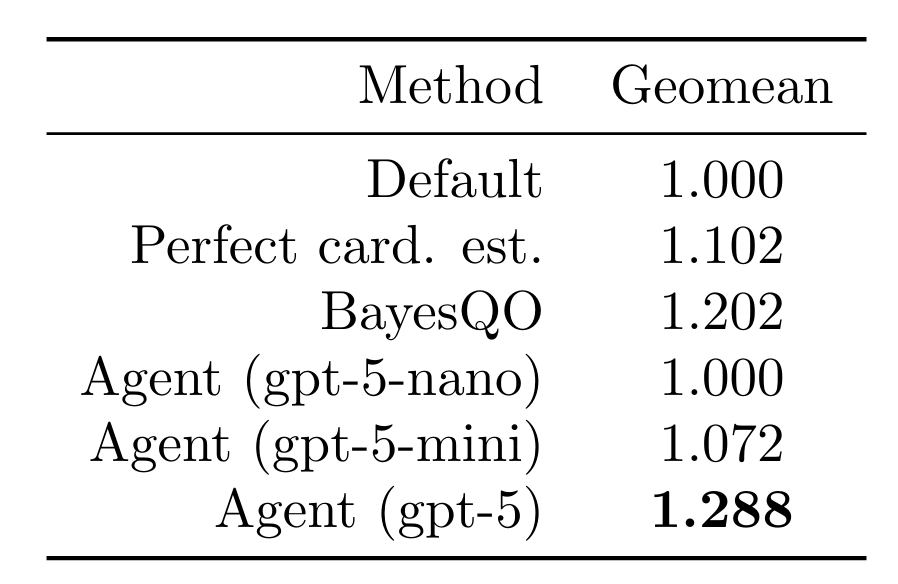
Permitimos que nuestro agente probara 15 ordenamientos de uniones (rollouts) por consulta para las 113 consultas en el benchmark de ordenamiento de uniones. Informamos los resultados sobre el mejor ordenamiento de uniones encontrado para cada consulta. Al usar un modelo de vanguardia, el agente pudo mejorar la latencia de la consulta en un factor de 1.288 (media geométrica). Esto supera el uso de estimaciones de cardinalidad perfectas (intratables en la práctica), modelos más pequeños y el reciente optimizador fuera de línea BayesQO (aunque BayesQO fue diseñado para PostgreSQL, no para Databricks).
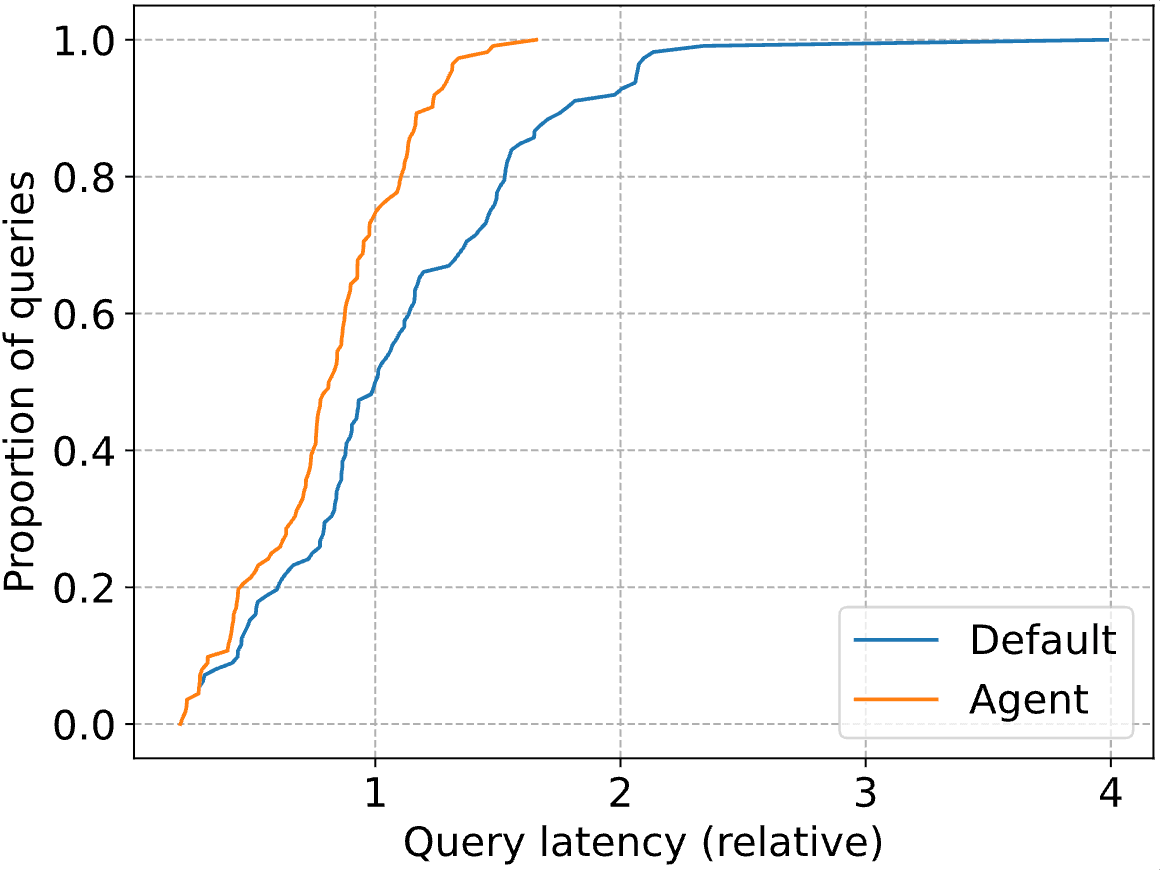
Las ganancias realmente impresionantes están en la cola de la distribución, con la latencia de consulta P90 reducida en un 41%. A continuación, trazamos la CDF completa tanto para el optimizador Databricks estándar ("Default") como para nuestro agente ("Agent"). Las latencias de consulta se normalizan a la latencia mediana del optimizador Databricks (es decir, en 1, la línea azul alcanza una proporción de 0.5).
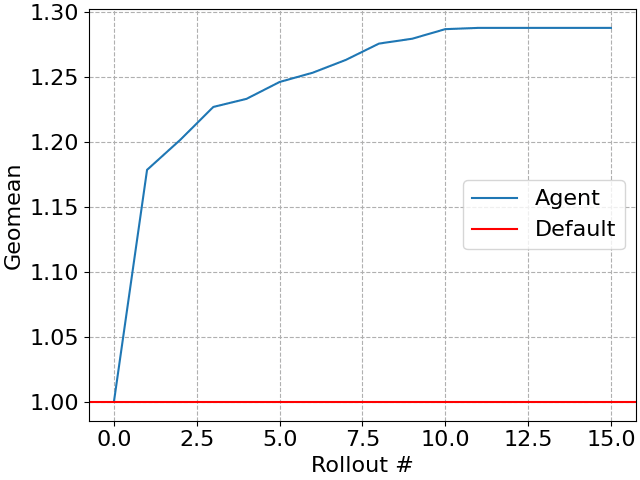
Nuestro agente mejora progresivamente la carga de trabajo con cada plan probado (a veces llamado rollout), creando un simple "algoritmo en cualquier momento" donde presupuestos de tiempo más grandes se pueden traducir en un mayor rendimiento de la consulta. Por supuesto, eventualmente el rendimiento de la consulta dejará de mejorar.
Una de las mayores mejoras que encontró nuestro agente fue en la consulta 5b, una simple unión de 5 vías que busca compañías de producción estadounidenses que lanzaron una película posterior a 2010 en VHS con una nota que hace referencia a 1994. El optimizador de Databricks se centró primero en encontrar compañías de producción estadounidenses de VHS (lo cual es realmente selectivo, produciendo solo 12 filas). El agente encuentra un plan que primero busca lanzamientos de VHS que hagan referencia a 1994, lo que resulta ser significativamente más rápido. Esto se debe a que la consulta utiliza predicados LIKE para identificar lanzamientos de VHS, que son excepcionalmente difíciles para los estimadores de cardinalidad.
Nuestro prototipo demuestra la promesa de los sistemas agénticos para reparar y mejorar autónomamente las consultas de bases de datos. Este ejercicio planteó varias preguntas sobre el diseño de agentes en nuestras mentes:
- ¿Qué herramientas deberíamos darle al agente? En nuestro enfoque actual, el agente puede ejecutar órdenes de unión candidatas. ¿Por qué no permitir que el agente emita consultas de cardinalidad específicas (por ejemplo, calcular el tamaño de un subplan particular), o consultas para probar ciertas suposiciones sobre los datos (por ejemplo, para determinar que no hubo lanzamientos de DVD antes de 1995)?
- ¿Cuándo debería activarse esta optimización agéntica? Seguramente, un usuario puede marcar manualmente una consulta problemática para su intervención. Pero, ¿podríamos también aplicar proactivamente esta optimización a consultas que se ejecutan regularmente? ¿Cómo podemos determinar si una consulta tiene “potencial” de optimización?
- ¿Podemos entender automáticamente las mejoras? Cuando el agente encuentra un orden de unión mejor que el encontrado por el optimizador predeterminado, este orden de unión puede verse como una prueba de que el optimizador predeterminado está eligiendo un orden subóptimo. Si el agente corrige un error sistemático en el optimizador subyacente, ¿podemos descubrirlo y usarlo para mejorar el optimizador?
Por supuesto, no somos los únicos que pensamos en el potencial de los LLM para la optimización de consultas [D]. En Databricks, estamos entusiasmados con la posibilidad de aprovechar la generalización de los LLM para mejorar los propios sistemas de datos.
Si está interesado en este tema, consulte también nuestra continuación del blog de UCB sobre "¿Cómo piensan los agentes LLM a través de los órdenes de unión SQL?".
Únete a nosotros
Mientras miramos hacia el futuro, estamos emocionados de seguir ampliando los límites de cómo la IA puede dar forma a las optimizaciones de bases de datos. Si te apasiona construir la próxima generación de motores de bases de datos, ¡únete a nosotros!
1 Databricks utiliza técnicas como filtros en tiempo de ejecución para mitigar el impacto de órdenes de unión deficientes. Los resultados presentados aquí incluyen esas técnicas.
Notas
A. Las técnicas para la estimación de cardinalidad han incluido, por ejemplo, retroalimentación adaptativa, aprendizaje profundo, modelado de distribución, teoría de bases de datos, teoría del aprendizaje y descomposiciones de factores. Trabajos anteriores también han intentado reemplazar por completo la arquitectura tradicional del optimizador de consultas con aprendizajeprofundo de refuerzo, bandidos multi-armados, optimización bayesiana, o algoritmos de unión más avanzados.
B. Se han utilizado enfoques basados en RAG, por ejemplo, para construir sistemas de “LLM en la ruta crítica”.
C. Aunque rudimentario, este enfoque se ha utilizado en trabajos anteriores.
D. Otros investigadores han propuesto sistemas de reparación de consultas basados en RAG, sistemas de reescritura de consultas potenciados por LLM, e incluso sistemas de bases de datos completos sintetizados por LLMs.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.