La convergencia de formatos de tabla abiertos y catálogos abiertos: los confirmaciones de catálogo están disponibles de forma general
Catalog Commits es la próxima evolución del lakehouse abierto
por Benjamin Mathew, Michelle Leon, Lukas Rupprecht y Ryan Johnson
Catalog Commits da un gran paso adelante en la unificación del lakehouse al alinear Delta con el modelo orientado al catálogo de Iceberg. Con Catalog Commits, los catálogos se convierten en el sistema de coordinación para las tablas Delta, intermediando el descubrimiento, acceso y estado de las tablas entre motores.
Hoy, nos complace anunciar la Disponibilidad General de Catalog Commits para tablas administradas de UC. Esta es una actualización importante de la plataforma que amplía la interoperabilidad de las tablas administradas de UC, fortalece las capacidades de gobernanza de UC y desbloquea nuevas funciones, incluidas transacciones de múltiples sentencias y múltiples tablas.
En este blog, cubriremos…
- Cómo Delta y Unity Catalog coevolucionan
- Los problemas que resuelve Catalog Commits
- Cómo funciona Catalog Commits
- Cómo habilitar Catalog Commits en tablas administradas de Unity Catalog
La evolución de Delta Lake y Unity Catalog
Cuando se creó Delta Lake, el lakehouse primero necesitó transacciones confiables en almacenamiento en la nube abierto. En ese momento, los catálogos no estaban diseñados para coordinar cargas de trabajo de datos modernas, por lo que Delta tomó una decisión arquitectónica revolucionaria: trajo garantías ACID directamente a los sistemas de archivos del data lake. Esta base hizo posible el lakehouse.
A medida que el lakehouse se convirtió en el sistema de registro para más equipos, motores y cargas de trabajo de IA, la necesidad de una gobernanza unificada en todos estos diferentes activos se volvió crítica. Unity Catalog proporcionó esa capa de gobernanza faltante: un lugar único para descubrir, asegurar, auditar y coordinar el acceso a datos y activos de IA en todas las nubes, formatos y motores.
Juntos, Delta Lake y Unity Catalog formaron la base del lakehouse moderno. Sin embargo, operaron uno al lado del otro: Delta administrando el estado transaccional en la capa de almacenamiento y Unity Catalog gobernando el acceso en la capa de catálogo. Esta arquitectura fue suficiente al principio, pero a medida que las organizaciones escalaron a más motores y cargas de trabajo, este diseño condujo a nuevos desafíos de coordinación.
Desafíos actuales de coordinación entre tablas y catálogos
La arquitectura original orientada al sistema de archivos de Delta fue poderosa para llevar transacciones a los data lakes, pero no fue diseñada para un mundo donde el catálogo debe coordinar consistentemente la identidad, el acceso y el estado de las tablas en muchos motores. A medida que las organizaciones imponen mayores demandas a sus datos, la falta de coordinación del catálogo expuso tres desafíos persistentes:
- El problema de la "división cerebral": los motores externos que escriben directamente en tablas Delta en el almacenamiento de objetos hacen que los metadatos del catálogo, como los esquemas, diverjan silenciosamente del estado real de la tabla.
- Expansión del acceso multi-motor, multi-agente: cada motor, herramienta y agente puede acceder a las tablas de manera diferente, lo que resulta en un descubrimiento de tablas fragmentado, auditoría inconsistente y ninguna aplicación estandarizada de controles a nivel de fila o columna en todos los sistemas.
- Coordinación de transacciones multi-tabla: históricamente, las arquitecturas abiertas de lakehouse no han admitido escrituras atómicas que abarcan múltiples tablas, por lo que las organizaciones se vieron obligadas a mantener almacenes de datos heredados específicamente para cargas de trabajo transaccionales.
Desafío n.º 1: Problema de "división cerebral" – mantener sincronizados los catálogos y tablas de gobernanza
Hoy en día, los catálogos no están en la ruta de lectura o escritura para los motores Delta. Por lo tanto, si un motor como Apache Flink quiere realizar un cambio de esquema en una tabla escribiendo directamente en la capa de almacenamiento, el catálogo no se entera de esos cambios, creando un estado de "división cerebral" donde los metadatos del catálogo y el estado real de la tabla divergen. Esto puede causar una deriva silenciosa de metadatos y fallas en las canalizaciones posteriores.
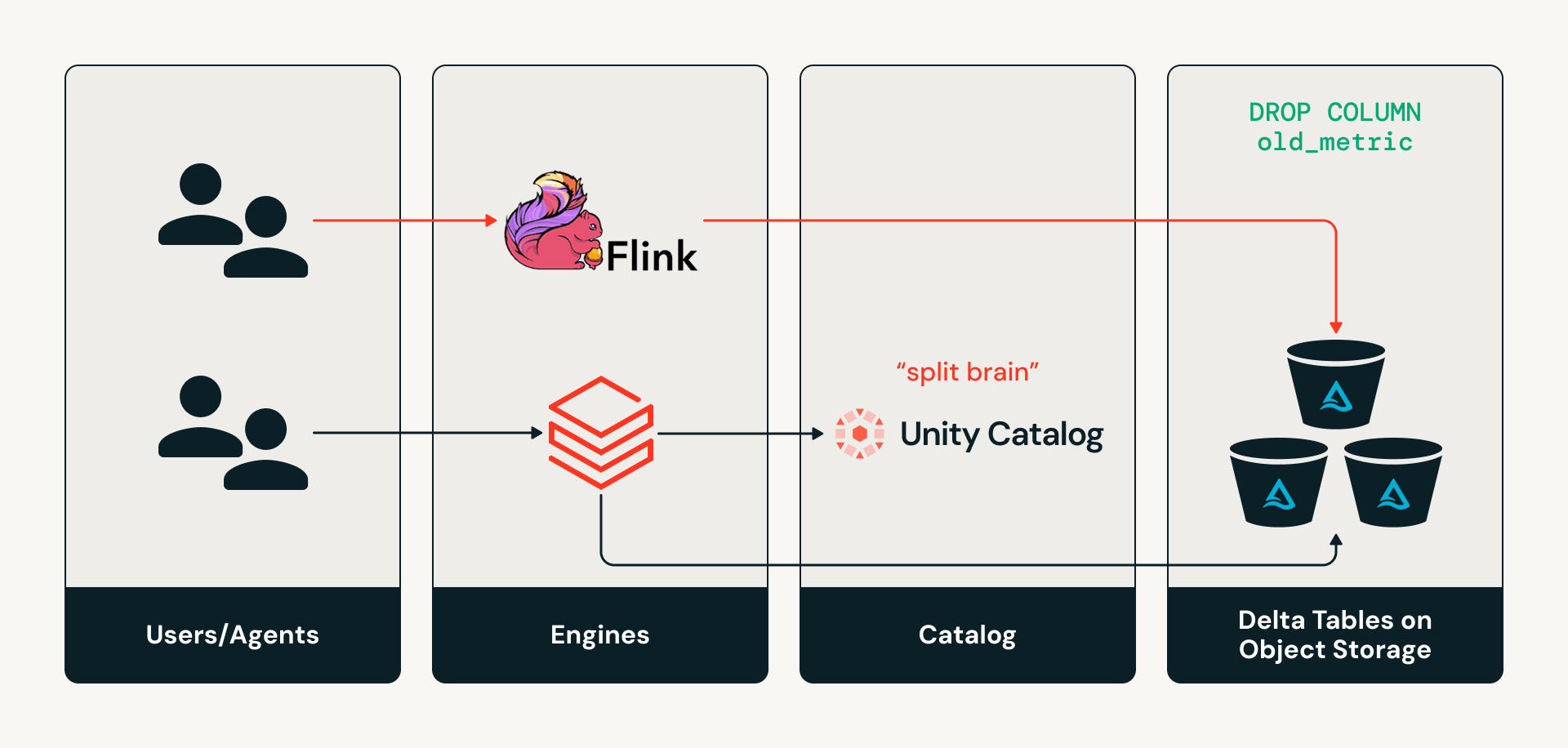
Desafío n.º 2: Expansión del acceso multi-motor y multi-agente
Las organizaciones modernas utilizan muchos motores y herramientas para analizar datos, crear canalizaciones y potenciar la IA. Históricamente, estos sistemas han accedido a los datos directamente desde el almacenamiento de objetos utilizando rutas estáticas. Esto acopla estrechamente las cargas de trabajo al almacenamiento físico, lo que dificulta el descubrimiento de tablas. Además, dado que cada motor lee las tablas Delta directamente de la capa de almacenamiento, que generalmente solo admite permisos de grano grueso, es muy difícil aplicar una gobernanza coherente a nivel de fila/columna en todos los motores. Del mismo modo, la auditoría del acceso a los datos sigue siendo fragmentada porque no hay una capa de acceso coherente para capturar la actividad entre motores, por lo que los administradores pueden tener una visión inconsistente de cómo se utilizan realmente los datos.
Las organizaciones necesitan un lugar central para descubrir, gobernar y auditar sus datos. Esta necesidad se está volviendo aún más urgente a medida que los agentes de IA emergen como un consumidor principal de datos empresariales.
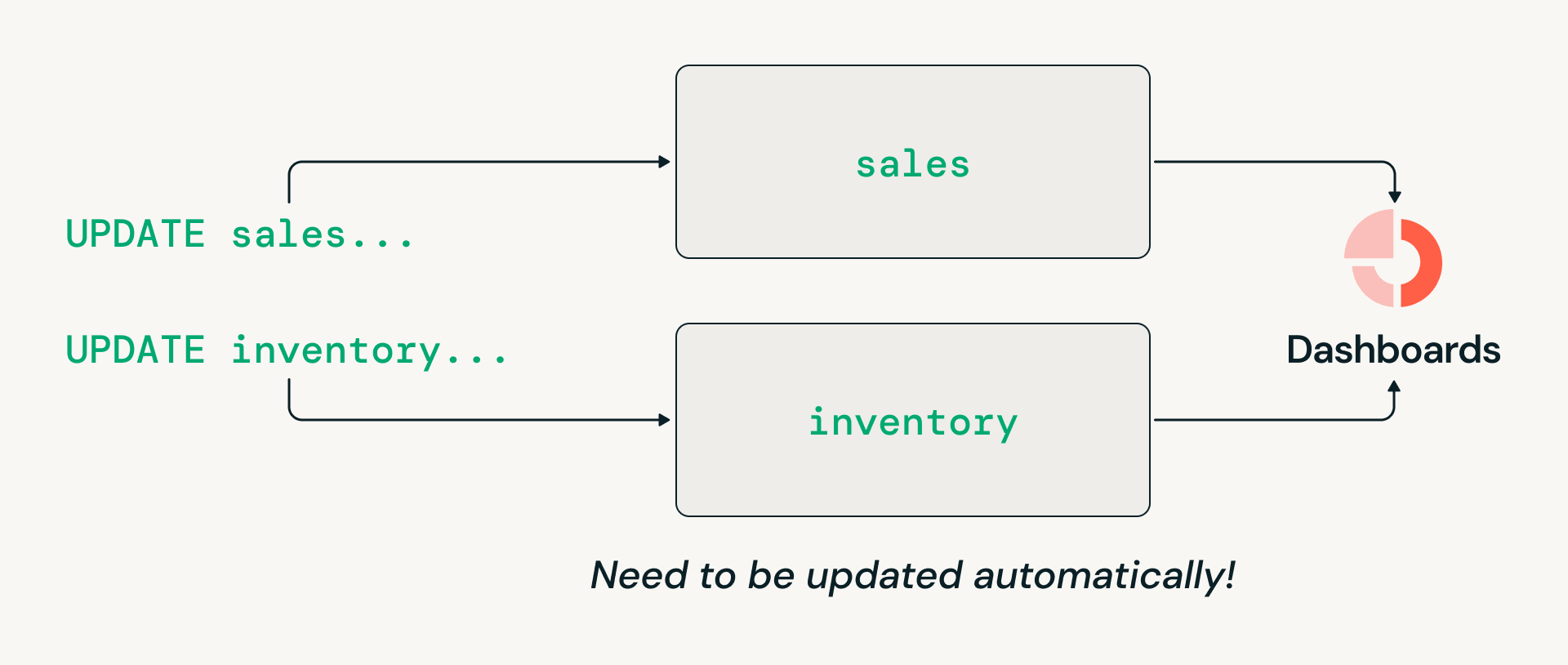
Desafío n.º 3: Coordinación de transacciones en múltiples tablas
Las cargas de trabajo de los almacenes de datos a menudo requieren transacciones de múltiples tablas, como la actualización atómica de las tablas de *ventas* e *inventario* para que los lectores posteriores siempre vean una vista coherente. Sin embargo, el diseño histórico orientado al sistema de archivos de Delta Lake limitó las transacciones a tablas individuales. Como resultado, a pesar de que muchas organizaciones quieren consolidarse en la arquitectura del lakehouse, han tenido que mantener almacenes de datos heredados específicamente para estas cargas de trabajo.
Catalog Commits es la próxima evolución del lakehouse abierto
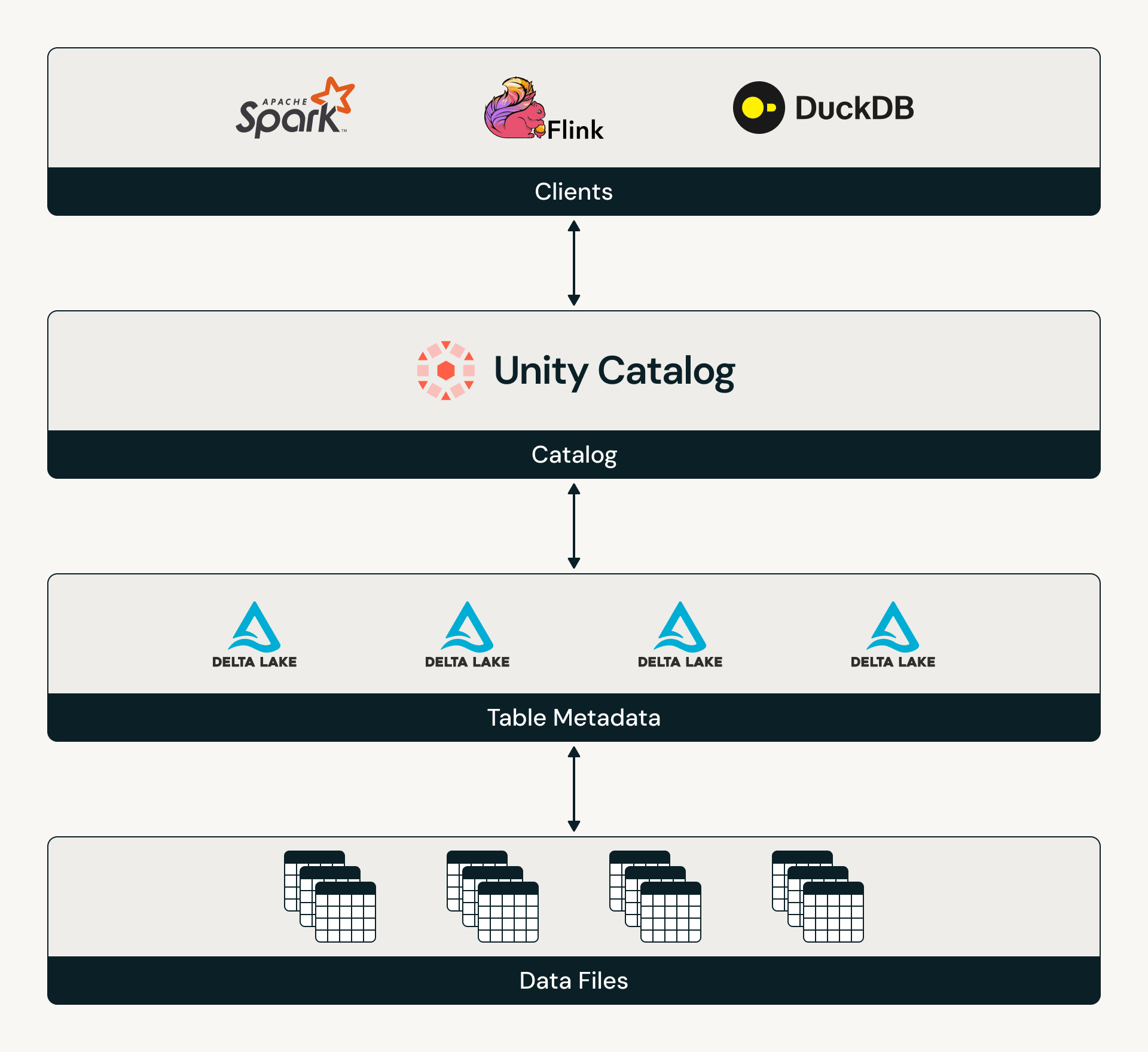
Catalog Commits es el estándar abierto para que las tablas Delta se integren con un catálogo, haciendo que el catálogo sea responsable de coordinar el acceso a las tablas y rastrear el estado más reciente de la tabla. Ahora que tanto Delta como Iceberg están orientados al catálogo, los clientes pueden confiar en que sus tablas tendrán un modelo estandarizado de descubrimiento y gobernanza de tablas. Para obtener más información sobre la especificación Catalog Commits, lea el protocolo Delta y vea la implementación de referencia de Unity Catalog de Catalog Commits.
En Databricks, Catalog Commits se puede habilitar en tablas Delta administradas por UC. Una vez habilitado, Unity Catalog intermedia todos los accesos a las tablas, creando un modelo coherente de descubrimiento y autorización para cualquier motor. Esto permite a las organizaciones centralizar verdaderamente la gobernanza sobre sus entornos.
Catalog Commits resuelve los desafíos de larga data de "división cerebral", expansión multi-motor y coordinación multi-tabla.
1. Eliminación del problema de "división cerebral": El estado de la tabla y el catálogo se mantienen sincronizados porque todos los motores acceden a las tablas a través de las mismas API, eliminando cualquier riesgo de deriva silenciosa de metadatos.
Permite que motores externos escriban en tablas Delta administradas por Unity Catalog
"Históricamente, transmitir datos a un lakehouse gobernado significaba reconciliar metadatos del catálogo fuera de banda y esperar que nada se desviara. Catalog Commits elimina esa brecha por completo. Con el servicio nativo de Kafka de StreamNative, impulsado por Ursa para la arquitectura sin disco y sin líder de Kafka, los datos se transmiten y confirman directamente a través de Unity Catalog, por lo que cada registro se almacena como una fila gobernada que es consultable instantáneamente por cualquier motor."—Sijie Guo, Co-fundador y CEO, StreamNative
2. Resolución de la expansión del acceso multi-motor: Dado que cada motor y agente utiliza API de catálogo estandarizadas para resolver tablas, las organizaciones ya no necesitan codificar rutas de almacenamiento ni administrar permisos a nivel de sistema de archivos de grano grueso.
Permite una gobernanza consistente y mejorada sobre todos los motores
3. Permite cargas de trabajo de data warehousing tradicionales en el lakehouse: El motor Databricks y Unity Catalog pueden coordinar escrituras atómicas que abarcan múltiples tablas. Esto aporta semántica ACID multi-tabla al lakehouse, desbloqueando cargas de trabajo tradicionales de data warehousing.
Permite realizar transacciones multi-tabla en Databricks
“Las transacciones, combinadas con todas las nuevas características de SQL como SQL Scripting y Stored Procedures, nos permiten migrar con confianza nuestras cargas de trabajo de almacenamiento de datos más críticas a Databricks. Estas cargas de trabajo sustentan análisis esenciales en nuestro negocio, y tener garantías transaccionales robustas en el lakehouse cambia las reglas del juego”. —Gal Doron, Head of Data, AnyClip
Además de eso, habilitar Catalog Commits en tablas administradas por UC también desbloquea:
- Auditoría holística: Unity Catalog centraliza los metadatos de las tablas y las políticas de acceso, lo que permite a los equipos inspeccionar los permisos y la propiedad de las tablas a través de una interfaz de catálogo coherente en lugar de depender únicamente de registros de almacenamiento de bajo nivel.
- Optimizaciones automatizadas de tablas: Unity Catalog aprovecha su visibilidad en todos los accesos a tablas para organizar de manera óptima los datos de las organizaciones según sus patrones de consulta específicos, a través de Liquid Clustering y Predictive Optimization.
- Bases para un mejor rendimiento: Unity Catalog puede informar directamente a los motores sobre los metadatos a nivel de tabla sin que el motor necesite obtener metadatos del almacenamiento en la nube, eliminando una fuente importante de latencia de metadatos.
En conjunto, estas capacidades hacen que las tablas administradas por UC con Catalog Commits sean la base más abierta, gobernada y de mayor rendimiento para el lakehouse moderno.
Habilite Catalog Commits en sus tablas hoy mismo
¡Catalog Commits en Databricks está disponible de forma general hoy! Al habilitar Catalog Commits en tablas administradas por Unity Catalog, se desbloquean las siguientes características:
- Interoperabilidad mejorada: Escrituras de motores externos en tablas Delta administradas por UC
- Gobernanza más sólida: Desbloquea una gobernanza coherente y mejorada sobre todos los motores
- Nuevas características: Transacciones de múltiples sentencias y múltiples tablas
Los productos de Databricks que leen o escriben en tablas administradas por UC, desde la ingesta hasta el consumo de nivel gold, ahora admiten Catalog Commits. Estos incluyen Streaming Tables, Delta Sharing, Zerobus, Lakeflow Connect, AI Gateway, MLflow y Lakeflow Job Triggers. Asimismo, Catalog Commits es compatible actualmente con motores de todo el ecosistema, incluidos Delta Spark, Delta Flink, Starburst Trino, DuckDB y StreamNative.
También es fácil para cualquier motor admitir Catalog Commits integrándose con Delta Kernel, una biblioteca compartida de API que abstrae los detalles a nivel de protocolo. Delta Kernel facilita que los conectores admitan las últimas características de Delta con simples actualizaciones de versión.
Crear una tabla Delta administrada por UC con Catalog Commits habilitado es fácil. Usando Databricks Runtime 16.4+, ejecute:
Para actualizar una tabla Delta administrada por UC existente y habilitar Catalog Commits, use Databricks Runtime 18.0+ y ejecute:
¡Comience con Catalog Commits y únase a nosotros en el Data and AI Summit para obtener más información sobre nuestro trabajo en la construcción del lakehouse abierto!
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.