Cómo Deutsche Börse creó una herramienta de IA generativa para abordar la migración a gran escala de notebooks de Zeppelin a Databricks
por Evan Pandya y Tobi Wole-Fasanya
- El equipo StatistiX de Deutsche Börse Group se enfrentó a un desafío de migración de notebooks que afectaba a más de 2000 usuarios con una fecha límite en 2027 y sin una ruta manual escalable.
- El equipo creó una Databricks App que maneja la conversión estructural automáticamente y genera prompts de Genie conscientes del contexto para reconstruir la lógica del notebook con ayuda de IA.
- Con esta nueva app, la re-elaboración de notebooks que antes tomaba horas ahora toma 15-20 minutos por notebook.
En Deutsche Börse Group, nuestra plataforma StatistiX proporciona aproximadamente el 95% de todos los datos de Compensación y Negociación del grupo, impulsando el análisis de autoservicio para cientos de usuarios de negocio. Mantener esos datos accesibles y accionables es fundamental en todo lo que hacemos.
Durante años, eso significó notebooks de Zeppelin ejecutándose en Cloudera, con acceso a los sistemas de datos HDFS y Oracle. La plataforma nos sirvió bien, pero el panorama cambió. Cloudera está desmantelando completamente Zeppelin en 2027, nuestras cargas de trabajo de análisis se están moviendo a la nube y Databricks ha sido seleccionado como nuestra nueva plataforma de análisis unificada. Esa combinación creó un desafío de migración que la mayoría de las organizaciones subestiman: más de 2000 usuarios y un gran volumen de notebooks, muchos de ellos profundamente integrados en los flujos de trabajo diarios del negocio, todos necesitando ser migrados.
Reescribir todo manualmente llevaría años. Así que decidimos construir un mejor camino en Databricks.
El problema de la migración de notebooks
Las migraciones de infraestructura reciben mucha atención. Las migraciones de notebooks no suelen recibirla, lo que es una gran razón por la que ralentizan a los equipos.
Nuestros notebooks de Zeppelin no eran simples scripts. Contenían lógica compleja de SQL y Python, intérpretes personalizados, referencias a Oracle y HDFS, visualizaciones, widgets y lógica de programación incorporada a lo largo de los años. Cada uno reflejaba el conocimiento institucional de los equipos de negocio que dependían de él. La diversidad en todo el panorama de notebooks hacía que un motor de reescritura basado en reglas fuera poco práctico, ya que la lógica era simplemente demasiado heterogénea y específica del negocio para que las reglas automatizadas la manejaran de manera confiable.
Esa limitación nos llevó a una idea de diseño más clara: separar la estructura de la lógica y aplicar la herramienta adecuada a cada una. La conversión estructural (mapear el formato de párrafo de Zeppelin a celdas de Databricks, traducir la sintaxis del intérprete, reformatear metadatos) es determinista y automatizable, mientras que la reconstrucción de la lógica no lo es. Afortunadamente, los LLM son excelentes en esta parte de la conversión estructural.
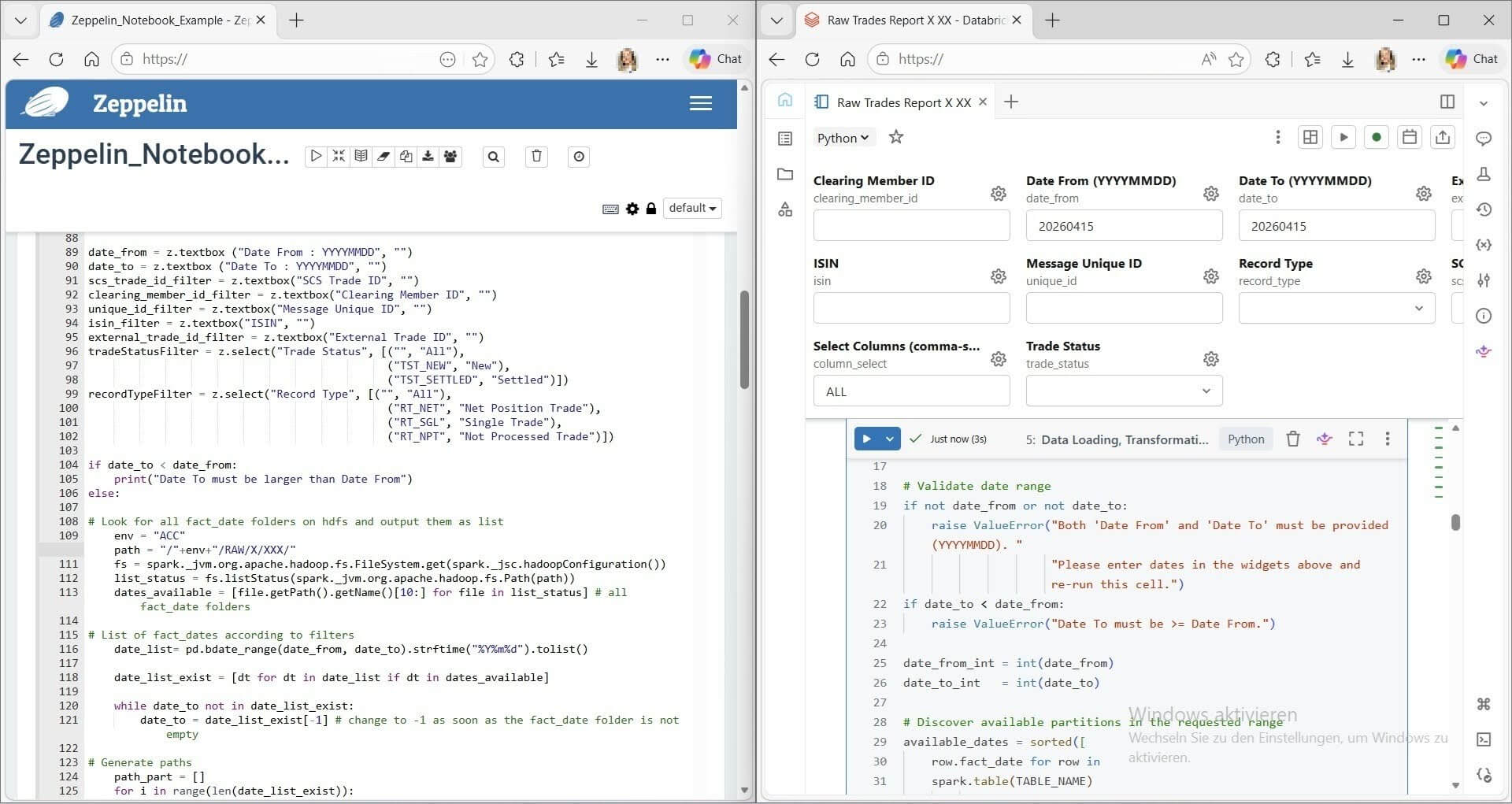
Construyendo el conversor en Databricks Apps
Con ese principio de diseño en mente, construimos el Conversor de Notebooks de Zeppelin a Databricks, una Databricks App diseñada específicamente para nuestro flujo de trabajo de migración.
La app maneja el lado estructural de la conversión: los párrafos de Zeppelin se convierten en celdas de Databricks, se aplican las asignaciones de intérpretes (%python, %sql, %pyspark y otros se traducen a sus equivalentes de Databricks), y los metadatos del notebook se reformatean en JSON .ipynb válido. El contenido original se conserva exactamente. No estamos reescribiendo la lógica en esta etapa, solo preparándola para el siguiente paso.
Ese siguiente paso es Genie. Para cada notebook cargado, la app genera automáticamente un prompt consciente del contexto que incluye detalles específicos sobre nuestro entorno Zeppelin. Piensa en nuestros intérpretes personalizados, fuentes de datos y patrones de configuración. El prompt le da a Genie el contexto que necesita para reconstruir la lógica con precisión de una manera nativa de Databricks.
El flujo de trabajo para un usuario de negocio es sencillo:
- Exportar un notebook de Zeppelin como JSON
- Subirlo a la Databricks App
- Hacer clic en Convertir
- Descargar el .ipynb convertido
- Abrir Databricks, subir el notebook, lanzar Genie y pegar el prompt generado
- Genie hace preguntas aclaratorias y reconstruye el notebook
La app en sí fue construida con un frontend shadcn UI. Originalmente, construimos un prototipo de Streamlit, pero sentimos que shadcn nos dio una interfaz más profesional y escalable. La experiencia de desarrollo de Databricks Apps facilitó el envío rápido sin necesidad de configurar infraestructura separada.
Lo que decidimos no automatizar
Una de las decisiones de diseño más importantes fue determinar qué debería dejar intencionalmente de lado la herramienta.
El conversor no reescribe la lógica SQL, la lógica Python, las visualizaciones, los widgets, las referencias a Oracle y HDFS, la lógica de programación o el código personalizado específico del negocio. Todo ese contenido se conserva en el notebook convertido, intacto, porque reescribirlo automáticamente introduciría errores y socavaría la confianza en el resultado. Estos son exactamente los elementos que más varían entre los notebooks y que contienen la lógica más crítica para el negocio. Pertenecen a Genie, que puede interpretar el contexto, hacer preguntas aclaratorias y tomar decisiones que las reglas no pueden.
Este enfoque híbrido de automatizar la parte determinista y delegar la parte variable nos permite evitar la fragilidad de los sistemas basados en reglas y aprovechar la IA donde realmente funciona bien.
El resultado: de horas a minutos
Al combinar la conversión estructural con la reconstrucción de lógica asistida por IA, hemos reducido la re-elaboración de notebooks de horas de esfuerzo manual a 15-20 minutos por notebook, dependiendo de la complejidad. Para una migración a gran escala de esta naturaleza, que abarca múltiples dominios de negocio, este enfoque transforma lo que habría sido una tarea intensiva en recursos y tiempo en un flujo de trabajo escalable y repetible que llevará mucho menos tiempo.
La ganancia de velocidad también cambia la naturaleza del trabajo. Los usuarios de negocio no necesitan un conocimiento profundo de Databricks para migrar sus propios notebooks. Siguen una breve secuencia de pasos, obtienen un prompt y dejan que Genie haga la reconstrucción. La herramienta es lo suficientemente accesible como para que la migración no requiera un equipo de ingeniería dedicado.
Lo que aprendimos
Unos pocos principios surgieron de este proyecto que llevaríamos a cualquier esfuerzo similar.
- Evita la sobreingeniería. Nuestro primer intento utilizó una arquitectura agéntica más compleja que añadió sobrecarga sin resolver el problema central. Una interfaz de usuario simple y un backend limpio resultaron ser exactamente suficientes.
- La reescritura basada en reglas no escala para contenido heterogéneo. La diversidad de lógica en nuestros notebooks hizo que las reglas fueran poco prácticas. Los LLM son esenciales para manejar esa variabilidad y la clave es diseñar la transferencia entre la automatización y la IA de manera reflexiva.
- El contexto es la diferencia entre un buen prompt y uno excelente. Los prompts genéricos de Genie producen resultados genéricos. Invertir en un prompt que codifique el conocimiento de nuestro entorno específico (intérpretes, fuentes de datos, patrones de configuración) es lo que hizo que el resultado fuera realmente utilizable.
- Involucra a tu equipo de plataforma desde el principio. Nuestra colaboración con el equipo de Databricks durante la construcción nos ayudó a mantenernos alineados y evitar retrabajos.
Qué sigue
Si bien el desarrollo inicial de nuestra herramienta de conversión está completo, ahora estamos procediendo con pruebas a gran escala en el mundo real. Nuestras prioridades inmediatas incluyen finalizar las definiciones de prompts para mejorar la precisión, validar la herramienta con notebooks de varias entidades de negocio y TI, y prepararnos para incorporar a los usuarios.
La implicación más amplia es lo que más nos entusiasma. ¡Este proyecto demostró que la migración asistida por IA no es una capacidad futura, está disponible ahora! Al combinar Databricks Apps con IA generativa, hemos construido un flujo de trabajo repetible que convierte uno de los problemas más difíciles de la transformación a la nube en un proceso rápido y escalable.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.