Mejores prácticas para Model Serving con alto QPS en Databricks
Potencie las aplicaciones de ML en tiempo real de forma nativa dentro de la Lakehouse
por Tejas Sundaresan, Anshul Gupta, Arjun DCunha y Mike Del Balso
- Model Serving admite puntos de conexión en tiempo real que escalan a más de 300 mil QPS (CPU), con un motor mejorado especializado para ML en tiempo real de baja latencia.
- Los clientes utilizan Model Serving para potenciar aplicaciones de ML en tiempo real de alto QPS, como sistemas de recomendación, detección de fraudes, búsqueda y otros casos de uso.
- Utilice puntos de conexión optimizados para la ruta, mejores prácticas para puntos de conexión y optimizaciones del lado del cliente para alcanzar objetivos de alto rendimiento al servir sus modelos.
Los clientes esperan respuestas instantáneas en cada interacción, ya sea una recomendación generada en milisegundos, un cargo fraudulento bloqueado antes de que se procese o un resultado de búsqueda que le parezca inmediato al usuario. A escala, ofrecer estas experiencias depende de los sistemas de servicio de modelos que se mantienen rápidos, estables y predecibles, incluso bajo una carga sostenida y desigual.
A medida que el tráfico aumenta a decenas o cientos de miles de solicitudes por segundo, muchos equipos se enfrentan al mismo conjunto de desafíos. La latencia se vuelve inconsistente, los costos de infraestructura aumentan y los sistemas requieren un ajuste constante para manejar los picos y las caídas de la demanda. Las fallas también se vuelven más difíciles de diagnosticar a medida que se unen más componentes, lo que aleja a los equipos de la mejora de los modelos y los obliga a centrarse en mantener los sistemas de producción en funcionamiento.
En esta publicación se explica cómo el servicio de modelos en Databricks admite cargas de trabajo en tiempo real con un alto QPS y se describen las mejores prácticas concretas que se pueden aplicar para lograr una baja latencia, un alto rendimiento y un desempeño predecible en la producción.
Servicio de modelos de Databricks: Sencillo y escalable para cargas de trabajo con un QPS alto
Databricks Model Serving proporciona una infraestructura de servicio totalmente administrada y escalable directamente dentro de su lakehouse de Databricks. Simplemente, toma un modelo existente de tu registro de modelos, despliégalo y obtén un endpoint REST en una infraestructura administrada que sea altamente escalable y esté optimizada para un tráfico de QPS alto.
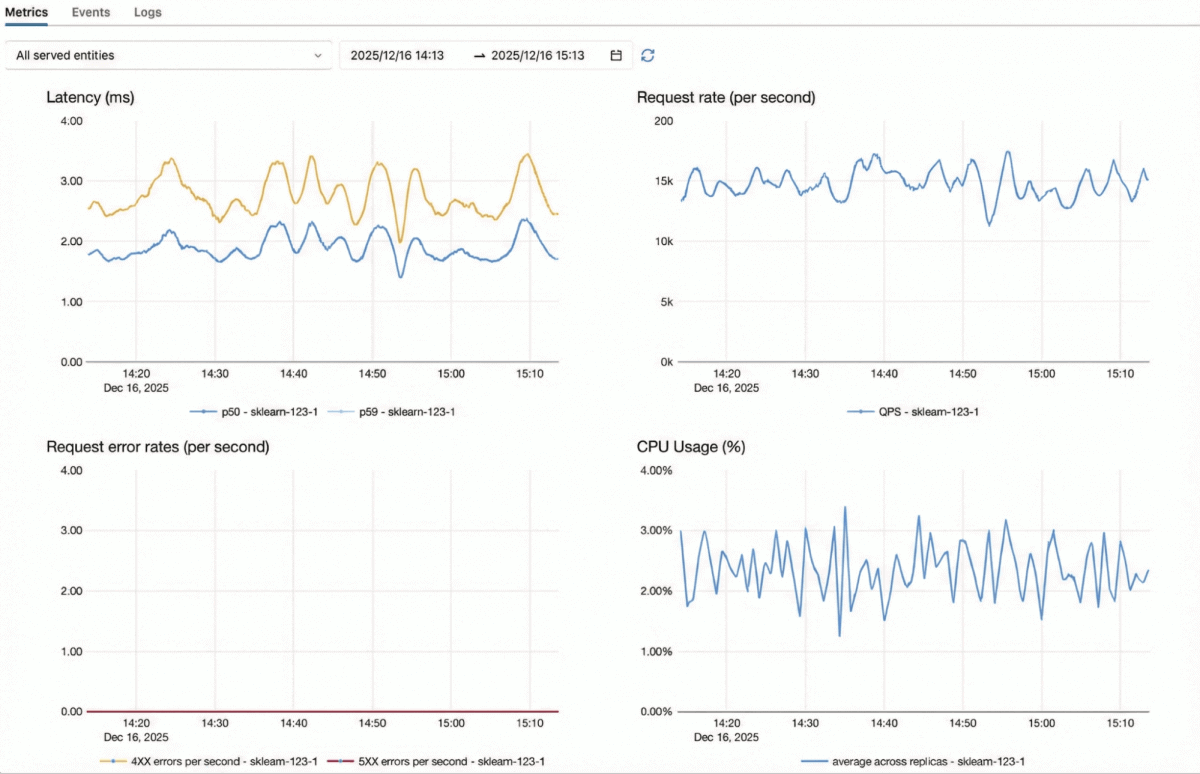
El servicio de modelos de Databricks está optimizado para cargas de trabajo de misión crítica con un QPS alto:
- Motor adaptativo en tiempo real: un servidor de modelos que se optimiza automáticamente y se adapta a la carga de trabajo de cada modelo, lo que genera un mayor rendimiento y una mejor utilización de los recursos con el mismo hardware.
- Arquitectura totalmente escalable de forma horizontal: nuestro servidor de inferencia, capa de autenticación, proxy y limitador de velocidad están diseñados para escalar de forma independiente, lo que permite que el sistema soporte volúmenes de solicitudes muy altos.
- Escalamiento elástico rápido: los servidores de inferencia pueden escalar vertical y horizontalmente para adaptarse a picos o caídas repentinas de tráfico sin necesidad de sobreaprovisionamiento.
- Integración nativa del almacén de características: El servicio de características de Databricks se integra a la perfección con Model Serving, lo que le permite implementar características y modelos juntos como una sola aplicación completa.
- Nativo de Lakehouse: Los clientes pueden centralizar las características, el entrenamiento, MLOps a través de MLFlow, el servicio y el monitoreo en tiempo real de sus sistemas de ML de producción en una pila unificada, lo que conduce a una menor complejidad de las operaciones y a implementaciones más rápidas.
Databricks Model Serving permite a nuestro equipo implementar modelos de machine learning con la confiabilidad y la escala necesarias para aplicaciones en tiempo real. Está diseñado para manejar cargas de trabajo de alto QPS mientras maximiza la utilización del hardware. Además, Databricks ofrece una solución de Feature Store de última generación con búsquedas superrápidas necesarias para dichas cargas de trabajo. Con estas capacidades, nuestros ingenieros de ML pueden centrarse en lo que importa: perfeccionar el rendimiento del modelo y mejorar la experiencia del usuario. —Bojan Babic, ingeniero de investigación, You.com
Mejores prácticas para lograr un alto rendimiento de QPS en el servicio de modelos
Con esta base establecida, el siguiente paso es optimizar sus endpoints, modelos y aplicaciones cliente para lograr de manera consistente un alto rendimiento y una baja latencia, especialmente a medida que aumenta el tráfico. Las siguientes prácticas recomendadas respaldan implementaciones de clientes reales que ejecutan de millones a miles de millones de inferencias todos los días.
Consulta nuestra guía de prácticas recomendadas para obtener más detalles.
Práctica recomendada 1: reducir la latencia mediante el uso de endpoints con optimización de rutas
Un primer paso clave para garantizar que la capa de red esté optimizada para un alto rendimiento/QPS y una baja latencia. El servicio de modelos lo hace por usted mediante endpoints con optimización de ruta. Cuando habilita la optimización de ruta en un endpoint, el servicio de modelos de Databricks optimiza la red y el enrutamiento para las solicitudes de inferencia, lo que resulta en una comunicación más rápida y directa entre su cliente y el modelo. Esto reduce considerablemente la cantidad de tiempo que tarda una solicitud en llegar al modelo y es especialmente útil para aplicaciones de baja latencia, como los sistemas de recomendación, la búsqueda y la detección de fraudes.

{kind=link}
Mejor práctica 2: Optimizar el modelo y hacer que los endpoints sean eficientes
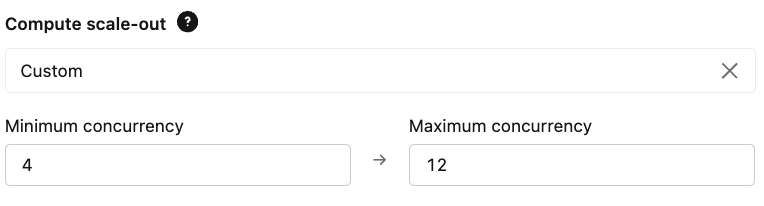
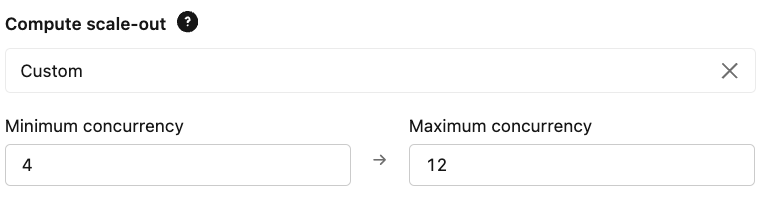
En escenarios de alto rendimiento, reducir la complejidad del modelo, descargar el procesamiento del endpoint de servicio y elegir los objetivos de simultaneidad correctos ayuda a que su endpoint escale a grandes volúmenes de solicitudes con la cantidad justa de computación necesaria. De esta manera, sus endpoints son rentables, pero aun así pueden escalar para alcanzar los objetivos de rendimiento.
- Tamaño y complejidad del modelo: los modelos más pequeños y menos complejos generalmente dan como resultado tiempos de inferencia más rápidos y un QPS más alto. Considere técnicas como la cuantificación o la poda de modelos si su modelo es grande.
- Preprocesamiento y posprocesamiento: descargue los pasos complejos de preprocesamiento y posprocesamiento del endpoint de servicio siempre que sea posible. Esto garantiza que su endpoint de servicio del modelo solo realice el paso crucial de la inferencia.
- Escalado: Configure sus límites de simultaneidad aprovisionada en función de sus requisitos esperados de QPS y latencia. Esto garantiza que el endpoint sea suficiente para manejar la carga base y que el máximo permita la demanda máxima.
{kind=link}
Con Databricks Model Serving, podemos manejar cargas de trabajo de alto QPS, como la personalización y las recomendaciones, en tiempo real. Les da a nuestras marcas la escala y la velocidad necesarias para ofrecer experiencias de contenido personalizadas a nuestros millones de lectores. —Oscar Celma, vicepresidente sénior de ciencia de datos y análisis de productos en Conde Nast
Mejor práctica 3: optimizar el código del lado del cliente
La optimización del código del lado del cliente garantiza que las solicitudes se procesen rápidamente y que tus instancias de computación de endpoint se utilicen en su totalidad, lo que se traduce en un mejor rendimiento de QPS, un ahorro de costos y una menor latencia.
- Agrupación de conexiones: Utilice la agrupación de conexiones del lado del cliente para reducir la sobrecarga de establecer nuevas conexiones para cada solicitud. El SDK de Databricks siempre utiliza las prácticas recomendadas de conexión; sin embargo, si necesita usar su propio cliente, tenga en cuenta la estrategia de administración de conexiones.
- Tamaño de la carga útil: Mantenga las cargas útiles de solicitud y respuesta lo más pequeñas posible para minimizar el tiempo de transferencia de la red.
- Procesamiento por lotes del lado del cliente: si su aplicación puede enviar varias solicitudes en una sola llamada, habilite el procesamiento por lotes del lado del cliente. Esto puede reducir significativamente la sobrecarga por predicción.
Agrupe las solicitudes en lotes al llamar a los endpoints de Databricks Model Serving.
Empieza hoy
- ¡Pruebe Model Serving de Databricks! Comience a implementar modelos de ML como una API REST.
- Para profundizar: Consulte la documentación de Databricks para el servicio de modelos personalizados.
- Guía de QPS alto: consulta la guía de prácticas recomendadas para el servicio de QPS alto en Databricks Model Serving en Databricks.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.