Rompiendo la barrera de los microlotes: la arquitectura del modo en tiempo real de Apache Spark
Cómo evolucionamos Spark para manejar ETL de alto rendimiento y cargas de trabajo de streaming de latencia ultrabaja
por Jerry Peng, Siying Dong y Indrajit Roy
- El Modo en tiempo real de Apache Structured Streaming unifica las cargas de trabajo operativas de ETL de alto rendimiento y latencia de milisegundos en un solo motor.
- Análisis profundo del modelo de ejecución híbrido, que detalla las etapas de procesamiento concurrente y los operadores sin bloqueo que ofrecen latencias de milisegundos.
- Los clientes ahora pueden lograr una capacidad de respuesta inferior a 100 ms para aplicaciones de latencia ultrabaja, como la detección de fraudes en tiempo real.
Con el lanzamiento del modo de tiempo real (RTM) en Apache Spark 4.1, Structured Streaming ahora ofrece una latencia de milisegundos. En una publicación de blog reciente, demostramos cómo el RTM puede superar a Flink en muchas cargas de trabajo de ingeniería de características de baja latencia (véase a continuación).
En este blog, analizaremos los cambios de arquitectura que permitieron a Structured Streaming admitir tanto cargas de trabajo ETL de alto rendimiento como cargas de trabajo de latencia ultrabaja.
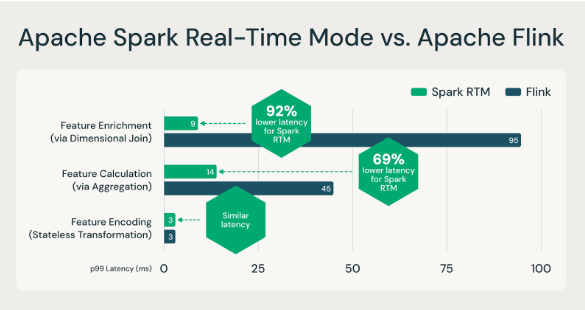
Apache Spark RTM es más rápido que Flink para casos de uso de ingeniería de características.
El dilema entre rendimiento y latencia
Hasta ahora, elegir un motor de streaming implicaba hacer una concesión al optar por sistemas como Apache Spark para cargas de trabajo ETL de alto rendimiento o sistemas como Apache Flink para cargas de trabajo de baja latencia. Los dos sistemas tienen semánticas y características de rendimiento muy diferentes. Eso cambia con RTM en Structured Streaming. Con la introducción de RTM, Apache Spark ahora puede gestionar tanto casos de uso de alto rendimiento como de latencia ultrabaja. Esto significa que ahora es posible elegir un único motor sin una nueva curva de aprendizaje y evitar la gestión de dos sistemas completamente diferentes.
La arquitectura de microlotes ofrece un alto rendimiento
Spark Structured Streaming utiliza una arquitectura de microlotes: el sistema de streaming recibe datos de entrada y los divide en lotes discretos llamados épocas, según la disponibilidad de los datos y las configuraciones de tamaño máximo de lote. El motor de Spark aplica la lógica de negocio a través de transformaciones como proyección, filtro y agregación. Los resultados se emiten como un flujo continuo de lotes. Structured Streaming se destaca en el procesamiento de alto rendimiento debido a esta arquitectura de microlotes: como se procesan varios registros a la vez, los sobrecostos fijos se amortizan y la ejecución vectorizada puede mejorar aún más el rendimiento. Estos lotes se ejecutan en paralelo, manteniendo una alta utilización del hardware. El modo de microlotes asigna dinámicamente ranuras de tareas a través de múltiples flujos, lo que además ayuda a obtener una alta utilización y un gran rendimiento. La innovación fundamental de Spark de tolerancia a fallos basada en el linaje garantiza que estos flujos se procesen con sólidas garantías de tipo “exactly-once”.
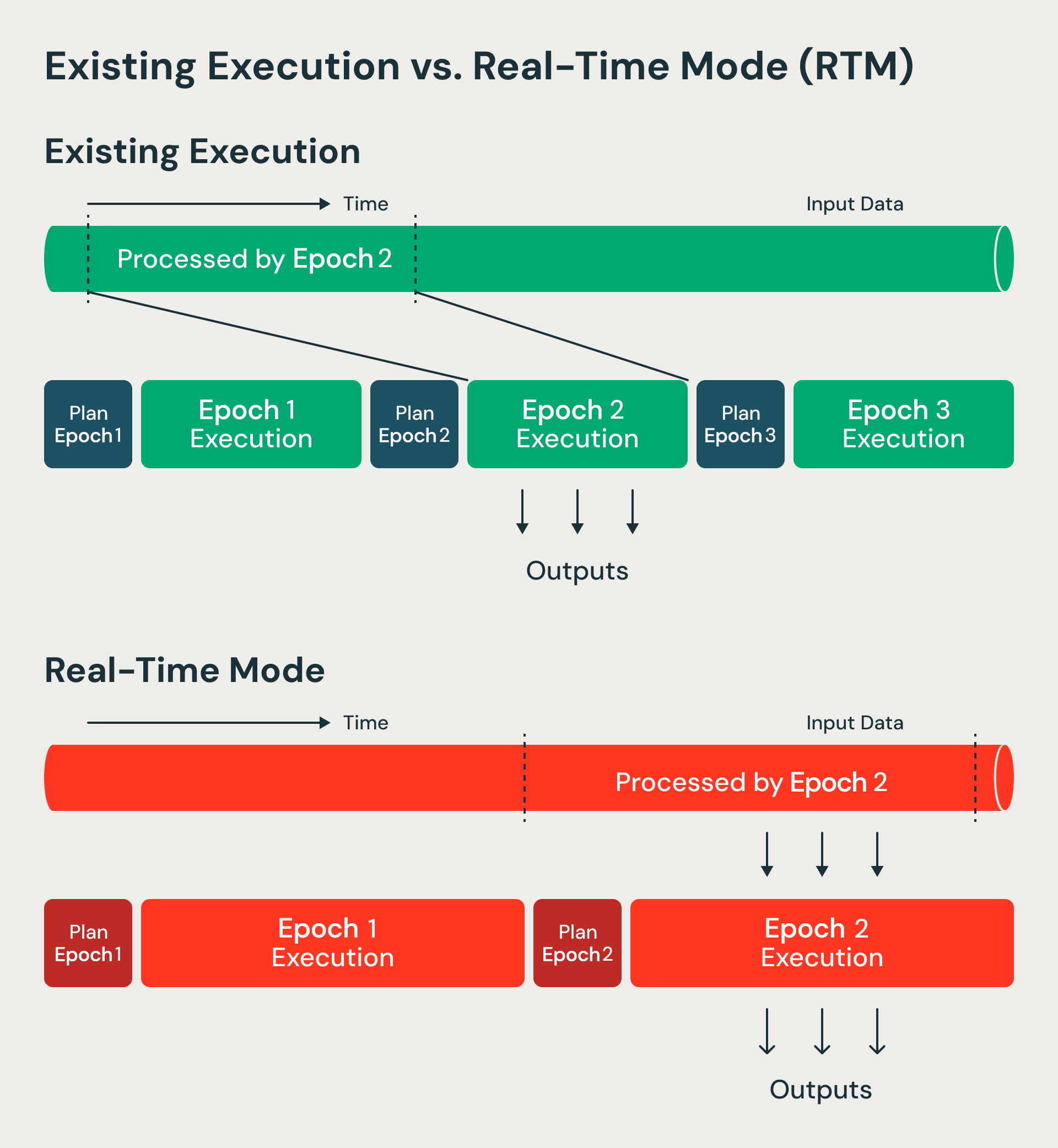
RTM procesa los datos de forma no bloqueante en comparación con el modo de microlotes.
Resolviendo el reto de la baja latencia
Aunque Structured Streaming es muy bueno para gestionar cargas de trabajo de ETL e ingesta a nivel de segundos, muchos casos de uso operativos exigen una latencia de milisegundos. La detección de fraudes en transacciones financieras, la información en tiempo real en la industria de los viajes o el análisis de datos de telemetría de vehículos conectados son ejemplos en los que los clientes necesitan respuestas en milisegundos.
Desafío arquitectónico: por qué los lotes más pequeños no funcionan
La solución obvia podría parecer simple: simplemente hacer los lotes más pequeños. Si procesamos un registro a la vez, deberíamos obtener un rendimiento en tiempo real. Lamentablemente, no es tan sencillo.
Cada microlote en Structured Streaming conlleva costos fijos que dominan el tiempo de ejecución al procesar pequeñas cantidades de datos. El sistema escribe archivos de registro en un almacenamiento de objetos duradero antes y después de cada ejecución de microlotes. Además, las actualizaciones de estado para cada consulta con estado también deben cargarse en el almacenamiento de objetos al final de un microlote. Estos son pasos críticos para garantizar la semántica de consistencia, pero pueden añadir cientos de milisegundos, si no segundos, al tiempo de ejecución. Incluso si ocultamos algunas de estas latencias, la latencia de la planificación de cada lote, la sobrecarga de planificación lógica y física, la serialización de tareas y la programación son difíciles de reducir. Como puede imaginar, reducir el tamaño de los lotes rápidamente se topa con un muro. La siguiente figura muestra que cuando los microlotes se vuelven demasiado pequeños (barra de la izquierda), los costos fijos de procesamiento de microlotes dominan la ejecución y aumentan la latencia de extremo a extremo.
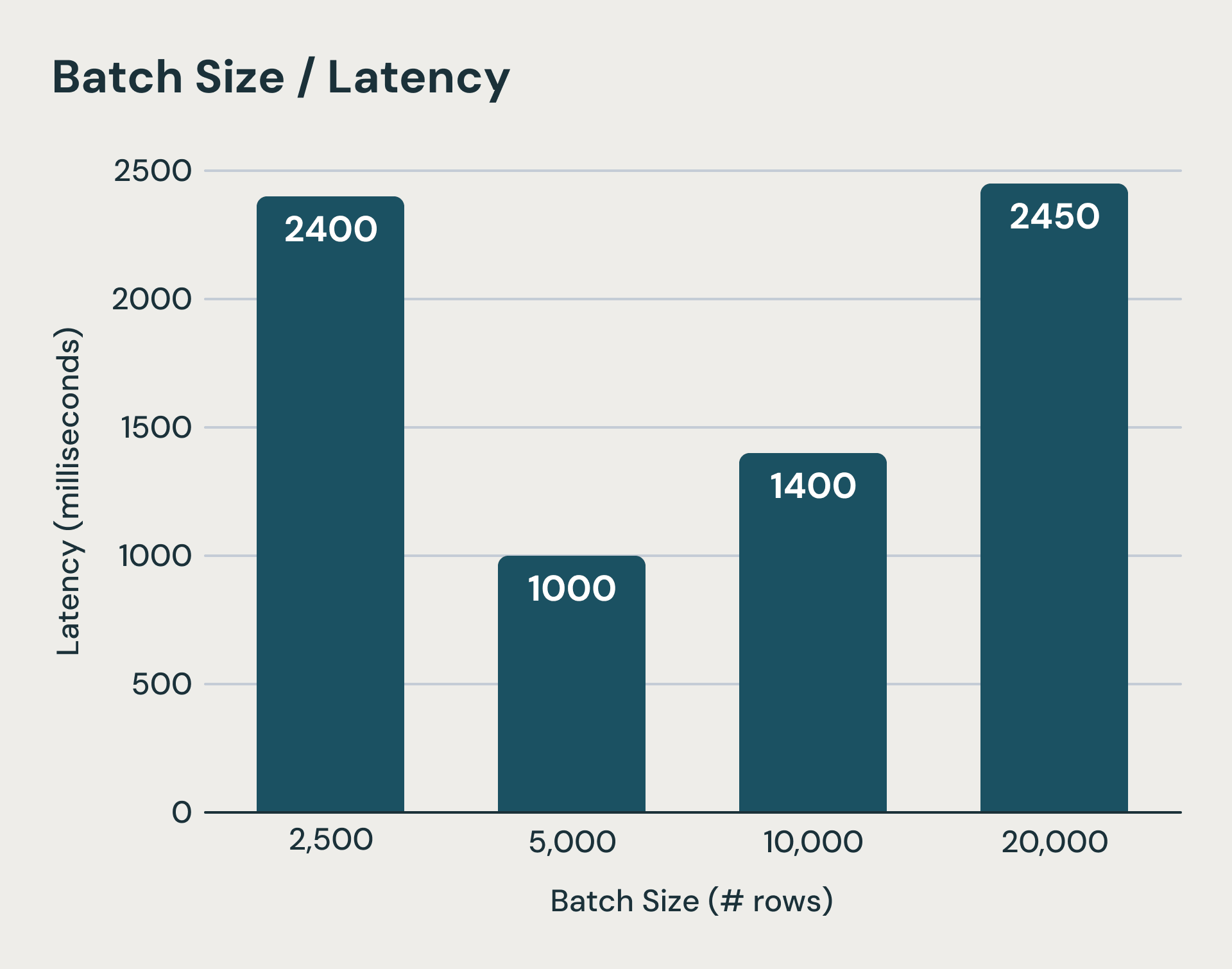
Más allá de un umbral, los tamaños de lote más pequeños pueden aumentar la latencia debido a las sobrecargas fijas
Esto nos presentó un reto de arquitectura: queríamos conservar las ventajas de costo y tolerancia a fallos de la arquitectura de microlotes y, al mismo tiempo, lograr la baja latencia que se espera de los modelos que procesan registro por registro (como Apache Storm y Apache Flink). Nuestra idea clave es que podemos evolucionar la arquitectura de microlotes para admitir cargas de trabajo en tiempo real. Seguimos usando muchas de las características principales de la arquitectura de microlotes, como los puntos de control para la tolerancia a fallos. Sin embargo, eliminamos los pasos de espera de los datos que provocaban una alta latencia. A continuación, analizamos estos cambios.
Nuestra solución: un modelo de ejecución híbrido
Así es como mejoramos la latencia de Structured Streaming:
1. Épocas de mayor duración con flujo de datos continuo
El modo de microlotes procesa lotes de datos denominados épocas. Los límites de las épocas se deciden de antemano usando los desplazamientos de inicio y fin. En cambio, el modo en tiempo real procesa épocas de mayor duración, pero modifica la forma en que los datos fluyen dentro de cada época. Ahora los datos fluyen de forma continua a través de diferentes etapas y operadores sin bloquearse. Como las épocas son de mayor duración, la sobrecarga de los puntos de control y las barreras se amortiza. En los límites de las épocas, seguimos usando barreras para el registro de la recuperación y la reprogramación de tareas, lo que conserva las ventajas que hacen que las arquitecturas de microlotes sean resilientes y eficientes. Básicamente, evolucionamos el microlote en Structured Streaming a un intervalo de punto de control.
2. Etapas de procesamiento concurrentes
En la arquitectura de Structured Streaming, las etapas de procesamiento se ejecutaban de forma secuencial —los reducers esperaban que los mappers se completaran, lo que creaba retrasos innecesarios. Hicimos que estas etapas fueran concurrentes en el modo de tiempo real. Ahora el controlador de Spark solicita los desplazamientos de origen y programa los mapeadores, pero los reductores pueden empezar a procesar los archivos de mezcla tan pronto como estén disponibles, en lugar de esperar a que todos los mapeadores terminen. Este cambio reduce drásticamente la latencia de extremo a extremo. La figura RTM a continuación muestra que las dos etapas se ejecutan de forma concurrente, y la etapa 2 comienza a procesar filas tan pronto como son procesadas por la etapa 1.
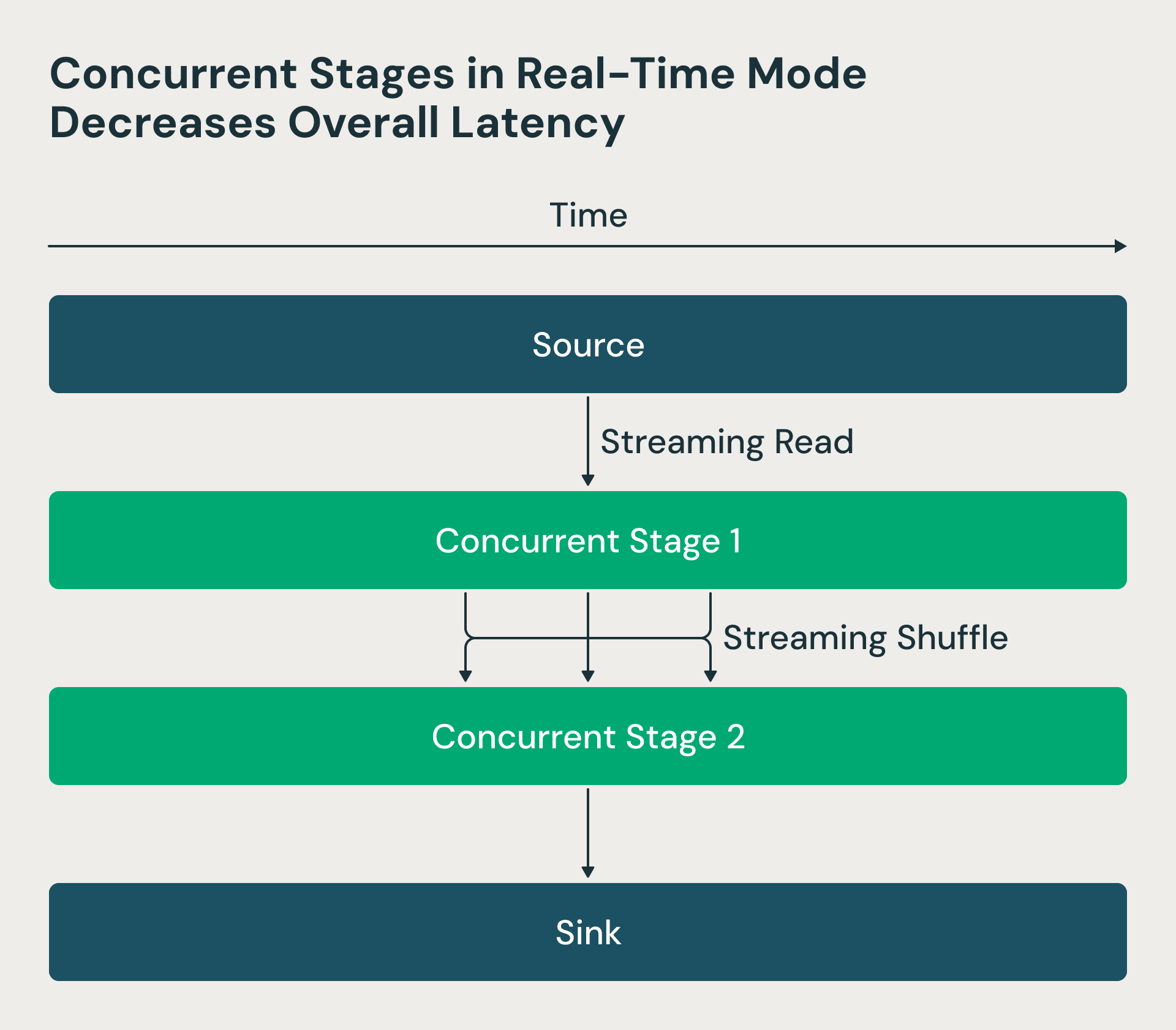
El modo en tiempo real utiliza etapas concurrentes, lo que disminuye la latencia
3. Operadores no bloqueantes
Reestructuramos operadores clave como shuffle, que estaban diseñados para la ejecución por lotes con un almacenamiento en búfer sustancial. En el modo por lotes, una agregación group-by almacenaría en búfer todos los registros, realizaría una preagregación y emitiría los resultados solo al final. Para el procesamiento en tiempo real, modificamos estos operadores para minimizar el almacenamiento en búfer y producir resultados de forma continua, lo que permite que los datos fluyan a través del pipeline sin esperas innecesarias.
Resumen
Al usar épocas de mayor duración con un flujo de datos continuo, etapas de procesamiento concurrentes y operadores sin bloqueo, hemos generalizado el motor de Apache Spark Structured Streaming para manejar tanto los casos de uso de streaming de alto rendimiento como los de latencia ultrabaja. Este enfoque híbrido ahora elimina la necesidad de elegir entre motores de streaming. Los usuarios solo necesitan aprender a usar Apache Spark y no es necesario aprender otro framework dedicado al streaming de latencia ultrabaja.
El modo en tiempo real ya está en producción en Databricks y lo utilizan múltiples clientes, desde empresas financieras de vanguardia hasta sitios de viajes. Nuestros clientes pueden alcanzar una latencia de milisegundos para sus casos de uso.
Si bien este es un salto importante en las capacidades de Spark, seguimos agregando nuevas características de streaming. Si su organización está buscando soluciones para cargas de trabajo en tiempo real, ¡pruebe Apache Spark Structured Streaming!
Explore los recursos técnicos
Para profundizar en la ingeniería detrás de RTM, mire esta sesión bajo demanda dirigida por nuestros expertos en la materia. Ellos explicarán en detalle el diseño y la implementación del modo en tiempo real.
O revise la guía técnica del modo en tiempo real para saber cómo empezar. Encontrará todo lo que necesita para habilitar el procesamiento en tiempo real para sus cargas de trabajo de streaming.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.