Mejora del rendimiento de Text2SQL con facilidad en Databricks
por Matthew Hayes, Evion Kim, Linqing Liu, Alnur Ali, Ritendra Datta y Sam Shah
¿Quieres que tu LLM suba al top 10 de Spider, un benchmark ampliamente utilizado para tareas de texto a SQL? Spider evalúa qué tan bien los LLM pueden convertir consultas de texto en código SQL.
Para aquellos que no están familiarizados con texto a SQL, su importancia radica en transformar la forma en que las empresas interactúan con sus datos. En lugar de depender de expertos en SQL para escribir consultas, las personas pueden simplemente hacer preguntas sobre sus datos en lenguaje natural y recibir respuestas precisas. Esto democratiza el acceso a los datos, mejora la inteligencia empresarial y permite una toma de decisiones más informada.
El benchmark Spider es un estándar ampliamente reconocido para evaluar el rendimiento de los sistemas de texto a SQL. Desafía a los LLM a traducir consultas en lenguaje natural a sentencias SQL precisas, lo que requiere una comprensión profunda de los esquemas de bases de datos y la capacidad de generar código SQL sintácticamente y semánticamente correcto.
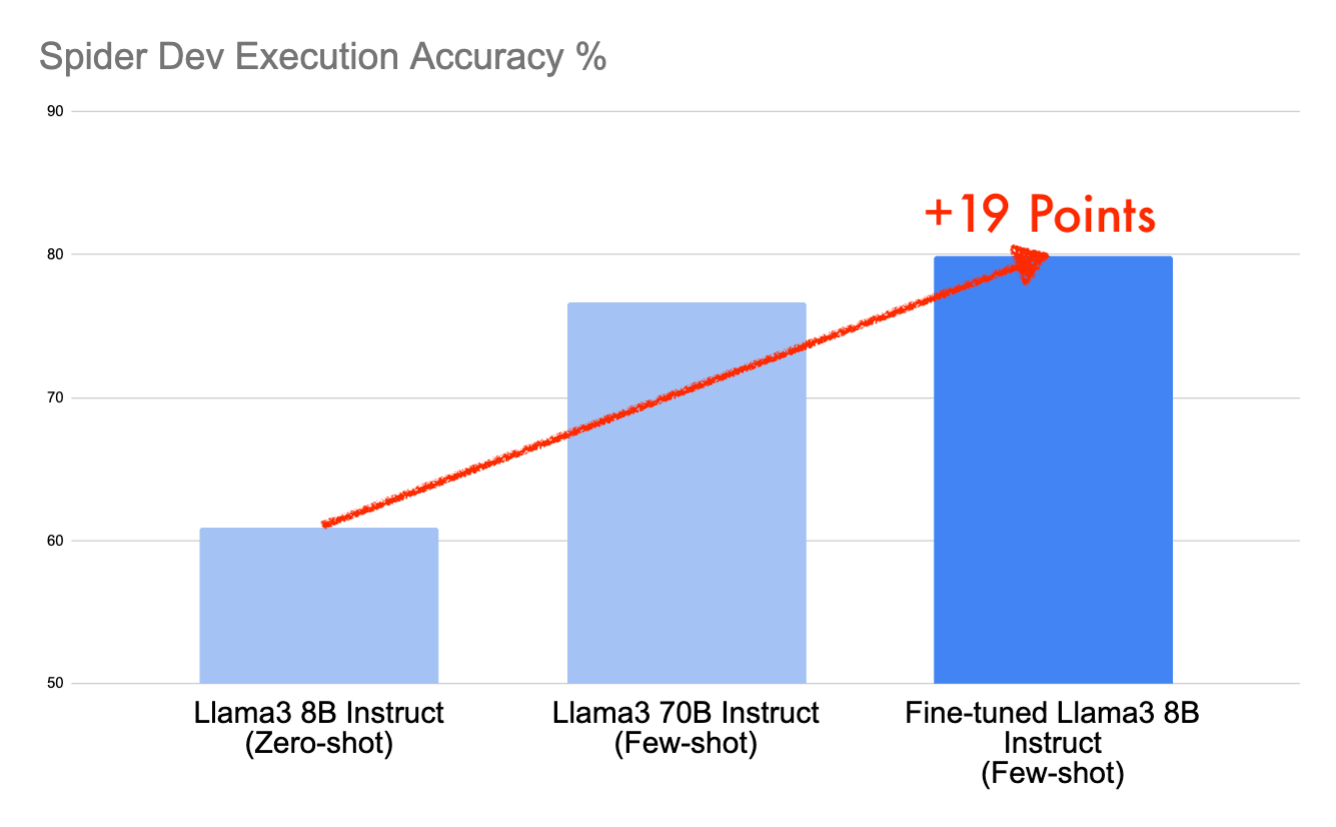
En esta publicación, profundizaremos en cómo logramos puntuaciones del 79.9% en el conjunto de datos de desarrollo de Spider y del 78.9% en el conjunto de datos de prueba en menos de un día de trabajo utilizando el modelo de código abierto Llama3 8B Instruct, una mejora notable de 19 puntos con respecto a la línea base. Este rendimiento lo colocaría en el top 10 de la tabla de clasificación de Spider, ahora congelada, gracias a la indicación estratégica y el ajuste fino en Databricks.
Indicación sin ejemplos (Zero-shot) para el rendimiento base
Comencemos evaluando el rendimiento de Meta Llama 3 8B Instruct en el conjunto de datos de desarrollo de Spider utilizando un formato de indicación muy simple que consiste en las declaraciones CREATE TABLE que crearon las tablas y una pregunta que nos gustaría responder utilizando esas tablas:
Este tipo de indicación a menudo se denomina "sin ejemplos" (zero-shot) porque no hay otros ejemplos en la indicación. Para la primera pregunta en el conjunto de datos de desarrollo de Spider, este formato de indicación produce:
Ejecutar el benchmark Spider en el conjunto de datos de desarrollo utilizando este formato produce una puntuación general de 60.9 cuando se mide utilizando la precisión de ejecución y la decodificación codiciosa. Esto significa que el 60.9% de las veces el modelo produce SQL que, al ejecutarse, produce los mismos resultados que una consulta "gold" que representa la solución correcta.
| Fácil | Medio | Difícil | Extra | Todos | |
|---|---|---|---|---|---|
| Sin ejemplos | 78.6 | 69.3 | 42.5 | 31.3 | 60.9 |
Con la puntuación base establecida, antes de entrar en el ajuste fino, intentemos diferentes estrategias de indicación para intentar aumentar la puntuación del modelo base en el conjunto de datos de desarrollo de Spider.
Indicación con filas de ejemplo
Uno de los inconvenientes de la primera indicación que utilizamos es que no incluye información sobre los datos en las columnas más allá del tipo de dato. Un artículo sobre la evaluación de las capacidades de texto a SQL de los modelos con Spider encontró que agregar filas de ejemplo a la indicación conducía a una puntuación más alta, así que intentemos eso.
Podemos actualizar el formato de indicación anterior para que las consultas de creación de tablas también incluyan las primeras filas de cada tabla. Para la misma pregunta anterior, ahora tenemos una indicación actualizada:
Incluir filas de ejemplo para cada tabla aumenta la puntuación general en aproximadamente 6 puntos porcentuales a 67.0:
| Fácil | Medio | Difícil | Extra | Todos | |
|---|---|---|---|---|---|
| Sin ejemplos con filas de ejemplo | 80.6 | 75.3 | 51.1 | 41.0 | 67.0 |
Indicación con pocos ejemplos (Few-shot)
La indicación con pocos ejemplos (few-shot) es una estrategia bien conocida utilizada con los LLM donde podemos mejorar el rendimiento en una tarea como la generación de SQL correcto al incluir algunos ejemplos que demuestran la tarea a realizar. Con una indicación sin ejemplos (zero-shot), proporcionamos los esquemas y luego hicimos una pregunta. Con una indicación con pocos ejemplos (few-shot), proporcionamos algunos esquemas, una pregunta, el SQL que responde a esa pregunta, y luego repetimos esa secuencia un par de veces antes de llegar a la pregunta real que queremos hacer. Esto generalmente resulta en un mejor rendimiento que una indicación sin ejemplos.
Una buena fuente de ejemplos que demuestran la tarea de generación de SQL es en realidad el propio conjunto de datos de entrenamiento de Spider. Podemos tomar una muestra aleatoria de algunas preguntas de este conjunto de datos con sus tablas correspondientes y construir una indicación con pocos ejemplos que demuestre el SQL que puede responder a cada una de estas preguntas. Dado que ahora estamos utilizando filas de ejemplo como en la indicación anterior, también debemos asegurarnos de que uno de estos ejemplos también incluya filas de ejemplo para demostrar su uso.
Otra mejora que podemos hacer en la indicación sin ejemplos anterior es incluir también una "indicación del sistema" al principio. Las indicaciones del sistema se utilizan típicamente para proporcionar orientación detallada al modelo que describe la tarea a realizar. Si bien un usuario puede hacer varias preguntas a lo largo de una conversación con un modelo, la indicación del sistema se proporciona una sola vez antes de que el usuario haga una pregunta, estableciendo esencialmente las expectativas de cómo debe funcionar el "sistema" durante la conversación.
Con estas estrategias en mente, podemos construir una indicación con pocos ejemplos que también comience con un mensaje del sistema representado como un bloque grande de comentarios SQL en la parte superior, seguido de tres ejemplos:
Esta nueva indicación ha resultado en una puntuación de 70.8, que es otra mejora de 3.8 puntos porcentuales con respecto a nuestra puntuación anterior. Hemos aumentado la puntuación casi 10 puntos porcentuales desde donde empezamos, solo a través de estrategias simples de indicación.
| Fácil | Medio | Difícil | Extra | Todos | |
|---|---|---|---|---|---|
| Pocos ejemplos con filas de ejemplo | 83.9 | 79.1 | 55.7 | 44.6 | 70.8 |
Probablemente estemos llegando al punto de rendimientos decrecientes al ajustar nuestra indicación. Vamos a ajustar el modelo para ver qué otras ganancias se pueden lograr.
Ajuste Fino con LoRA
Si estamos ajustando el modelo, la primera pregunta es qué datos de entrenamiento usar. Spider incluye un conjunto de datos de entrenamiento, por lo que este parece un buen lugar para empezar. Para ajustar el modelo, usaremos QLoRA para poder entrenar el modelo de manera eficiente en un clúster de GPU Databricks A100 80GB individual, como Standard_NC24ads_A100_v4 en Databricks. Esto se puede completar en aproximadamente cuatro horas utilizando los 7k registros del conjunto de datos de entrenamiento de Spider. Hemos discutido previamente el ajuste fino con LoRA en una publicación de blog anterior. Los lectores interesados pueden consultar esa publicación para obtener más detalles. Podemos seguir recetas de entrenamiento estándar utilizando las bibliotecas trl, peft y bitsandbytes.
Aunque obtenemos los registros de entrenamiento de Spider, todavía necesitamos formatearlos de una manera que el modelo pueda aprender. El objetivo es mapear cada registro, que consta del esquema (con filas de ejemplo), la pregunta y el SQL a una única cadena de texto. Comenzamos realizando un procesamiento en el conjunto de datos bruto de Spider. A partir de los datos brutos, producimos un conjunto de datos donde cada registro consta de tres campos: schema_with_rows, question y query. El campo schema_with_rows se deriva de las tablas correspondientes a la pregunta, siguiendo el formato de la declaración CREATE TABLE y las filas utilizadas en el prompt few-shot anterior.
A continuación, cargamos el tokenizador:
Definiremos una función de mapeo que convertirá cada registro de nuestro conjunto de datos de entrenamiento de Spider procesado en una cadena de texto. Podemos usar apply_chat_template del tokenizador para formatear convenientemente el texto en el formato de chat esperado por el modelo Instruct. Aunque este no es exactamente el mismo formato que estamos utilizando para nuestro prompt few-shot, el modelo se generaliza lo suficientemente bien como para funcionar incluso si el formato de plantilla de los prompts es ligeramente diferente.
Para SYSTEM_PROMPT usamos el mismo prompt del sistema que se utilizó anteriormente en el prompt few-shot. Para USER_MESSAGE_FORMAT, usamos de manera similar:
Con esta función definida, todo lo que queda es transformar el conjunto de datos de Spider procesado con ella y guardarlo como un archivo JSONL.
Ahora estamos listos para entrenar. Unas horas después, tenemos un Llama3 8B Instruct ajustado. Al volver a ejecutar nuestro prompt few-shot en este nuevo modelo, obtuvimos una puntuación de 79.9, lo que representa una mejora adicional de 9 puntos porcentuales sobre nuestra puntuación anterior. Ahora hemos aumentado la puntuación total en ~19 puntos porcentuales con respecto a nuestra línea base simple de zero-shot.
| Fácil | Medio | Difícil | Extra | Todos | |
|---|---|---|---|---|---|
| Few-shot con filas de ejemplo (Llama3 8B Instruct ajustado) |
91.1 | 85.9 | 72.4 | 54.8 | 79.9 |
| Few-shot con filas de ejemplo (Llama3 8B Instruct) |
83.9 | 79.1 | 55.7 | 44.6 | 70.8 |
| Zero-shot con filas de ejemplo (Llama3 8B Instruct) |
80.6 | 75.3 | 51.1 | 41.0 | 67.0 |
| Zero-shot (Llama3 8B Instruct) |
78.6 | 69.3 | 42.5 | 31.3 | 60.9 |
Quizás se pregunte ahora cómo se compara el modelo Llama3 8B Instruct y su versión ajustada con un modelo más grande como Llama3 70B Instruct. Hemos repetido el proceso de evaluación utilizando el modelo 70B listo para usar en el conjunto de datos de desarrollo con ocho GPU A100 de 40 GB y registrado los resultados a continuación.
| Few-shot con filas de ejemplo (Llama3 70B Instruct) |
89.5 | 83.0 | 64.9 | 53.0 | 76.7 |
| Zero-shot con filas de ejemplo (Llama3 70B Instruct) |
83.1 | 81.8 | 59.2 | 36.7 | 71.1 |
| Zero-shot (Llama3 70B Instruct) |
82.3 | 80.5 | 57.5 | 31.9 | 69.2 |
Como era de esperar, al comparar los modelos listos para usar, el modelo 70B supera al modelo 8B medido con el mismo formato de prompt. Pero lo sorprendente es que el modelo Llama3 8B Instruct ajustado obtiene una puntuación superior al modelo Llama3 70B Instruct en 3 puntos porcentuales. Cuando se enfoca en tareas específicas como text-to-SQL, el ajuste fino puede resultar en modelos pequeños que son comparables en rendimiento con modelos mucho más grandes en tamaño.
Desplegar a un Endpoint de Servicio de Modelos
Llama3 es compatible con Databricks Model Serving, por lo que incluso podríamos desplegar nuestro modelo Llama3 ajustado a un endpoint y usarlo para potenciar aplicaciones. Todo lo que necesitamos hacer es registrar el modelo ajustado en Unity Catalog y luego crear un endpoint usando la UI. Una vez desplegado, podemos consultarlo usando bibliotecas comunes.
Resumen
Comenzamos nuestro viaje con Llama3 8B Instruct en el conjunto de datos de desarrollo de Spider usando un prompt zero-shot, logrando una puntuación modesta de 60.9. Al mejorar esto con un prompt few-shot —completo con mensajes del sistema, múltiples ejemplos y filas de muestra— aumentamos nuestra puntuación a 70.8. Se obtuvieron más mejoras al ajustar el modelo en el conjunto de datos de entrenamiento de Spider, lo que nos impulsó a un impresionante 79.9 en Spider dev y 78.9 en Spider test. Este aumento significativo de 19 puntos desde nuestro punto de partida y una ventaja de 3 puntos sobre el Llama3 70B Instruct base no solo muestra la destreza de nuestro modelo, sino que también nos aseguraría un lugar codiciado entre los 10 mejores resultados en Spider.
Obtenga más información sobre cómo aprovechar el poder de los LLM de código abierto y la Plataforma de Inteligencia de Datos registrándose en Data+AI Summit.
Apéndice
Configuración de Evaluación
La generación se realizó utilizando vLLM, decodificación greedy (temperatura de 0), dos GPU A100 de 80 GB y 1024 tokens nuevos máximos. Para evaluar las generaciones, utilizamos el conjunto de pruebas del repositorio taoyds/test-suite-sql-eval en Github.
Configuración de Entrenamiento
Aquí están los detalles específicos sobre la configuración de ajuste fino:
| Modelo Base | Llama3 8B Instruct |
| GPUs | A100 80GB individual |
| Pasos Máximos | 100 |
| Registros del conjunto de datos de entrenamiento de Spider | 7000 |
| Lora R | 16 |
| Lora Alpha | 32 |
| Lora Dropout | 0.1 |
| Tasa de Aprendizaje | 1.5e-4 |
| Programador de Tasa de Aprendizaje | Constante |
| Pasos de Acumulación de Gradiente | 8 |
| Checkpointing de Gradiente | True |
| Tamaño de Lote de Entrenamiento | 12 |
| Módulos Objetivo de LoRA | q_proj,v_proj,k_proj,o_proj,gate_proj,up_proj,down_proj |
| Plantilla de Respuesta del Compilador de Datos | <|start_header_id|>asistente<|end_header_id|> |
Ejemplo de Prompt Zero-Shot
Este es el primer registro del conjunto de datos de desarrollo que utilizamos para la evaluación, formateado como un prompt zero-shot que incluye los esquemas de las tablas. Las tablas a las que se refiere la pregunta se representan mediante las sentencias CREATE TABLE que las crearon.
Ejemplo de Prompt Zero-Shot con Filas de Muestra
Este es el primer registro del conjunto de datos de desarrollo que utilizamos para la evaluación, formateado como un prompt zero-shot que incluye los esquemas de las tablas y filas de muestra. Las tablas a las que se refiere la pregunta se representan mediante las sentencias CREATE TABLE que las crearon. Las filas se seleccionaron usando "SELECT * {table_name} LIMIT 3" de cada tabla, con los nombres de las columnas apareciendo como encabezado.
Ejemplo de Prompt Few-Shot con Filas de Muestra
Este es el primer registro del conjunto de datos de desarrollo que utilizamos para la evaluación, formateado como un prompt few-shot que incluye los esquemas de las tablas y filas de muestra. Las tablas a las que se refiere la pregunta se representan mediante las sentencias CREATE TABLE que las crearon. Las filas se seleccionaron usando "SELECT * {table_name} LIMIT 3" de cada tabla, con los nombres de las columnas apareciendo como encabezado.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.