Desarrollar y desplegar JARs Serverless
por Achille Negrier, Edward Feng, Giorgi Kikolashvili y Shiyu Wang
- Ejecute JARs Serverless escritos en Scala o Java, con tiempos de inicio instantáneos y cero administración de clústeres.
- Desarrolle en su IDE favorito usando Databricks Connect, probando contra datos reales y entornos similares a producción.
- Pague solo por el trabajo realizado con facturación elástica basada en el uso, no por tiempo inactivo o adquisición de instancias.
JARs Serverless y Databricks Connect para Scala
Los JARs Serverless permiten a los equipos crear y ejecutar trabajos Spark de Scala y Java en cómputo Serverless totalmente administrado. Los equipos pueden seguir creando pipelines Spark de calidad de producción en los lenguajes en los que ya confían, con actualizaciones automatizadas y sin la sobrecarga operativa de administrar clústeres:
- Inicio rápido: Con Serverless, los trabajos de Scala y Java se inician en segundos en lugar de minutos. Los ingenieros pueden ejecutar e iterar código de inmediato, sin esperar a que los clústeres se inicien.
- Actualizaciones sin versión: Serverless se ejecuta continuamente en el último tiempo de ejecución de Spark compatible, por lo que nunca tendrá que planificar ni administrar las actualizaciones de Databricks Runtime.
- Sin infraestructura que administrar: No hay aprovisionamiento de clústeres, ni planificación de capacidad, ni administración del tiempo de ejecución. Databricks administra automáticamente la infraestructura, la escalabilidad y la optimización del rendimiento, para que los desarrolladores puedan centrarse en escribir código.
- Pague solo por lo que usa: En lugar de pagar por clústeres siempre activos o capacidad inactiva, los equipos solo se facturan por el cómputo que realmente utilizan.
¿Cómo funcionan los JARs Serverless?
Puede ejecutar JARs con Lakeflow Jobs en cómputo Serverless. Los JARs Serverless se basan en Spark 4 (Scala 2.13) y Spark Connect, utilizando la misma arquitectura que Python. La desacoplación del código del usuario del motor permite actualizaciones sin versión, elimina conflictos de dependencias y habilita controles de acceso nativos y detallados con Lakeguard.
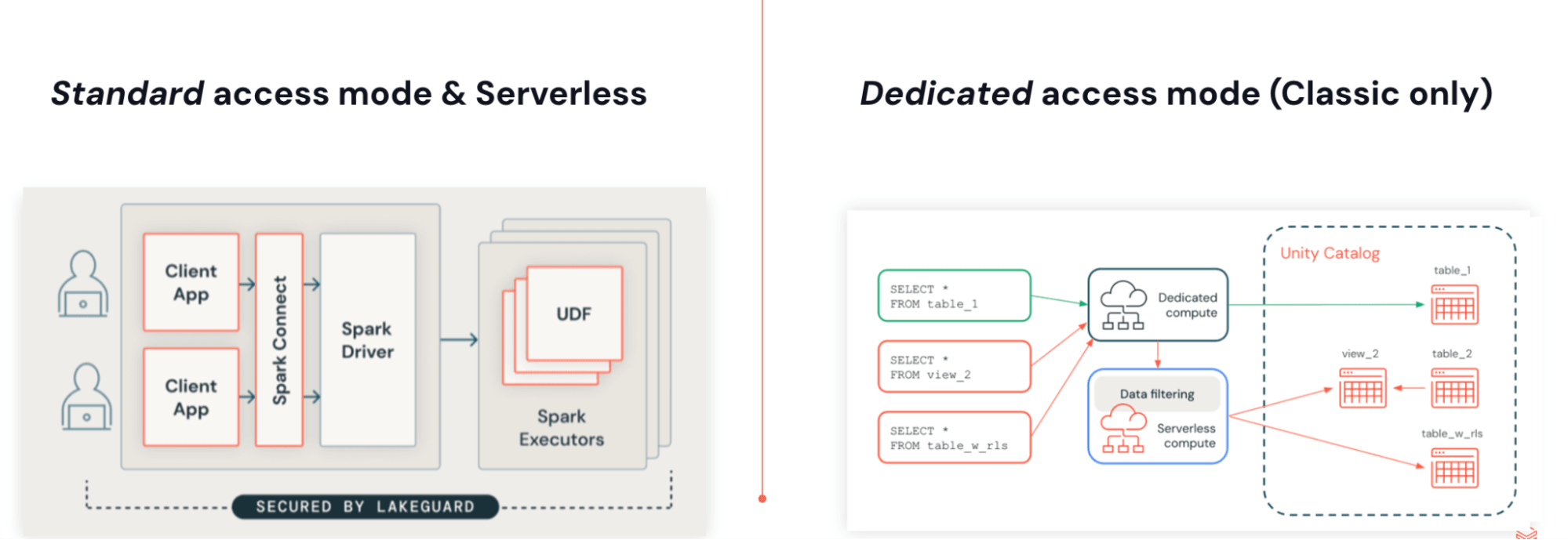
Esta arquitectura tiene algunos beneficios clave:
- Ejecución sin versión: Las aplicaciones ya no están vinculadas a una versión específica de Databricks Runtime. Serverless siempre se ejecuta en el tiempo de ejecución compatible más reciente, lo que elimina la necesidad de planificar, programar o administrar las actualizaciones de Databricks Runtime.
- Controles de acceso nativos y detallados con Lakeguard: Dado que toda la ejecución ocurre en el servidor, Databricks puede aplicar filtros a nivel de fila y controles de acceso basados en atributos (ABAC) a bajo costo.
- Conjunto de dependencias delgado e independiente: El entorno Serverless se ejecuta aislado de Spark, por lo que puede proporcionar un conjunto de dependencias independiente y reducido que también elimina los conflictos de dependencias.
Desarrollar usando Databricks Connect y Databricks Asset Bundles
Con Databricks Connect, puede escribir y depurar código de forma interactiva en su IDE preferido, como IntelliJ o Cursor, utilizando cómputo Serverless con tiempos de inicio casi instantáneos.
Esto hace que los ciclos de desarrollo sean más rápidos y confiables, ya que puede probar con datos y entornos reales sin salir de su IDE. Una vez que haya terminado de desarrollar, puede poner en producción su trabajo utilizando Databricks Asset Bundles.
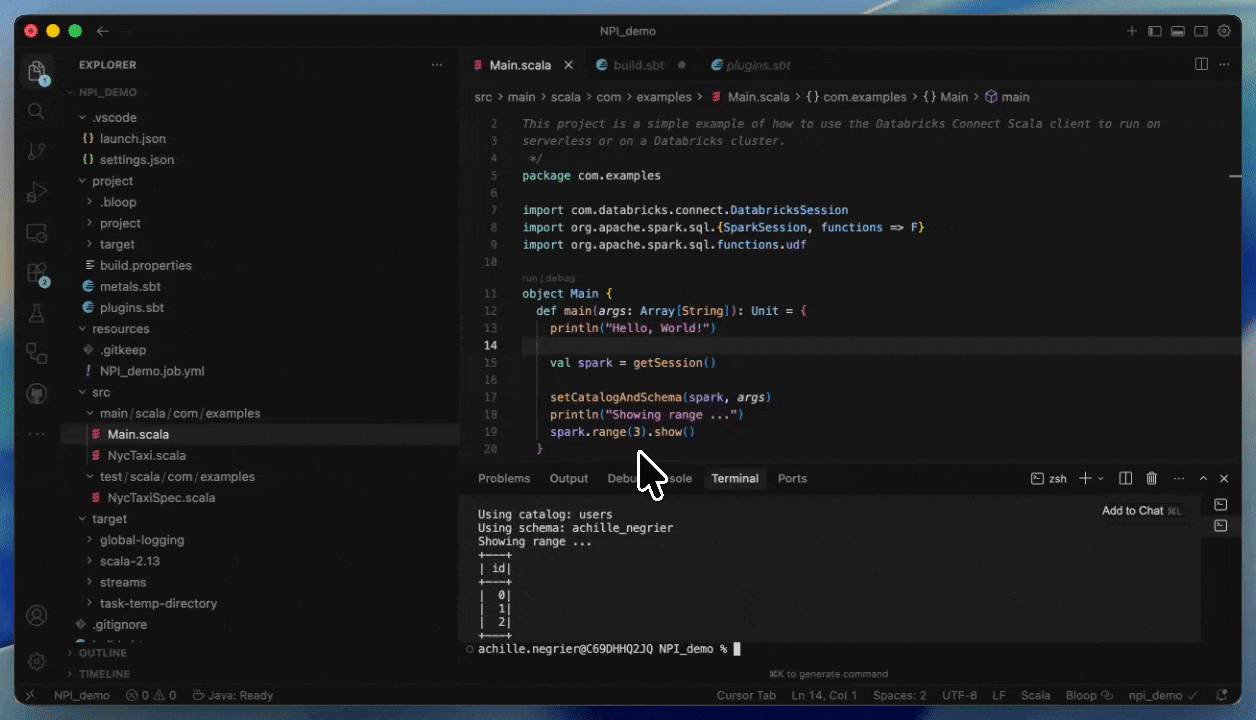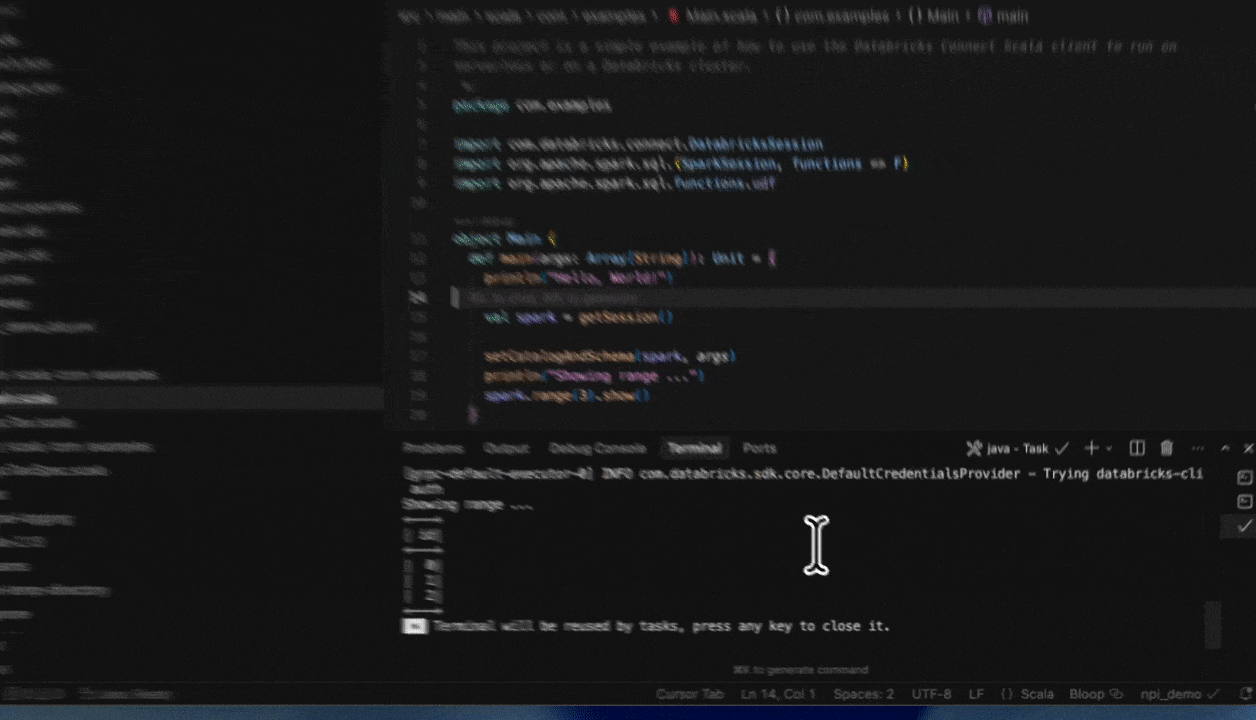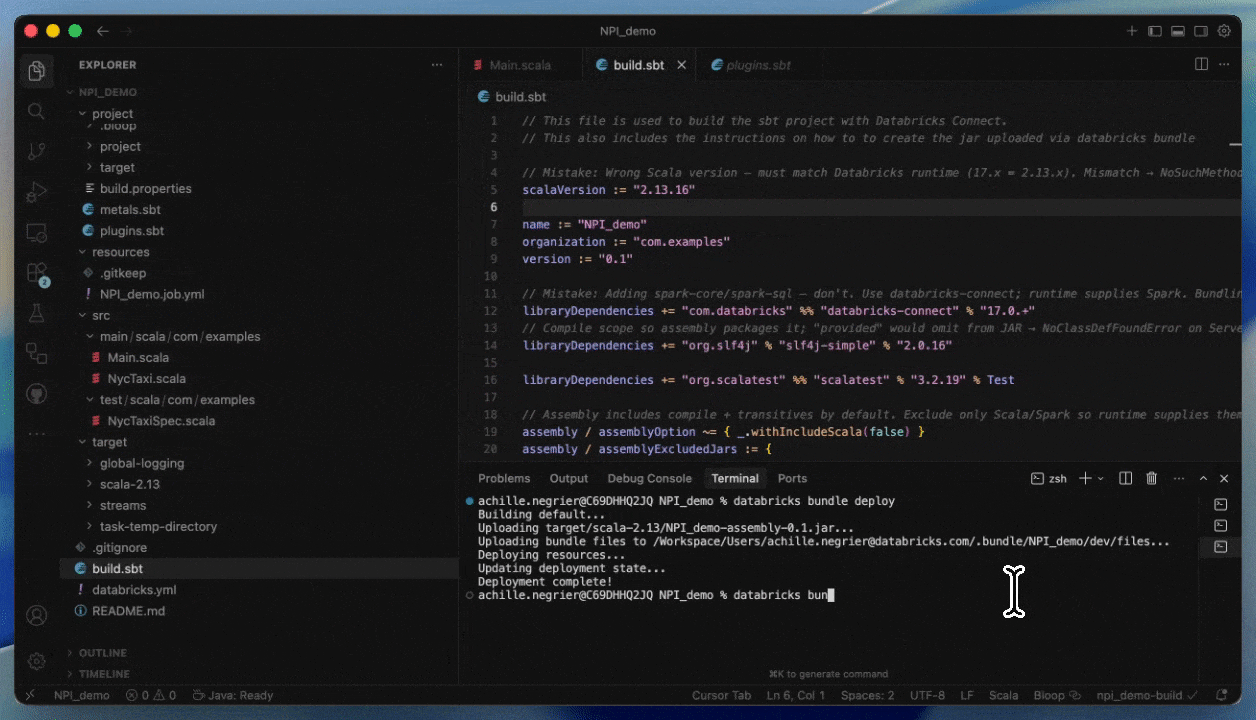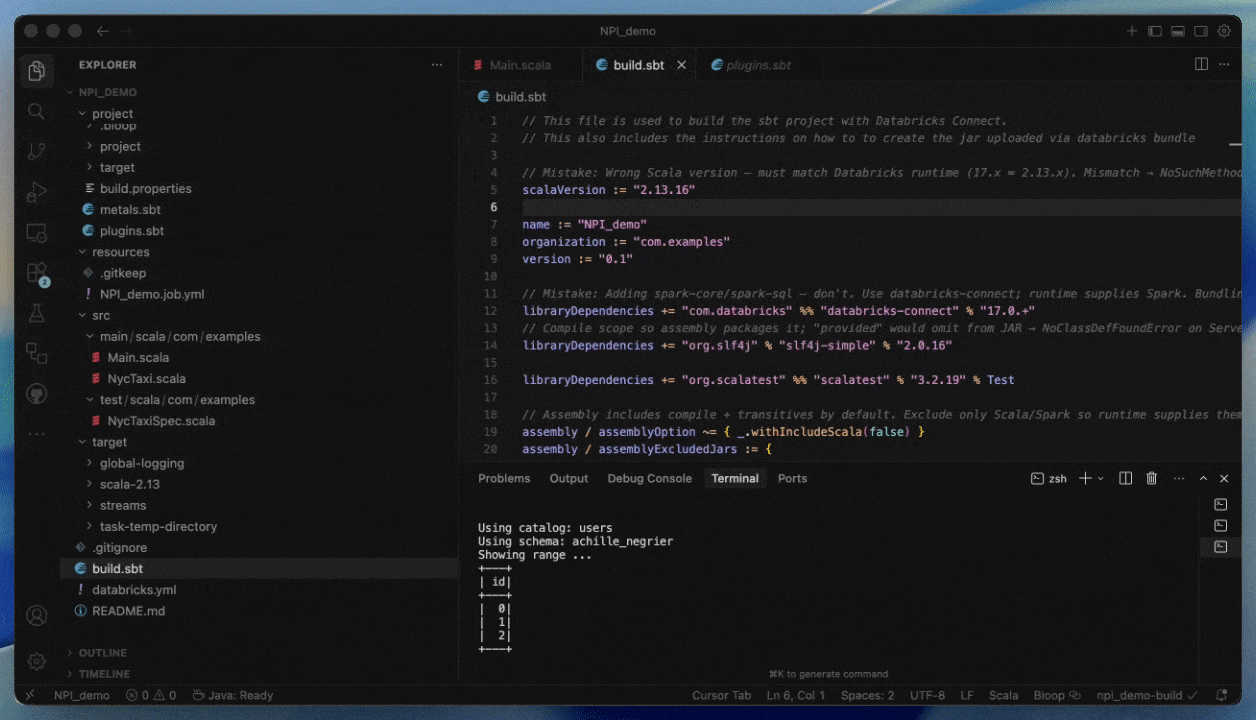
Cómo desplegar en Serverless proporcionando un JAR
Paso 1: Compilar su JAR para Serverless
- Compile con Spark 4 (Scala 2.13) y Spark Connect
- Agrupe todas las dependencias que no sean de Spark explícitamente o proporciónelas como JARs adicionales
Paso 2: Crear un trabajo Serverless
- Suba su JAR a un volumen de Unity Catalog o a una carpeta del espacio de trabajo de UC.
- Cree un nuevo trabajo utilizando una tarea JAR y seleccione Serverless como cómputo.
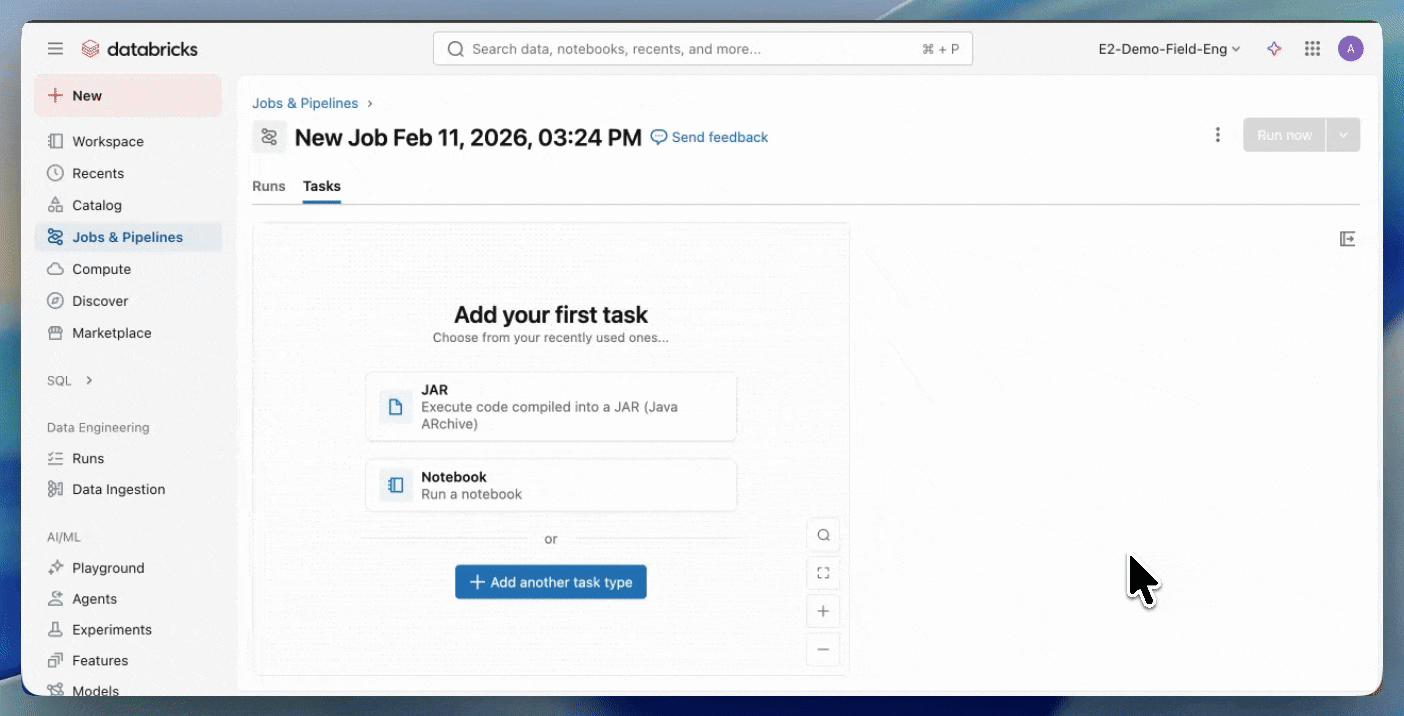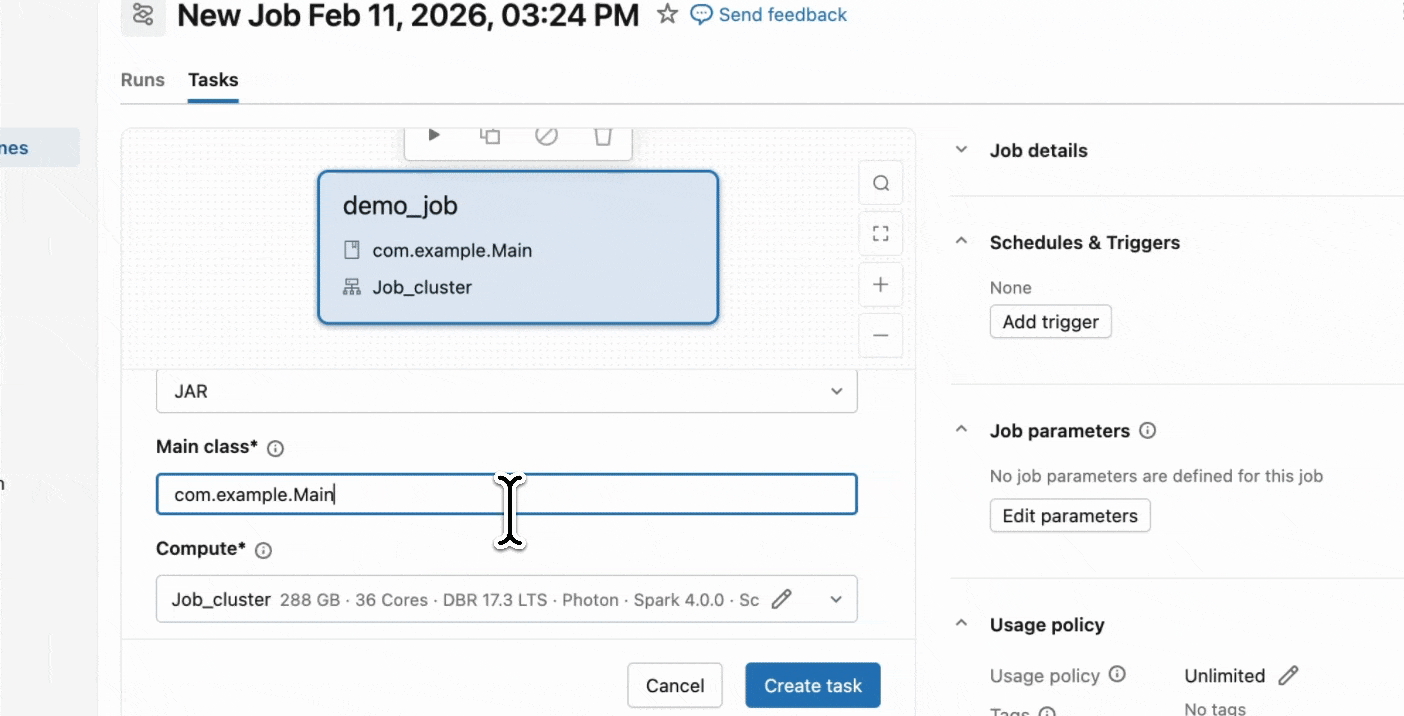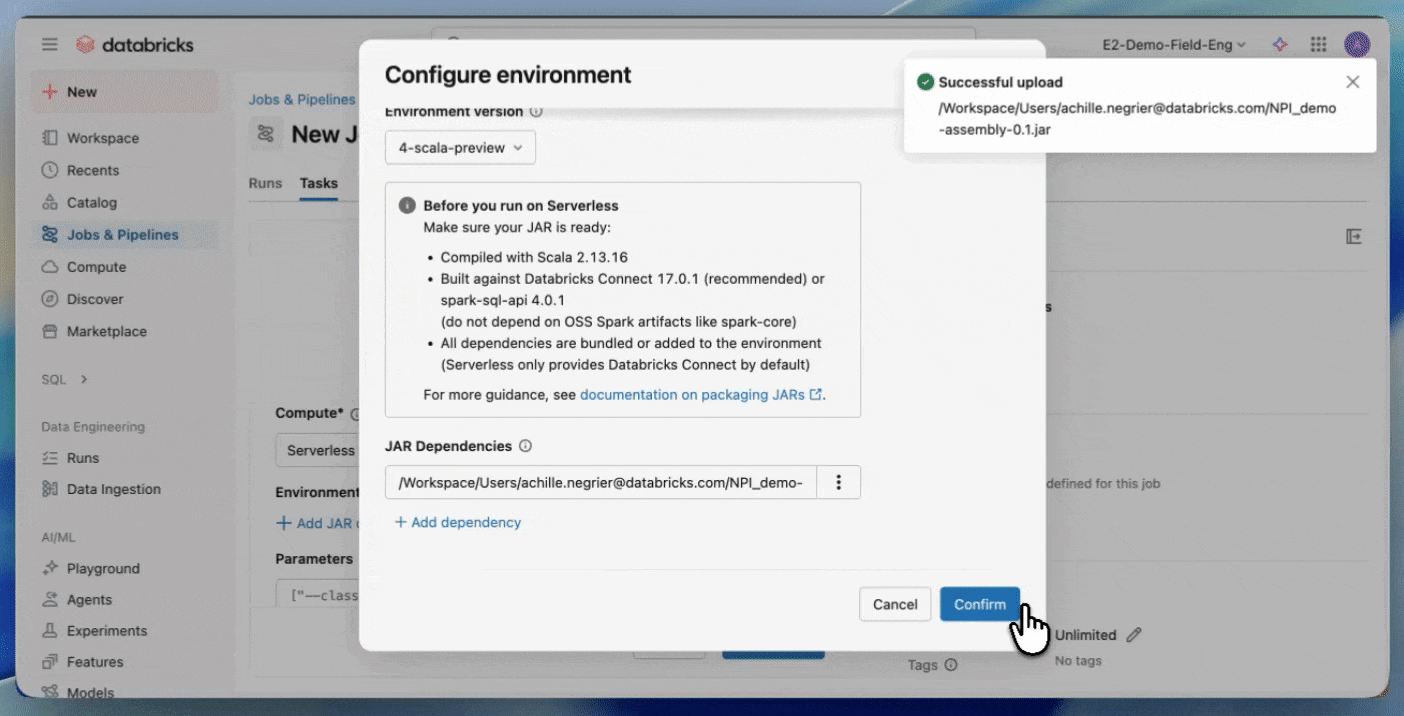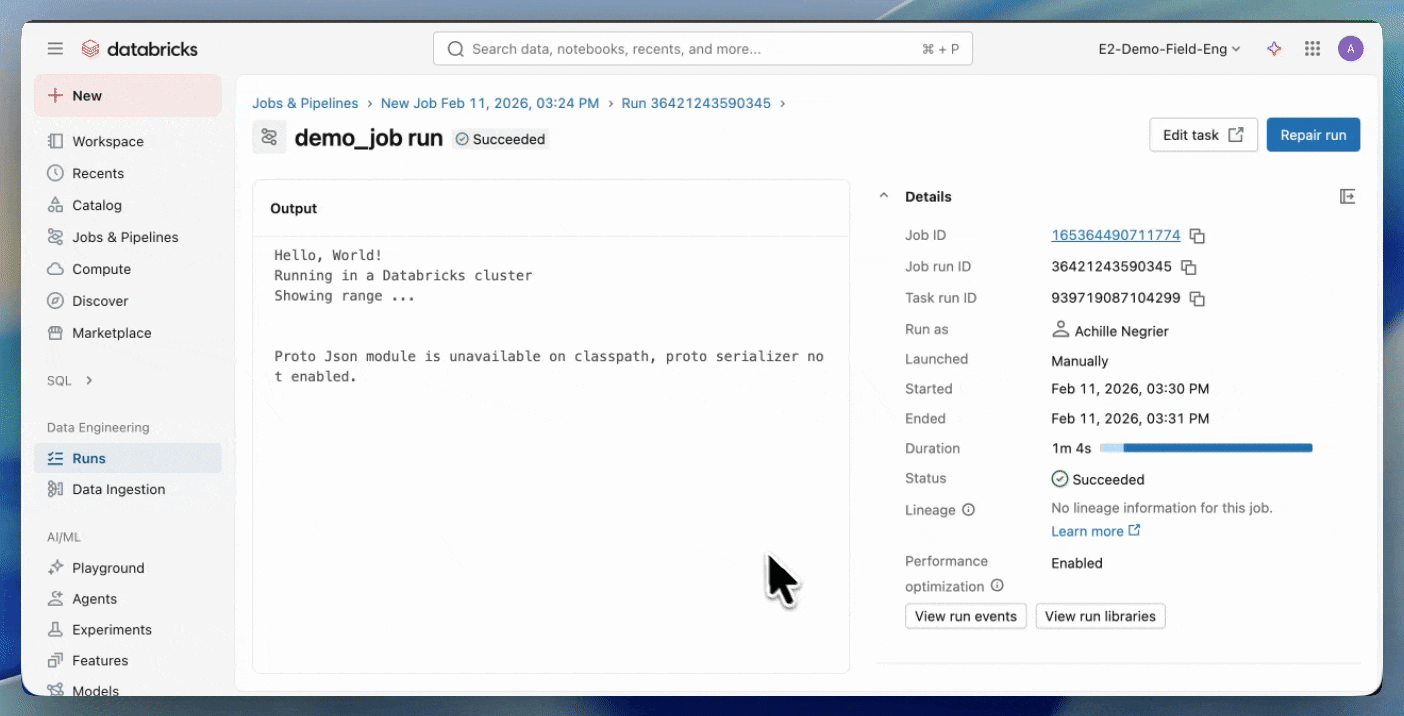
Comience con los JARs Serverless.
Para empezar rápidamente, siga el tutorial sobre el desarrollo y despliegue de trabajos Scala utilizando la plantilla de Databricks Asset Bundle. Para un tutorial sobre cómo compilar un JAR manualmente, consulte Ejecutar código Scala en cómputo Serverless.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.