Equilibra de forma inteligente la optimización de costos y la confiabilidad en Databricks
Profundiza en la intersección de la gestión financiera y la computación en la nube en la Plataforma de Inteligencia de Datos de Databricks
por Vuong Nguyen y Wasim Ahmad
La Plataforma de Inteligencia de Datos de Databricks ofrece una flexibilidad sin igual, permitiendo a los usuarios acceder a recursos de cómputo escalables horizontalmente y casi instantáneos. Esta facilidad de creación puede generar costos de nube descontrolados si no se gestionan adecuadamente.
Implementar Observabilidad para Rastrear y Asignar Costos
Cómo usar la observabilidad de manera efectiva para rastrear y asignar costos en Databricks
Al trabajar con ecosistemas técnicos complejos, comprender de forma proactiva lo desconocido es clave para mantener la estabilidad de la plataforma y controlar los costos. La observabilidad proporciona una forma de analizar y optimizar sistemas basándose en los datos que generan. Esto es diferente del monitoreo, que se enfoca en identificar patrones nuevos en lugar de rastrear problemas conocidos.
Características clave para el rastreo de costos en Databricks
Etiquetas (Tags): Usa etiquetas para categorizar recursos y cargos. Esto permite una asignación de costos más granular.
Tablas del Sistema (System Tables): Aprovecha las tablas del sistema para el rastreo de costos automatizado y la asignación de cargos. Herramientas de monitoreo de costos nativas de la nube: Utiliza estas herramientas para obtener información sobre los costos en todos los recursos.
¿Qué son las Tablas del Sistema y cómo usarlas?
Databricks proporciona excelentes capacidades de observabilidad utilizando Tablas del Sistema. Estas son almacenes analíticos alojados por Databricks de los datos operativos de la cuenta de un cliente que se encuentran en el catálogo del sistema. Proporcionan observabilidad histórica en toda la cuenta e incluyen información tabular fácil de usar sobre la telemetría de la plataforma. Se pueden encontrar información clave como los datos de uso de facturación en las tablas del sistema (esto actualmente solo incluye el precio de lista de DBU), y cada registro de uso representa un agregado horario del uso facturable de un recurso.
Cómo habilitar las tablas del sistema
Las tablas del sistema son administradas por Unity Catalog y requieren un espacio de trabajo habilitado para Unity Catalog para acceder. Incluyen datos de todos los espacios de trabajo, pero solo se pueden consultar desde espacios de trabajo habilitados. La habilitación de las tablas del sistema se realiza a nivel de esquema: habilitar un esquema habilita todas sus tablas. Los administradores deben habilitar manualmente los esquemas nuevos usando la API.

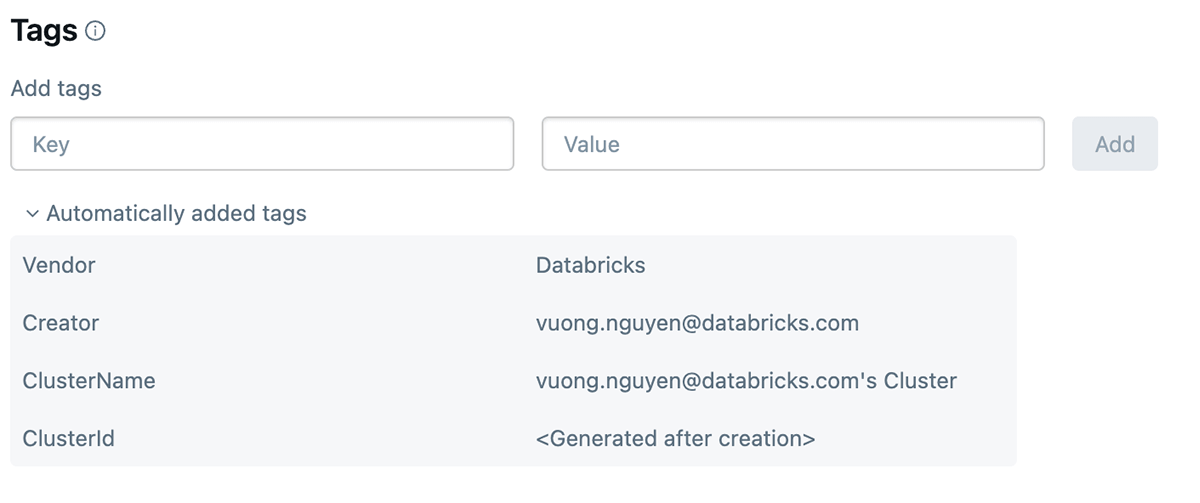
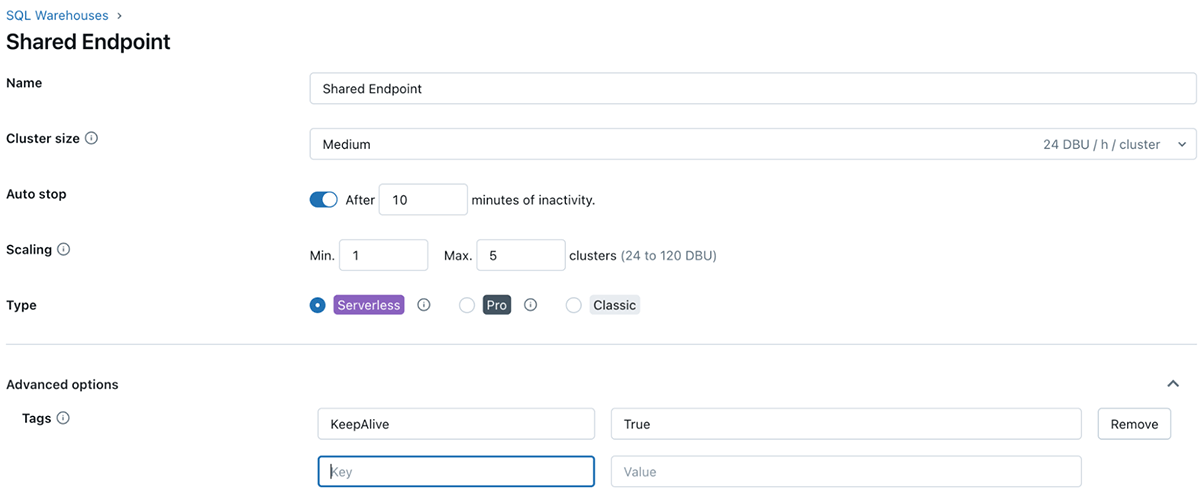
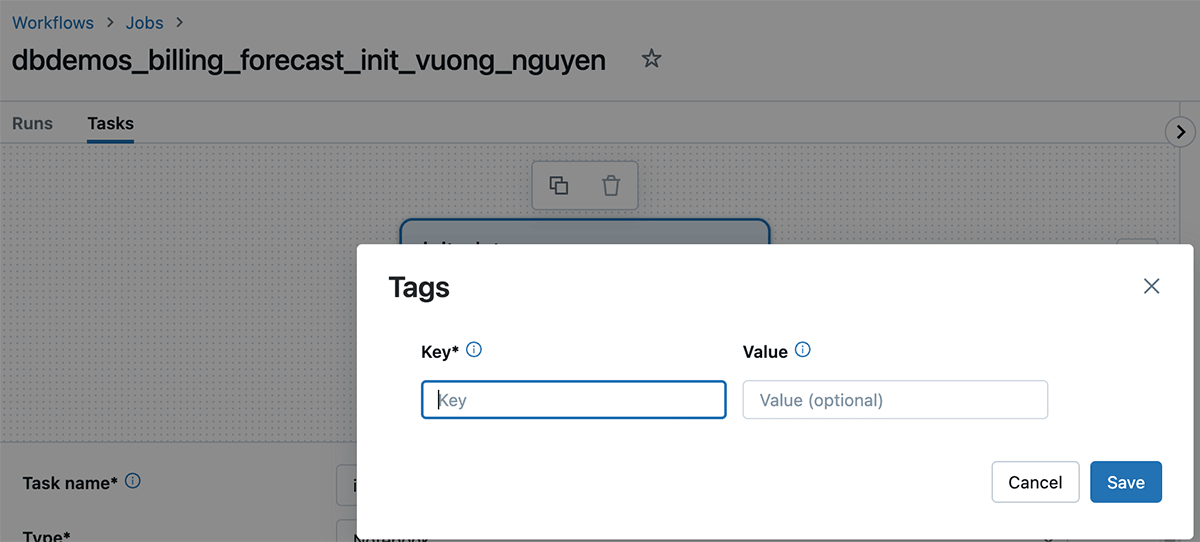
¿Qué son las etiquetas de Databricks y cómo usarlas?
El etiquetado de Databricks te permite aplicar atributos (pares clave-valor) a los recursos para una mejor organización, búsqueda y gestión. Para rastrear costos y asignarlos, los equipos pueden etiquetar sus trabajos y cómputo de Databricks (Clusters, SQL warehouse), lo que puede ayudarles a rastrear el uso, los costos y atribuirlos a equipos o unidades específicas.
Cómo aplicar etiquetas
Las etiquetas se pueden aplicar a los siguientes recursos de Databricks para rastrear el uso y los costos:
- Cómputo de Databricks
- Trabajos de Databricks
Una vez aplicadas estas etiquetas, se puede realizar un análisis detallado de costos utilizando las tablas del sistema de uso facturable.
Cómo identificar costos usando herramientas nativas de la nube
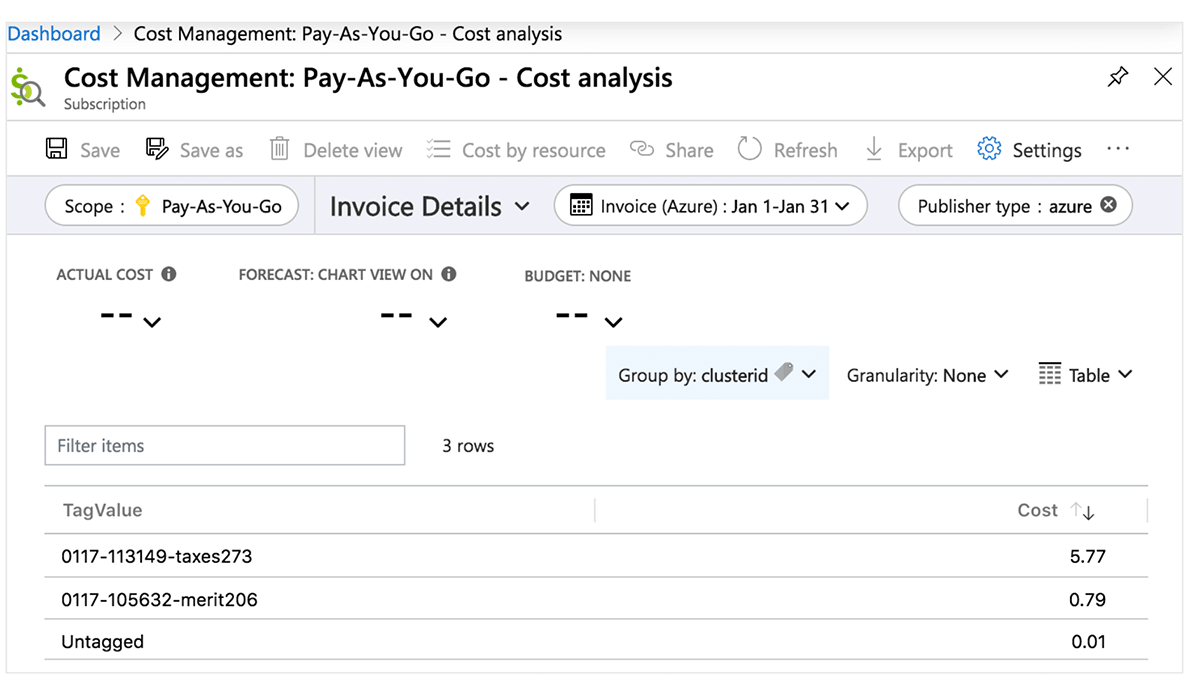
Para monitorear costos y atribuir con precisión el uso de Databricks a las unidades de negocio y equipos de tu organización (para asignación de cargos, por ejemplo), puedes etiquetar espacios de trabajo (y los grupos de recursos administrados asociados), así como los recursos de cómputo.
Centro de Costos de Azure
La siguiente tabla detalla los objetos de Azure Databricks donde se pueden aplicar etiquetas. Estas etiquetas pueden propagarse a informes detallados de análisis de costos que puedes acceder en el portal y a la tabla del sistema de uso facturable. Encuentra más detalles sobre la propagación de etiquetas y limitaciones en Azure.
| Objeto de Azure Databricks | Interfaz de Etiquetado (UI) | Interfaz de Etiquetado (API) |
|---|---|---|
| Espacio de trabajo | Portal de Azure | API de Recursos de Azure |
| Pool | UI de Pools en el espacio de trabajo de Azure Databricks | API de Instance Pool |
| Cómputo de propósito general y de trabajos | UI de Cómputo en el espacio de trabajo de Azure Databricks | API de Clusters |
| SQL Warehouse | UI de SQL warehouse en el espacio de trabajo de Azure Databricks | API de Warehouse |
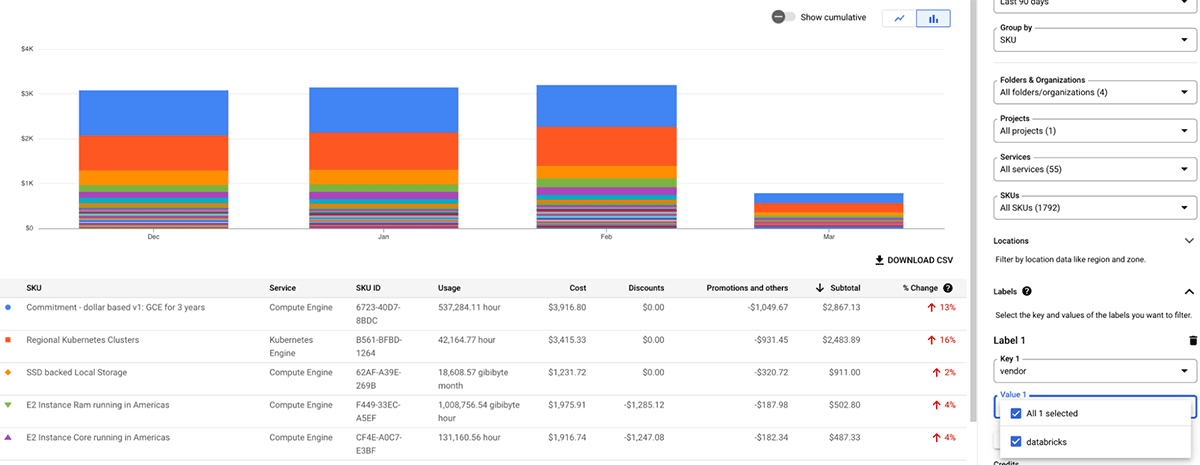
AWS Cost Explorer
La siguiente tabla detalla los objetos de AWS Databricks donde se pueden aplicar etiquetas. Estas etiquetas pueden propagarse tanto a los registros de uso como a las instancias de AWS EC2 y AWS EBS para el análisis de costos. Databricks recomienda usar tablas del sistema (Vista Previa Pública) para ver datos de uso facturable. Encuentra más detalles sobre la propagación de etiquetas y limitaciones en AWS.
| Objeto de AWS Databricks | Interfaz de Etiquetado (UI) | Interfaz de Etiquetado (API) |
|---|---|---|
| Espacio de trabajo | N/A | API de Cuenta |
| Pool | UI de Pools en el espacio de trabajo de Databricks | API de Instance Pool |
| Cómputo de propósito general y de trabajos | UI de Cómputo en el espacio de trabajo de Databricks | API de Clusters |
| SQL Warehouse | UI de SQL warehouse en el espacio de trabajo de Databricks | API de Warehouse |
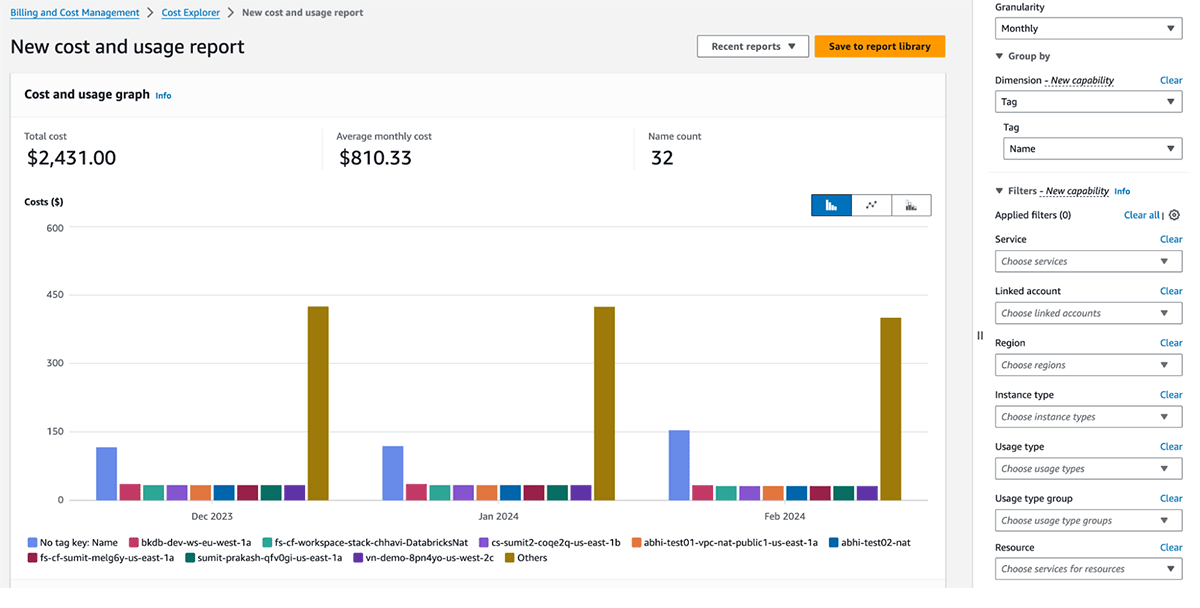
Gestión de costos y facturación de GCP
La siguiente tabla detalla los objetos de GCP Databricks donde se pueden aplicar etiquetas. Estas etiquetas/rótulos se pueden aplicar a los recursos de cómputo. Encuentra más detalles sobre la propagación de etiquetas/rótulos y limitaciones en GCP.
Los gráficos de uso facturable de Databricks en la consola de la cuenta pueden agregar el uso por etiquetas individuales. Los informes CSV de uso facturable descargados de la misma página también incluyen etiquetas predeterminadas y personalizadas. Las etiquetas también se propagan a los rótulos de GKE y GCE.
| Objeto de GCP Databricks | Interfaz de Etiquetado (UI) | Interfaz de Etiquetado (API) |
|---|---|---|
| Pool | UI de Pools en el espacio de trabajo de Databricks | API de Instance Pool |
| Computación para todo uso y trabajos | Interfaz de usuario de computación en el espacio de trabajo de Databricks | API de clústeres |
| Almacén SQL | Interfaz de usuario del almacén SQL en el espacio de trabajo de Databricks | API de almacenes |
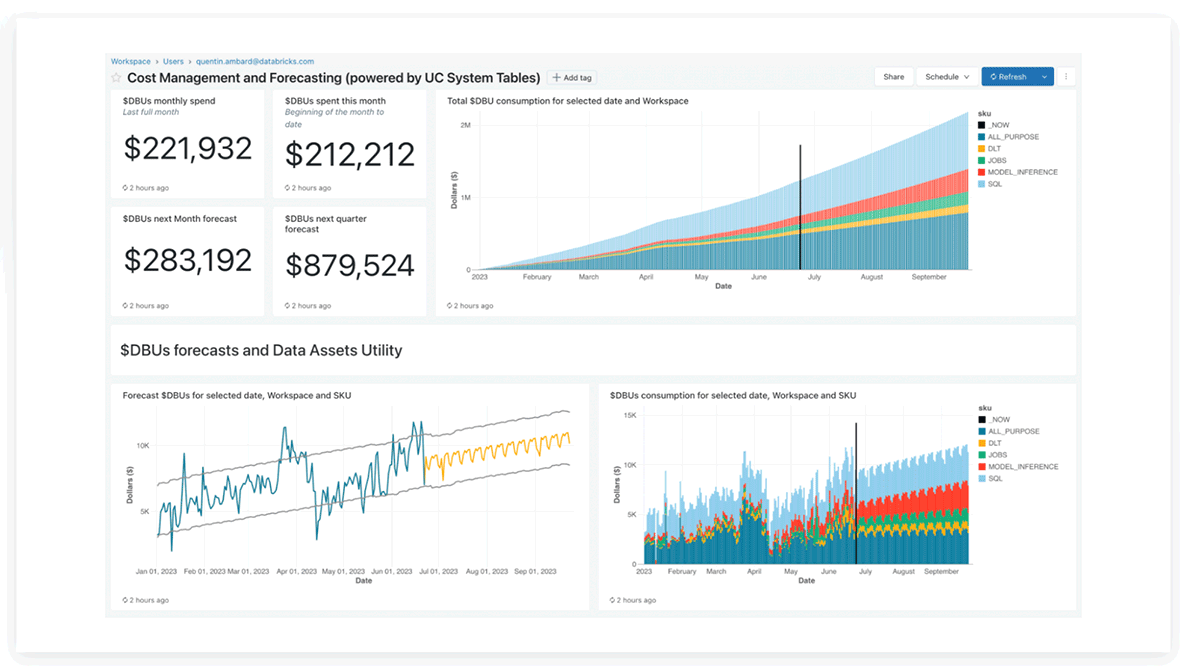
Panel de Lakeview de tablas del sistema de Databricks
El equipo de producto de Databricks ha proporcionado paneles de Lakeview precreados para el análisis de costos y la previsión utilizando tablas del sistema, que los clientes también pueden personalizar.
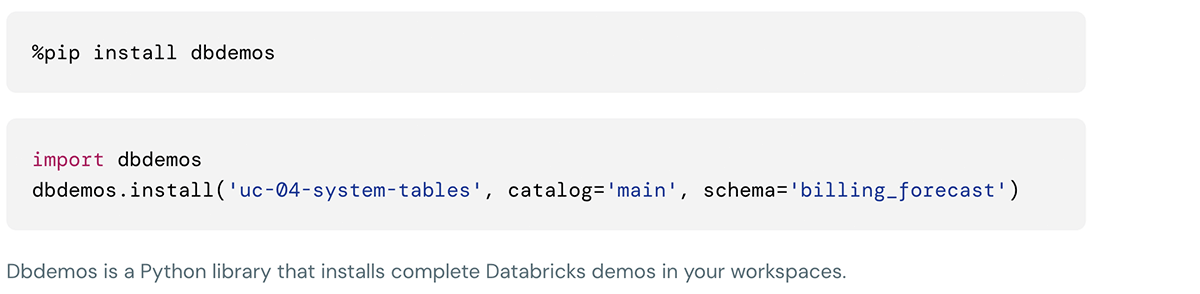
Esta demostración se puede instalar usando los siguientes comandos en la celda de los notebooks de Databricks:
Mejores prácticas para maximizar el valor
Al ejecutar cargas de trabajo en Databricks, elegir la configuración de computación adecuada mejorará significativamente las métricas de costo/rendimiento. A continuación, se presentan algunas técnicas prácticas de optimización de costos:
Usar el tipo de computación adecuado para el trabajo adecuado
Para cargas de trabajo interactivas de SQL, el almacén SQL es el motor más rentable. Aún más eficiente podría ser la computación Serverless, que viene con un tiempo de inicio muy rápido para los almacenes SQL y permite un tiempo de terminación automática más corto.
Para cargas de trabajo no interactivas, los clústeres de trabajos cuestan significativamente menos que los clústeres para todo uso. Los flujos de trabajo multitarea pueden reutilizar recursos de computación para todas las tareas, lo que reduce aún más los costos.
Elegir el tipo de instancia adecuado
Usar la última generación de tipos de instancia en la nube casi siempre brindará beneficios de rendimiento, ya que vienen con el mejor rendimiento y las últimas características. En AWS, las instancias Amazon EC2 basadas en Graviton2 pueden ofrecer hasta 3 veces mejor relación precio-rendimiento que las instancias Amazon EC2 comparables.
Según sus cargas de trabajo, también es importante elegir la familia de instancias adecuada. Algunas reglas generales son:
- Optimizado para memoria para ML, cargas de trabajo con mucho barajado y desbordamiento.
- Optimizado para computación para cargas de trabajo de Structured Streaming, trabajos de mantenimiento (por ejemplo, Optimize & Vacuum).
- Optimizado para almacenamiento para cargas de trabajo que se benefician del almacenamiento en caché, por ejemplo, análisis de datos ad hoc e interactivos.
- Optimizado para GPU para cargas de trabajo específicas de ML y DL.
- Uso general en ausencia de requisitos específicos.
Elegir el tiempo de ejecución adecuado
El último Databricks Runtime (DBR) generalmente viene con un rendimiento mejorado y casi siempre será más rápido que el anterior.
Photon es un motor de consulta vectorial nativo de Databricks de alto rendimiento que acelera sus cargas de trabajo SQL y las llamadas a la API de DataFrame para reducir su costo total por carga de trabajo. Para esas cargas de trabajo, habilitar Photon podría generar ahorros significativos.
Aprovechar la escalabilidad automática en la computación de Databricks
Databricks proporciona una característica única de escalabilidad automática de clústeres, lo que facilita lograr una alta utilización del clúster porque no necesita aprovisionar el clúster para que coincida con una carga de trabajo. Esto es particularmente útil para cargas de trabajo interactivas o cargas de trabajo por lotes con carga de datos variable. Sin embargo, la escalabilidad automática clásica no funciona con cargas de trabajo de Structured Streaming, por lo que hemos desarrollado Escalabilidad Automática Mejorada en Delta Live Tables para manejar cargas de trabajo de transmisión que son irregulares e impredecibles.
Aprovechar las instancias Spot
Todos los principales proveedores de nube ofrecen instancias spot que le permiten acceder a capacidad no utilizada en sus centros de datos por hasta un 90% menos que las instancias On-Demand regulares. Databricks le permite aprovechar estas instancias spot, con la capacidad de recurrir automáticamente a instancias On-Demand en caso de terminación para minimizar las interrupciones. Para la estabilidad del clúster, recomendamos usar nodos de controlador On-Demand.
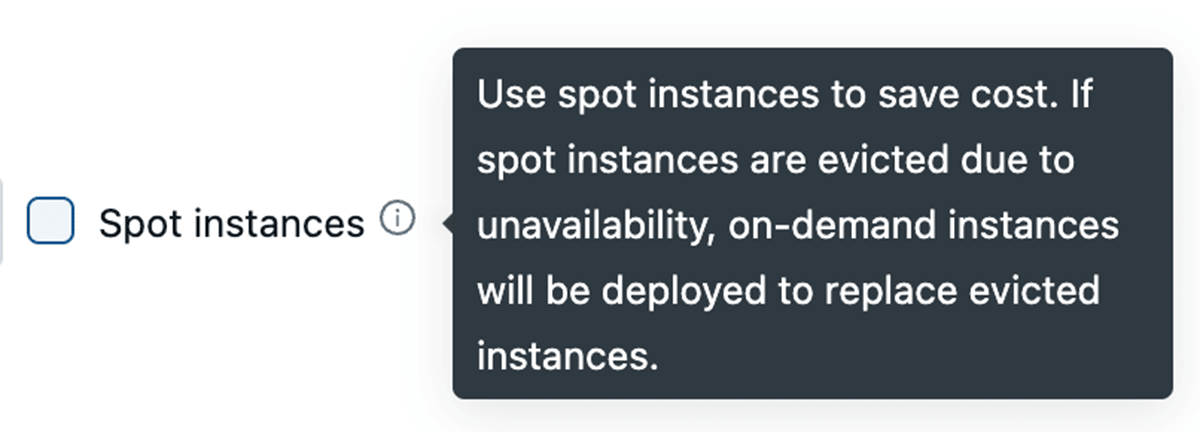
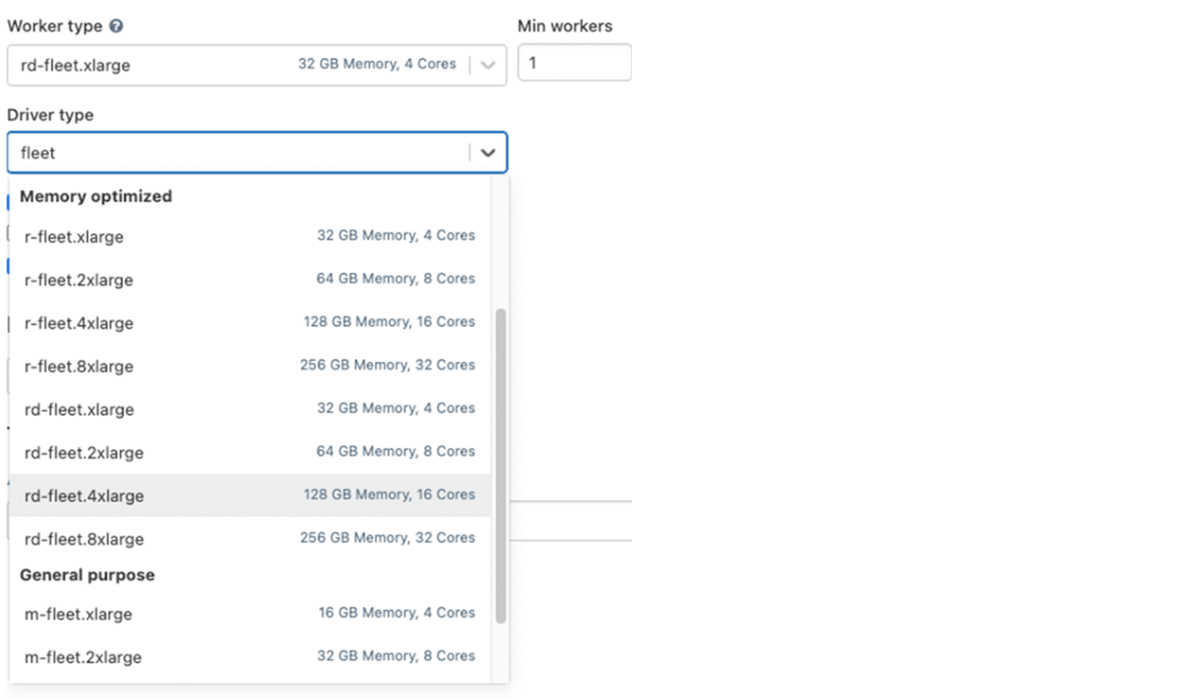
Aprovechar el tipo de instancia Fleet (en AWS)
En segundo plano, cuando un clúster utiliza uno de estos tipos de instancia fleet, Databricks seleccionará los tipos de instancia física de AWS coincidentes con el mejor precio y disponibilidad para usar en su clúster.
Política de clúster
El uso eficaz de políticas de clúster permite a los administradores aplicar restricciones específicas de costos para los usuarios finales:
- Habilitar la terminación automática del clúster con un valor razonable (por ejemplo, 1 hora) para evitar pagar por tiempos inactivos.
- Asegurarse de que solo se puedan seleccionar instancias de VM rentables.
- Aplicar etiquetas obligatorias para la imputación de costos.
- Controlar el perfil de costos general limitando el costo máximo por clúster, por ejemplo, DBUs máximos por hora o recursos de computación máximos por usuario.
Optimización de costos impulsada por IA
La Plataforma de Inteligencia de Datos de Databricks integra funciones avanzadas de IA que optimizan el rendimiento, reducen los costos, mejoran la gobernanza y simplifican el desarrollo de aplicaciones empresariales de IA. La E/S predictiva y Liquid Clustering mejoran las velocidades de consulta y la utilización de recursos, mientras que la gestión inteligente de cargas de trabajo optimiza la escalabilidad automática para la eficiencia de costos. En general, la plataforma de Databricks ofrece un conjunto completo de herramientas de IA para impulsar la productividad y el ahorro de costos, al tiempo que permite soluciones innovadoras para casos de uso específicos de la industria.
Liquid clustering
Liquid clustering de Delta Lake reemplaza la partición de tablas y ZORDER para simplificar las decisiones de diseño de datos y optimizar el rendimiento de las consultas. Liquid clustering proporciona flexibilidad para redefinir las claves de agrupación sin reescribir los datos existentes, lo que permite que el diseño de los datos evolucione junto con las necesidades analíticas a lo largo del tiempo.
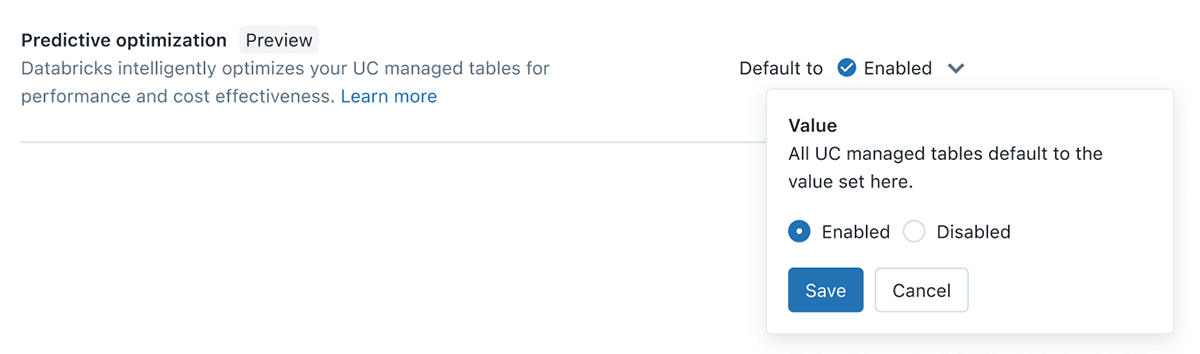
Optimización Predictiva
Los ingenieros de datos en el lakehouse estarán familiarizados con la necesidad de OPTIMIZAR y VACUAR regularmente sus tablas, sin embargo, esto crea desafíos continuos para determinar las tablas correctas, el programa apropiado y el tamaño de computación correcto para que se ejecuten estas tareas. Con Optimización Predictiva, aprovechamos Unity Catalog y Lakehouse AI para determinar las mejores optimizaciones a realizar en sus datos, y luego ejecutamos esas operaciones en infraestructura serverless especialmente diseñada. Todo esto sucede automáticamente, asegurando el mejor rendimiento sin desperdicio de computación ni esfuerzo de ajuste manual.
Vista Materializada con Actualización Incremental
En Databricks, las Vistas Materializadas (MVs) son tablas administradas por Unity Catalog que permiten a los usuarios precalcular resultados basados en la última versión de los datos en las tablas de origen. Construidas sobre Delta Live Tables y serverless, las MVs reducen la latencia de las consultas al precalcular cálculos lentos y frecuentes. Cuando es posible, los resultados se actualizan incrementalmente, pero son idénticos a los que se obtendrían con una recalcularción completa. Esto reduce el costo computacional y evita la necesidad de mantener clústeres separados.
Funcionalidades serverless para casos de uso de Model Serving y Gen AI
Para dar mejor soporte a los casos de uso de model serving y Gen AI, Databricks ha introducido múltiples capacidades sobre nuestra infraestructura serverless que escala automáticamente a tus flujos de trabajo sin necesidad de configurar instancias y tipos de servidor.
- AI Search: Índice vectorial que puede sincronizarse desde cualquier Delta Table con un clic, sin necesidad de complejas canalizaciones de ingesta/sincronización de datos personalizadas.
- Online Tables: Tablas completamente serverless que escalan automáticamente la capacidad de rendimiento con la carga de solicitudes y proporcionan acceso de baja latencia y alto rendimiento a datos de cualquier escala.
- Model Serving: Servicio de alta disponibilidad y baja latencia para desplegar modelos. El servicio escala automáticamente hacia arriba o hacia abajo para satisfacer los cambios en la demanda, ahorrando costos de infraestructura mientras optimiza el rendimiento de la latencia.
Predictive I/O para actualizaciones y eliminaciones
Con estas funcionalidades potenciadas por IA, Databricks SQL ahora puede analizar patrones históricos de lectura y escritura para construir índices de forma inteligente y optimizar cargas de trabajo. Predictive I/O es un conjunto de optimizaciones de Databricks que mejoran el rendimiento de las interacciones con los datos. Las capacidades de Predictive I/O se agrupan en las siguientes categorías:
- Las lecturas aceleradas reducen el tiempo necesario para escanear y leer datos. Utiliza técnicas de deep learning para lograrlo. Puedes encontrar más detalles en esta documentación.
- Las actualizaciones aceleradas reducen la cantidad de datos que necesitan ser reescritos durante actualizaciones, eliminaciones y fusiones. Predictive I/O aprovecha los deletion vectors para acelerar las actualizaciones reduciendo la frecuencia de reescrituras completas de archivos durante la modificación de datos en tablas Delta. Predictive I/O optimiza las operaciones
DELETE,MERGEyUPDATE. Puedes encontrar más detalles en esta documentación.
Predictive I/O es exclusivo del motor Photon en Databricks.
Gestión inteligente de cargas de trabajo (IWM)
Uno de los principales puntos débiles de los administradores de plataformas técnicas es gestionar diferentes almacenes para cargas de trabajo pequeñas y grandes y asegurarse de que el código esté optimizado y ajustado para ejecutarse de manera óptima y aprovechar al máximo la capacidad de la infraestructura de cómputo. IWM es un conjunto de funcionalidades que ayuda con los desafíos anteriores y permite ejecutar estas cargas de trabajo más rápido manteniendo los costos bajos. Lo logra analizando patrones en tiempo real y asegurando que las cargas de trabajo tengan la cantidad óptima de cómputo para ejecutar las sentencias SQL entrantes sin interrumpir las consultas ya en ejecución.
La base correcta de FinOps, a través de etiquetado, políticas e informes, es crucial para la transparencia y el ROI de tu Plataforma de Inteligencia de Datos. Te ayuda a obtener valor comercial más rápido y a construir una empresa más exitosa.
Utiliza serverless y DatabricksIQ para una configuración rápida, eficiencia de costos y optimizaciones automáticas que se adaptan a tus patrones de carga de trabajo. Esto conduce a un TCO más bajo, mejor confiabilidad y operaciones más simples y rentables.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.