Creación de un marco de análisis de pruebas A/B para juegos móviles en Databricks
Cómo HARDlight escaló el análisis de experimentos con modelado estadístico automatizado, información gobernada, un panel de actualización diaria y resúmenes generados por LLM.
por Sanjay Ashok, Jack Holdsworth, Tingting Wan, Joel Dias, Richard Carr y Monika Kolodziejczyk
- De datos a decisiones: cómo Sega HARDlight automatizó el análisis de pruebas A/B en Databricks mediante la ingesta estandarizada de experimentos, modelado estadístico y publicación de resultados, reduciendo los flujos de trabajo manuales y permitiendo un aumento de 2 veces en la capacidad de experimentación mensual sin personal adicional.
- Información para cada audiencia: monitorización con actualización diaria con un resumen de LLM y métricas progresivamente granulares, diagnósticos y acciones recomendadas que democratizan el acceso a información procesable en toda la organización.
- Confianza a través de la transparencia: la inferencia estadística coherente y las vistas de IA/BI accesibles ayudaron a los equipos a comprender los resultados, generar confianza y adoptar un enfoque científico compartido para la experimentación.
Introducción
Los estudios de juegos para móviles dependen de la experimentación continua para refinar la jugabilidad, la monetización y las operaciones en vivo. A medida que la experimentación escala, el análisis a menudo se convierte en el factor limitante. Los resultados a menudo se unen manualmente, los enfoques estadísticos varían según el analista y las ideas llegan días después de que surgen las señales clave. Con el tiempo, esto crea fricción: iteración más lenta, conclusiones inconsistentes y una disminución de la confianza en las pruebas A/B como una herramienta de decisión confiable.
El Desafío
En HARDlight, el desafío no era solo la velocidad, sino la confianza. Diferentes enfoques llevaron a diferentes interpretaciones, lo que dificultó la alineación y debilitó la confianza en la experimentación como una herramienta científica de toma de decisiones. Algunos interesados necesitaban un estado diario simple, otros querían comprender el comportamiento del jugador o el impacto comercial, y un grupo más pequeño requería una validación profunda de palancas de juego específicas. Los paneles e informes existentes lucharon para satisfacer eficazmente todo este espectro de necesidades. Para que la experimentación escalara, HARDlight necesitaba una forma de estandarizar la inferencia, hacer que los resultados fueran accesibles en diferentes niveles de profundidad y reconstruir la confianza en las pruebas A/B como un proceso científico compartido de toma de decisiones.
Para abordar esto, HARDlight construyó un marco de análisis de pruebas A/B nativo de Databricks que automatiza el camino desde los datos del experimento hasta la información lista para la toma de decisiones. El análisis estadístico se realizó aguas arriba de manera repetible y transparente, y Databricks AI/BI expuso los resultados a través de una experiencia de actualización diaria que comenzó con un resumen generado por LLM y permite una exploración más profunda con vistas progresivamente granulares. Al final de cada experimento, los resultados se congelaron y conservaron, asegurando que las decisiones, el contexto y los aprendizajes permanezcan disponibles mucho después de que concluya la prueba.
La Solución: Pruebas A/B Automatizadas en Databricks
El marco de HARDlight automatiza la experimentación desde la ingesta hasta el soporte de decisiones. Dentro de Databricks, las definiciones de experimentos y la telemetría se estandarizan, se aplica el modelado estadístico de manera consistente y los resultados se publican en un panel en capas que se actualiza diariamente durante la ventana de ejecución. Un resumen de LLM en la parte superior proporciona una vista accesible del estado del experimento, mientras que las secciones más profundas exponen los KPI, los diagnósticos y las acciones recomendadas para los usuarios expertos.
La elección de Databricks permite la gobernanza y la repetibilidad en todos los equipos. Unity Catalog proporciona un plano de control único para los permisos y el linaje de los activos del experimento; Spark Declarative Pipelines orquesta canalizaciones confiables para la ingesta y las transformaciones de experimentos; y MLflow admite el seguimiento de experimentos y el empaquetado de modelos para un análisis reproducible. Juntas, estas capacidades mantienen los datos y los análisis gobernados, consistentes y fáciles de operar en el Lakehouse.
Una innovación clave es el "panel congelado" al final de la ejecución. En lugar de continuar con la siguiente actualización, el marco conserva la instantánea final y las decisiones tomadas, junto con las acciones recomendadas. Esto institucionaliza los aprendizajes de experimentos pasados y permite a los interesados revisar los resultados sin ambigüedades.
Arquitectura Técnica
El marco de experimentación se construye como un sistema nativo de Databricks que separa el procesamiento de datos, la inferencia estadística y el consumo, al tiempo que mantiene todas las salidas gobernadas y reproducibles por defecto. Este diseño garantiza que el rigor analítico escale sin aumentar la sobrecarga operativa ni fragmentar la interpretación entre equipos.
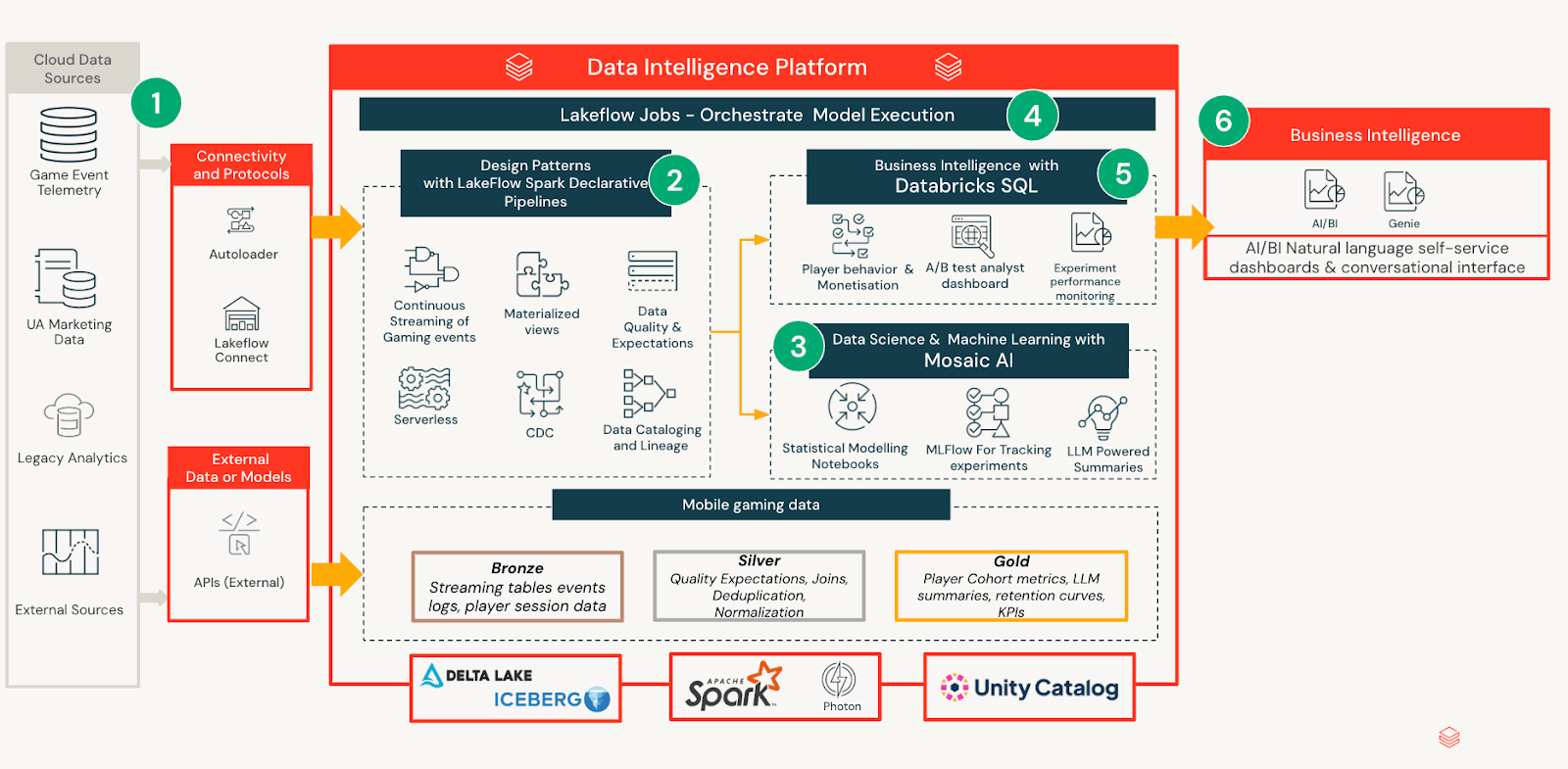
Ingesta y Modelado de Datos
Las definiciones de experimentos, la telemetría de jugadores y las métricas de resultados se ingieren de canalizaciones internas y se curan en tablas gobernadas con esquemas consistentes. Esta estandarización permite a los analistas y equipos de producto razonar sobre los experimentos de manera consistente, independientemente del diseño o la duración de la prueba. Se utilizan cuadernos para calcular modelos estadísticos que calculan las estimaciones de efectos, las incertidumbres y los impactos a nivel de segmento a lo largo del tiempo. En lugar de incrustar la lógica en paneles o informes, todas las salidas analíticas se materializan en un modelo unificado de análisis de experimentos. Esto crea una capa semántica estable en la que los consumidores posteriores pueden confiar sin volver a ejecutar el análisis ni reinterpretar los resultados.
Entrega de Información impulsada por AI/BI
Sobre esta capa de análisis gobernada, Databricks AI/BI proporciona una interfaz accesible para consumir los resultados de los experimentos. Cada actualización diaria genera un resumen conciso de LLM dirigido a partes interesadas no técnicas, traduciendo los resultados estadísticos validados a lenguaje natural. El panel utiliza la divulgación progresiva: los usuarios pueden detenerse en el resumen cuando estén satisfechos, o explorar capas más profundas de métricas, diagnósticos y análisis de segmentos a medida que aumenta su curiosidad. Esta experiencia en capas permite un escaneo rápido y, al mismo tiempo, mantiene la profundidad analítica disponible para la validación experta.

Ciclo de Vida y Persistencia del Experimento
Durante la fase activa, el panel se actualiza diariamente para que los equipos puedan seguir la trayectoria y reaccionar a las señales. Al concluir, el panel se congela para conservar los resultados, las decisiones y las acciones recomendadas. Este ciclo de vida crea un registro auditable que acelera la incorporación y reduce el análisis duplicado en experimentos futuros.
Capas del Panel Explicadas
El panel está diseñado para guiar a los usuarios a través de los resultados de un experimento en una secuencia clara y deliberada. Comienza con simplicidad y revela gradualmente más detalles para aquellos interesados en explorar más a fondo. Cada sección aborda una pregunta diferente, y es totalmente aceptable detenerse una vez que el lector ha obtenido la información necesaria.
Resumen del experimento generado por LLM: En la parte superior del panel hay un resumen generado por LLM. Mientras un experimento está activo, esto proporciona una vista simple y de alto nivel de cómo van las cosas, destacando las señales tempranas sin sacar conclusiones prematuras.
Una vez que el experimento concluye, el resumen cambia de función. Se convierte en una explicación clara de lo que sucedió, destacando las métricas que se movieron con alta confianza, en orden de prioridad y en lenguaje sencillo. El objetivo es ayudar a los equipos a comprender rápidamente el resultado y por qué es importante.
Resultados confirmados e impacto estadístico: Para audiencias más técnicas, la siguiente sección presenta una vista estructurada de los resultados estadísticamente significativos. Las métricas clave como el valor de vida del jugador (LTV) y la retención se enumeran junto con los tamaños del efecto y los niveles de confianza, lo que facilita la validación de las conclusiones sin tener que examinar el análisis en bruto.
Impacto estimado en el valor de vida: El panel muestra luego el impacto estimado en el valor de vida del jugador para los grupos de control y variantes. La incertidumbre y los márgenes de error se muestran explícitamente, lo que refuerza que estas son estimaciones informadas, no pronósticos absolutos.
Impacto en los ingresos por fuente: Los resultados se desglosan por flujo de ingresos, incluidos anuncios, compras dentro de la aplicación e ingresos totales. Esto ayuda a los equipos a comprender si los cambios son de base amplia o impulsados por canales de monetización específicos.
Participación y comportamiento del jugador: Más allá de los ingresos, se exponen métricas de participación como la retención y el comportamiento de la sesión para garantizar que las ganancias comerciales se consideren junto con la experiencia del jugador y la salud a largo plazo.
Análisis a nivel de segmento: La segmentación es fundamental para cómo HARDlight diseña y evalúa experimentos. Esta sección muestra cómo responden diferentes segmentos de jugadores a un cambio, ya sea definido por retención, progresión u otros rasgos de comportamiento. Ayuda a los equipos a confirmar que las experiencias dirigidas funcionan según lo previsto, sin dañar otras partes de la base de jugadores.
Mecánicas de monetización y economía del juego: Las capas más profundas exploran cómo los experimentos afectan los sistemas del juego, incluido el rendimiento de los anuncios por ubicación, el rendimiento de las compras dentro de la aplicación por categoría de producto y los cambios en los flujos de moneda dura y blanda entre fuentes y sumideros.
Bucles de juego principales y apéndices: En el nivel más profundo, los gráficos y tablas detallados cubren las mecánicas de juego como carreras, personajes y elementos, junto con elementos visuales estadísticos de apoyo. Esta capa está destinada a usuarios expertos que desean total transparencia o necesitan reutilizar información en trabajos futuros.
Juntas, estas capas permiten que la información se desarrolle de forma natural. Los equipos pueden moverse rápidamente cuando la respuesta es clara, o profundizar cuando surgen preguntas, todo mientras trabajan desde la misma fuente de datos gobernada y confiable.
Esta estructura es posible gracias a Databricks AI/BI, que permite exponer resultados analíticos complejos de manera limpia sin incrustar código personalizado o flujos de trabajo solo para analistas en los paneles. Los resultados estadísticos, las proyecciones y los análisis a nivel de segmento se calculan aguas arriba en cuadernos y se materializan en tablas gobernadas, mientras que AI/BI proporciona una capa de presentación flexible en la parte superior. Esto elimina la necesidad de ejecutar Python dentro de los paneles, simplifica el mantenimiento y hace posible que un equipo reducido itere y evolucione el sistema con el tiempo.
Igualmente importante, AI/BI hace posible servir a audiencias muy diferentes a partir de los mismos datos subyacentes. Los resúmenes narrativos, los resultados tabulares, los gráficos y los diagnósticos profundos pueden coexistir sin duplicar la lógica ni fragmentar la interpretación. Este fue un cambio clave con respecto a los enfoques anteriores, donde las limitaciones de las herramientas obligaban a comprometer la profundidad analítica, la accesibilidad y la sostenibilidad.
Impacto y resultados
El marco ha cambiado fundamentalmente la forma en que opera la experimentación en HARDlight. Al automatizar el análisis y estandarizar la inferencia estadística, el equipo de datos ha reducido el esfuerzo manual en más de ocho horas por semana. Al estandarizar las ejecuciones de experimentos con Databricks Workflows, el equipo eliminó gran parte del trabajo de configuración manual requerido previamente para cada análisis. Esto ahorra aproximadamente un día por experimento y ha permitido un aumento específico de dos veces en la capacidad mensual de pruebas A/B sin aumentar la plantilla.
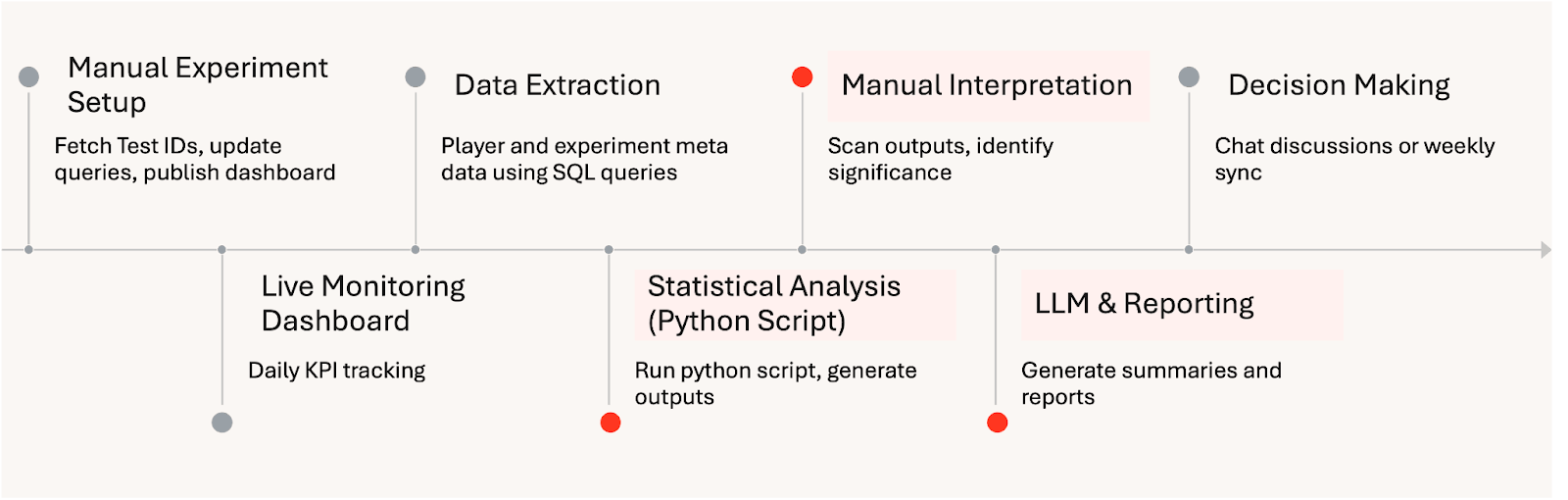
Flujo de trabajo de análisis de experimentos manual:
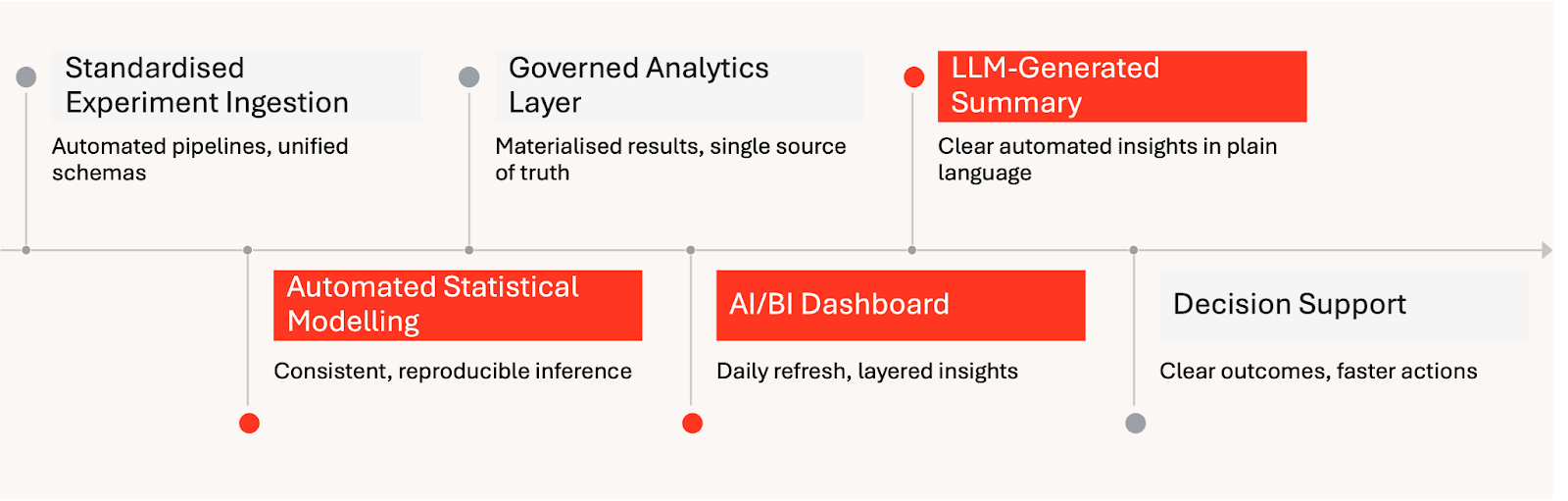
Entrega automatizada de información de experimentos en Databricks:
Más allá de las ganancias de eficiencia, el sistema ha mejorado la coherencia y la confianza en los resultados. El archivo de panel congelado ahora actúa como una fuente de verdad duradera para los experimentos completados, reduciendo el análisis repetido y facilitando que los equipos revisen decisiones pasadas con contexto completo. Esto ha reducido significativamente la sobrecarga de mantenimiento del conocimiento histórico entre equipos.
Quizás lo más importante es que el marco ha cambiado la forma en que se consumen los insights en el estudio. Con múltiples experimentos ejecutándose en paralelo, los equipos ahora reciben actualizaciones diarias habilitadas por IA/BI que reemplazan la agregación e interpretación manual de varios días. Genie se habilitará directamente en el panel, lo que permitirá a los usuarios hacer preguntas sobre lo que están viendo y explorar los resultados en sus propias palabras, sin necesidad de comprender el modelo de datos subyacente. En conjunto, los resúmenes claros, las métricas gobernadas, los resultados estadísticos transparentes y el acceso conversacional han ayudado a generar confianza entre los equipos de producto, LiveOps e ingeniería, reforzando la experimentación como una forma de trabajo científica y compartida.
Próximos pasos
HARDlight planea extender el marco con una aplicación de pronóstico, extendiendo el marco desde análisis descriptivos e inferenciales hasta orientación prospectiva. La visión más amplia es la experimentación predictiva y la optimización de circuito cerrado — utilizando el Lakehouse para automatizar más del ciclo desde la hipótesis hasta el despliegue, al tiempo que se preserva la gobernanza y la consistencia con Unity Catalog, Spark Declarative Pipelines y MLflow. Este enfoque centrado en el panel puede tener un impacto significativo para otros estudios con necesidades similares, aplicando resúmenes de LLM sobre métricas gobernadas y diagnósticos para escalar la experimentación con confianza en Databricks.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.