Mejores prácticas de modelado de datos e implementación en un Lakehouse moderno
por Leo Mao, Abhishek Dey, Justin Breese y Soham Bhatt
Muchos de nuestros clientes están migrando sus almacenes de datos heredados a Databricks Lakehouse, ya que les permite modernizar no solo su almacén de datos, sino que también obtienen acceso instantáneo a una plataforma madura de Streaming y Análisis Avanzado. Lakehouse puede hacerlo todo, ya que es una plataforma única para todas sus necesidades de streaming, ETL, BI y IA, y ayuda a sus equipos de negocio y datos a colaborar en una sola plataforma.
Mientras ayudamos a los clientes en el campo, encontramos que muchos buscan las mejores prácticas sobre el modelado de datos adecuado y las implementaciones de modelos de datos físicos en Databricks.
En este artículo, nuestro objetivo es profundizar en la mejor práctica del modelado dimensional en la Plataforma Databricks Lakehouse y proporcionar un ejemplo en vivo de una implementación de modelo de datos físico utilizando nuestras mejores prácticas de creación de tablas y DDL.
Estos son los temas generales que cubriremos en este blog:
- La importancia del modelado de datos
- Técnicas comunes de modelado de datos
- Implementación de DDL de modelado de Data Warehouse
- Mejores prácticas y recomendaciones para el modelado de datos en Databricks Lakehouse
La importancia del modelado de datos para el Data Warehouse
Los modelos de datos están al frente y al centro de la construcción de un Data Warehouse. Típicamente, el proceso comienza con la defensa del Modelo de Información de Negocio Semántica, luego un Modelo de Datos Lógico y, finalmente, un Modelo de Datos Físico (PDM). Todo comienza con una fase adecuada de Análisis y Diseño de Sistemas donde primero se crea un modelo de información de negocio y flujos de procesos, y se capturan las entidades clave del negocio, atributos e interacciones según los procesos de negocio dentro de la organización. Luego se crea el Modelo de Datos Lógico que representa cómo las entidades se relacionan entre sí y este es un modelo tecnológicamente agnóstico. Finalmente, se crea un PDM basado en la plataforma tecnológica subyacente para garantizar que las escrituras y lecturas se puedan realizar de manera eficiente. Como todos sabemos, para el Data Warehousing, los estilos de modelado amigables para el análisis como el esquema en estrella y el Data Vault son bastante populares.
Mejores prácticas para crear un modelo de datos físico en Databricks
Basado en el problema de negocio definido, el objetivo del diseño del modelo de datos es representar los datos de una manera fácil para la reutilización, flexibilidad y escalabilidad. Aquí hay un modelo de datos típico de esquema en estrella que muestra una tabla de hechos de ventas que contiene cada transacción y varias tablas de dimensiones como clientes, productos, tiendas, fecha, etc., por las cuales se segmentan los datos. Las dimensiones se pueden unir a la tabla de hechos para responder preguntas específicas de negocio, como cuáles son los productos más populares para un mes determinado o cuáles son las tiendas con mejor rendimiento para el trimestre. Veamos cómo implementarlo en Databricks.
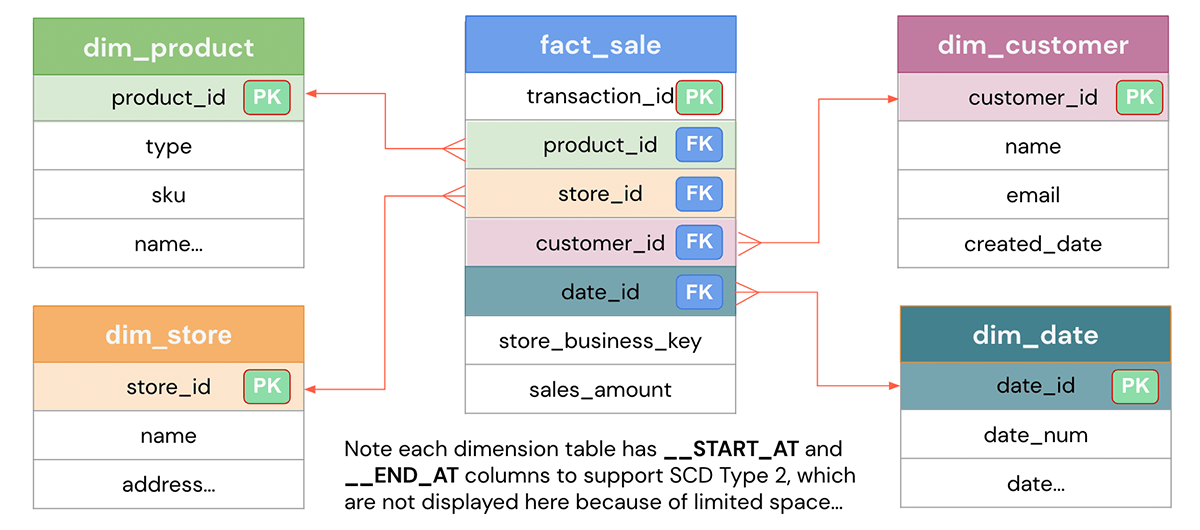
Implementación de DDL de modelado de Data Warehouse en Databricks
En las siguientes secciones, demostraremos lo siguiente usando nuestros ejemplos.
- Creación de catálogo, base de datos y tabla de 3 niveles
- Definiciones de clave primaria y clave externa
- Columnas de identidad para claves sustitutas
- Restricciones de columna para la calidad de los datos
- Índice, optimizar y analizar
- Técnicas avanzadas
1. Unity Catalog - Espacio de nombres de 3 niveles
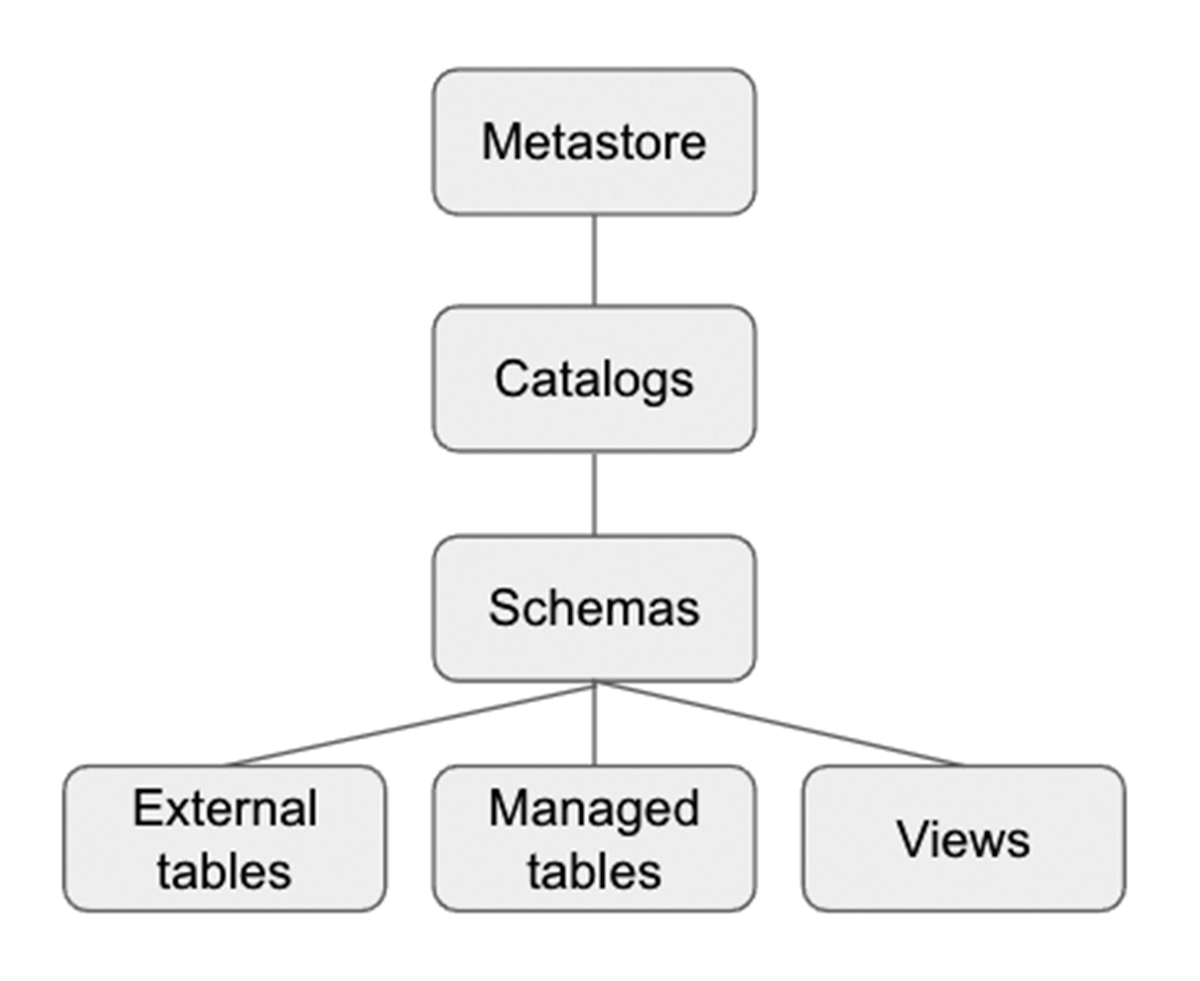
Unity Catalog es una capa de gobernanza de Databricks que permite a los administradores y administradores de datos de Databricks gestionar centralmente a los usuarios y su acceso a los datos en todos los espacios de trabajo de una cuenta de Databricks utilizando un único Metastore. Los usuarios en diferentes espacios de trabajo pueden compartir el acceso a los mismos datos, dependiendo de los privilegios otorgados centralmente en Unity Catalog. Unity Catalog tiene un espacio de nombres de 3 niveles (catálogo.esquema(base de datos).tabla) que organiza sus datos. Obtenga más información sobre Unity Catalog aquí.
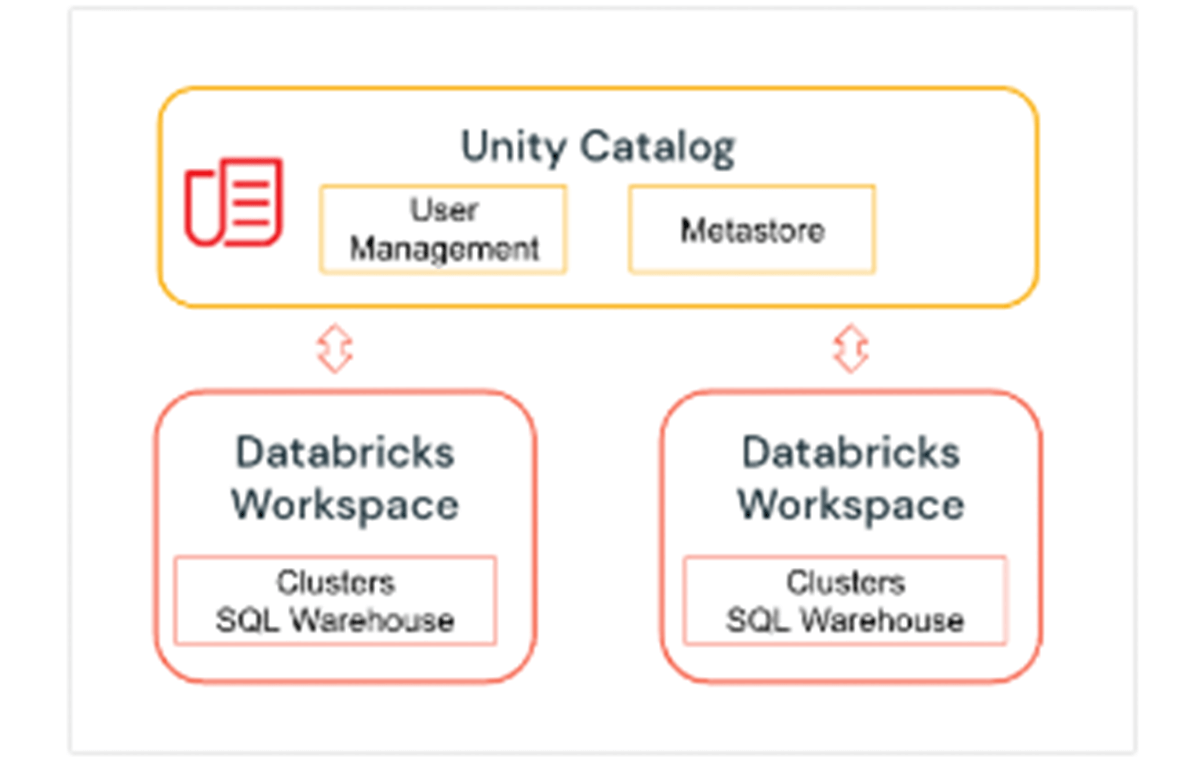
Así es como se configura el catálogo y el esquema antes de crear tablas dentro de la base de datos. Para nuestro ejemplo, creamos un catálogo US_Stores y un esquema (base de datos) Sales_DW como se muestra a continuación, y los usamos para la parte posterior de la sección.
Configuración del Catálogo y la Base de Datos
Aquí hay un ejemplo de consulta de la tabla fact_sales con un espacio de nombres de 3 niveles.
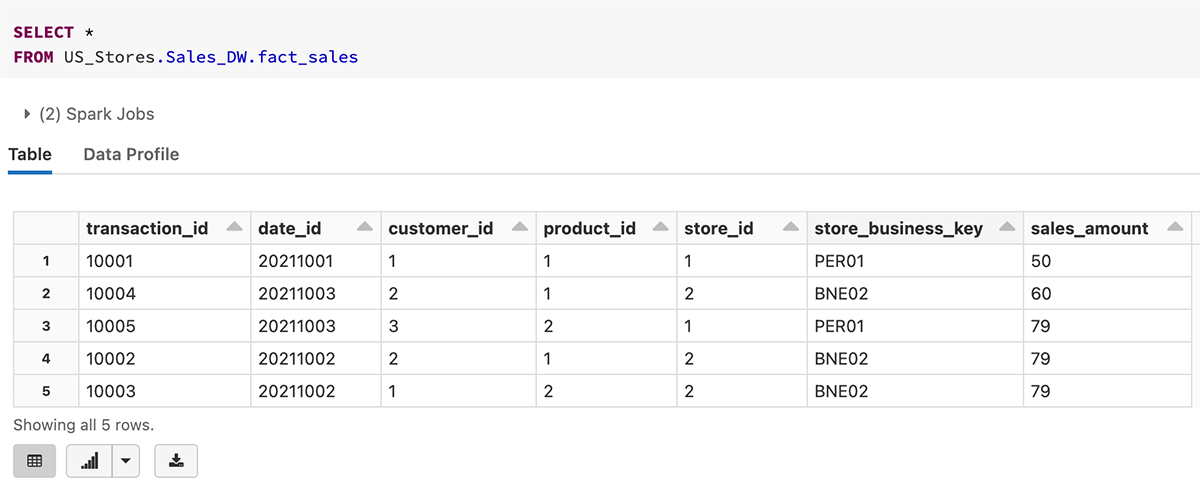
2. Definiciones de clave primaria y clave externa
Las definiciones de Clave Primaria y Clave Externa son muy importantes al crear un modelo de datos. Tener la capacidad de admitir la definición de PK/FK hace que la definición del modelo de datos sea muy fácil en Databricks. También ayuda a los analistas a identificar rápidamente las relaciones de unión en Databricks SQL Warehouse para que puedan escribir consultas de manera efectiva. Al igual que la mayoría de los otros almacenes de datos masivamente paralelos (MPP), EDW y en la nube, las restricciones PK/FK son solo informativas. Databricks no admite la aplicación de la relación PK/FK, pero brinda la capacidad de definirla para facilitar el diseño del Modelo de Datos Semántico.
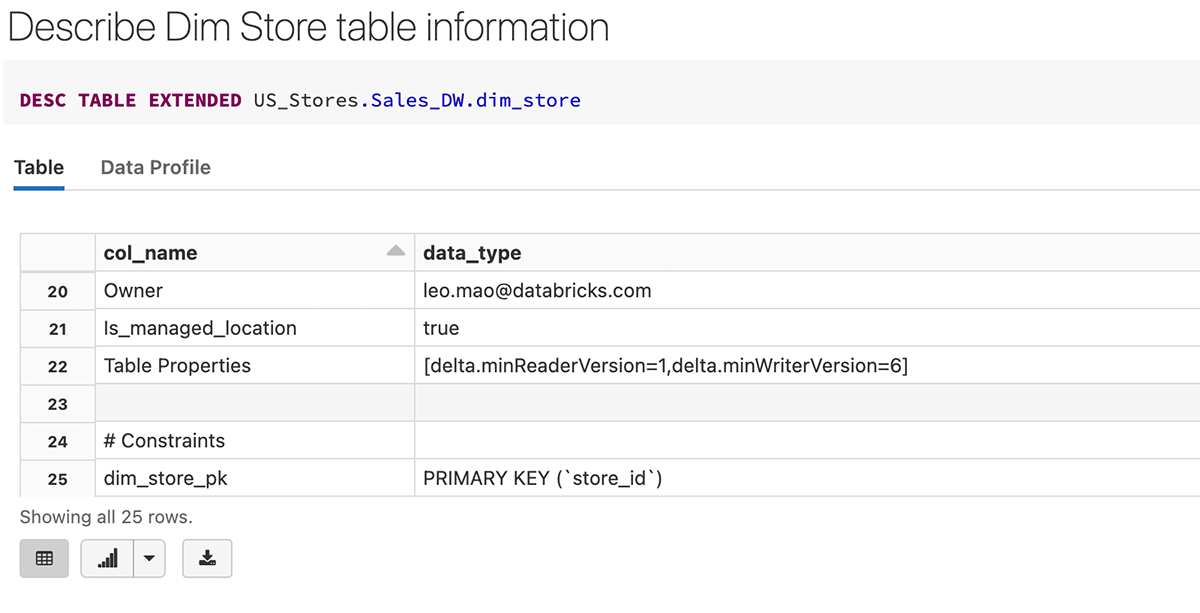
Aquí hay un ejemplo de creación de la tabla dim_store con store_id como Columna de Identidad y también definida como Clave Primaria al mismo tiempo.
Implementación de DDL para crear la dimensión de tienda con definiciones de Clave Primaria
Después de crear la tabla, podemos ver que la clave primaria (store_id) se crea como una restricción en la definición de la tabla a continuación.
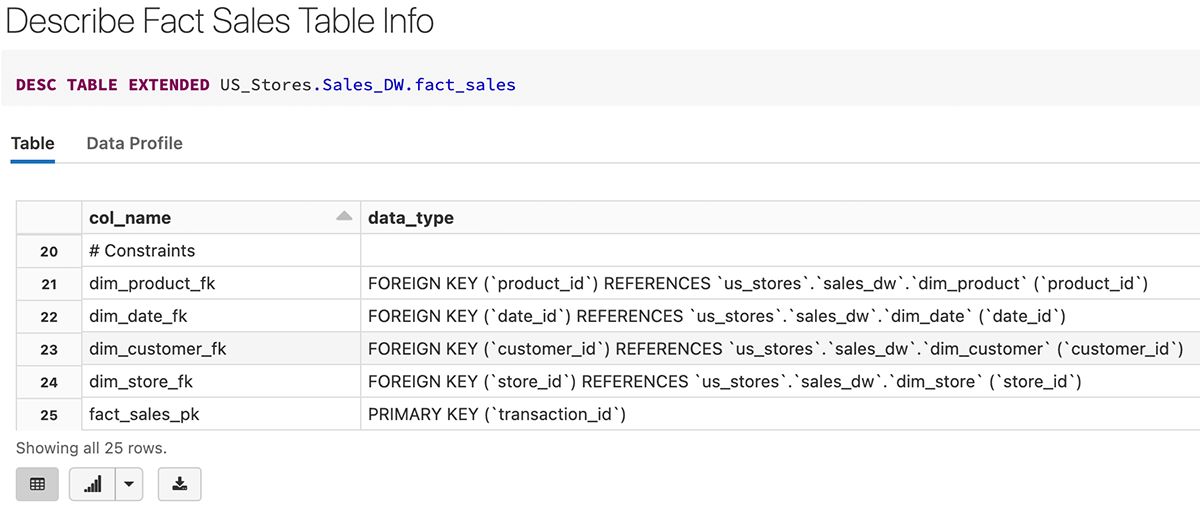
Aquí hay un ejemplo de creación de la tabla fact_sales con transaction_id como Clave Primaria, así como claves externas que hacen referencia a las tablas de dimensiones.
Implementación de DDL para crear hechos de ventas con definiciones de Clave Externa
Después de crear la tabla de hechos, podríamos ver que la clave primaria (transaction_id) y las claves externas se crean como restricciones en la definición de la tabla a continuación.
3. Columnas de identidad para claves sustitutas
Una columna de identidad es una columna en una base de datos que genera automáticamente un número de identificación único para cada nueva fila de datos. Estos se usan comúnmente para crear claves sustitutas en los almacenes de datos. Las claves sustitutas son claves sin significado generadas por el sistema, para que no tengamos que depender de varias Claves Primarias Naturales y concatenaciones de varios campos para identificar la unicidad de la fila. Típicamente, estas claves sustitutas se utilizan como claves primarias y externas en los almacenes de datos. Los detalles sobre las columnas de identidad se discuten en este blog. A continuación se muestra un ejemplo de creación de una columna de identidad customer_id, con valores asignados automáticamente a partir de 1 e incrementando en 1.
Implementación DDL para crear la dimensión de cliente con columna de identidad
4. Restricciones de columna para la calidad de los datos
Además de las restricciones informativas de Clave Primaria y Clave Externa, Databricks también admite restricciones de Verificación de Calidad de Datos a nivel de columna que se aplican para garantizar la calidad e integridad de los datos que se agregan a una tabla. Las restricciones se verifican automáticamente. Buenos ejemplos de estas son las restricciones NOT NULL y las restricciones de valor de columna. A diferencia de otros Data Warehouses en la nube, Databricks fue más allá para proporcionar restricciones de verificación de valor de columna, que son muy útiles para garantizar la calidad de los datos de una columna determinada. Como podemos ver a continuación, la restricción de verificación valid_sales_amount verificará que todas las filas existentes cumplan la restricción (es decir, sales amount > 0) antes de agregarla a la tabla. Puede encontrar más información aquí.
Aquí hay ejemplos para agregar restricciones a dim_store y fact_sales respectivamente para asegurarnos de que store_id y sales_amount tengan valores válidos.
Agregar restricción de columna a tablas existentes para garantizar la calidad de los datos
5. Indexación, Optimización y Análisis
Las bases de datos tradicionales tienen índices b-tree y bitmap, Databricks tiene una forma de indexación mucho más avanzada: indexación agrupada Z-order multidimensional y también admitimos la indexación de filtros Bloom. En primer lugar, el formato de archivo Delta utiliza el formato de archivo Parquet, que es un formato de archivo comprimido columnar, por lo que ya es muy eficiente en la poda de columnas y, además, el uso de la indexación z-order le brinda la capacidad de examinar datos a escala de petabytes en segundos. Tanto Z-order como la indexación de filtros Bloom reducen drásticamente la cantidad de datos que deben escanearse para responder consultas altamente selectivas contra tablas Delta grandes, lo que generalmente se traduce en mejoras de tiempo de ejecución de órdenes de magnitud y ahorros de costos. Utilice Z-order en sus Claves Primarias y claves externas que se utilizan para las uniones más frecuentes. Y utilice indexación de filtros Bloom adicional según sea necesario.
Optimizar fact_sales en customer_id y product_id para un mejor rendimiento
Crear un índice de filtro Bloom para habilitar el salto de datos en una columna determinada
Y al igual que cualquier otro Data Warehouse, puede ANALYZE TABLE para actualizar estadísticas y garantizar que el optimizador de consultas tenga las mejores estadísticas para crear el mejor plan de consulta.
Recopilar estadísticas para todas las columnas para un mejor plan de ejecución de consultas
6. Técnicas Avanzadas
Si bien Databricks admite técnicas avanzadas como Table Partitioning, utilice estas funciones con moderación, solo cuando tenga muchos Terabytes de datos comprimidos, porque la mayoría de las veces nuestros índices OPTIMIZE y Z-ORDER le brindarán la mejor poda de archivos y datos, lo que hace que particionar una tabla por fecha o mes sea casi una mala práctica. Sin embargo, es una buena práctica asegurarse de que las DDL de su tabla estén configuradas para optimización y compactación automáticas. Esto garantizará que sus datos escritos frecuentemente en archivos pequeños se compacten en formatos comprimidos columnares más grandes de Delta.
¿Está buscando aprovechar una herramienta de modelado de datos visual? Nuestro socio erwin Data Modeler de Quest se puede utilizar para realizar ingeniería inversa, crear e implementar esquemas en estrella, Data Vaults y cualquier modelo de datos de la industria en Databricks con solo unos pocos clics.
Ejemplo de Notebook de Databricks
Con la plataforma Databricks, uno puede diseñar e implementar fácilmente varios modelos de datos con facilidad. Para ver todos los ejemplos anteriores en un flujo de trabajo completo, consulte este ejemplo.
Consulte también nuestro blog relacionado: Cinco pasos sencillos para implementar un esquema en estrella en Databricks con Delta Lake.
Comience a crear sus modelos dimensionales en el Lakehouse
Pruebe Databricks gratis durante 14 días.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.