How Deutsche Börse built a generative AI tool to tackle the large-scale migration of Zeppelin notebooks to Databricks
by Evan Pandya and Tobi Wole-Fasanya
- Deutsche Börse Group’s StatistiX team faced a notebook migration challenge affecting 2,000+ users with a 2027 deadline and no scalable manual path forward.
- The team built a Databricks App that handles structural conversion automatically and generates context-aware Genie prompts to reconstruct notebook logic with AI assistance.
- With this new app, notebook redevelopment that previously took hours now takes 15–20 minutes per notebook.
At Deutsche Börse Group, our StatistiX platform provides approximately 95% of all Clearing and Trading data across the group, powering self-service analytics for hundreds of business users. Keeping that data accessible and actionable is central to everything we do.
For years, that meant Zeppelin notebooks running on Cloudera, with access to HDFS and Oracle data systems. The platform served us well, but the landscape shifted. Cloudera is fully decommissioning Zeppelin in 2027, our analytics workloads are moving to the cloud, and Databricks has been selected as our new unified analytics platform. That combination created a migration challenge that most organizations underestimate: 2,000+ users and a high volume of notebooks, many of them deeply embedded in day-to-day business workflows, all needing to move.
Rewriting everything manually would take years. So we decided to build a better path on Databricks.
The notebook migration problem
Infrastructure migrations get a lot of attention. Notebook migrations tend not to, which is a big reason why they slow teams down.
Our Zeppelin notebooks weren't simple scripts. They contained complex SQL and Python logic, custom interpreters, Oracle and HDFS references, visualizations, widgets and scheduling logic built up over years. Each one reflected institutional knowledge from the business teams who relied on it. The diversity across the entire notebook landscape made a rule-based rewriting engine impractical, since the logic was simply too heterogeneous and too business-specific for automated rules to handle reliably.
That constraint led us to a cleaner design insight: separate structure from logic, and apply the right tool to each. Structural conversion (mapping Zeppelin's paragraph format to Databricks cells, translating interpreter syntax, reformatting metadata) is deterministic and automatable, while logic reconstruction is not. Thankfully, LLMs are great at this structural conversion part..
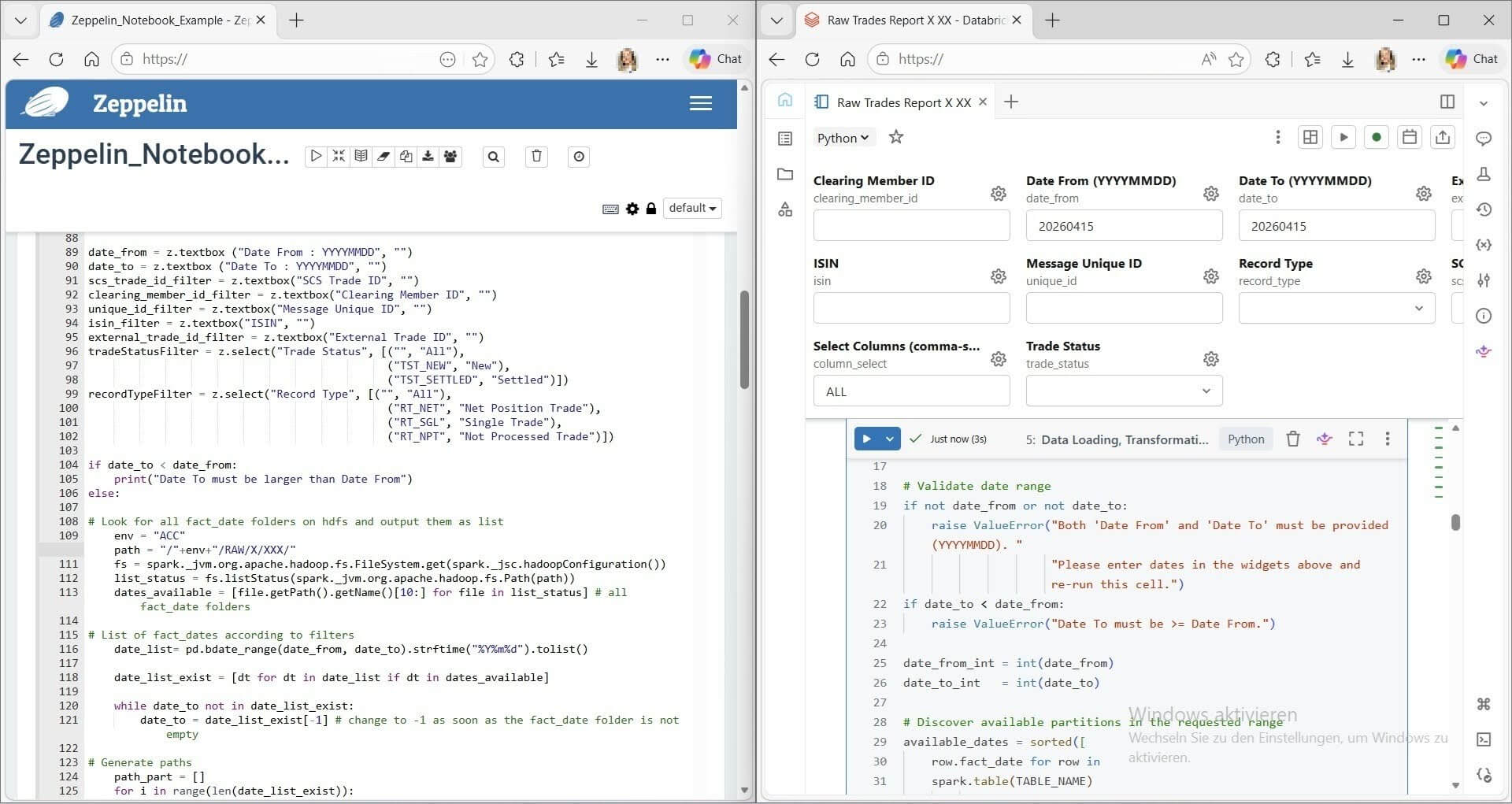
Building the converter on Databricks Apps
With that design principle in hand, we built the Zeppelin to Databricks Notebook Converter, a Databricks App designed specifically for our migration workflow.
The app handles the structural side of the conversion: Zeppelin paragraphs become Databricks cells, interpreter mappings are applied (%python, %sql, %pyspark and others are translated to their Databricks equivalents), and notebook metadata is reformatted into valid .ipynb JSON. Original content is preserved exactly. We're not rewriting logic at this stage, just preparing it for the next step.
That next step is Genie. For every uploaded notebook, the app automatically generates a context-aware prompt that includes specific details about our Zeppelin environment. Think our custom interpreters, data sources and configuration patterns. The prompt gives Genie the context it needs to reconstruct logic accurately in a Databricks-native way.
The workflow for a business user is straightforward:
- Export a Zeppelin notebook as JSON
- Upload it into the Databricks App
- Click Convert
- Download the converted .ipynb
- Open Databricks, upload the notebook, launch Genie and paste the generated prompt
- Genie asks clarifying questions and rebuilds the notebook
The app itself was built with a shadcn UI frontend. Originally, we built a Streamlit prototype, but we felt that shadcn gave us a more professional and scalable interface. The Databricks Apps development experience made it straightforward to ship quickly without standing up separate infrastructure.
What we chose not to automate
One of the most important design decisions was determining what the tool should intentionally leave alone.
The converter does not rewrite SQL logic, Python logic, visualizations, widgets, Oracle and HDFS references, scheduling logic or business-specific custom code. All of that content is preserved in the converted notebook, untouched, because rewriting it automatically would introduce errors and undermine trust in the output. These are exactly the elements that vary most across notebooks and that carry the most business-critical logic. They belong to Genie, which can interpret context, ask clarifying questions and make judgment calls that rules cannot.
This hybrid approach of automating the deterministic part and delegating the variable part allows us to avoid the brittleness of rule-based systems and leverage AI where it actually performs well.
The result: hours to minutes
By combining structural conversion with AI-assisted logic reconstruction, we've reduced notebook redevelopment from hours of manual effort to 15–20 minutes per notebook, depending on complexity. For a large-scale migration of this nature, spanning multiple business domains, this approach transforms what would have been a resource-intensive, time-consuming undertaking into a scalable, repeatable workflow that will take much less time.
The speed gain also changes the nature of the work. Business users don't need deep Databricks expertise to migrate their own notebooks. They follow a short sequence of steps, get a prompt, and let Genie do the reconstruction. The tool is accessible enough that migration doesn't require a dedicated engineering team.
What we learned
A few principles emerged from this project that we'd carry into any similar effort.
- Avoid overengineering. Our first attempt used a more complex agentic architecture that added overhead without solving the core problem. A simple UI and a clean backend turned out to be exactly sufficient.
- Rule-based rewriting doesn't scale for heterogeneous content. The diversity of logic across our notebooks made rules impractical. LLMs are essential for handling that variability and the key is designing the handoff between automation and AI thoughtfully.
- Context is the difference between a good prompt and a great one. Generic Genie prompts produce generic results. Investing in a prompt that encodes knowledge of our specific environment–interpreters, data sources, configuration patterns–is what made the output actually usable.
- Engage your platform team early. Our collaboration with the Databricks team throughout the build helped us stay aligned and avoid rework.
What's next
While the initial development of our converter tool is complete, we are now proceeding with large-scale, real-world testing. Our immediate priorities include finalising prompt definitions to improve accuracy, validating the tool with notebooks across several business entities and IT, and preparing to onboard the users.
The broader implication is what excites us most. This project demonstrated that AI-assisted migration isn't a future capability, it's available now! By combining Databricks Apps with generative AI, we've built a repeatable workflow that turns one of cloud transformation's hardest problems into a fast, scalable process.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.