Mejora de la recuperación y RAG con el ajuste fino de modelos de incrustación
por Jacob Portes, Andrew Drozdov, Erica Ji Yuen, Vincent Chen, Sean Kulinski, Milo Cress, Colton Peltier, Sam Havens, Michael Carbin, Vitaliy Chiley y Connor Jennings
- Cómo el ajuste fino de modelos de incrustación mejora la recuperación y la precisión de RAG
- Ganancias clave de rendimiento en benchmarks
- Cómo empezar con el ajuste fino de incrustaciones en Databricks
Ajuste Fino de Modelos de Embeddings para Mejor Recuperación y RAG
En resumen: Ajustar finamente un modelo de embeddings con datos específicos del dominio puede mejorar significativamente la precisión de la búsqueda vectorial y la generación aumentada por recuperación (RAG). Con Databricks, es fácil ajustar finamente, desplegar y evaluar modelos de embeddings para optimizar la recuperación para tu caso de uso específico, aprovechando datos sintéticos sin etiquetado manual.
Por qué es importante: Si tu sistema de búsqueda vectorial o RAG no está recuperando los mejores resultados, ajustar finamente un modelo de embeddings es una forma sencilla pero potente de mejorar el rendimiento. Ya sea que estés trabajando con documentos financieros, bases de conocimiento o documentación de código interna, el ajuste fino puede proporcionarte resultados de búsqueda más relevantes y mejores respuestas posteriores del LLM.
Lo que encontramos: Ajustamos finamente y probamos dos modelos de embeddings en tres conjuntos de datos empresariales y vimos mejoras importantes en las métricas de recuperación (Recall@10) y en el rendimiento posterior de RAG. Esto significa que el ajuste fino puede ser un punto de inflexión para la precisión sin requerir etiquetado manual, aprovechando solo tus datos existentes.
¿Quieres probar el ajuste fino de embeddings? Proporcionamos una solución de referencia para ayudarte a empezar. Databricks facilita labúsqueda vectorial, RAG, la reordenación y el ajuste fino de embeddings. Ponte en contacto con tu Ejecutivo de Cuentas de Databricks o Arquitecto de Soluciones para obtener más información.
{kind=link}
¿Por qué ajustar finamente los embeddings?
Los modelos de embeddings potencian los sistemas modernos de búsqueda vectorial y RAG. Un modelo de embeddings transforma el texto en vectores, lo que permite encontrar contenido relevante basándose en el significado y no solo en palabras clave. Sin embargo, los modelos preexistentes no siempre están optimizados para tu dominio específico, ahí es donde entra el ajuste fino.
Ajustar finamente un modelo de embeddings con datos específicos del dominio ayuda de varias maneras:
- Mejora la precisión de la recuperación: Los embeddings personalizados mejoran los resultados de búsqueda al alinearse con tus datos.
- Mejora el rendimiento de RAG: Una mejor recuperación reduce las alucinaciones y permite respuestas de IA generativa más fundamentadas.
- Mejora el costo y la latencia: Un modelo ajustado finamente más pequeño a veces puede superar a alternativas más grandes y costosas.
En esta publicación de blog, mostramos que ajustar finamente un modelo de embeddings es una forma eficaz de mejorar el rendimiento de recuperación y RAG para casos de uso empresariales específicos de tareas.
Resultados: El Ajuste Fino Funciona
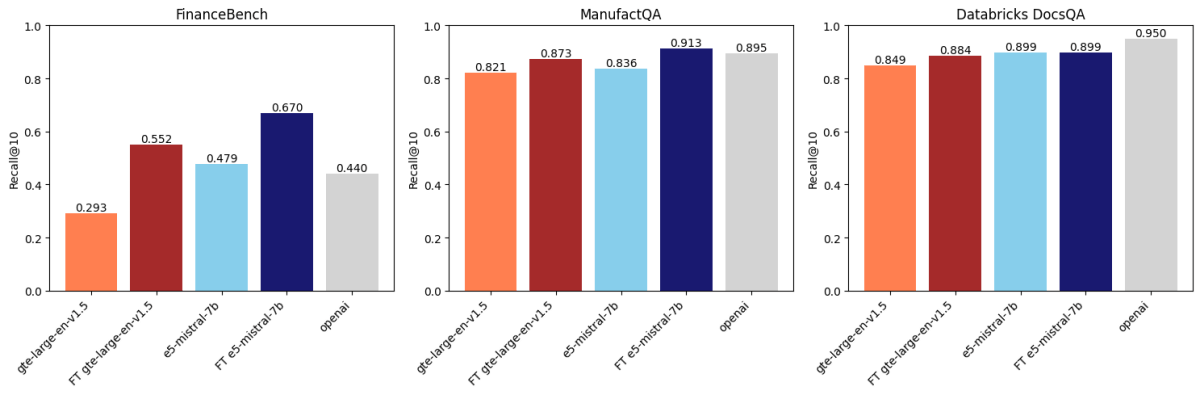
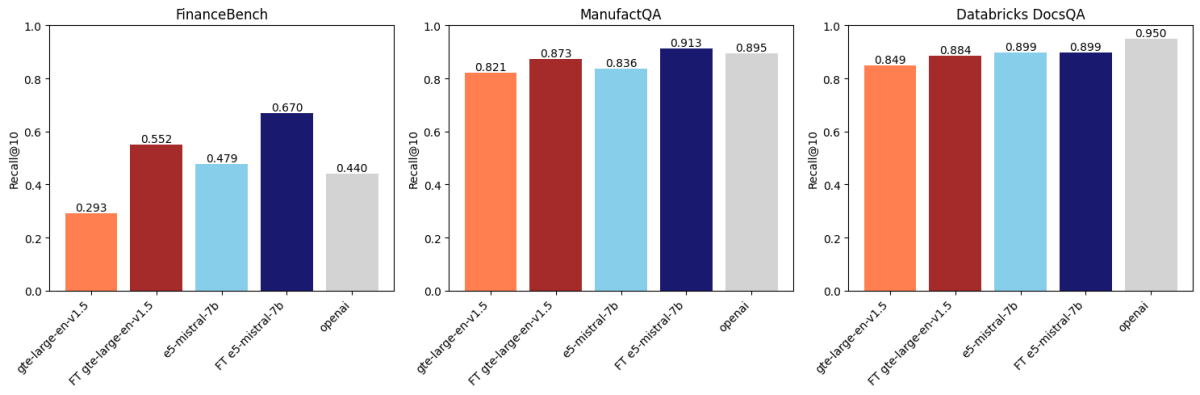
Ajustamos finamente dos modelos de embeddings (gte-large-en-v1.5 y e5-mistral-7b-instruct) con datos sintéticos y los evaluamos en tres conjuntos de datos de nuestro Domain Intelligence Benchmark Suite (DIBS) (FinanceBench, ManufactQA y Databricks DocsQA). Luego los comparamos con el modelo text-embedding-3-large de OpenAI.
Conclusiones clave:
- El ajuste fino mejoró la precisión de la recuperación en todos los conjuntos de datos, superando a menudo significativamente a los modelos base.
- Los embeddings ajustados finamente rindieron igual o mejor que la reordenación en muchos casos, lo que demuestra que pueden ser una solución independiente sólida.
- Una mejor recuperación condujo a un mejor rendimiento de RAG en FinanceBench, demostrando beneficios de extremo a extremo.
Rendimiento de Recuperación
Después de comparar en tres conjuntos de datos, encontramos que el ajuste fino de embeddings mejora la precisión en dos de estos conjuntos de datos. La Figura 1 muestra que para FinanceBench y ManufactQA, los embeddings ajustados finamente superaron a sus versiones base, superando a veces incluso al modelo API de OpenAI (gris claro). Sin embargo, para Databricks DocsQA, la precisión de OpenAI text-embedding-3-large supera a todos los modelos ajustados finamente. Es posible que esto se deba a que el modelo ha sido entrenado con documentación pública de Databricks. Esto demuestra que, si bien el ajuste fino puede ser efectivo, depende en gran medida del conjunto de datos de entrenamiento y de la tarea de evaluación.
Ajuste Fino vs. Reordenación
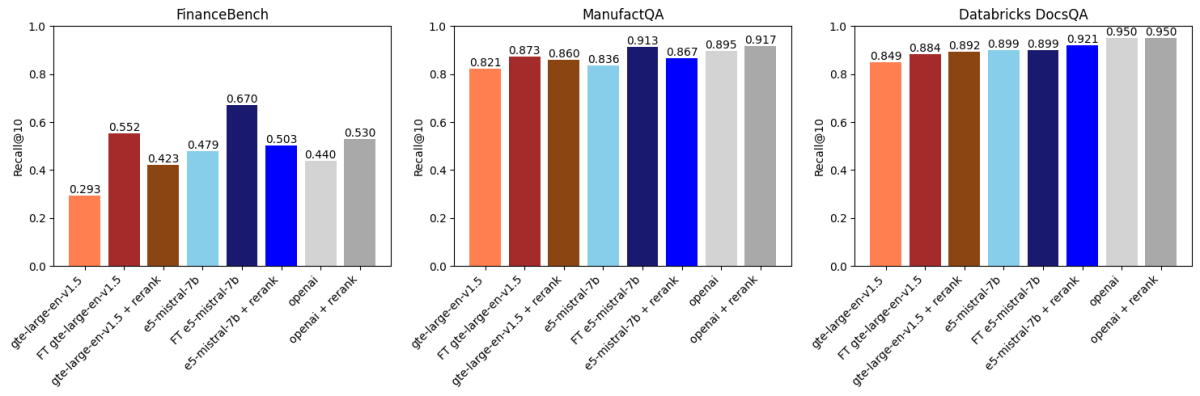
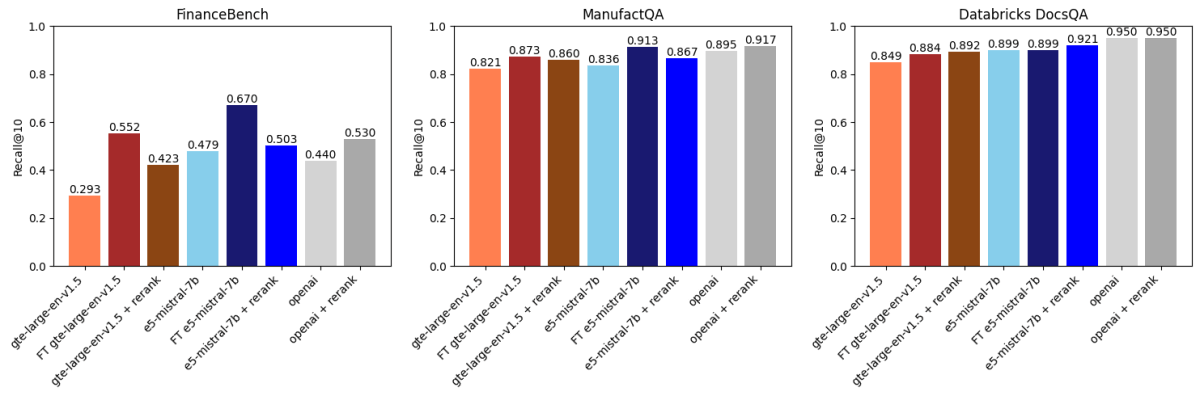
Luego comparamos los resultados anteriores con la reordenación basada en API utilizando voyageai/rerank-1 (Figura 2). Un reordenador normalmente toma los k mejores resultados recuperados por un modelo de embeddings, reordena estos resultados por relevancia a la consulta de búsqueda y luego devuelve los k mejores reordenados (en nuestro caso, k=30 seguido de k=10). Esto funciona porque los reordenadores suelen ser modelos más grandes y potentes que los modelos de embeddings, y también modelan la interacción entre la consulta y el documento de una manera más expresiva.
{kind=link}
Lo que encontramos fue:
- El ajuste fino de gte-large-en-v1.5 superó a la reordenación en FinanceBench y ManufactQA.
- El modelo text-embedding-3-large de OpenAI se benefició de la reordenación, pero las mejoras fueron marginales en algunos conjuntos de datos.
- Para Databricks DocsQA, la reordenación tuvo un impacto menor, pero el ajuste fino aún aportó mejoras, lo que demuestra la naturaleza dependiente del conjunto de datos de estos métodos.
Los reordenadores suelen incurrir en latencia e costo de inferencia adicionales por consulta en comparación con los modelos de embeddings. Sin embargo, se pueden usar con bases de datos vectoriales existentes y, en algunos casos, pueden ser más rentables que re-embeber datos con un modelo de embeddings más nuevo. La elección de usar un reordenador depende de tu dominio y de tus requisitos de latencia/costo.
El Ajuste Fino Ayuda al Rendimiento de RAG
Para FinanceBench, una mejor recuperación se tradujo directamente en una mejor precisión de RAG cuando se combinó con GPT-4o (ver Apéndice). Sin embargo, en dominios donde la recuperación ya era sólida, como en Databricks DocsQA, el ajuste fino no aportó mucho, lo que resalta que el ajuste fino funciona mejor cuando la recuperación es un cuello de botella claro.
Cómo Ajustamos Finamente y Evaluamos Modelos de Embeddings
Aquí hay algunos detalles más técnicos sobre nuestra generación de datos sintéticos, ajuste fino y evaluación.
Modelos de Embeddings
Ajustamos finamente dos modelos de embeddings de código abierto:
- gte-large-en-v1.5 es un popular modelo de embeddings basado en BERT Large (434M parámetros, 1.75 GB). Elegimos ejecutar experimentos en este modelo debido a su tamaño modesto y licencia abierta. Este modelo de embeddings también es compatible actualmente con la API de Modelos Fundacionales de Databricks.
- e5-mistral-7b-instruct pertenece a una clase más nueva de modelos de embeddings construidos sobre LLMs potentes (en este caso Mistral-7b-instruct-v0.1). Aunque e5-mistral-7b-instruct es mejor en los benchmarks de embeddings estándar como MTEB y es capaz de manejar prompts más largos y matizados, es mucho más grande que gte-large-en-v1.5 (ya que tiene 7 mil millones de parámetros) y es ligeramente más lento y más caro de servir.
Luego los comparamos con el modelo text-embedding-3-large de OpenAI.
Conjuntos de Datos de Evaluación
Evaluamos todos los modelos en los siguientes conjuntos de datos de nuestro Domain Intelligence Benchmark Suite (DIBS): FinanceBench, ManufactQA y Databricks DocsQA.
| Conjunto de Datos | Descripción | # Consultas | # Corpus |
|---|---|---|---|
| FinanceBench | Preguntas sobre documentos SEC 10-K generadas por expertos humanos. La recuperación se realiza sobre páginas individuales de un superconjunto de 360 presentaciones SEC 10-K. | 150 | 53,399 |
| ManufactQA | Preguntas y respuestas extraídas de foros públicos de un fabricante de dispositivos electrónicos. | 6,787 | 6,787 |
| Databricks DocsQA | Preguntas basadas en la documentación públicamente disponible de Databricks, generadas por expertos de Databricks. | 139 | 7,561 |
Informamos la métrica recall@10 como nuestra métrica principal de recuperación; esta mide si el documento correcto se encuentra entre los 10 documentos recuperados.
El estándar de oro para la calidad del modelo de incrustación es el benchmark MTEB, que incorpora tareas de recuperación como BEIR, así como muchas otras tareas que no son de recuperación. Si bien modelos como gte-large-en-v1.5 y e5-mistral-7b-instruct obtienen buenos resultados en MTEB, teníamos curiosidad por ver cómo se desempeñaban en nuestras tareas empresariales internas.
Datos de Entrenamiento
Entrenamos modelos separados con datos sintéticos adaptados para cada uno de los benchmarks anteriores:
| Conjunto de Entrenamiento | Descripción | # Muestras Únicas |
|---|---|---|
| Synthetic FinanceBench | Consultas generadas a partir de 2,400 documentos SEC 10-K | ~6,000 |
| Synthetic Databricks Docs QA | Consultas generadas a partir de la documentación pública de Databricks. | 8,727 |
| ManufactQA | Consultas generadas a partir de PDFs de fabricación de productos electrónicos | 14,220 |
Para generar el conjunto de entrenamiento para cada dominio, tomamos documentos existentes y generamos consultas de ejemplo basadas en el contenido de cada documento utilizando LLMs como Llama 3 405B. Las consultas sintéticas fueron luego filtradas por calidad por un LLM-como-juez (GPT4o). Las consultas filtradas y sus documentos asociados se utilizaron como pares contrastivos para el ajuste fino. Utilizamos negativos dentro del lote para el entrenamiento contrastivo, pero agregar negativos difíciles podría mejorar aún más el rendimiento (ver Apéndice).
Ajuste de Hiperparámetros
Realizamos barridos en:
- Tasa de aprendizaje, tamaño del lote, temperatura softmax
- Número de épocas (se probaron 1-3 épocas)
- Variaciones de prompt de consulta (por ejemplo, "Query:" frente a prompts basados en instrucciones)
- Estrategia de pooling (pooling medio frente a pooling del último token)
Todo el ajuste fino se realizó utilizando las bibliotecas de código abierto mosaicml/composer, mosaicml/llm-foundry y mosaicml/streaming en la plataforma Databricks.
Cómo Mejorar la Búsqueda Vectorial y RAG en Databricks
El ajuste fino es solo un enfoque para mejorar el rendimiento de la búsqueda vectorial y RAG; enumeramos algunos enfoques adicionales a continuación.
Para una Mejor Recuperación:
- Use un mejor modelo de incrustación: Muchos usuarios trabajan sin saberlo con incrustaciones obsoletas. Simplemente reemplazarlo por un modelo de mayor rendimiento puede generar ganancias inmediatas. Consulte la tabla de clasificación MTEB para ver los modelos principales.
- Pruebe la búsqueda híbrida: Combine incrustaciones densas con búsqueda basada en palabras clave para mejorar la precisión. Databricks AI Search lo hace fácil con una solución de un clic.
- Use un reranker: Un reranker puede refinar los resultados reordenándolos según la relevancia. Databricks proporciona esto como una función integrada (actualmente en Private Preview). Comuníquese con su Gerente de Cuentas para probarlo.
Para un Mejor RAG:
- Optimice sus prompts: Pequeños ajustes en los prompts de LLM pueden mejorar drásticamente las respuestas. DSPy puede ayudar a automatizar este proceso (consulte Crear aplicaciones genAI usando DSPy en Databricks).
- Actualice su LLM: Si la recuperación es sólida pero las respuestas son débiles, considere usar un mejor modelo generativo.
- Ajuste fino de un LLM: Si su dominio es único y tiene suficientes datos, el ajuste fino de un modelo como Llama 3 puede mejorar aún más la calidad de RAG. Consulte Entrenamiento de Modelos en Databricks: Ajuste Fino de su LLM en Databricks para Tareas y Conocimientos Específicos para más detalles.
Comience con el Ajuste Fino en Databricks
El ajuste fino de incrustaciones puede ser una victoria fácil para mejorar la recuperación y RAG en sus sistemas de IA. En Databricks, puede:
- Ajustar y servir modelos de incrustación en infraestructura escalable.
- Usar herramientas integradas para búsqueda vectorial, reranking y RAG.
- Probar rápidamente diferentes modelos para encontrar lo que funciona mejor para su caso de uso.
¿Listo para probarlo? Hemos creado una solución de referencia para facilitar el ajuste fino: comuníquese con su Gerente de Cuentas o Arquitecto de Soluciones de Databricks para obtener acceso.
Apéndice
Tabla 1: Comparación de gte-large-en-v1.5, e5-mistral-7b-instruct y text-embedding-3-large. Mismos datos que la Figura 1.
Generación de Datos Sintéticos de Entrenamiento
Para todos los conjuntos de datos, las consultas en el conjunto de entrenamiento no fueron las mismas que las consultas en el conjunto de prueba. Sin embargo, en el caso de Databricks DocsQA (pero no FinanceBench o ManufactQA), los documentos utilizados para generar consultas sintéticas fueron los mismos documentos utilizados en el conjunto de evaluación. Nuestro estudio se centra en mejorar la recuperación en tareas y dominios particulares (en contraposición a un modelo de incrustación generalizable de cero disparos); por lo tanto, vemos esto como un enfoque válido para ciertos casos de uso de producción. Para FinanceBench y ManufactQA, los documentos utilizados para generar datos sintéticos no se superpusieron con el corpus utilizado para la evaluación.
Existen diversas formas de seleccionar pasajes negativos para el entrenamiento contrastivo. Pueden seleccionarse aleatoriamente o predefinirse. En el primer caso, los pasajes negativos se seleccionan dentro del lote de entrenamiento; a menudo se les denomina "negativos dentro del lote" o “negativos suaves”. En el segundo caso, el usuario preselecciona ejemplos de texto que son semánticamente difíciles, es decir, potencialmente relacionados con la consulta pero ligeramente incorrectos o irrelevantes. Este segundo caso a veces se denomina "negativos duros". En este trabajo, simplemente utilizamos negativos dentro del lote; la literatura indica que el uso de negativos duros probablemente conduciría a resultados aún mejores.
Detalles de Ajuste Fino
Para todos los experimentos de ajuste fino, la longitud máxima de la secuencia se establece en 2048. Luego evaluamos todos los puntos de control. Para toda la evaluación comparativa, los documentos del corpus se truncaron a 2048 tokens (no se dividieron en fragmentos), lo que fue una restricción razonable para nuestros conjuntos de datos particulares. Elegimos las líneas de base más sólidas en cada evaluación comparativa después de barrer las indicaciones de consulta y la estrategia de agrupación.
Mejora del Rendimiento de RAG
Un sistema RAG consta de un recuperador y un modelo generativo. El recuperador selecciona un conjunto de documentos relevantes para una consulta particular y luego los alimenta al modelo generativo. Seleccionamos los mejores modelos gte-large-en-v1.5 ajustados y los utilizamos para la primera etapa de recuperación de un sistema RAG simple (siguiendo el enfoque general descrito en Long Context RAG Performance of LLMs y The Long Context RAG Capabilities of OpenAI o1 and Google Gemini). En particular, recuperamos k=10 documentos cada uno con una longitud máxima de 512 tokens y utilizamos GPT4o como LLM generativo. La precisión final se evaluó utilizando un LLM como juez (GPT4o).
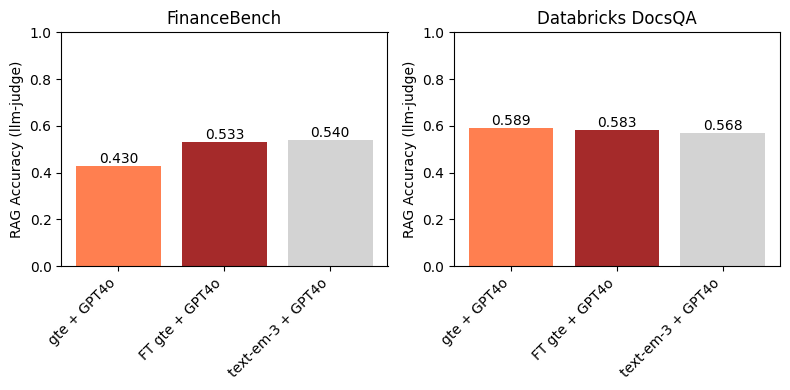
En FinanceBench, la Figura 3 muestra que el uso de un modelo de incrustación ajustado conduce a una mejora en la precisión de RAG posterior. Además, es competitivo con text-embedding-3-large. Esto es esperado, ya que el ajuste fino de gte condujo a una gran mejora en Recall@10 sobre la línea de base gte (Figura 1). Este ejemplo destaca la eficacia del ajuste fino del modelo de incrustación en dominios y conjuntos de datos particulares.
En el conjunto de datos Databricks DocsQA, no encontramos ninguna mejora al usar el modelo gte ajustado por encima de la línea de base gte. Esto es algo esperado, ya que los márgenes entre los modelos de línea de base y ajustados en las Figuras 1 y 2 son pequeños. Curiosamente, aunque text-embedding-3-large tiene un Recall@10 (ligeramente) mayor que cualquiera de los modelos gte, no conduce a una mayor precisión de RAG posterior. Como se muestra en la Figura 1, todos los modelos de incrustación tenían un Recall@10 relativamente alto en el conjunto de datos Databricks DocsQA; esto indica que la recuperación probablemente no es el cuello de botella para RAG, y que el ajuste fino de un modelo de incrustación en este conjunto de datos no es necesariamente el enfoque más fructífero.
Nos gustaría agradecer a Quinn Leng y Matei Zaharia por sus comentarios sobre esta publicación de blog.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.