Modo de tiempo real: streaming de latencia ultrabaja en las API de Spark sin un segundo motor
Procesa datos de streaming en milisegundos en Apache Spark, sin ninguna de las sobrecargas de Apache Flink
por Navneeth Nair, Jerry Peng y Abhay Bothra
- Unificación: descubre cómo el modo de tiempo real (RTM) en Apache Spark unifica el entrenamiento sin conexión y la ingeniería de características en línea de latencia ultrabaja en un único motor de alto rendimiento.
- Rendimiento: descubre la rearquitectura que permite una latencia ultrabaja en Spark, con un análisis de rendimiento que compara Apache Spark RTM con Apache Flink.
- Simplicidad y adopción: RTM ofrece muchas ventajas operativas, incluyendo una migración simplificada, una API unificada para evitar la "deriva lógica" y casos de uso reales de clientes.
Apache Spark Structured Streaming ha impulsado durante mucho tiempo los pipelines de datos de misión crítica a gran escala, desde ETL de streaming hasta análisis y machine learning. Pero a medida que los casos de uso operativos evolucionaron, los equipos comenzaron a exigir algo más: latencias de subsegundo para aplicaciones como la detección de fraudes, la personalización, la detección de anomalías, las alertas y los informes en tiempo real.
Históricamente, cumplir con estos requisitos de latencia ultrabaja significaba introducir sistemas especializados junto con Spark. Con la introducción del modo de tiempo real en Spark Structured Streaming, esa contrapartida ya no es necesaria. En este blog, exploramos cómo Spark simplifica la arquitectura de streaming en tiempo real para casos de uso comunes, como la ingeniería de características, elimina la complejidad operativa de larga data y ofrece un rendimiento líder en la industria.
El streaming en tiempo real ya no requiere ejecutar múltiples sistemas dispares
La capacidad de procesar datos y actuar sobre ellos en tiempo real es ahora un requisito fundamental. Las aplicaciones modernas, especialmente los agentes de IA, dependen de un flujo continuo de contexto actualizado para funcionar. Si los datos subyacentes están incompletos o desactualizados, la experiencia del usuario se ve afectada. El rendimiento en tiempo real no solo es necesario para casos de uso tradicionales como la detección de fraudes, sino para cada interacción común en la que un usuario espera respuestas precisas y actualizadas. En este entorno, la latencia afecta directamente los ingresos, la confianza del cliente y la ventaja competitiva.
Históricamente, los equipos de datos que creaban aplicaciones de streaming en tiempo real han tenido que gestionar dos stacks de procesamiento de datos distintos: Apache Spark™ para el análisis a gran escala y sistemas especializados como Apache Flink® o Kafka Streams para aplicaciones sensibles a la latencia y de subsegundo. Esta fragmentación requiere que los equipos mantengan bases de código duplicadas, administren modelos de gobernanza separados y contraten talento especializado para ajustar y mantener la infraestructura específica del motor.
Lanzado en versión preliminar pública en agosto de 2025, el Modo en tiempo real (RTM) para Apache Spark Structured Streaming está diseñado para eliminar esta fricción. Al evolucionar fundamentalmente el motor de ejecución de Spark, hemos eliminado la necesidad de un segundo sistema. Este cambio permite a los ingenieros abordar todo el espectro de casos de uso —desde ETL de alto rendimiento hasta aplicaciones en tiempo real de baja latencia— utilizando la misma API de Spark que ya conocen. Esto significa menos tiempo gestionando la infraestructura y más tiempo para centrarse en el caso de uso de negocio.
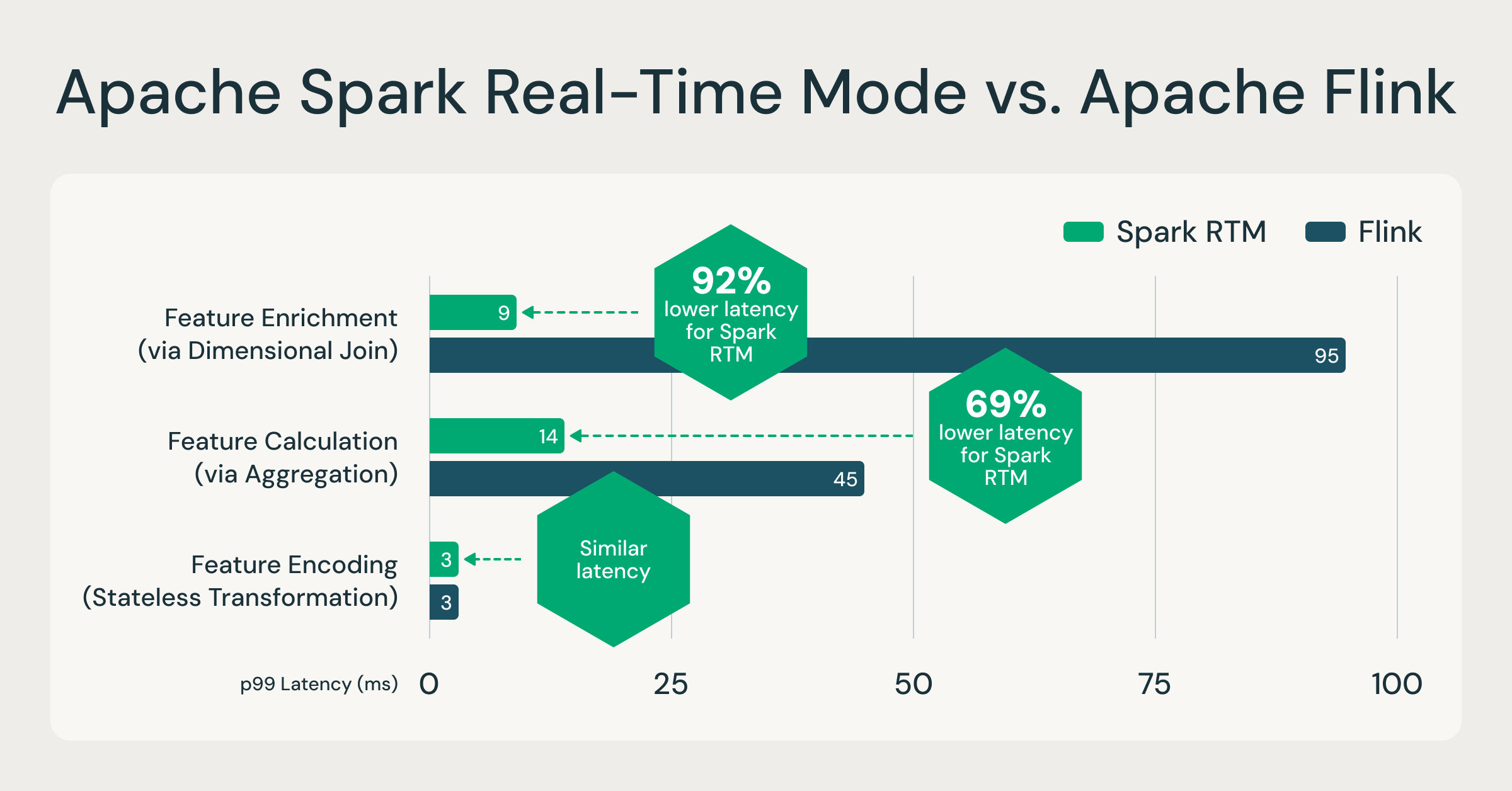
Spark ahora puede procesar eventos en milisegundos; hasta un 92 % más rápido que Flink
El modo de tiempo real (RTM) introdujo un nuevo motor de ejecución optimizado que permite a Spark ofrecer latencias consistentes de menos de un segundo. Para evaluar el rendimiento, realizamos una comparación en paralelo entre Spark RTM y Apache Flink. Las pruebas se basaron en cargas de trabajo de computación de características en tiempo real que vemos comúnmente en producción. Estos patrones de computación de características son representativos de la mayoría de los casos de uso de ETL de baja latencia, como la detección de fraudes, la personalización y el análisis operativo.
Evaluamos tres patrones de características comunes:
- Codificación de características (transformación sin estado): truncamiento de las filas de entrada y codificación
- Enriquecimiento de características (mediante join): Unión de un stream con una tabla estática
- Cálculo de características (mediante agregación): agregación GroupBy + Count
Los resultados demuestran que la arquitectura evolucionada de Spark proporciona un perfil de latencia comparable al de los frameworks de streaming especializados.
Este rendimiento es posible gracias a tres innovaciones técnicas clave en RTM:
- Flujo de datos continuo: los datos se procesan a medida que llegan, en lugar de en fragmentos periódicos y discretizados.
- Programación de canalizaciones: las etapas se ejecutan simultáneamente sin bloqueo, lo que permite que las tareas posteriores procesen los datos de inmediato sin esperar a que finalicen las etapas anteriores.
- Combinación de streaming: los datos se pasan entre tareas de inmediato, lo que evita los cuellos de botella de latencia de las combinaciones tradicionales basadas en disco.
En conjunto, estos transforman a Spark en un motor de alto rendimiento y baja latencia capaz de manejar los casos de uso operativos más exigentes.
Los equipos operan con menos infraestructura y se mueven más rápido con Spark.
Si bien la velocidad pura es esencial, el verdadero valor del modo de tiempo real reside en su capacidad para eliminar la complejidad operativa que normalmente dificulta la creación de pipelines de latencia ultrabaja. Spark RTM simplifica significativamente su arquitectura a través de tres ventajas principales. Para concretar esto, los describimos en el contexto de las aplicaciones de machine learning en tiempo real.
Minimizar la “deriva lógica” entre el entrenamiento y la inferencia: el ML en tiempo real, como la detección de fraudes, requiere una transferencia fluida entre el procesamiento por lotes de alto rendimiento (para el entrenamiento de modelos) y el streaming de baja latencia (para la inferencia en vivo). Spark es la opción preferida de los científicos de datos para el entrenamiento de modelos, y forzar un cambio de Spark a Flink para la inferencia crearía una brecha en la lógica de negocio. Terminas con una versión de la lógica en Spark para el entrenamiento y una base de código completamente diferente en Flink para la producción. Esta replicación de la lógica de negocio puede ser propensa a errores y conduce a la deriva lógica, donde tu modelo se entrena con una realidad, pero realiza predicciones sobre otra. Con Spark RTM, tu código de transformación permanece idéntico, lo que te permite poner las características en producción más rápido y con gran precisión.
Actualización de datos a pedido con un cambio de una sola línea de código: Los requisitos del negocio rara vez son estáticos. Un pipeline de características que hoy comienza con un SLA de 1 minuto podría requerir una latencia inferior al segundo mañana, a medida que evolucionan las necesidades de actualización de datos del modelo. Por el contrario, para muchos casos de uso, "ir más lento" (p. ej., lotes diarios u horarios) es significativamente más rentable cuando no se requiere una actualización de datos inmediata. Spark proporciona el espacio para crecer y escalar junto con su producto. Le permite cambiar fácilmente su estrategia de ingeniería de características con un cambio de una sola línea de código. Por ejemplo, puede configurar su activador en AvailableNow para ejecutar un pipeline con una programación diaria u horaria. Cuando las necesidades del negocio cambian, puede pasar al streaming continuo de latencia ultrabaja simplemente cambiando al modo de tiempo real: .trigger(RealTimeTrigger.apply()). En cambio, lograr esto en Flink es un proceso manual. A menudo, requiere que ajuste el paralelismo y organice el apagado y el reinicio de los recursos de computación solo para igualar una nueva frecuencia de procesamiento.
Acelere el desarrollo: RTM se basa en la misma API de Spark que su equipo ya conoce. Esto elimina la fricción de mantener múltiples sistemas, lo que le permite avanzar más rápido al crear y escalar aplicaciones en tiempo real dentro de un entorno único y coherente.
Los clientes están ejecutando varias aplicaciones en tiempo real en Spark.
Los primeros en adoptarlo están usando RTM para potenciar una gama de aplicaciones de baja latencia en diversas industrias.
Detección de fraudes: Una plataforma líder de activos digitales computa características de riesgo dinámicas, como verificaciones de velocidad y patrones de gasto agregado, a partir de flujos de Kafka, y actualiza su almacén de características en línea en menos de 200 milisegundos para bloquear transacciones fraudulentas en el punto de venta.
Experiencias personalizadas: Una plataforma de comercio electrónico computa características de intención en tiempo real basadas en la sesión actual de un usuario, lo que permite que los modelos actualicen las recomendaciones en el momento en que un usuario interactúa con un producto.
Monitoreo de IoT: una empresa de transporte y logística ingiere telemetría en vivo para impulsar la detección de anomalías, y pasa de una toma de decisiones reactiva a una proactiva en milisegundos.
DraftKings, uno de los servicios de apuestas deportivas y deportes de fantasía más grandes de Norteamérica, usa RTM para potenciar el cómputo de características para sus modelos de detección de fraudes.
“En las apuestas deportivas en vivo, la detección de fraudes exige una velocidad extrema. La introducción del modo de tiempo real, junto con la API transformWithState en Spark Structured Streaming, ha sido un punto de inflexión para nosotros. “Logramos mejoras sustanciales tanto en la latencia como en el diseño de pipelines y, por primera vez, creamos pipelines de características unificados para el entrenamiento de ML y la inferencia en línea, logrando latencias ultrabajas que antes simplemente no eran posibles”. —Maria Marinova, ingeniera de software líder sénior, DraftKings
Comienza a desarrollar con el modo de tiempo real de Spark.
La era de elegir entre "fácil" y "rápido" ha terminado. ¿Por qué administrar dos motores, dos modelos de seguridad y dos conjuntos de habilidades especializadas cuando ahora un solo motor lo hace todo? RTM ofrece la velocidad inferior al segundo que exigen tus aplicaciones en tiempo real, con la simplicidad arquitectónica que tu equipo merece. Al eliminar el "impuesto operativo", finalmente puedes centrarte en generar valor en lugar de administrar la infraestructura.
¿Listo para eliminar la complejidad de tu stack de tiempo real?
- Profundiza en los detalles: explora la documentación de RTM para comprender todas las especificaciones técnicas, las fuentes y los receptores compatibles y las consultas de ejemplo. Encontrarás todo lo que necesitas para habilitar el nuevo disparador y configurar tus cargas de trabajo de streaming.
- Véalo en acción: Para profundizar en la ingeniería detrás de RTM, mire esta sesión técnica de inmersión profunda, que recorre el diseño y la implementación.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.