Cómo MakeMyTrip logró personalización en milisegundos a escala con Databricks
Descubre cómo Real-Time Mode ofrece recomendaciones de viaje instantáneas y contexto para agentes de IA
- Arquitectura unificada de streaming: MakeMyTrip superó los cuellos de botella de latencia del ETL tradicional al adoptar el Modo en Tiempo Real (RTM) de Databricks, creando una arquitectura Spark unificada sin necesidad de otros motores especializados.
- Personalización en milisegundos: Al procesar búsquedas de viajeros de alto volumen con flujo de datos continuo, RTM permitió latencias P50 inferiores a 50 ms, lo que impulsó directamente un aumento del 7% en las tasas de clics de los usuarios.
- Lógica unificada, innovación más rápida: Al utilizar un motor unificado, MakeMyTrip puede pasar sin problemas del procesamiento por lotes al procesamiento en tiempo real sin reescribir la lógica de negocio. Esto no solo elimina la complejidad operativa, sino que también impulsa la innovación futura, facilitando el suministro de contexto en tiempo real que los agentes de IA generativa necesitan para una toma de decisiones precisa.
Personalización en tiempo real a gran escala
Cada milisegundo cuenta cuando los viajeros buscan hoteles, vuelos o experiencias. Como la agencia de viajes en línea más grande de la India, MakeMyTrip compite en velocidad y relevancia en tiempo real. Una de sus características más importantes son los hoteles "últimamente buscados": a medida que los usuarios tocan la barra de búsqueda, esperan una lista personalizada en tiempo real de sus intereses recientes, basada en su interacción con el sistema.
A la escala de MakeMyTrip, ofrecer esa experiencia requiere una latencia inferior a un segundo en un pipeline de producción que atiende a millones de usuarios diarios, tanto en las líneas de negocio de viajes de consumo como corporativas. Al implementar el Modo en Tiempo Real (RTM) de Databricks, el motor de ejecución de próxima generación en Apache Spark™ Structured Streaming, MakeMyTrip logró con éxito latencias a nivel de milisegundos, al tiempo que mantenía una infraestructura rentable y reducía la complejidad de la ingeniería.
El Desafío: Latencia Ultra Baja sin Fragmentación Arquitectónica
El equipo de datos de MakeMyTrip necesitaba una latencia inferior a un segundo para el flujo de trabajo de hoteles "últimamente buscados" en todas las líneas de negocio. A su escala, incluso unos pocos cientos de milisegundos de retraso crean fricción en el viaje del usuario, lo que impacta directamente en las tasas de clics.
El modo de micro-lotes de Apache Spark introdujo límites de latencia inherentes que el equipo no pudo superar a pesar de una extensa optimización, entregando consistentemente una latencia de uno a dos segundos, demasiado lenta para sus requisitos.
A continuación, evaluaron Apache Flink en aproximadamente 10 pipelines de streaming que resolvieron sus requisitos de latencia. Sin embargo, la adopción de Apache Flink como segundo motor habría introducido desafíos significativos a largo plazo:
- Fragmentación arquitectónica: Mantener motores separados para procesamiento en tiempo real y por lotes
- Duplicación de lógica de negocio: Las reglas de negocio tendrían que implementarse y mantenerse en dos bases de código
- Mayor sobrecarga operativa: Duplicar el esfuerzo de monitoreo, depuración y gobernanza en múltiples pipelines
- Riesgos de consistencia: Los resultados corren el riesgo de divergir entre el procesamiento por lotes y en tiempo real
- Costos de infraestructura: Ejecutar y optimizar dos motores aumenta el gasto de cómputo y la carga de mantenimiento
Por qué el Modo en Tiempo Real: Latencia de Milisegundos en una Única Pila de Spark
Dado que MakeMyTrip nunca quiso una arquitectura de doble motor, Apache Flink no era una opción viable a largo plazo. El equipo tomó una decisión arquitectónica deliberada: esperar a que Apache Spark fuera más rápido, en lugar de fragmentar la pila. Por lo tanto, cuando Apache Spark Structured Streaming introdujo RTM, MakeMyTrip se convirtió en el primer cliente en adoptarlo. RTM les permitió lograr latencia a nivel de milisegundos en Apache Spark, cumpliendo los requisitos en tiempo real sin introducir otro motor ni dividir la plataforma.
Mantener dos motores significa duplicar la complejidad y el riesgo de deriva lógica entre los cálculos por lotes y en tiempo real. Queríamos una única fuente de verdad, un pipeline basado en Spark, en lugar de dos motores que mantener. El Modo en Tiempo Real nos dio el rendimiento que necesitábamos con la simplicidad que queríamos." —Aditya Kumar, Director Asociado de Ingeniería, MakeMyTrip
RTM ofrece procesamiento continuo de baja latencia a través de tres innovaciones técnicas clave que trabajan juntas para eliminar las fuentes de latencia inherentes a la ejecución de micro-lotes:
- Flujo de datos continuo: Los datos se procesan a medida que llegan en lugar de discretizarse en fragmentos periódicos.
- Programación de pipelines: Las etapas se ejecutan simultáneamente sin bloqueo, lo que permite que las tareas posteriores procesen los datos inmediatamente sin esperar a que las etapas anteriores finalicen.
- Shuffle de streaming: Los datos se pasan entre tareas inmediatamente, evitando los cuellos de botella de latencia de los shuffles tradicionales basados en disco.
En conjunto, estas innovaciones permiten a Apache Spark lograr pipelines a escala de milisegundos que antes solo eran posibles con motores especializados. Para obtener más información sobre la base técnica de RTM, lea esta entrada de blog, "Rompiendo la Barrera de Micro-lotes: La Arquitectura del Modo en Tiempo Real de Apache Spark."
La Arquitectura: Un Pipeline Unificado en Tiempo Real
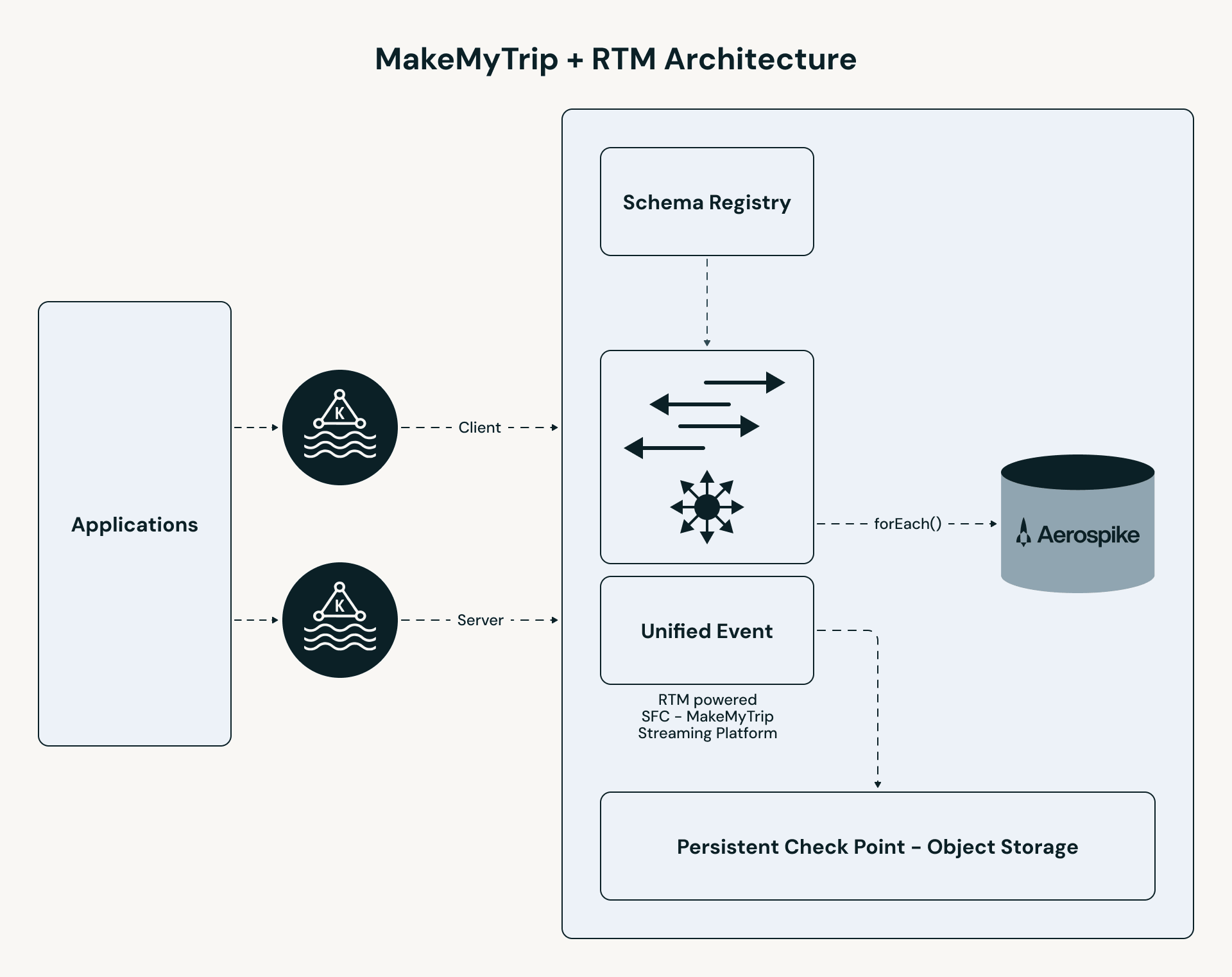
El pipeline de MakeMyTrip sigue una ruta de alto rendimiento:
- Ingesta unificada: Los temas de clics de B2C y B2B se fusionan en un único stream. Toda la lógica de personalización (enriquecimiento, búsqueda con estado y procesamiento de eventos) se aplica de manera consistente en ambos segmentos de usuarios.
- Procesamiento RTM: El motor Apache Spark utiliza programación concurrente y shuffle de streaming para procesar eventos en milisegundos.
- Enriquecimiento con estado: El pipeline realiza una búsqueda de baja latencia en Aerospike para recuperar los "Últimos N" hoteles para cada usuario.
- Servicio instantáneo: Los resultados se envían a una caché de UI (Redis), lo que permite que la aplicación sirva resultados personalizados en menos de 50 ms.
Configuración de RTM: un cambio de código de una sola línea
Usar RTM en su consulta de streaming no requiere reescribir la lógica de negocio ni reestructurar los pipelines. El único cambio de código necesario es establecer el tipo de disparador en RealTimeTrigger, como se muestra en el siguiente fragmento de código:
La única consideración de infraestructura: las ranuras de tareas del clúster deben ser mayores o iguales al número total de tareas activas en las etapas de origen y shuffle. El equipo de MakeMyTrip analizó sus particiones de Kafka, particiones de shuffle y la complejidad del pipeline de antemano para garantizar una concurrencia suficiente antes de pasar a producción.
Co-desarrollo de RTM para Producción
Como primer adoptante de RTM, MakeMyTrip trabajó directamente con la ingeniería de Databricks para llevar el pipeline a la preparación para producción. Varias capacidades requirieron colaboración activa entre los dos equipos para construir, optimizar y validar.
- Stream Union: Fusión de B2C y B2B en un Único Pipeline
MakeMyTrip necesitaba unificar dos flujos de Kafka separados (clics de consumo B2C y viajes corporativos B2B) en un único pipeline RTM para que la misma lógica de personalización pudiera aplicarse de manera consistente en ambos segmentos de usuarios. Después de un mes de estrecha colaboración con la ingeniería de Databricks, la función se construyó y se lanzó. El resultado fue un único pipeline donde toda la lógica de negocio reside en un solo lugar, sin riesgo de divergencia entre los segmentos de usuarios. - Multiplexación de Tareas: Más Particiones, Menos Núcleos
El modelo predeterminado de RTM asigna una ranura/núcleo por partición de Kafka. Con 64 particiones en la configuración de producción de MakeMyTrip, eso se traduce en 64 ranuras/núcleos, lo que resulta prohibitivo en cuanto a costos a su escala. Para abordar esto, el equipo de Databricks introdujo la opción MaxPartitions para Kafka, que permite que múltiples particiones sean manejadas por un solo núcleo. Esto le dio a MakeMyTrip la palanca que necesitaban para reducir los costos de infraestructura sin comprometer el rendimiento. - Fortalecimiento del Pipeline: Checkpointing, Backpressure y Tolerancia a Fallos
El equipo trabajó en una serie de desafíos operativos específicos para cargas de trabajo de baja latencia y alto rendimiento: optimización de la frecuencia y retención de checkpointing, manejo de tiempos de espera y gestión de backpressure durante picos en el volumen de clics. Al escalar a 64 particiones de Kafka, habilitar backpressure y limitar MaxRatePerPartition a 500 eventos, el equipo optimizó el rendimiento y la estabilidad. A través de esta optimización iterativa de las configuraciones de lotes, el particionamiento y el comportamiento de reintento, llegaron a un pipeline estable y listo para producción que atiende a millones de usuarios diariamente.
Resultados
RTM permitió la personalización instantánea y mejoró la capacidad de respuesta, una mayor participación medida a través de las tasas de clics y la simplicidad operativa de un único motor unificado. Las métricas clave se muestran a continuación.
Apache Spark como motor en tiempo real
La implementación de MakeMyTrip demuestra que RTM en Spark ofrece la latencia extremadamente baja que requieren tus aplicaciones en tiempo real. Dado que RTM se basa en las mismas API de Spark que ya conoces, puedes usar la misma lógica de negocio en pipelines batch y en tiempo real. Ya no necesitas el sobrecoste de mantener una segunda plataforma o un codebase separado para el procesamiento en tiempo real, y puedes habilitar RTM en Spark con una sola línea de código.
El Modo en Tiempo Real nos permitió comprimir nuestra infraestructura y ofrecer experiencias en tiempo real sin gestionar múltiples motores de streaming. A medida que avanzamos hacia la era de los agentes de IA, dirigirlos eficazmente requiere construir contexto en tiempo real a partir de flujos de datos. Estamos experimentando con Spark RTM para proporcionar a nuestros agentes el contexto más rico y reciente necesario para tomar las mejores decisiones posibles. —Aditya Kumar, Director Asociado de Ingeniería, MakeMyTrip
Primeros pasos con el Modo en Tiempo Real
Para obtener más información sobre el Modo en Tiempo Real, mira este vídeo bajo demanda sobre cómo empezar o revisa la documentación.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.