Recuperador instruido: Activación del razonamiento a nivel de sistema en agentes de búsqueda
Los agentes basados en recuperación son la base de muchos casos de uso empresariales de misión crítica. Los clientes empresariales esperan que realicen tareas de razonamiento que requieren seguir instrucciones específicas del usuario y operar eficazmente a través de fuentes de conocimiento heterogéneas. Sin embargo, la mayoría de las veces, la generación aumentada por recuperación (RAG) tradicional no logra traducir la intención detallada del usuario y las especificaciones de la fuente de conocimiento en consultas de búsqueda precisas. La mayoría de las soluciones existentes ignoran este problema y emplean herramientas de búsqueda listas para usar. Otras subestiman drásticamente el desafío, basándose únicamente en modelos personalizados para embedding y reclasificación, que son fundamentalmente limitados en su expresividad. En este blog, presentamos el Instructed Retriever, una nueva arquitectura de recuperación que aborda las limitaciones de RAG y reinventa la búsqueda para la era agéntica. Luego, ilustramos cómo esta arquitectura permite agentes basados en recuperación más capaces, incluidos sistemas como Agent Bricks: Knowledge Assistant, que deben razonar sobre datos empresariales complejos y mantener una estricta adherencia a las instrucciones del usuario.
Por ejemplo, considera un ejemplo en la Figura 1, donde un usuario pregunta sobre la duración esperada de la batería en un producto ficticio de FooBrand. Además, las especificaciones del sistema incluyen instrucciones sobre la actualidad, los tipos de documento que se deben considerar y la longitud de la respuesta. Para seguir correctamente las especificaciones del sistema, la solicitud del usuario primero debe traducirse a consultas de búsqueda estructuradas que contengan los filtros de columna apropiados, además de palabras clave. Luego, se debe generar una respuesta concisa basada en los resultados de la consulta, según las instrucciones del usuario. Un seguimiento de instrucciones tan complejo y deliberado no se puede lograr con un pipeline de recuperación simple que se centre únicamente en la consulta del usuario.
![Figura 1. Ejemplo del flujo de trabajo de recuperación instruida para la consulta [Cuál es la expectativa de vida útil de la batería para los productos FooBrand]. Las instrucciones del usuario se traducen en (a) dos consultas de recuperación estructuradas, que recuperan tanto reseñas recientes como una descripción oficial del producto (b) una respuesta breve, basada en los resultados de la búsqueda.](https://www.databricks.com/sites/default/files/inline-images/image7_24.png)
Los pipelines de RAG tradicionales se basan en la recuperación de un solo paso utilizando únicamente la consulta del usuario y no incorporan ninguna especificación adicional del sistema, como instrucciones específicas, ejemplos o esquemas de fuentes de conocimiento. Sin embargo, como mostramos en la Figura 1, estas especificaciones son clave para el seguimiento exitoso de instrucciones en los sistemas de búsqueda agénticos. Para abordar estas limitaciones y para completar con éxito tareas como la descrita en la Figura 1, nuestra arquitectura Instructed Retriever permite el flujo de especificaciones del sistema hacia cada uno de los componentes del sistema.
Incluso más allá de RAG, en sistemas de búsqueda agénticos más avanzados que permiten la ejecución de búsquedas iterativas, el seguimiento de instrucciones y la comprensión del esquema de la fuente de conocimiento subyacente son capacidades clave que no se pueden desbloquear simplemente ejecutando RAG como una herramienta durante varios pasos, como lo ilustra la Tabla 1. Por lo tanto, la arquitectura de Instructed Retriever proporciona una alternativa de alto rendimiento a RAG cuando se requiere baja latencia y una huella de modelo pequeña, al tiempo que permite agentes de búsqueda más eficaces para escenarios como la investigación profunda.
Generación aumentada por recuperación (RAG) | Instructed Retriever | Agente de varios pasos (RAG) | Agente multipaso (recuperador instruido) | |
Número de pasos de búsqueda | Simple | Simple | Múltiples | Múltiples |
Capacidad para seguir instrucciones | ✖️ | ✅ | ✖️ | ✅ |
Comprensión de la fuente de conocimiento | ✖️ | ✅ | ✖️ | ✅ |
Baja latencia | ✅ | ✅ | ✖️ | ✖️ |
Huella de modelo pequeña | ✅ | ✅ | ✖️ | ✖️ |
Razonamiento sobre los resultados | ✖️ | ✖️ | ✅ | ✅ |
Tabla 1. Un resumen de las capacidades del RAG tradicional, el Instructed Retriever y un agente de búsqueda de varios pasos implementado usando cualquiera de los enfoques como una herramienta
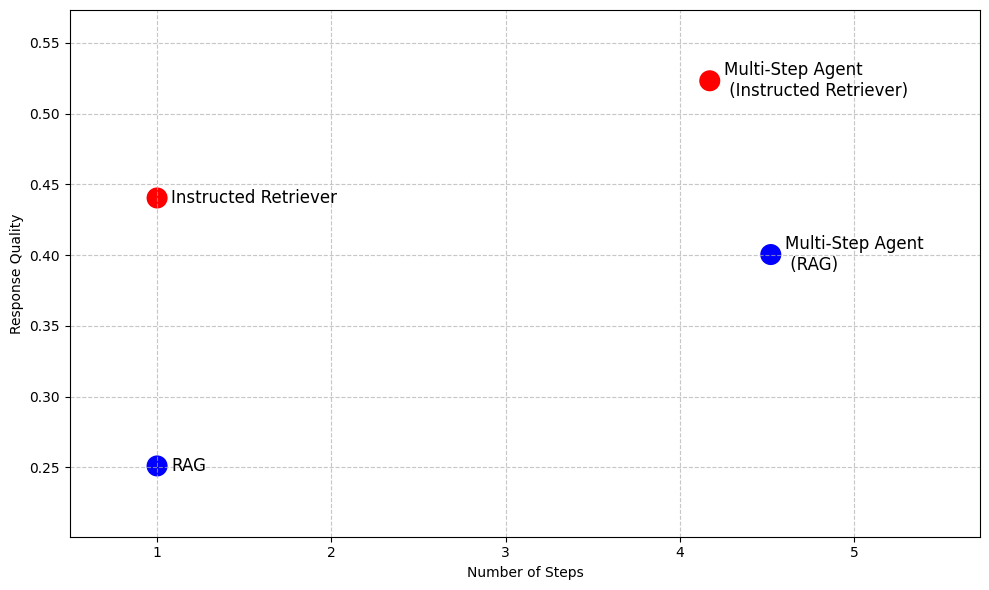
Para demostrar las ventajas de Instructed Retriever, la Figura 2 muestra una vista previa de su rendimiento en comparación con las líneas de base basadas en RAG en un conjunto de datos empresariales de respuesta a preguntas1. En estos complejos puntos de referencia, Instructed Retriever aumenta el rendimiento en más de un 70 % en comparación con el RAG tradicional. Instructed Retriever incluso supera en un 10 % a un agente de varios pasos basado en RAG. Incorporarlo como una herramienta en un agente de varios pasos aporta ganancias adicionales, al tiempo que reduce el número de pasos de ejecución, en comparación con RAG.
En el resto de esta publicación de blog, analizamos el diseño y la implementación de esta novedosa arquitectura de Instructed Retriever. Demostramos que el recuperador instruido conduce a un seguimiento de instrucciones preciso y robusto en la etapa de generación de consultas, lo que resulta en mejoras significativas en el recall de la recuperación. Además, demostramos que estas capacidades de generación de consultas se pueden habilitar incluso en modelos pequeños mediante el aprendizaje por refuerzo offline. Finalmente, desglosamos aún más el rendimiento de extremo a extremo del instructed retriever, tanto en configuraciones agénticas de un solo paso como de varios pasos. Mostramos que permite de forma consistente mejoras significativas en la calidad de la respuesta en comparación con las arquitecturas RAG tradicionales.
Arquitectura de Instructed Retriever
Para abordar los desafíos del razonamiento a nivel de sistema en los sistemas de recuperación basados en agentes, proponemos una nueva arquitectura de Instructed Retriever, que se muestra en la Figura 3. El Instructed Retriever puede ser llamado en un flujo de trabajo estático o exponerse como una herramienta para un agente. La innovación clave es que esta nueva arquitectura proporciona una forma optimizada no solo para abordar la consulta inmediata del usuario, sino también para propagar la totalidad de las especificaciones del sistema a los componentes del sistema tanto de recuperación como de generación. Esto supone un cambio fundamental con respecto a los pipelines de RAG tradicionales, donde las especificaciones del sistema podrían (en el mejor de los casos) influir en la consulta inicial, pero luego se pierden, lo que obliga al recuperador y al generador de respuestas a operar sin el contexto vital de estas especificaciones.
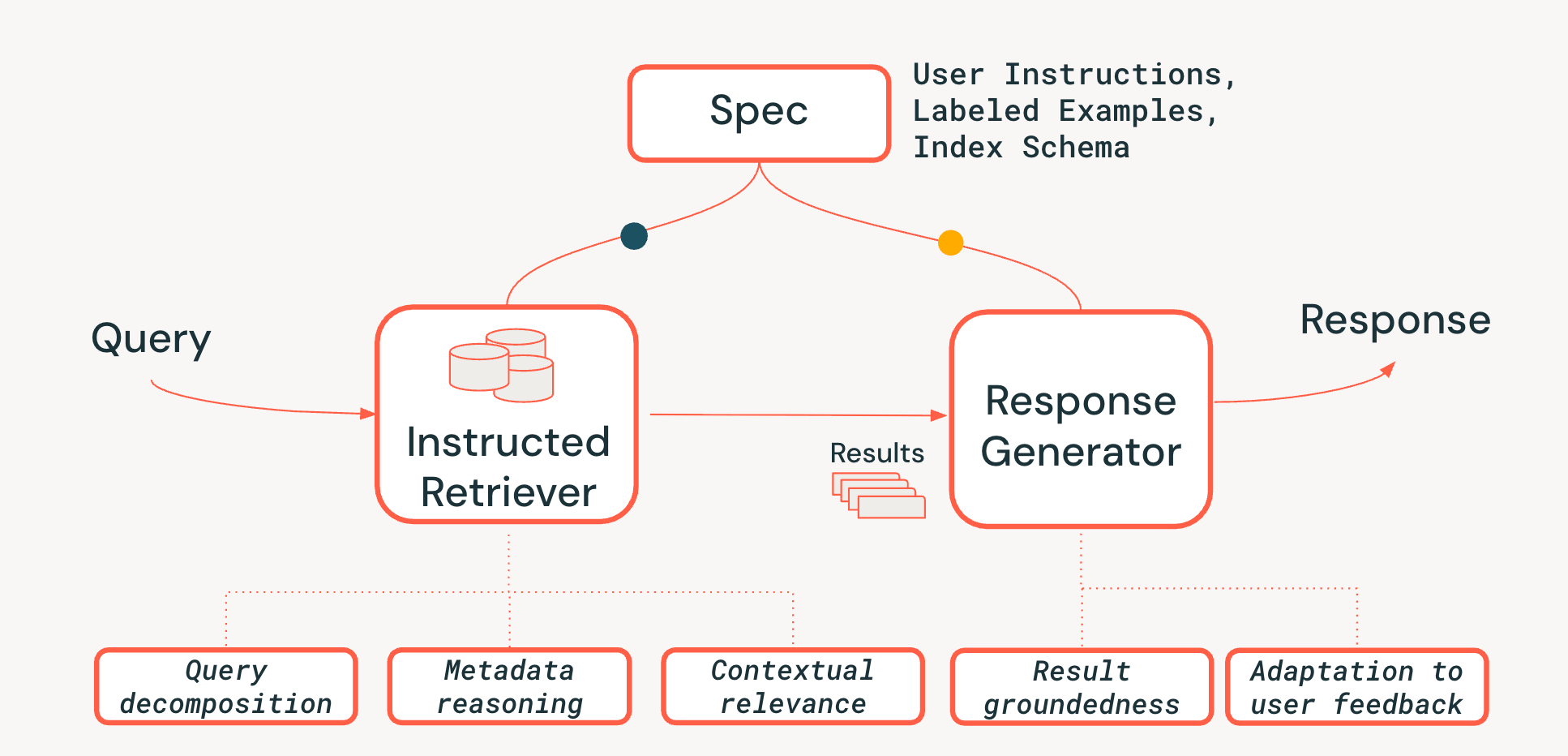
Las especificaciones del sistema son, por lo tanto, un conjunto de principios rectores e instrucciones que el agente debe seguir para cumplir fielmente la solicitud del usuario, que pueden incluir lo siguiente:
- Instrucciones del usuario: preferencias o restricciones generales, como "enfócate en las reseñas de los últimos años" o "no muestres ningún producto de FooBrand en los resultados".
- Ejemplos etiquetados: muestras concretas de pares <query, document> relevantes/no relevantes que ayudan a definir cómo es una recuperación de alta calidad que sigue instrucciones para una tarea específica.
- Descripciones del índice: Un esquema que le dice al agente qué metadatos están realmente disponibles para recuperar (p. ej., product_brand, doc_timestamp, en el ejemplo de la Figura 1).2
Para habilitar la persistencia de las especificaciones a lo largo de todo el pipeline, agregamos tres capacidades críticas al proceso de recuperación:
- Descomposición de la consulta: La capacidad de desglosar una solicitud compleja y de varias partes ("Encuéntrame un producto FooBrand, pero solo del año pasado y que no sea un modelo 'lite'") en un plan de búsqueda completo, que contiene múltiples búsquedas por palabras clave e instrucciones de filtro.
- Relevancia contextual: Va más allá de la simple similitud de texto para comprender la verdadera relevancia en el contexto de la consulta y las instrucciones del sistema. Esto significa que el reclasificador, por ejemplo, puede usar las instrucciones para potenciar los documentos que coinciden con la intención del usuario (p. ej., “recencia”), incluso si la coincidencia de palabras clave es más débil.
- Razonamiento de metadatos: Uno de los diferenciadores clave de nuestra arquitectura Instructed Retriever es la capacidad de traducir instrucciones en lenguaje natural ("del año pasado") a filtros de búsqueda precisos y ejecutables ("doc_timestamp > TO_TIMESTAMP('2024-11-01')").
También nos aseguramos de que la etapa de generación de respuestas sea concordante con los resultados recuperados, las especificaciones del sistema y cualquier historial o comentario previo del usuario (como se describe con más detalle en este blog).
La adherencia a las instrucciones en los agentes de búsqueda es un desafío porque las necesidades de información del usuario pueden ser complejas, vagas o incluso contradictorias, a menudo acumuladas a través de muchas rondas de comentarios en lenguaje natural. El recuperador también debe ser consciente del esquema (capaz de traducir el lenguaje del usuario en filtros estructurados, campos y metadatos que realmente existen en el índice). Finalmente, los componentes deben trabajar juntos sin problemas para satisfacer estas restricciones complejas y, a veces, de varias capas, sin omitir ni malinterpretar ninguna de ellas. Dicha coordinación requiere un razonamiento holístico a nivel de sistema. Como demuestran nuestros experimentos en las próximas dos secciones, la arquitectura Instructed Retriever es un gran avance para desbloquear esta capacidad en los flujos de trabajo de búsqueda y los agentes.
Evaluación del seguimiento de instrucciones en la generación de consultas
La mayoría de los benchmarks de recuperación existentes pasan por alto cómo los modelos interpretan y ejecutan las especificaciones en lenguaje natural, particularmente aquellas que involucran restricciones estructuradas basadas en el esquema del índice. Por lo tanto, para evaluar las capacidades de nuestra arquitectura de Instructed Retriever, ampliamos el conjunto de datos StaRK (Semi-Structured Retrieval Benchmark) y diseñamos un nuevo benchmark de recuperación con seguimiento de instrucciones, StaRK-Instruct, usando su subconjunto de comercio electrónico, STaRK-Amazon.
Para nuestro dataset, nos centramos en tres tipos comunes de instrucciones de usuario que requieren que el modelo razone más allá de la similitud de texto simple:
- Instrucciones de inclusión: seleccionar documentos que deben contener un atributo determinado (p. ej., “encuentra una chaqueta de FooBrand que sea la mejor calificada para el clima frío”).
- Instrucciones de exclusión: filtrar elementos que no deberían aparecer en los resultados (p. ej., “recomienda un SUV de bajo consumo, pero he tenido experiencias negativas con FooBrand, así que evita cualquier cosa que fabriquen”).
- Impulso de actualidad: preferir elementos más nuevos cuando hay metadatos relacionados con el tiempo disponibles (p. ej., “¿Qué laptops FooBrand han envejecido bien? Prioriza las reseñas de los últimos 2 o 3 años; las reseñas más antiguas importan menos debido a los cambios en el SO”).
Para crear StaRK-Instruct, a la vez que reutilizamos los juicios de relevancia existentes de StaRK-Amazon, nos basamos en trabajos previos sobre el seguimiento de instrucciones en la recuperación de información y sintetizamos las consultas existentes para hacerlas más específicas al incluir restricciones adicionales que acotan las definiciones de relevancia existentes. Luego, los conjuntos de documentos relevantes se filtran de manera programática para garantizar la alineación con las consultas reescritas. Mediante este proceso, sintetizamos 81 consultas de StaRK-Amazon (19.5 documentos relevantes por consulta) en 198 consultas en StaRK-Instruct (11.7 documentos relevantes por consulta, entre los tres tipos de instrucciones).
Para evaluar las capacidades de generación de consultas de Instructed Retriever usando StaRK-Instruct, evaluamos los siguientes métodos (en una configuración de recuperación de un solo paso)
- Consulta en crudo – como base de referencia, usamos la consulta original del usuario para la recuperación, sin etapas adicionales de generación de consultas. Esto es similar a un enfoque RAG tradicional.
- GPT5-nano, GPT5.2, Claude4.5-Sonnet: usamos cada uno de los modelos respectivos para generar la consulta de recuperación, utilizando tanto las consultas originales del usuario, las especificaciones del sistema, incluidas las instrucciones del usuario, y el esquema del índice.
- InstructedRetriever-4B – Si bien los modelos de vanguardia como GPT5.2 y Claude4.5-Sonnet son muy eficaces, también pueden ser demasiado costosos para tareas como la generación de consultas y filtros, especialmente para implementaciones a gran escala. Por lo tanto, aplicamos el mecanismo de optimización adaptativa en tiempo de prueba (TAO), que aprovecha el cómputo en tiempo de prueba y el aprendizaje por refuerzo (RL) fuera de línea para enseñar a un modelo a realizar mejor una tarea basándose en ejemplos de entrada anteriores. Específicamente, usamos el subconjunto de consultas “sintetizadas” de StaRK-Amazon y generamos consultas adicionales que siguen instrucciones usando estas consultas sintetizadas. Usamos directamente el recall como señal de recompensa para ajustar un pequeño modelo de 4B de parámetros, muestreando llamadas a herramientas candidatas y reforzando aquellas que logran puntuaciones de recall más altas.
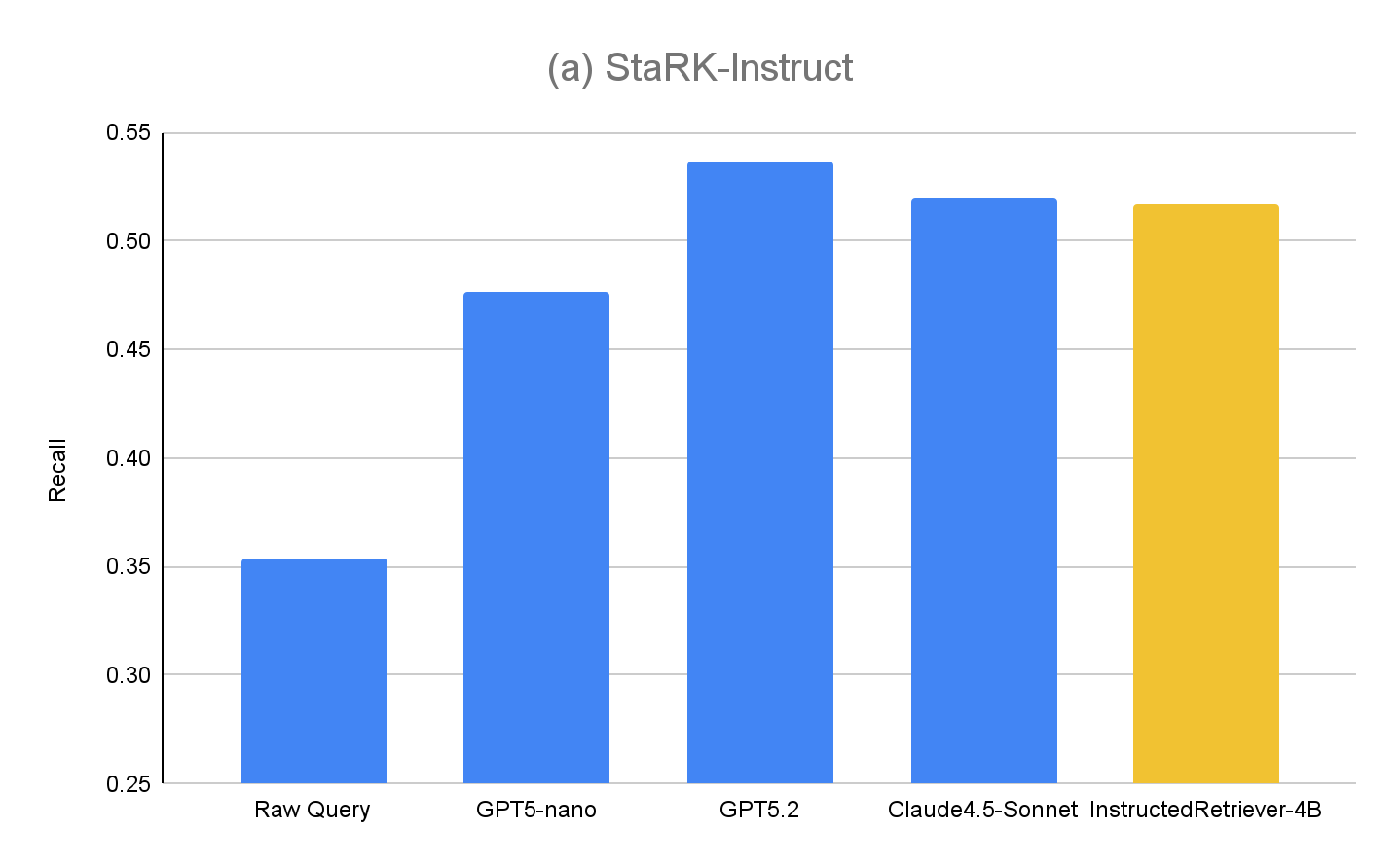
Los resultados para StaRK-Instruct se muestran en la Figura 4(a). La generación de consultas instruidas logra un recall un 35-50 % más alto en el benchmark StaRK-Instruct en comparación con la línea de base Raw Query. Las ganancias son consistentes en todos los tamaños de modelo, lo que confirma que el análisis eficaz de instrucciones y la formulación de consultas estructuradas pueden ofrecer mejoras medibles incluso con presupuestos computacionales ajustados. Los modelos más grandes generalmente exhiben mayores ganancias, lo que sugiere la escalabilidad del enfoque con la capacidad del modelo. Sin embargo, nuestro modelo InstructedRetriever-4B afinado casi iguala el rendimiento de modelos de frontera mucho más grandes y supera al modelo GPT5-nano, lo que demuestra que la alineación puede mejorar sustancialmente la eficacia del seguimiento de instrucciones en los sistemas de recuperación agénticos, incluso con modelos más pequeños.
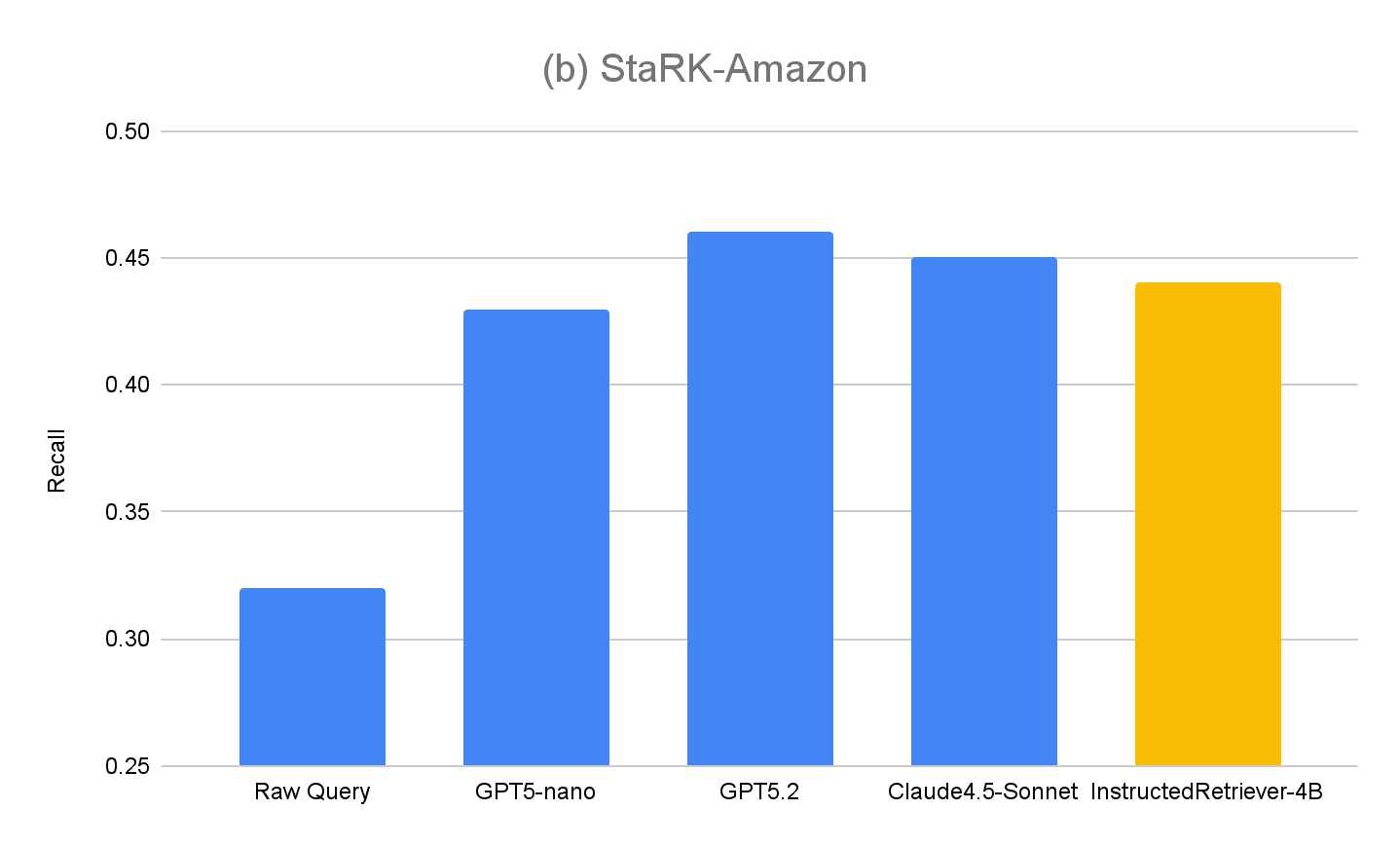
Para evaluar más a fondo la generalización de nuestro enfoque, también medimos el rendimiento en el conjunto de evaluación original, StaRK-Amazon, donde las consultas no tienen instrucciones explícitas relacionadas con los metadatos. Como se muestra en la Figura 4(b), todos los métodos de generación de consultas con instrucciones superan el recall de Raw Query en StaRK-Amazon en aproximadamente un 10 %, lo que confirma que el seguimiento de instrucciones también es beneficioso en escenarios de generación de consultas no restringidas. Tampoco observamos una degradación en el rendimiento de InstructedRetriever-4B en comparación con los modelos no ajustados, lo que confirma que la especialización en la generación de consultas estructuradas no perjudica sus capacidades generales de generación de consultas.
Implementación de Instructed Retriever en Agent Bricks
En la sección anterior, demostramos las importantes ganancias en la calidad de recuperación que se pueden lograr mediante la generación de consultas que siguen instrucciones. En esta sección, exploramos más a fondo la utilidad de un recuperador instruido como parte de un sistema de recuperación agéntico de nivel de producción. En particular, Instructed Retriever se implementa en el Asistente de conocimiento de Agent Bricks, un chatbot de preguntas y respuestas con el que puede hacer preguntas y recibir respuestas confiables basadas en el conocimiento especializado del dominio que se proporciona.
Consideramos dos soluciones RAG tipo DIY como bases de referencia:
- RAG Alimentamos los mejores resultados recuperados de nuestra búsqueda vectorial de alto rendimiento en un modelo de lenguaje grande de última generación para la generación.
- RAG + Rerank Seguimos la etapa de recuperación con una etapa de reclasificación, que demostró aumentar la precisión de la recuperación en un promedio de 15 puntos porcentuales en pruebas anteriores. Los resultados reclasificados se introducen en un modelo de lenguaje grande de vanguardia para la generación.
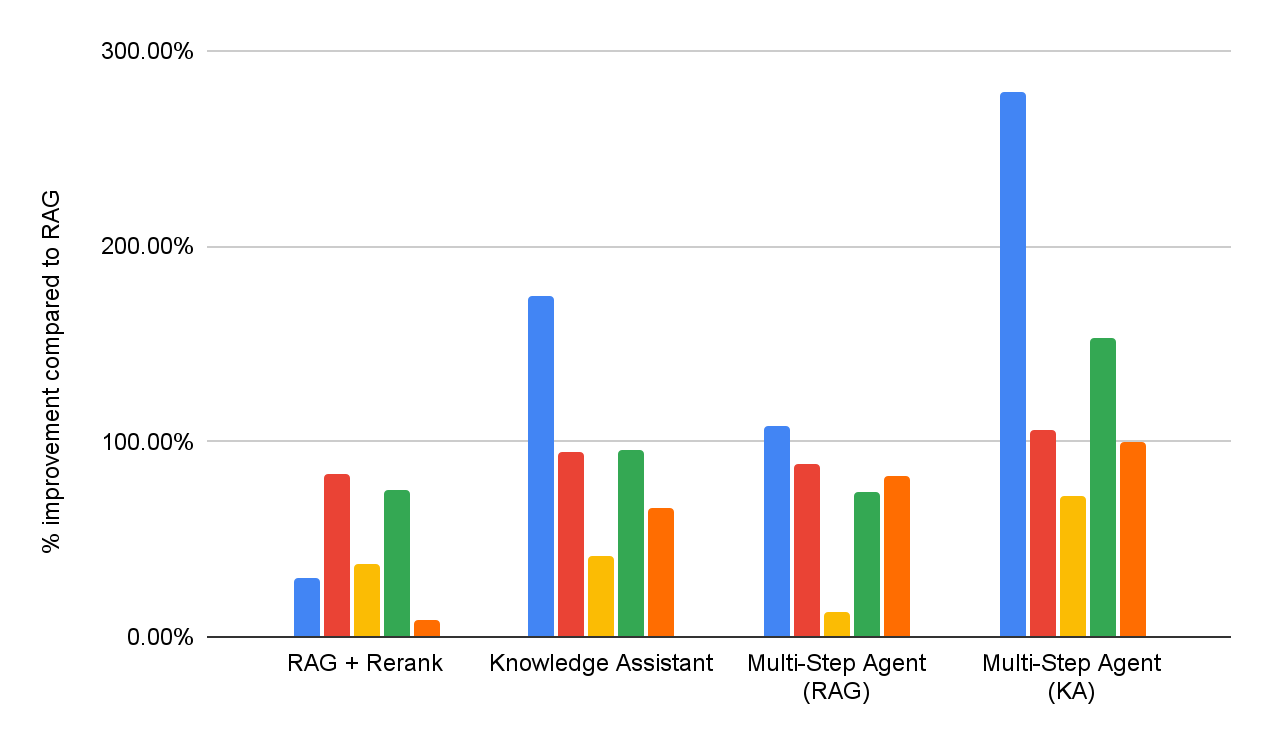
Para evaluar la eficacia de las soluciones DIY RAG y de Knowledge Assistant, realizamos una evaluación de la calidad de las respuestas en el mismo conjunto de benchmarks de respuesta a preguntas empresariales que se informa en la Figura 1. Además, implementamos dos agentes de varios pasos que tienen acceso a RAG o a Knowledge Assistant como herramienta de búsqueda, respectivamente. El rendimiento detallado para cada conjunto de datos se informa en la Figura 5 (como un % de mejora en comparación con la línea de base de RAG).
En general, podemos ver que todos los sistemas superan consistentemente la línea de base simple de RAG en todos los conjuntos de datos, lo que refleja su incapacidad para interpretar y hacer cumplir consistentemente especificaciones de varias partes. Agregar una etapa de reclasificación mejora los resultados, lo que demuestra cierto beneficio del modelado de relevancia post-hoc. Knowledge Assistant, implementado con la arquitectura de Instructed Retriever, aporta mejoras adicionales, lo que indica la importancia de mantener las especificaciones del sistema (restricciones, exclusiones, preferencias temporales y filtros de metadatos) en cada etapa de la recuperación y generación.
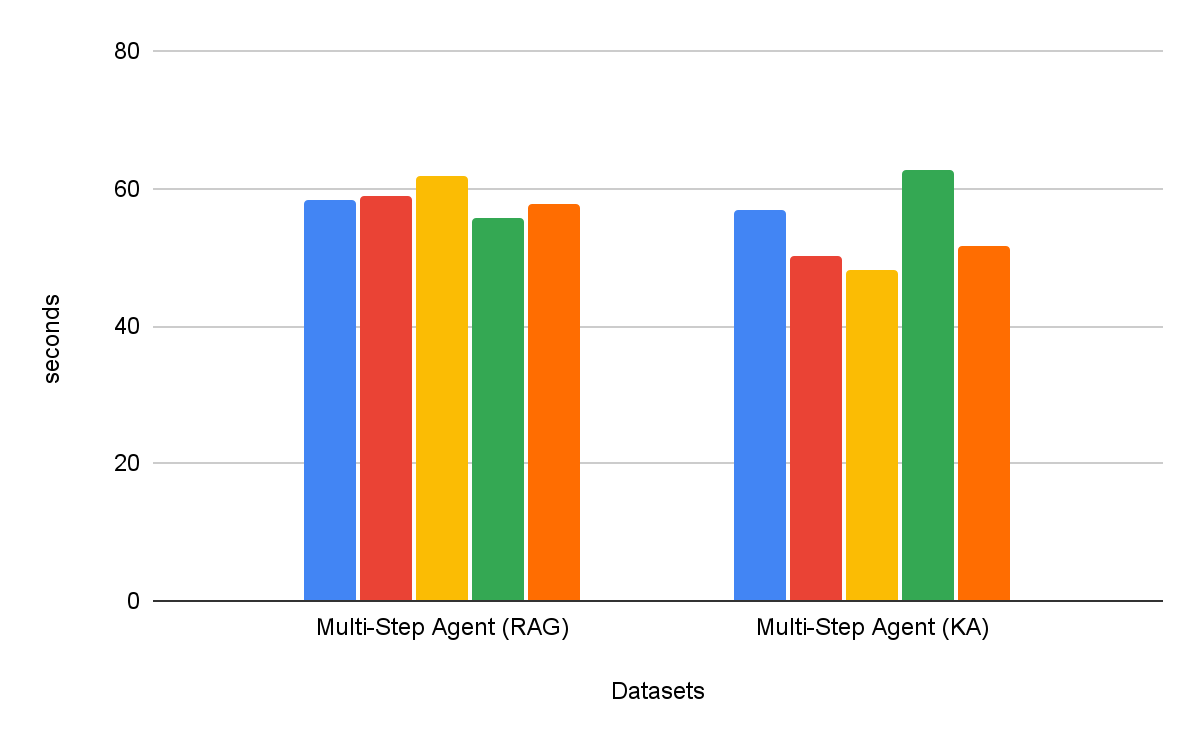
Los agentes de búsqueda de varios pasos son consistentemente más efectivos que los flujos de trabajo de recuperación de un solo paso. Además, la elección de la herramienta es importante: Knowledge Assistant como herramienta supera a RAG como herramienta en más de un 30 %, con una mejora constante en todos los conjuntos de datos. Curiosamente, no solo mejora la calidad, sino que también logra un menor tiempo para completar la tarea en la mayoría de los conjuntos de datos, con una reducción promedio del 8 % (Figura 6).
Conclusión
Crear agentes empresariales confiables requiere un seguimiento exhaustivo de las instrucciones y un razonamiento a nivel de sistema al recuperar información de fuentes de conocimiento heterogéneas. Para ello, en este blog presentamos la arquitectura del Recuperador instruido, cuya innovación principal es la propagación de las especificaciones completas del sistema —desde las instrucciones hasta los ejemplos y el esquema del índice— a través de cada etapa del pipeline de búsqueda.
También presentamos un nuevo conjunto de datos StaRK-Instruct, que evalúa la capacidad del agente de recuperación para manejar instrucciones del mundo real como inclusión, exclusión y actualidad. En este benchmark, la arquitectura de Instructed Retriever logró ganancias sustanciales del 35-50 % en el recall de recuperación, lo que demuestra empíricamente los beneficios de una conciencia de las instrucciones en todo el sistema para la generación de consultas. También mostramos que un modelo pequeño y eficiente puede optimizarse para igualar el rendimiento de seguimiento de instrucciones de modelos propietarios más grandes, lo que convierte a Instructed Retriever en una arquitectura agéntica rentable y adecuada para implementaciones empresariales en el mundo real.
Cuando se integra con un Asistente de conocimiento de Agent Bricks, la arquitectura de Instructed Retriever se traduce directamente en respuestas de mayor calidad y más precisas para el usuario final. En nuestro conjunto de pruebas de referencia completo y de alta dificultad, proporciona ganancias de más del 70 % en comparación con una solución RAG simplista, y unaganancia de calidad de más del 15 % en comparación con soluciones tipo DIY más sofisticadas que incorporan la reclasificación. Además, cuando se integra como una herramienta para un agente de búsqueda multipaso, Instructed Retriever no solo puede aumentar el rendimiento en más de un 30 %, sino también disminuir el tiempo para completar la tarea en un 8 %, en comparación con RAG como herramienta.
Instructed Retriever, junto con muchas innovaciones publicadas anteriormente como la optimización de prompts, ALHF, TAO y RLVR, ya está disponible en el producto Agent Bricks. El principio fundamental de Agent Bricks es ayudar a las empresas a desarrollar agentes que razonen con precisión sobre sus datos propietarios, aprendan continuamente de los comentarios y logren una calidad y una rentabilidad de última generación en tareas específicas del dominio. Animamos a los clientes a que prueben el Asistente de conocimiento y otros productos de Agent Bricks para crear agentes dirigibles y eficaces para sus propios casos de uso empresariales.
Autores: Cindy Wang, Andrew Drozdov, Michael Bendersky, Wen Sun, Owen Oertell, Jonathan Chang, Jonathan Frankle, Xing Chen, Matei Zaharia, Elise Gonzales, Xiangrui Meng
1 Nuestro conjunto contiene una mezcla de cinco benchmarks propietarios y académicos que prueban las siguientes capacidades: seguimiento de instrucciones, búsqueda específica de dominio, generación de informes, generación de listas y búsqueda en PDF con diseños complejos. Cada benchmark está asociado con un juez de calidad personalizado, basado en el tipo de respuesta.
2 Las descripciones del índice pueden incluirse en la instrucción especificada por el usuario o construirse automáticamente mediante métodos para la vinculación de esquemas que a menudo se emplean en sistemas para text-to-SQL, p. ej., recuperación de valores.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.