Cómo Zalando construyó una base de datos unificada para IA y análisis en Databricks
Zalando separa la creación de datos del consumo, estandariza las definiciones de métricas y permite consultas fiables en lenguaje natural en dashboards e IA.
por Fabian Halkivaha, Mukrram Ur Rahman, Maria Vedenina y Timur Yüre
- Zalando construyó una base de datos unificada en Databricks con Unity Catalog, Metric Views y Genie para gobernar datos, estandarizar métricas y habilitar análisis en lenguaje natural.
- Centralizaron la lógica de negocio utilizando Metric Views ("métricas como código"), resolviendo definiciones de métricas inconsistentes en dashboards, SQL y pipelines.
- Al basar Genie en esta capa semántica, Zalando ofrece consultas fiables en lenguaje natural, reduciendo el tiempo de respuesta a nuevas preguntas y mejorando la confianza en los resultados.
En Zalando, una plataforma en línea líder en Europa para moda y estilo de vida, orquestamos un ecosistema digital masivo que conecta a más de 50 millones de clientes activos con más de 7.000 marcas y socios en toda Europa. Cada interacción del cliente (navegación, pedido, devolución, etc.) genera un pulso de datos que impulsa nuestra toma de decisiones, desde recomendaciones personalizadas hasta la optimización logística.
Operar a esta escala conlleva un conjunto único de desafíos. Nuestro panorama de datos es vasto y complejo, alimentado por una arquitectura de microservicios que transmite terabytes de eventos a nuestro lago de datos central. Si bien esta arquitectura nos permitió escalar rápidamente, también hizo que la gobernanza fuera un desafío y difuminó la distinción entre Datos Transaccionales (operaciones comerciales diarias) y Datos Analíticos (información para la toma de decisiones).
Durante años, nos esforzamos por un enfoque distribuido para resolver esto descentralizando la propiedad, para que los equipos de dominio (como "Pagos" o "Logística") pudieran administrar sus propios productos de datos. Una estructura de gobernanza centralizada es crucial en esta configuración para garantizar una carga manejable para los equipos y prevenir riesgos comerciales. Además, sin una capa unificada para definir la verdad, nos enfrentamos al desafío de la divergencia de métricas: ¿Por qué el panel de Marketing muestra un "Ingreso Neto" diferente al del informe de Finanzas? Dado que las métricas viven en silos, es difícil gobernarlas y garantizar que sean descubribles y confiables para su reutilización durante todo su ciclo de vida.
En esta publicación, compartiremos cómo Zalando está logrando esto aprovechando toda la amplitud de la Plataforma Databricks. Profundizaremos en cómo estamos construyendo una Capa Semántica Unificada que cierra la brecha entre Datos Transaccionales y Datos Analíticos. Específicamente, cubriremos:
- La Base: Cómo Unity Catalog habilita la gobernanza federada y el intercambio seguro entre cientos de equipos.
- La Capa Semántica: Cómo Unity Catalog Business Semantics, impulsado por Metric Views, nos permite definir la lógica de negocio una vez y servirla en todas partes.
- La Analítica Potenciada por IA Conversacional: Cómo aprovechamos la capa semántica a través de Genie, una interfaz impulsada por IA generativa que permite a los usuarios consultar datos usando lenguaje natural sin necesidad de experiencia en SQL, ayudándonos a tomar decisiones más rápidas y basadas en datos.
La Base – Democratizando la Gobernanza con Unity Catalog
Para administrar nuestro vasto panorama de datos de manera efectiva, decidimos alejarnos del control de acceso centrado en los recursos. En ese modelo, cada nuevo conjunto de datos o consumidor requería roles IAM personalizados, políticas de bucket S3 y manejo de excepciones. Pero identificamos desafíos: los permisos estaban fragmentados en miles de recursos, eran engorrosos de revisar y propensos a la deriva. Por lo tanto, cambiamos a un enfoque de gobernanza basado en identidad. Las decisiones de acceso se expresan como políticas reutilizables vinculadas a personas y grupos. Se evalúan de manera consistente en todos los conjuntos de datos y se aplican centralmente. Esto hace que el acceso sea más fácil de operar, auditar y evolucionar a medida que cambian los equipos y los datos. Construimos esta base utilizando Databricks Unity Catalog e implementamos un marco de control de acceso federado encima.
La Arquitectura
Diseñamos un patrón de doble catálogo que separa estrictamente la creación de datos de su consumo, asegurando que la agilidad no se produzca a costa del control:
- Catálogos Privados para Autonomía: Cada equipo de dominio crea su propio Catálogo Privado utilizando una solución interna de autoservicio. Dentro de este entorno privado, el equipo puede crear esquemas, ingerir datos sin procesar y construir tablas a su propio ritmo sin esperar la aprobación central. Esto sirve como su "fábrica", optimizada para el desarrollo y la iteración sin restricciones. La única limitación que enfrentan es que todos los objetos creados aquí son accesibles únicamente por el propio equipo, más un número limitado de colaboradores relacionados. Esto significa que los casos de uso construidos sobre estos catálogos no están destinados al uso en toda la empresa.
- El Catálogo Compartido Central para Gobernanza: Para casos de uso en los que varios equipos de toda la empresa necesitan utilizar estos conjuntos de datos, introdujimos un catálogo compartido central. Esto actúa como la "sala de exposición" de toda la empresa. Todos los datos compartidos en la organización deben exponerse aquí a través de Vistas Dinámicas, donde caen bajo una estricta gobernanza central. En el momento en que los datos llegan aquí, son instantáneamente descubribles a través de Unity Catalog.
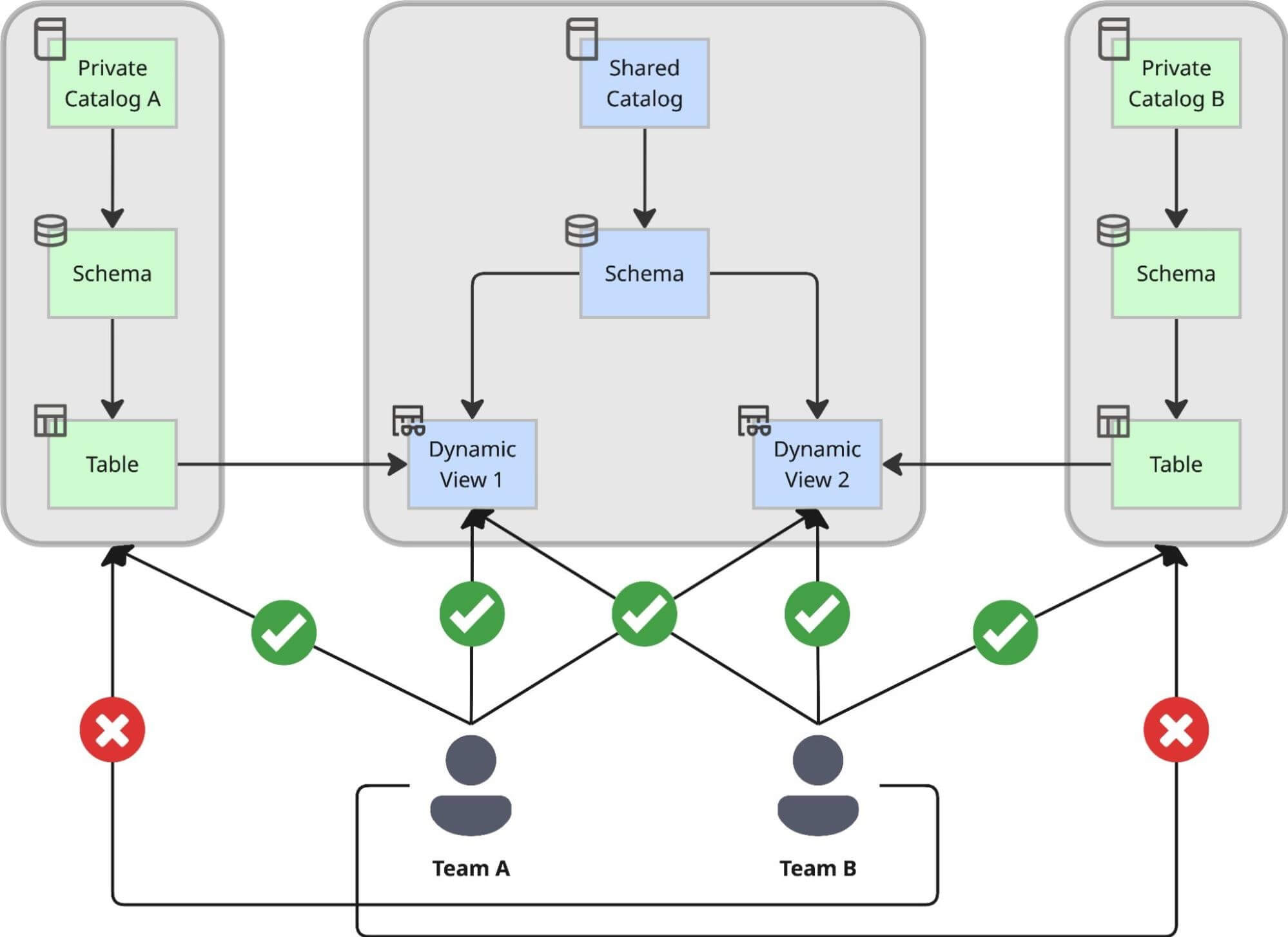
¿Por qué Vistas Dinámicas? Control Centralizado y Auditabilidad
Tomamos la decisión estratégica de exponer los datos en el catálogo compartido exclusivamente a través de Vistas Dinámicas, en lugar de punteros de tabla directos. Este enfoque nos permite aplicar un proceso de acceso centralizado capaz de manejar reglas de cumplimiento complejas.
Al utilizar Vistas Dinámicas como capa de servicio, logramos:
- Reglas de Proceso Personalizadas para GDPR: Inyectamos lógica personalizada directamente en la definición de la vista utilizando funciones como is_account_group_member(). Esto garantiza un control de acceso robusto al verificar si los usuarios cumplen con los requisitos antimonopolio y están autorizados a acceder a datos confidenciales (como el email).
- Acceso Interno por Defecto y Conforme: Debido a un proceso de clasificación automatizado, cada columna se clasifica. Todas las columnas no confidenciales son accesibles para una amplia variedad de usuarios por defecto, lo que acelera la democratización de datos y la toma de decisiones.
- Auditabilidad Completa: Dado que todo el acceso entre equipos fluye a través de estas vistas gestionadas centralmente, mantenemos un registro de auditoría completo de las decisiones de acceso. Sabemos exactamente qué política otorgó a un usuario acceso a una fila o columna específica.
- Información Confiable: Para evitar la generación de datos incorrectos o números engañosos debido a agregaciones parciales, cualquier consulta que intente acceder a una columna confidencial sin la autorización específica necesaria fallará explícitamente con un error de permiso denegado.
Gobernanza como Código: El Flujo de Trabajo de Compartición
Para mantener este proceso eficiente, automatizamos el flujo de trabajo de compartición utilizando un enfoque GitOps:
- Pull Request para Compartir: Cuando un equipo está listo para compartir un conjunto de datos de su catálogo privado al catálogo compartido, no presenta una solicitud. Abren una Pull Request (PR) en un repositorio central con un archivo de configuración que apunta a su tabla de origen.
- Reglas de Aprobación: La Pull Request se verifica en busca de criterios de compartición, unicidad y otros factores de decisión importantes.
- Validación y Aprovisionamiento Automatizados: Una vez que la PR es aprobada y fusionada, nuestro servicio de plataforma genera automáticamente la Vista Dinámica correspondiente en el catálogo compartido central y clasifica automáticamente las columnas.
Esta configuración nos permite mantener la agilidad de los equipos distribuidos mientras aplicamos un estándar de gobernanza centralizado y totalmente auditable que mantiene nuestros datos fácilmente descubribles, seguros y conformes.
La Capa Semántica – Definiendo "La Verdad" con Metric Views
Con la base segura que establecimos para acceder a los datos, ahora nos enfocamos en garantizar una interpretación consistente de los datos.
Estamos centralizando activamente la lógica de negocio que anteriormente estaba fragmentada en la pila de datos:
- Herramientas de BI: Definiciones de métricas incrustadas en paneles individuales
- Scripts SQL: Lógica duplicada en cuadernos y canalizaciones
- Tablas Materializadas: Métricas precalculadas vinculadas a casos de uso específicos
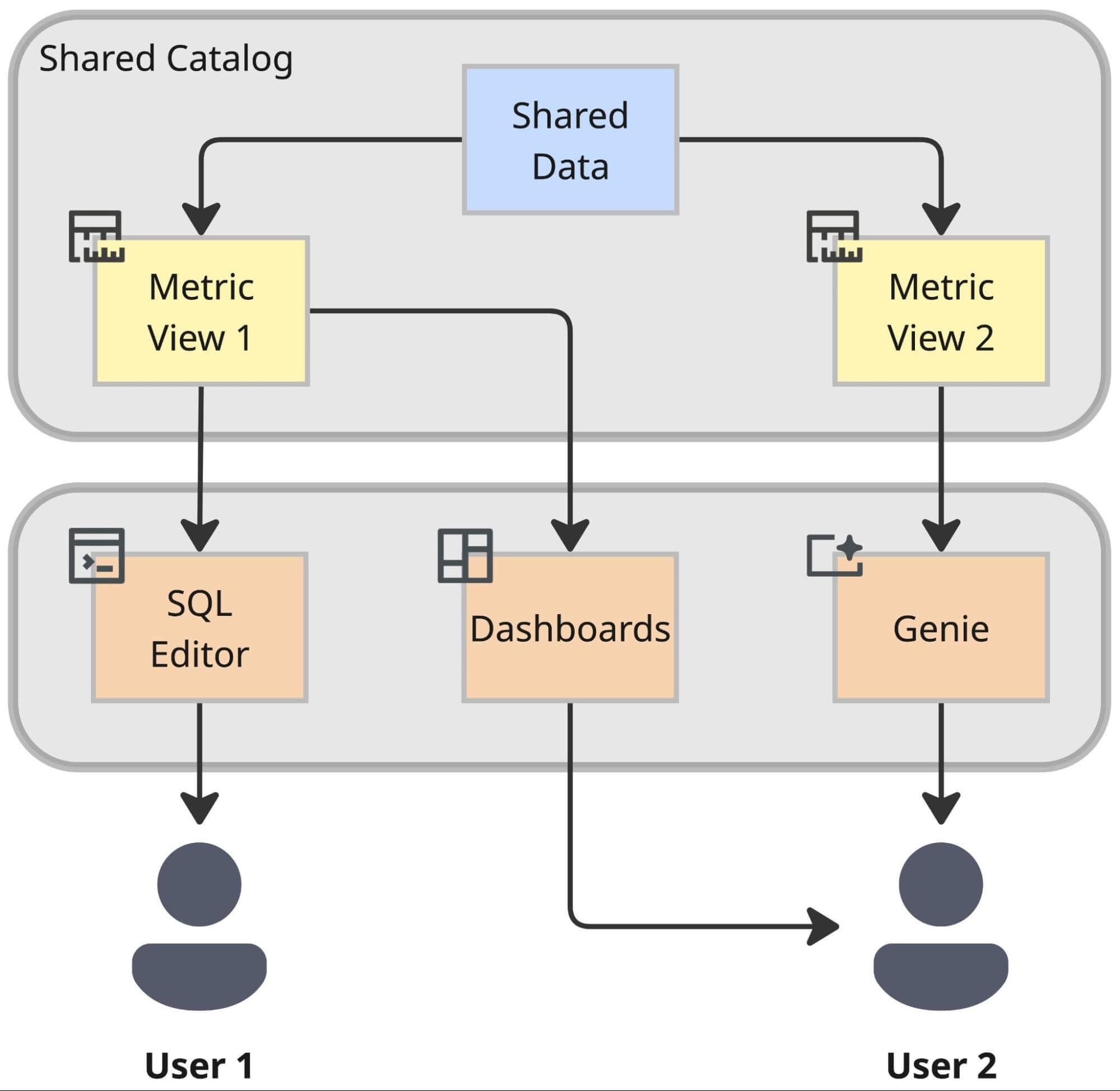
Estamos unificando miles de definiciones de métricas en una única capa gobernada. Esto nos permite romper el "bloqueo de lógica": la definición de "Valor Bruto de Mercancía" (NMV) en una herramienta de panel se vuelve totalmente accesible para un científico de datos que trabaja en un cuaderno o para un bot de IA que responde a la pregunta de un usuario.
Para lograr esto, estamos adoptando Databricks Metric Views como nuestra capa semántica unificada. Esto desacopla decisivamente la definición de una métrica de su consumo, garantizando que los usuarios reciban el mismo resultado calculado ya sea que consulten a través de un editor SQL, un panel o un agente de IA. En la práctica, esto asegura que tanto los usuarios técnicos como los no técnicos utilicen las mismas definiciones de métricas.
Métrica como Código: El Ciclo de Vida de la Métrica
Implementamos un riguroso enfoque de "Métrica como Código" para nuestra capa semántica, al igual que utilizamos GitOps para compartir datos en Unity Catalog. Aseguramos la consistencia entre todos los equipos centralizando y estandarizando cada definición de KPI.
Nuestra arquitectura gestiona el ciclo de vida completo de una métrica:
- Definición en YAML: Las métricas se definen en código (archivos YAML) almacenados en un repositorio central. Esto captura no solo la lógica de agregación (por ejemplo, SUM(amount)) y las relaciones entre tablas, hechos y métricas, sino también metadatos críticos como propiedad, descripción y formato.
- Validación Automatizada: Antes de que una métrica pueda ser fusionada en producción, nuestro pipeline de CI/CD ejecuta un conjunto de verificaciones automatizadas. Estas incluyen:
- Unicidad: Asegurar que no exista ya una métrica con el mismo nombre o definición.
- Conformidad: Aplicar convenciones de nomenclatura (por ejemplo, snake_case) para garantizar la descubribilidad.
- Propiedad: Verificar que un ID de equipo válido esté adjunto a la métrica para la rendición de cuentas.
- Humano en el bucle: A través de el principio de las 4 ojos, cada Solicitud de Extracción es revisada por expertos del dominio.
- Entornos de Desarrollo Individuales: Para permitir que los equipos iteren rápidamente mientras prueban en un entorno muy cercano a producción, cada Solicitud de Extracción implementa las Metric Views en un entorno de prueba separado. Esta configuración hace posible verificar las implicaciones del cambio de inmediato.
Construyendo un Esquema de Estrella para el Lakehouse
En el fondo, confiamos en principios establecidos de modelado dimensional. Cada Metric View en nuestro entorno de producción actúa como una interfaz estándar, típicamente mapeando 1 a 1 con nuestras tablas de Hechos mientras hereda atributos de tablas de Dimensión conformadas.
Esta configuración es crucial para nuestra escala. Al exigir que las Metric Views se construyan sobre los datos confiables en nuestro Catálogo Compartido (de la Sección 1), aseguramos que la capa semántica herede todos los beneficios de seguridad y cumplimiento de la plataforma subyacente. Un usuario que consulta una vista de métricas todavía está sujeto a la misma seguridad a nivel de fila y columna, y a las reglas de acceso que definimos en la capa de Unity Catalog. También mejoraremos esta configuración más adelante este año con una capa de autorización adicional a través de las Metric Views, para que los usuarios ya no necesiten acceso a datos brutos, sino solo acceso a nivel de métrica y dimensión.
El Resultado: Interoperabilidad
La recompensa de esta arquitectura es la interoperabilidad. Al sacar la lógica de negocio de las herramientas de BI propietarias y llevarla a la capa semántica del Lakehouse, nos preparamos para el futuro. Una métrica definida una vez en esta capa se vuelve instantáneamente disponible para:
- Databricks Dashboards para informes estándar.
- Genie para análisis impulsados por IA en una interfaz conversacional utilizando lenguaje natural.
- Herramientas y Aplicaciones Externas a través de conectores estandarizados.
Esta centralización es la clave para nuestro próximo gran paso: capacitar al negocio para que "hable" con sus datos.
Análisis Conversacional Impulsado por IA
Los paneles son esenciales para responder preguntas cotidianas y recurrentes. Sin embargo, la velocidad del negocio a menudo supera la capacidad de los informes estándar para capturar todo. Por ejemplo, un Gerente de Categoría podría necesitar saber: "*¿Qué marcas de zapatillas tuvieron una alta tasa de clics pero no entraron en el top 10 por número de artículos vendidos en Alemania la semana pasada?*" Responder preguntas novedosas como esta, no abordadas por los informes estándar existentes, frecuentemente requería la construcción de un nuevo panel. Incluso con herramientas de autoservicio, persistía un lapso significativo en el "tiempo hasta la información". Los usuarios tenían que encontrar el conjunto de datos correcto, configurar widgets y aplicar filtros antes de poder obtener una respuesta. Esto a menudo resultaba en paneles de un solo uso, contribuyendo a la proliferación de paneles y a la reducción de la descubribilidad.
Para optimizar la experiencia del usuario, evaluamos varias soluciones de "Hablar con los Datos" que ofrecen interfaces conversacionales impulsadas por LLM, a menudo denominadas chatbots de IA. Genie tuvo el mejor rendimiento porque está anclado en una capa semántica unificada, mientras que las soluciones sin esta capa lucharon para generar SQL preciso para una lógica de negocio compleja.
Es por eso que la introducción de Metric Views resultó instrumental para el análisis conversacional impulsado por IA como Genie. Al dirigir Genie hacia las Metric Views preestablecidas (como se detalla en la Sección 2), logramos un avance crítico: respuestas consistentes y confiables basadas en definiciones de negocio gobernadas.
Por qué Metric Views aumenta drásticamente la precisión de la IA
La mayor barrera para adoptar IA en análisis es la confianza. Si un LLM genera una consulta SQL errónea, los números serán incorrectos y los usuarios perderán la fe.
Genie resuelve esto trabajando con nuestra capa semántica en Metric Views.
- Sin Adivinanzas: Cuando un usuario solicita "NMV" (Valor Neto de Mercancía), Genie no intenta calcularlo a partir de tablas brutas. Reconoce "NMV" como una métrica gobernada en nuestra vista de métricas y simplemente consulta la lógica predefinida. Por lo tanto, la vista de métricas reduce la complejidad de generar una declaración SQL, lo que lleva a una mayor precisión.
- Consciente del Contexto: Invertimos mucho en enriquecer nuestros metadatos de Unity Catalog, agregando descripciones, sinónimos y consultas de ejemplo. Genie utiliza este contexto para comprender que cuando un usuario dice "Cancelaciones", se refiere específicamente a pedidos cancelados antes del envío, coincidiendo con nuestra definición interna.
Empoderando a la Primera Línea
Probamos Genie con equipos no técnicos, como Merchandisers, Compradores y Analistas de Precios, que históricamente habían dependido de exportaciones de Excel o herramientas de BI. La retroalimentación fue inmediata: los usuarios podían obtener respuestas rápidas a preguntas granulares (por ejemplo, rendimiento específico del mercado emparejado con un tipo de dispositivo específico) sin necesidad de conocer una sola línea de SQL o pasar tiempo creando una vista de informe personalizada.
La introducción del nuevo Modo Agente ha mejorado significativamente la experiencia del usuario. El Modo Agente analiza automáticamente los datos para identificar la causa raíz de los resultados del análisis, permitiendo a los usuarios simplemente preguntar "por qué" sucedió algo. En Zalando, esto podría reducir el tiempo de preparación para nuestras reuniones de rendimiento regulares, donde se toman decisiones de dirección críticas, de varias horas a solo unos minutos.
Sin embargo, con su extensa funcionalidad, Genie también puede resultar caro si no se configura correctamente, por ejemplo, en tablas y vistas no agregadas. Por eso es fundamental curar cuidadosamente los datos y el contexto que utiliza Genie. Además, reconocemos el potencial de mejora, como el beneficio de introducir el control de versiones completo de Genie y permitir actualizaciones programáticas de las configuraciones de Genie, en lo que Databricks ya está trabajando y que actualmente ya está parcialmente soportado.Escalar Genie para la Adopción Empresarial
No estamos tratando a Genie como un experimento de sandbox; lo estamos integrando en nuestras operaciones empresariales. Nuestras áreas de enfoque para la escalabilidad incluyen:
- Establecer Gobernanza: Los espacios curados de Genie se basarán en Metric Views gobernadas y mantenidas adecuadamente.
- Garantizar la Fiabilidad de los Datos: Estamos colaborando con los equipos propietarios de los datos para establecer espacios curados de Genie. Estos espacios ofrecerán representaciones analíticas de sus datos a través de Metric Views, asegurando que la calidad de los datos sea mantenida por los propios propietarios de los datos.
- Integración con Agent Bricks o uso de Genies en Databricks One: Planeamos orquestar estos espacios curados de Genie utilizando Agent Bricks o utilizando Genies dentro de Databricks One. Este enfoque garantiza que los usuarios tengan un punto de entrada único y unificado para todas sus consultas de datos.
Al combinar la gobernanza de Unity Catalog, la estandarización de la lógica de negocio a través de Metric Views y la inteligencia de Genie, estamos construyendo una cultura de datos donde "preguntar a los datos" es tan fácil como preguntar a un colega.
Gracias a Merve Karali, Tobias Efinger, y Roberto Bruno Martins por contribuir a esta publicación.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.