Cómo migrar de Apache Airflow® a Databricks Lakeflow Jobs
Una guía práctica que mapea las prácticas comunes de Airflow a Lakeflow Jobs de Databricks con ejemplos de código lado a lado.
- Aprende cómo los patrones comunes de orquestación de Apache Airflow se mapean directamente a las capacidades de Lakeflow Jobs, el orquestador integrado de Databricks.
- Comprende cómo funcionan el flujo de control, los desencadenadores, los parámetros y la ejecución dinámica cuando la orquestación se integra con el lakehouse.
- Utiliza ejemplos de código que se pueden copiar y pegar para migrar DAGs reales de Airflow a Lakeflow Jobs de forma incremental
En la publicación anterior,De Apache Airflow® a Lakeflow: Orquestación centrada en datos, la orquestación se replanteó en torno a los datos y el lakehouse en lugar de los programadores externos. Esta publicación se basa en esa base y se centra en los detalles de ejecución para los equipos que ya ejecutan Airflow en producción y desean migrar al orquestador nativo de Databricks, Lakeflow Jobs.
Esta guía está escrita tanto para profesionales que migran desde Airflow como para agentes de programación que generan flujos de trabajo de Lakeflow Jobs. El objetivo es mostrar cómo se pueden expresar esos mismos flujos de trabajo de forma natural cuando la orquestación forma parte del propio lakehouse dentro de Databricks.
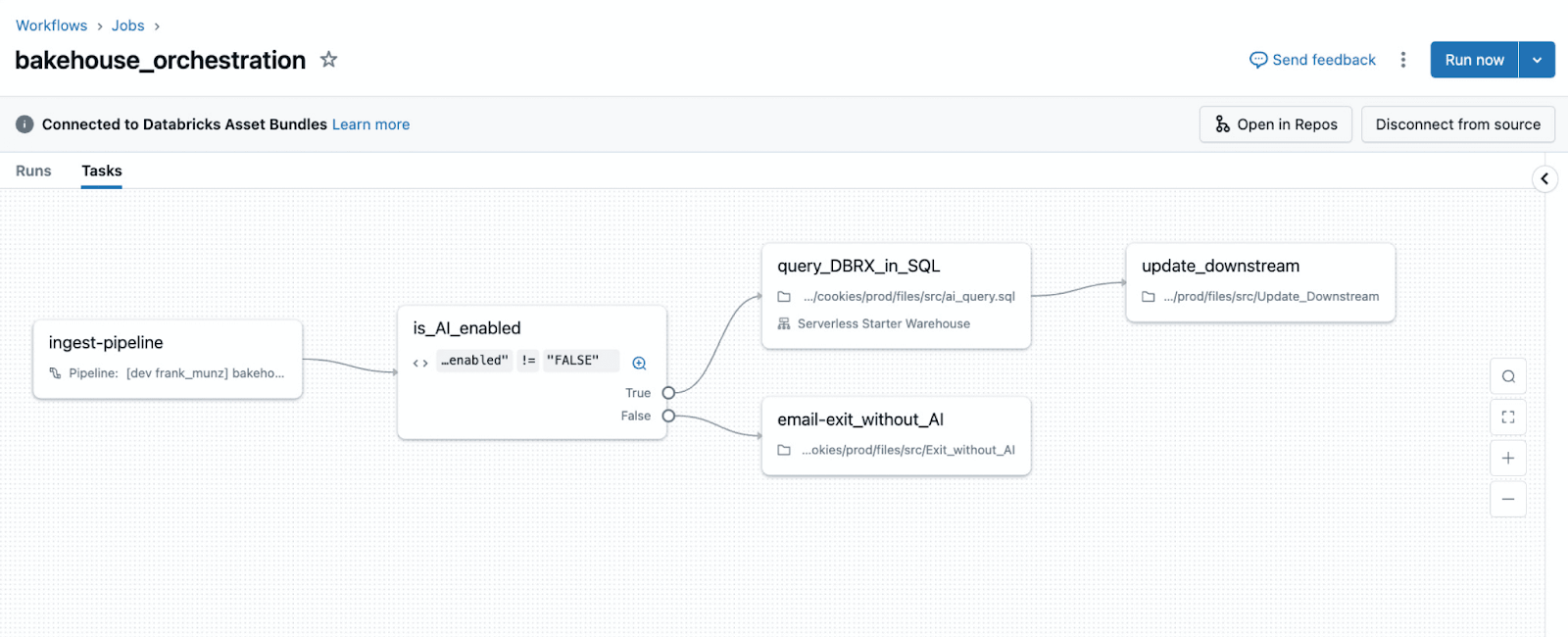
Mapa de migración de Airflow a Lakeflow Jobs
La siguiente tabla resume cómo los patrones comunes de orquestación de Airflow se traducen a Lakeflow Jobs y si la migración es una traducción directa o una refactorización conceptual.
Patrón de Airflow | Uso principal | Equivalente en Lakeflow Jobs | Guía de migración |
XComs | Pasar metadatos de control pequeños entre tareas | Usar valores de tarea para metadatos pequeños; mover cualquier dato real a tablas de Unity Catalog | |
Sensores | Esperar archivos o condiciones | Desencadenadores de llegada de archivos / desencadenadores de actualización de tablas | Reemplazar sensores de sondeo con desencadenadores integrados |
Backfills | Volver a ejecutar para fechas históricas | Trabajos backfills + parámetros | Tratar el tiempo como datos, usar backfills parametrizados |
Branching | Ejecución condicional de tareas | Tareas de condición (if/else) (if/else) | Reemplazar task.branch con tareas If-Else |
Mapeo dinámico de tareas | Fan-out en tiempo de ejecución | Tareas For-each | Usar for-each cuando el número de tareas depende de los datos en tiempo de ejecución |
Estrategia de migración: incremental, no todo a la vez
La mayoría de los equipos migran incrementalmente en lugar de reemplazar Airflow por completo. Los enfoques comunes incluyen:
- Comenzar con flujos de trabajo autocontenidos o impulsados por eventos
- Migrar la llegada de archivos y los desencadenadores basados en datos de forma temprana
- Mantener las canalizaciones estables de Airflow sin cambios inicialmente
- Evitar reescrituras de trabajos maduros y de bajo riesgo
Lakeflow Jobs está diseñado para coexistir durante la migración y para asumir responsabilidades de orquestación donde agrega el mayor valor.
Lista de verificación
XComs con metadatos pequeños → valores de tarea; XComs con datos → tablas o volúmenes de Unity Catalog.
- Sensores/activos de archivos → desencadenadores de llegada de archivos o actualización de tablas donde los datos están en UC.
Macros de fecha de ejecución (
ds, etc.) → parámetros explícitos + ejecuciones de backfill.Branching (
@task.branch) → tareas de condición.Mapeo dinámico de tareas → tareas for-each donde el fan-out está basado en datos.
(Opcional) Trabajos y esquemas administrados a través de Python Asset Bundles para entornos consistentes.
Descripción general de Lakeflow Jobs
Al migrar desde Airflow, es útil interiorizar algunas suposiciones centrales que dan forma a cómo funciona Lakeflow Jobs:
Plano de control vs plano de datos
Las operaciones en el plano de datos (consultas, lecturas, escrituras y transformaciones) impulsan el uso de cómputo. Las operaciones del plano de control, como desencadenadores, valores de tarea y parámetros, no lo hacen.
Los trabajos son la unidad de orquestación
- Los trabajos encapsulan tareas y dependencias; la coordinación entre trabajos típicamente usa datos (tablas, archivos), no señales entre DAGs
- Esto cambia los diseños de “DAG hablando con DAG” a “el productor escribe una tabla, el trabajo consumidor se activa cuando esa tabla cambia”.
- Existe una tarea Run Job para casos en los que la invocación de trabajo a trabajo es intencional, pero complementa en lugar de reemplazar el modelo de coordinación basado en datos.
Los desencadenadores son de primera clase
- Los desencadenadores de llegada de archivos y actualización de tablas son características integradas, no implementadas a través de sensores de ejecución prolongada.
- Esto cambia la orquestación de sondeo a basada en eventos por defecto.
Estas suposiciones explican por qué algunos patrones de Airflow se traducen directamente, mientras que otros se simplifican o reemplazan intencionalmente.
Pasos de migración
1. XComs a valores de tarea para control, tablas para datos
Airflow: XComs para metadatos de control pequeños
En Apache Airflow, se utilizan XComs para pasar pequeños fragmentos de metadatos entre tareas dentro de una ejecución de DAG. Un ejemplo mínimo de Airflow que pasa un valor pequeño entre tareas:
Esto funciona bien para identificadores pequeños, valores, indicadores y recuentos, pero se vuelve difícil de razonar cuando muchas tareas dependen de XComs o cuando se envían cargas útiles grandes.
Lakeflow: valores de tarea para control, tablas para datos
En Lakeflow Jobs, los valores de tarea desempeñan la función de XCom para metadatos de control. Los trabajos y las tareas generalmente se definen a través de paquetes de activos, y sus implementaciones residen en notebooks o archivos de Python. Fragmento de paquete (Python) que define dos tareas y una dependencia:
Notebook del productor:
Notebook del consumidor:
Los valores de las tareas son visibles en la interfaz de usuario de trabajos de Lakeflow por ejecución y se limitan a cargas útiles pequeñas, lo que los hace ideales para indicadores, contadores e identificadores. Para objetos más grandes o salidas reutilizables, las tareas deben escribir en tablas o vistas de Unity Catalog:
💡 Regla general: Use los valores de las tareas solo para metadatos de control; coloque cualquier cosa que parezca datos en tablas, vistas o volúmenes.
Consejos de migración
- XComs simples → valores de tareas.
- XComs que transportan dataframes o JSON grandes → leer/escribir en Unity Catalog en su lugar.
- Evite reproducir DAGs con muchos XComs; apóyese en el lakehouse como estado compartido.
2. Sensores y activos a disparadores de archivos y tablas
Airflow: sensores de archivos y activos
Patrón típico de Airflow para un pipeline impulsado por archivos:
Esto mantiene ocupado un slot de trabajador encuestando y a menudo se combina con el seguimiento de activos personalizados cuando varios consumidores dependen de los mismos datos.
Lakeflow: disparadores de llegada de archivos
Fragmento que muestra un disparador de llegada de archivos
Implementación del notebook
La plataforma maneja el estado del disparador, el debounce y el cooldown, y ya no necesita sensores de larga duración ni planificadores externos para monitorear archivos.
Lakeflow: disparadores de actualización de tablas (programación estilo activo)
Cuando los productores escriben en tablas de Unity Catalog, los consumidores pueden activarse ante las actualizaciones de tablas en lugar de las programaciones basadas en el tiempo.
💡Regla general: Active trabajos ante la llegada de archivos o actualizaciones de tablas siempre que sea posible; use programaciones solo cuando realmente las necesite.
Consejos de migración
- Sensores de archivos → disparadores de llegada de archivos en ubicaciones o volúmenes de UC.
- Registros de activos → tablas de Unity Catalog con disparadores de actualización de tablas.
- Eventos que no son de datos → disparadores o parámetros externos explícitos.
3. Fechas de ejecución a parámetros y ejecuciones de backfill
Airflow: fecha de ejecución y ds
Airflow fomenta la lógica de plantillas con fechas de ejecución:
Las ejecuciones de backfill son impulsadas por el planificador de Airflow y las fechas de ejecución; la lógica depende implícitamente del concepto de tiempo del planificador.
Lakeflow: parámetros explícitos y backfill
En Lakeflow Jobs, la “fecha de ejecución lógica” debe modelarse como un parámetro. Definición de trabajo (bundles) con un parámetro:
Nota: también puede usar {{ job.trigger.time.iso_date }} si desea usar el estilo de Airflow {{ds}} o {{ execution_date }} en lugar de datos codificados en el ejemplo anterior.
SQL usa el parámetro:
Para hacer backfill, define un conjunto de valores de parámetros y ejecuta backfills sobre ellos en la UI o a través de la API, en lugar de depender de la captura implícita del planificador. Los parámetros se definen una vez y se anulan en tiempo de ejecución al activar una ejecución de backfill
💡Regla general: Trate el tiempo como datos; modélalo como un parámetro, páselo explícitamente a las tareas y controle los backfills a través de rangos de parámetros.
Consejos de migración
- Reemplace
{{ ds }}y macros relacionadas con parámetros (por ejemplo, :run_date). - Haga que las tareas sean idempotentes para un conjunto de parámetros dado, de modo que los backfills permanezcan seguros.
- Use ejecuciones de backfill de Lakeflow en lugar de recrear la lógica de captura impulsada por el planificador.
4. Ramificación y mapeo dinámico a tareas de condición y for-each
Airflow: ramificación y mapeo dinámico de tareas
Ramificación con @task.branch:
Mapeo dinámico de tareas para fan-out en tiempo de ejecución usando expand():
Lakeflow: tareas de condición
Lakeflow Jobs utiliza tareas de condición para ramificación basada en datos
El notebook check_quality emite un valor de tarea:
El grafo muestra la ramificación explícitamente, y la lógica de decisión se expresa a través de datos (valores de tarea) en lugar de flujo de control de Python incrustado.
💡Regla general: Usa tareas de condición cuando una expresión booleana sobre parámetros o valores de tarea determine la ruta.
Lakeflow: tareas for‑each para fan‑out en tiempo de ejecución
Las tareas For‑each implementan fan‑out cuando el número de tareas depende de datos en tiempo de ejecución.
El notebook generate_items:
El notebook process_item ve el elemento actual como {{input}} (o la variable de tiempo de ejecución equivalente según el wrapper del lenguaje).
💡Regla general: Usa for‑each cuando el fan‑out es impulsado por datos en tiempo de ejecución; mantén las tareas estáticas cuando el fan‑out se fija en el momento del diseño.
Consejos de migración
@task.branch→ tareas de condición que usan valores de tarea o parámetros.- Mapeo dinámico de tareas → tareas for‑each impulsadas por valores de tarea o tablas.
- Metadatos de iteración grandes → tablas/volúmenes; IDs/índices pequeños → valores de tarea.
5. (Opcional) Generación programática con Python Asset Bundles
Muchas implementaciones de Airflow generan DAGs dinámicamente (un DAG por tabla o archivo SQL) y gestionan las diferencias del entorno a través de convenciones y scripts. Python Asset Bundles ofrece una forma estructurada de generar trabajos y recursos relacionados de forma programática.
Ejemplo: un trabajo por archivo SQL:
Puedes combinar esto con mutadores para ajustar notificaciones, identidades de ejecución o reintentos por entorno, centralizando los estándares mientras mantienes las definiciones de trabajos en Python.
💡 Regla general: Usa la generación programática para codificar las convenciones de la plataforma, no para ocultar hacks puntuales.
Próximos pasos
Si estás ejecutando Airflow hoy en día, elige un DAG que dependa de sensores, XComs o mapeo dinámico de tareas y reiméntalo usando un disparador, una tarea for‑each y parámetros explícitos. Esto suele ser suficiente para interiorizar el modelo mental de Lakeflow Jobs.
Clona y ejecuta los ejemplos completos y funcionales utilizados en esta guía
Aprende más sobre orquestación data-first
Explora la documentación de Lakeflow Jobs
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.