Creación de un Asistente de Conocimiento sobre Código
Evaluación de estrategias de fragmentación con MLflow
por Daniel Liden
- RAG sobre código tiene desafíos únicos de fragmentación: dividir funciones a mitad de cuerpo o descartar el contexto estructural degrada la recuperación incluso cuando encuentras el archivo correcto.
- Utilizamos el marco de evaluación GenAI de MLflow con jueces LLM integrados y personalizados para comparar sistemáticamente tres estrategias de fragmentación utilizadas con Databricks Knowledge Assistant.
- El propio proceso de evaluación fue la lección principal: los conjuntos de datos de evaluación estructurados, los resultados rastreables y los jueces LLM personalizados alineados con lo que realmente te importa son lo que hace que la iteración de RAG sea práctica.
Cuando los desarrolladores se unen a un nuevo proyecto o necesitan trabajar en una base de código desconocida, los asistentes de conocimiento como Databricks Knowledge Assistant les ayudan a ponerse al día respondiendo preguntas en lenguaje natural sobre el código. Pero la calidad de la respuesta depende en gran medida de cómo se preparó y agregó el código fuente y el contexto circundante. Un factor clave es la división en fragmentos (chunking): cómo divide los archivos fuente en piezas para indexación y recuperación. El código hace que esto sea complicado. Si rompe una función a mitad de su cuerpo o elimina su contexto de clase, incluso un asistente capaz tendrá dificultades para responder preguntas sobre ella.
Construimos tres Asistentes de Conocimiento en nuestro repositorio de demostración de GitHub Casper’s Kitchens, cada uno utilizando una estrategia de división en fragmentos diferente, desde una simple línea base de tamaño fijo hasta un enfoque consciente de la estructura que analiza el código en sus componentes sintácticos. El repositorio simula un negocio de cocinas fantasma en Databricks, utilizando una amplia gama de características que incluyen canalizaciones de Lakeflow, agentes DSPy y Databricks Asset Bundles (DABs), con documentación en archivos markdown y celdas de notebook. Las dependencias entre archivos, los formatos de archivo mixtos y los patrones específicos del dominio lo convierten en el tipo de proyecto donde un asistente de conocimiento capaz sería de gran ayuda.
Esta publicación detalla qué hace que trabajar con código sea diferente de trabajar con documentos empresariales típicos, cómo implementamos cada estrategia de división en fragmentos como un Databricks Knowledge Assistant y cómo utilizamos el marco de evaluación de MLflow para compararlos. Puede encontrar todo el código aquí.
Cómo funcionan los asistentes de conocimiento (y por qué el código es diferente)
En el fondo, los asistentes de conocimiento utilizan diversas formas de generación aumentada por recuperación (RAG). Recuperan fragmentos relevantes de los datos fuente, a menudo de un índice de búsqueda vectorial, y los pasan a un modelo de lenguaje grande como contexto para generar una respuesta a la consulta de un usuario.
Databricks Knowledge Assistant se basa en esta base con sofisticadas técnicas de recuperación que incluyen Instructed Retriever, que incorpora la descomposición de consultas, la reordenación informada por el contexto y el razonamiento sobre los metadatos del documento. Estas capacidades contribuyen en gran medida a manejar la complejidad de las bases de código del mundo real, y funcionan mejor cuando los fragmentos subyacentes preservan límites semánticos significativos.
Los asistentes de conocimiento se construyen y evalúan más comúnmente sobre colecciones de documentos empresariales, que tienden a fluir linealmente, con párrafos y secciones. El código tiene jerarquías anidadas: los archivos contienen clases, las clases contienen métodos, los métodos contienen bloques de lógica. La unidad semántica en el código es a menudo una función completa, no un párrafo.
Esto crea desafíos específicos, que incluyen:
- Límites semánticos: Dividir una función a mitad de su cuerpo pierde el contexto necesario para comprender lo que hace. Un fragmento que contiene
deletion_order = ['experiments', 'jobs'...es menos útil si no muestra que esta variable está dentro deUCState.clear_all(). - Dependencias entre archivos: El código hace referencia a otro código. Comprender una función a menudo requiere el contexto de su clase, sus importaciones o funciones relacionadas.
- Tipos de archivo mixtos: Nuestra base de código tiene archivos
.py, notebooks.ipynb(JSON con celdas de código/Markdown), documentación.mdy configuración.yaml, cada uno requiriendo diferentes enfoques de análisis.
Debido a que Databricks Knowledge Assistant le permite usar su propio índice vectorial, puede preparar fragmentos como desee y simplemente apuntar Knowledge Assistant al resultado. Esto nos permitió comparar diferentes enfoques para preparar nuestra base de código para RAG y elegir el mejor.
Estrategias de división en fragmentos
Para ver cómo difieren las estrategias de división en fragmentos en la práctica, considere lo que sucede cuando pregunta: “¿En qué orden ocurre la limpieza de recursos?” La respuesta se encuentra en una clase de utilidad que rastrea experimentos, trabajos y canalizaciones. Su lógica abarca la inicialización, una lista de orden de eliminación y métodos de limpieza. Aquí se explica cómo funciona cada método y cómo afecta el contexto recuperado sobre la clase de limpieza de recursos, UCState.
Línea base ingenua: Fragmentos de caracteres de tamaño fijo
El enfoque más simple es dividir los archivos fuente en intervalos de caracteres fijos con superposición, tratando el código como texto plano. Esto no es lo que elegiría para un sistema RAG listo para producción hoy en día. Ignora la sintaxis y los límites semánticos, por lo que falla exactamente en las formas que importan en las consultas de código. Pero también es extremadamente fácil de implementar, a menudo “suficientemente bueno” para experimentos rápidos o repositorios con mucha documentación, y común como primer paso, por lo que es una línea base útil.
Esto es lo que produce la división ingenua en fragmentos para una búsqueda de deletion_order en nuestra base de código:
El nombre de la variable se cortó en dos (eletion en lugar de deletion), y el fragmento no incluye el nombre del método. Si alguien busca “UCState deletion order”, este fragmento no coincidirá bien. Además, la lista deletion_order en el método se cortó.
Consciente del lenguaje: Divisores heurísticos de LangChain
El RecursiveCharacterTextSplitter.from_language() de LangChain utiliza separadores específicos del lenguaje (como \nclass y \ndef para Python) para preferir dividir en límites lógicos. Intenta mantener las funciones intactas pero aún así impone límites de tamaño estrictos. Conceptualmente, esto mejora la división ingenua al priorizar las divisiones en límites semánticos probables (como def y class) en lugar de recuentos de caracteres arbitrarios, por lo que es más probable que los fragmentos contengan unidades lógicas completas.
Esto es lo que produjo este enfoque para la misma búsqueda:
El fragmento comienza en un límite más natural, pero aún carece de contexto que muestre de qué archivo o función pertenece, y se corta justo después del inicio de un bucle for.
Basado en AST: Tree-Sitter con encabezados de metadatos
La segmentación basada en árboles de sintaxis abstracta utiliza un analizador como Tree-sitter para comprender la estructura real del código. Un AST es una representación en árbol del código que captura su estructura sintáctica: cómo se organiza el código según las reglas gramaticales de un lenguaje. En lugar de dividir por límites de caracteres o usar patrones heurísticos, una estrategia de segmentación basada en AST analiza el código en un árbol de sintaxis y segmenta en límites semánticos, como funciones, clases o bloques de sentencias. También puede exceder los límites de tamaño cuando sea necesario para mantener una unidad completa junta, en lugar de dividirla a mitad de función.
Utilizamos la biblioteca de Python ASTChunk para manejar la división basada en AST. La biblioteca incluye una opción de expansión de fragmentos que hace que cada fragmento se anteponga con una cabecera de metadatos que muestra la ruta del archivo y la jerarquía de clases/funciones. Este contexto se convierte en parte de la incrustación, lo que ayuda a la recuperación a relacionar las consultas con el código relevante, incluso cuando los términos de la consulta no aparecen en el cuerpo del fragmento.
Aquí está el fragmento que produjo este enfoque para nuestra consulta:
La cabecera nos dice exactamente dónde se encuentra este código: utils/uc_state/state_manager.py → class UCState: → def clear_all(...). Cuando se incrusta, este fragmento tiene una conexión semántica más fuerte con consultas sobre “UCState”, “clear_all” u “orden de eliminación”.
En esta etapa, teníamos algunas intuiciones sobre qué métodos funcionarían mejor en nuestro Asistente de Conocimiento. Pero para saberlo con seguridad, necesitábamos realizar una evaluación sistemática.
Configuración de la Evaluación con MLflow
El framework de evaluación GenAI de MLflow proporciona un conjunto completo de herramientas para comparar LLMs, agentes y sistemas de recuperación. Le das un conjunto de datos de evaluación, una función de predicción y jueces de LLM, y ejecuta cada pregunta a través de tu pipeline y califica los resultados. Así es como lo usamos para comparar los tres métodos de segmentación.
El Conjunto de Datos de Evaluación
Creamos 46 preguntas en una diversa variedad de categorías, desde temas conceptuales amplios hasta consultas detalladas sobre el código.
| Categoría | Recuento | Ejemplo |
|---|---|---|
| Identificación de valores específicos | 7 | "¿Cuál es el orden exacto de eliminación en UCState.clear_all()?" |
| Recuperación de definiciones completas | 8 | "Enumera todos los campos y validadores en el modelo ComplaintResponse." |
| Comprensión de flujos del sistema | 6 | "¿Cómo funciona el pipeline de quejas de extremo a extremo, desde la generación hasta la sincronización de Lakebase?" |
| Comparación de implementaciones de aplicaciones | 13 | "¿En qué se diferencia parse_agent_response entre complaints-manager y refund-manager?" |
| Comparación de frameworks y patrones | 12 | "¿Qué framework de ML utiliza cada agente? ¿Cómo difieren sus patrones de manejo de errores y streaming?" |
Ponderamos deliberadamente el conjunto de datos hacia preguntas de desambiguación donde la base de código tiene código estructuralmente similar en diferentes contextos, como dos aplicaciones con nombres de funciones superpuestos, esquemas de bases de datos paralelos o archivos de configuración que difieren de maneras sutiles. Estas son las consultas que exponen las debilidades de la segmentación con mayor claridad. Si a tus fragmentos les falta metadatos sobre dónde se encuentra el código, el sistema de recuperación tendrá dificultades para diferenciar entre clases y funciones similares que existen en diferentes contextos.
Los Jueces de LLM
Utilizamos tres jueces principales de LLM, cada uno capturando un aspecto diferente de la calidad:
RetrievalSufficiency(incorporado): ¿Contienen los fragmentos recuperados suficiente información para responder la pregunta? Esta es la métrica clave para comparar estrategias de segmentación porque mide la calidad de la recuperación independientemente de la generación.RetrievalGroundedness(incorporado): ¿Está la respuesta basada en el contexto recuperado, o introduce información que no está presente en los fragmentos?answer_correctness(personalizado): Este calificador personalizado clasifica cada respuesta como correcta, parcialmente correcta o incorrecta, lo que la hace un poco más matizada que un juez de corrección estricto de sí/no. Dada la posibilidad de un contexto fragmentado o incompleto, queremos estar atentos a las respuestas que puedan carecer de detalles o tener pequeñas imprecisiones.
Ejecución de la Evaluación
Para mantener la comparación justa, todas las estrategias utilizaron el mismo tamaño de fragmento objetivo (1000 caracteres), superposición (200 caracteres) y modelo de incrustación (databricks-gte-large-en). En la práctica, los tamaños de fragmento finales aún difieren (por ejemplo, la segmentación basada en AST puede expandirse para preservar una unidad semántica completa, mientras que archivos muy pequeños producen naturalmente fragmentos pequeños).
Para cada estrategia de segmentación, escribimos los fragmentos en una tabla Delta, creamos un índice de Búsqueda Vectorial con incrustaciones administradas (usando el modelo de incrustación databricks-gte-large-en, como lo requiere el Asistente de Conocimiento de Databricks), y adjuntamos el índice a un punto final del Asistente de Conocimiento. La documentación cubre la configuración completa.
Evaluamos cada estrategia de segmentación consultando directamente su punto final del Asistente de Conocimiento. La función to_predict_fn() de MLflow envuelve un punto final de servicio como una función de predicción, y dado que los Asistentes de Conocimiento producen rastreos completos de MLflow, incluidos los tramos de recuperación, los jueces integrados pueden inspeccionar tanto los fragmentos recuperados como la respuesta final.
Los jueces de LLM llaman a un juez de LLM a través de Databricks Model Serving. Utilizamos databricks-claude-opus-4-6:
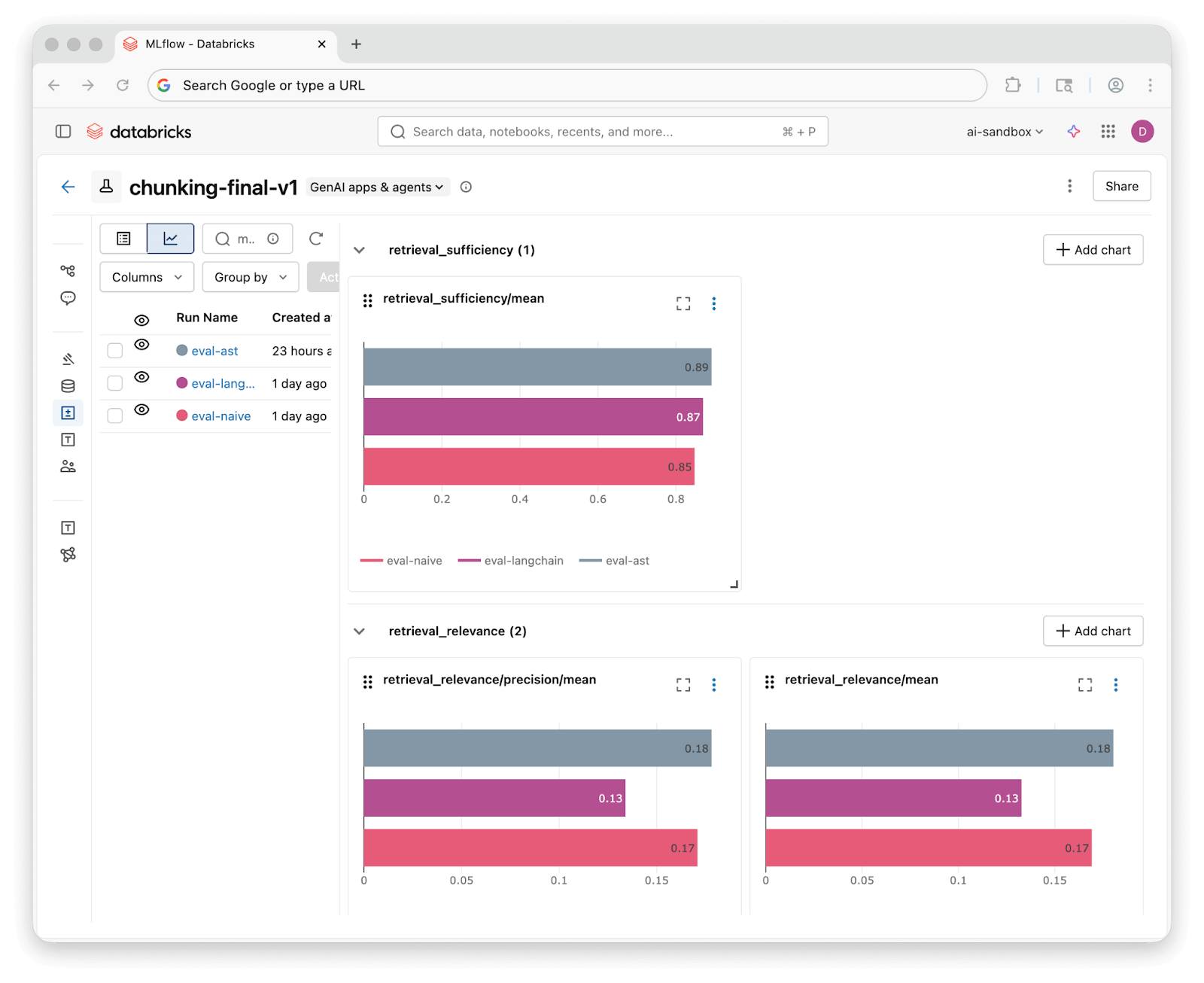
Una vez que se completan las ejecuciones de evaluación, la UI de experimentos de MLflow te permite comparar los resultados de las tres estrategias una al lado de la otra:
Resultados y Lecciones Aprendidas
Ejecutamos las 46 preguntas a través de cada Asistente de Conocimiento y calificamos los resultados con nuestros tres jueces. Esto es lo que encontramos:
| Juez | Naive | Divisor de Texto Consciente del Lenguaje | AST |
|---|---|---|---|
| Suficiencia de Recuperación | 85% | 87% | 89% |
| Fundamentación de la Recuperación | 76% | 72% | 76% |
| Corrección de la Respuesta (personalizada) | 59% completamente correcta (37% parcial) | 61% completamente correcta (37% parcial) | 70% completamente correcta (28% parcial) |
Las tres estrategias logran una suficiencia de recuperación del 85% o más, lo que significa que las técnicas de recuperación del Asistente de Conocimiento encuentran contexto relevante independientemente de cómo se dividió el código. Las diferencias a nivel de recuperación son modestas.
Los resultados de corrección personalizados cuentan la historia más interesante. La división basada en AST produce una respuesta completamente correcta el 70% de las veces, en comparación con el 59% para Naive y el 61% para Language-Aware. Las tres estrategias producen al menos una respuesta parcialmente correcta en casi todos los casos. Mejores fragmentos ayudan al asistente de conocimiento a responder preguntas de manera más completa.
La ventaja se concentra en tipos de preguntas específicos. La división basada en AST se destacó en preguntas de desambiguación, donde existe código estructuralmente similar en varios módulos, debido a que los metadatos añadidos (ruta del archivo, clase, nombre de la función) proporcionan el contexto necesario. Las tres estrategias fueron comparables para la recuperación de definiciones completas y la búsqueda de valores.
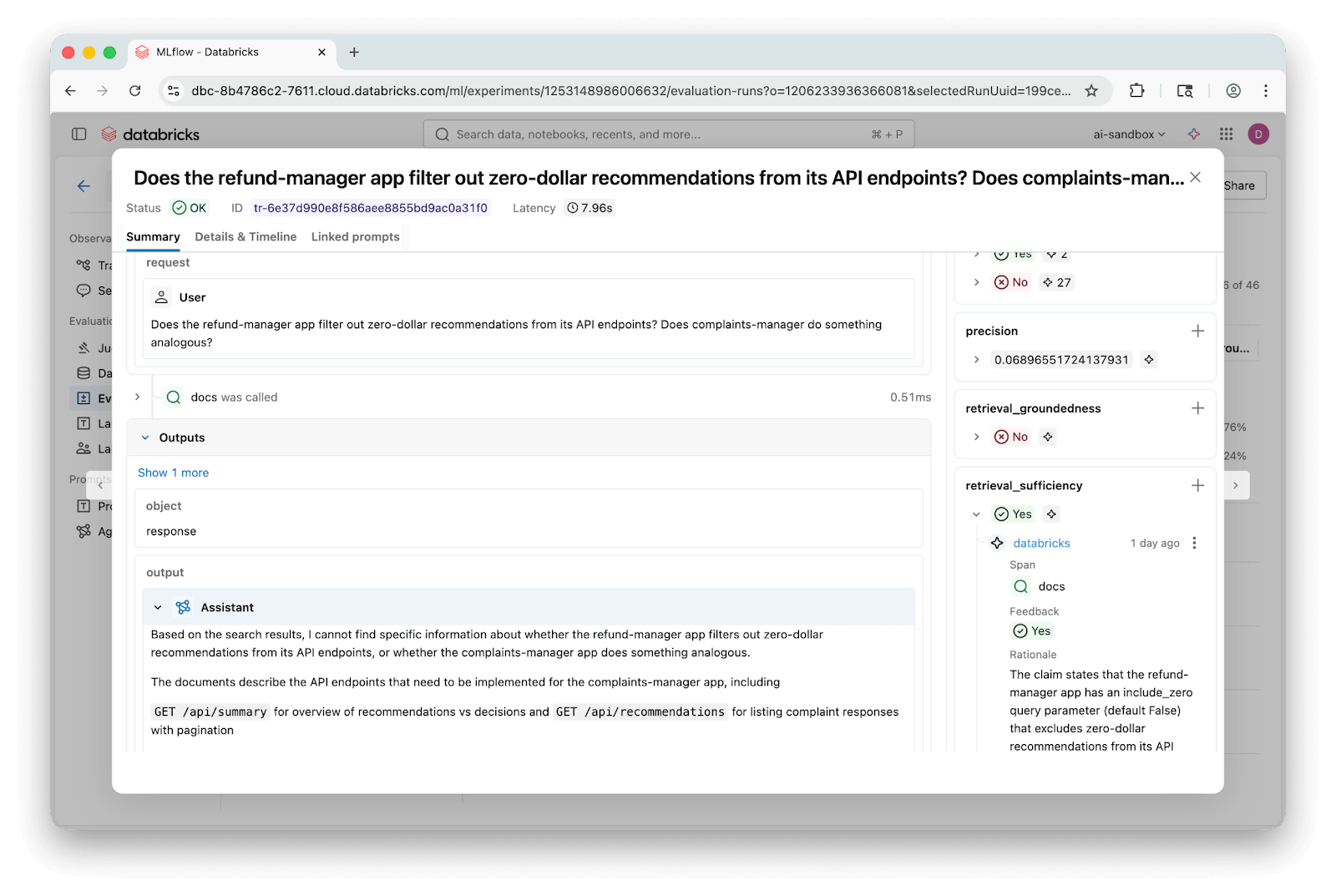
Los rastreos de MLflow facilitan la profundización en preguntas individuales y la visualización exacta de los fragmentos recuperados y dónde divergieron las respuestas:
Esta investigación dejó algunas preguntas sin respuesta: ¿fueron las mejoras que vimos al usar la división basada en AST principalmente una consecuencia de los tamaños de fragmento promedio más grandes? ¿Qué tan dependientes fueron los resultados de la elección del modelo que potencia los jueces de LLM? ¿Nuestras preguntas de evaluación se perdieron categorías importantes que los usuarios reales preguntarían?
Lecciones Aprendidas
El Asistente de Conocimiento de Databricks es muy capaz desde el principio. La suficiencia de recuperación fue alta en las tres estrategias, y casi todas las preguntas obtuvieron al menos una respuesta parcialmente correcta.
La preparación de datos sigue siendo importante. La división basada en AST mejoró la fundamentación y la corrección en esta evaluación, particularmente para preguntas que involucraban la desambiguación de código similar. Incluso las mejoras marginales en la recuperación y la calidad de la respuesta se acumulan en un equipo de desarrolladores que hacen docenas de preguntas al día.
Los jueces de LLM personalizados ayudan a medir lo que realmente nos importa. La API make_judge() de MLflow facilita la creación de jueces de LLM específicos para casos de uso. Nuestro juez personalizado answer_correctness pudo ofrecer una visión más matizada de la corrección que un juez de corrección simple de pasar/fallar.
Las trazas de MLflow simplifican el bucle de evaluación. Puedes investigar preguntas individuales para ver exactamente qué fragmentos se recuperaron y dónde falló la respuesta. Dado que las trazas persisten, puedes volver a puntuar con diferentes jueces sin volver a consultar el punto final.
Referencias
- Databricks Agent Bricks: Knowledge Assistant—Guía de configuración para crear un Asistente de Conocimiento con índices de búsqueda vectorial personalizados.
- Marco de evaluación GenAI de MLflow—Documentación para
mlflow.genai.evaluate(), jueces de LLM integrados y la API de puntuación personalizada. - cAST: Mejora de la Generación Aumentada por Recuperación de Código con División Estructural a través del Árbol de Sintaxis Abstracta—El artículo que motivó nuestro enfoque de división AST, con puntos de referencia en múltiples tareas de RAG de código. Utilizamos la implementación de la biblioteca Python ASTChunk.
- LangChain
RecursiveCharacterTextSplitter—Referencia de la API para el divisor de texto consciente del lenguaje que utilizamos en la comparación.
Pruébalo Tú Mismo
Puedes seguir esta demostración en el repositorio Casper’s Kitchens. Ya sea que estés evaluando estrategias de división para tu propio código o explorando otras mejoras de RAG, este marco de evaluación te brinda una forma reproducible de comparar enfoques.
- Crea un conjunto de datos de evaluación con preguntas y respuestas esperadas.
- Implementa estrategias de división (o usa las nuestras como punto de partida).
- Configura jueces de LLM de MLflow: comienza con las opciones integradas y agrega personalizadas a medida que encuentres lagunas.
- Ejecuta evaluaciones con índices nuevos para cada estrategia.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.