Presentamos Databricks Lakeflow: una solución unificada e inteligente para la ingeniería de datos
Ingiera datos de bases de datos, aplicaciones empresariales y orígenes en la nube, transfórmelos en lotes y en streaming en tiempo real, y despliegue y opere con confianza en producción.
por Michael Armbrust y Bilal Aslam
Hoy, nos complace anunciar Databricks Lakeflow, una nueva solución que contiene todo lo que necesita para crear y operar canalizaciones de datos de producción. Incluye nuevos conectores nativos y altamente escalables para bases de datos como SQL Server y para aplicaciones empresariales como Salesforce, Workday, Google Analytics, ServiceNow y SharePoint. Los usuarios pueden transformar datos en lotes y en streaming utilizando SQL y Python estándar. También anunciamos el Modo en Tiempo Real para Apache Spark, que permite el procesamiento de flujos de datos con latencias órdenes de magnitud más rápidas que el microbatch. Finalmente, puede orquestar y supervisar flujos de trabajo e implementar en producción utilizando CI/CD. Databricks Lakeflow es nativo de la Plataforma de Inteligencia de Datos, proporcionando cómputo sin servidor y gobernanza unificada con Unity Catalog.

En esta entrada de blog, analizamos las razones por las que creemos que Lakeflow ayudará a los equipos de datos a satisfacer la creciente demanda de datos e IA fiables, así como las capacidades clave de Lakeflow integradas en una única experiencia de producto.
Desafíos en la creación y operación de canalizaciones de datos fiables
La ingeniería de datos —recopilar y preparar datos frescos, de alta calidad y fiables— es un ingrediente necesario para democratizar los datos y la IA en su negocio. Sin embargo, lograr esto sigue estando lleno de complejidad y requiere unir muchas herramientas diferentes.
En primer lugar, los equipos de datos necesitan ingerir datos de múltiples sistemas, cada uno con sus propios formatos y métodos de acceso. Esto requiere crear y mantener conectores internos para bases de datos y aplicaciones empresariales. Mantenerse al día con los cambios de API de las aplicaciones empresariales puede ser un trabajo a tiempo completo para todo un equipo de datos. Luego, los datos deben prepararse tanto en lotes como en streaming, lo que requiere escribir y mantener una lógica compleja para la activación y el procesamiento incremental. Cuando la latencia aumenta o ocurre una falla, significa recibir una alerta, un conjunto de consumidores de datos insatisfechos e incluso interrupciones en el negocio que afectan los resultados. Finalmente, los equipos de datos necesitan implementar estas canalizaciones utilizando CI/CD y supervisar la calidad y el linaje de los activos de datos. Esto normalmente requiere implementar, aprender y administrar otra herramienta completamente nueva como Prometheus o Grafana.
Es por eso que decidimos crear Lakeflow, una solución unificada para la ingesta, transformación y orquestación de datos impulsada por la inteligencia de datos. Sus tres componentes clave son: Lakeflow Connect, Lakeflow Pipelines y Lakeflow Jobs.
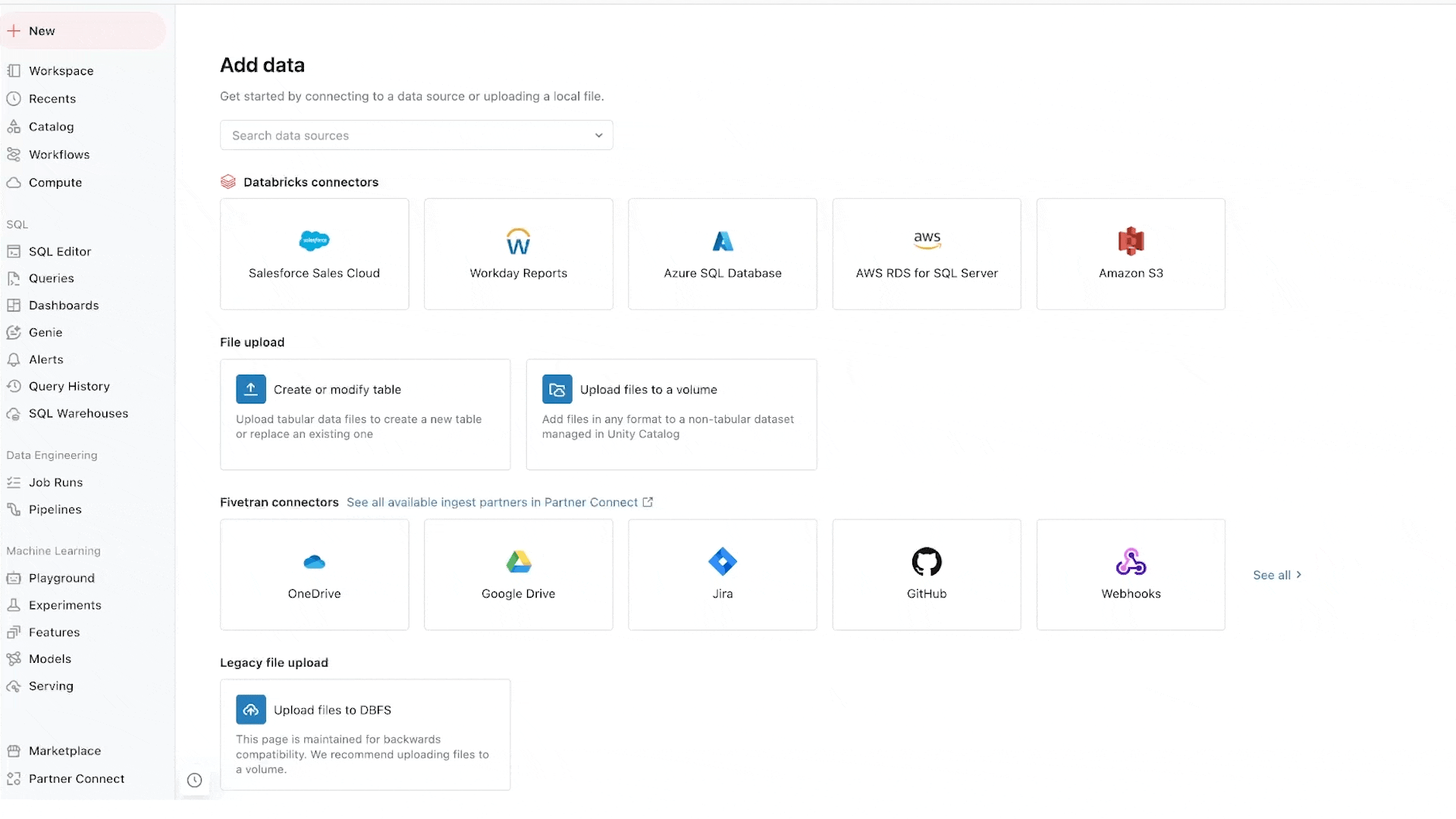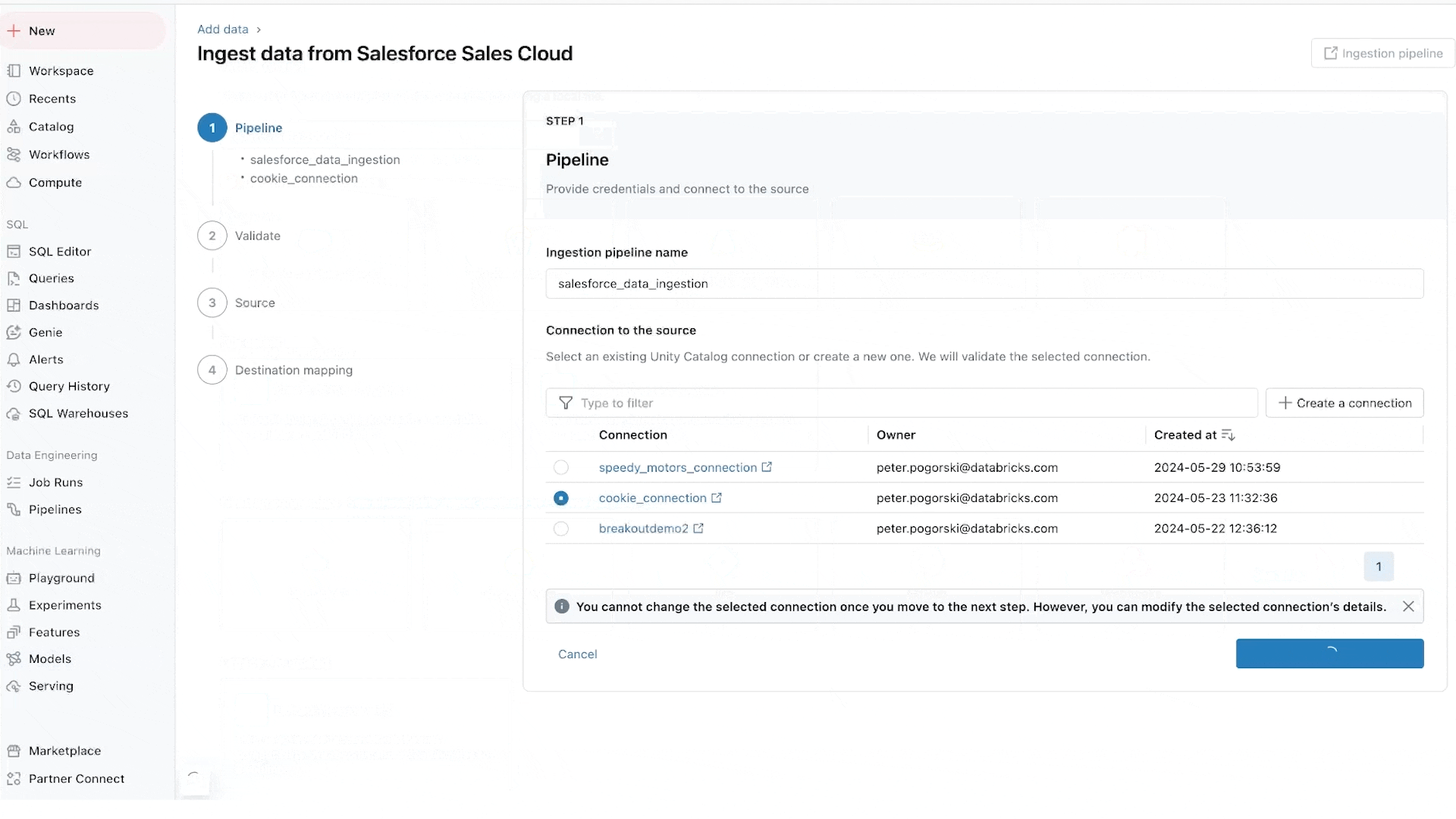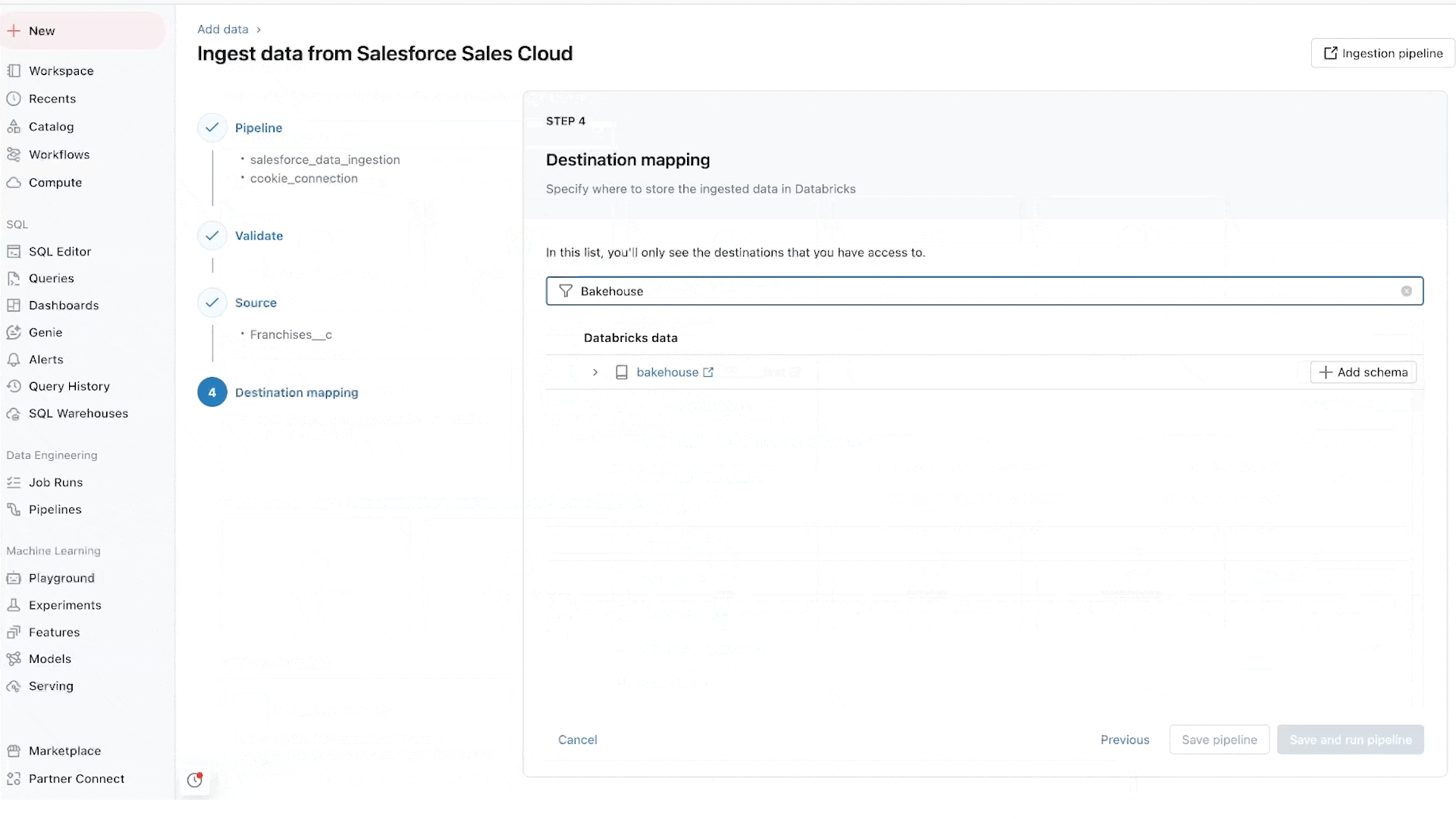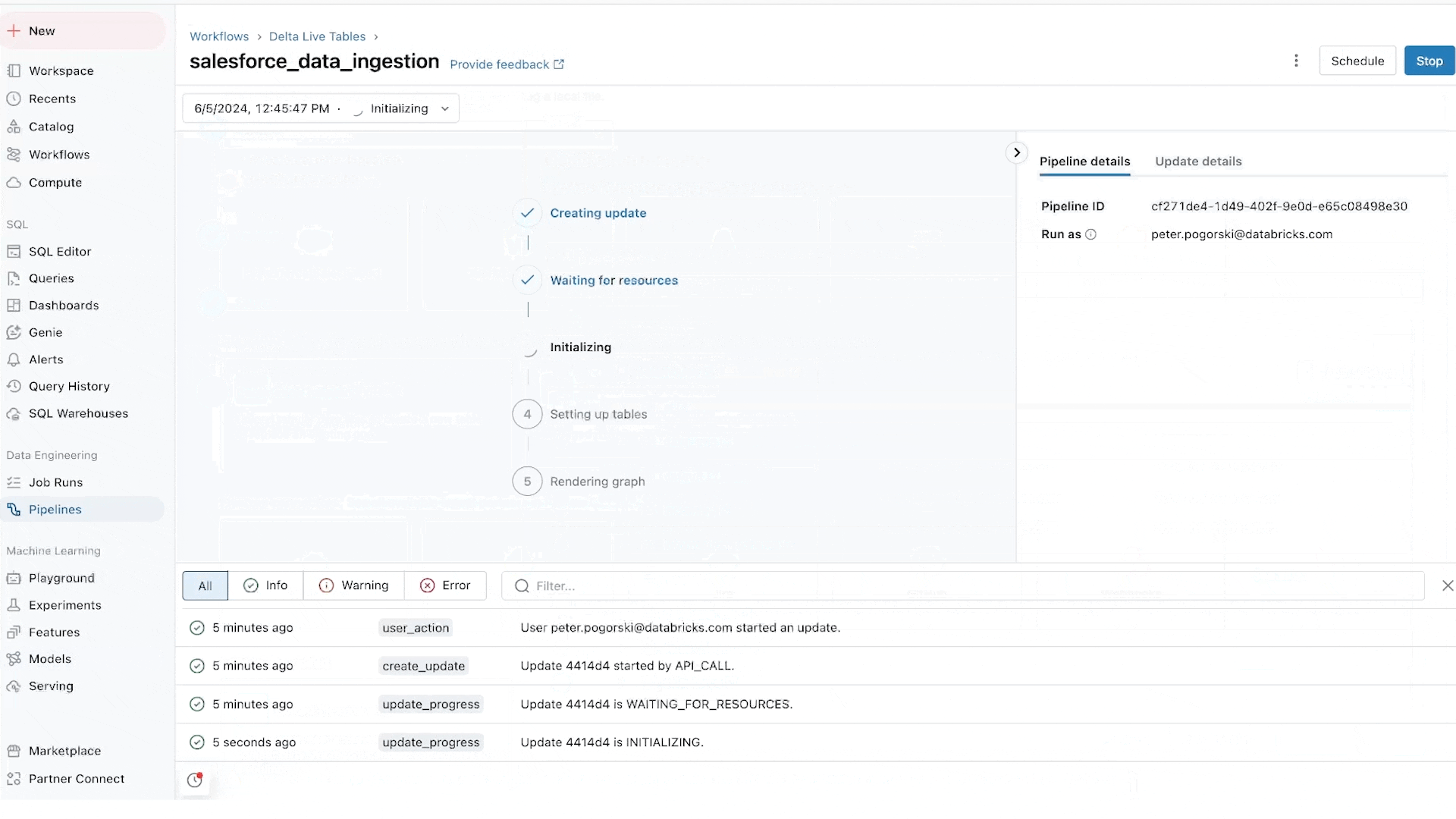
Lakeflow Connect: Ingesta de datos sencilla y escalable
Lakeflow Connect proporciona ingesta de datos punto a punto de bases de datos como SQL Server y aplicaciones empresariales como Salesforce, Workday, Google Analytics y ServiceNow. La hoja de ruta también incluye bases de datos como MySQL, Postgres y Oracle, así como aplicaciones empresariales como NetSuite, Dynamics 365 y Google Ads. Lakeflow Connect también puede ingerir datos no estructurados como PDF y hojas de cálculo de Excel de orígenes como SharePoint.
Complementa nuestros populares conectores nativos para almacenamiento en la nube (por ejemplo, conectores S3, ADLS Gen2 y GCS) y colas (por ejemplo, conectores Kafka, Kinesis, Event Hub y Pub/Sub), y soluciones de socios como Fivetran, Qlik e Informatica.
Estamos particularmente entusiasmados con los conectores de bases de datos, que son impulsados por nuestra adquisición de Arcion. Una cantidad increíble de datos valiosos está bloqueada en bases de datos operativas. En lugar de enfoques ingenuos para cargar estos datos, que presentan problemas operativos y de escalabilidad, Lakeflows utiliza la tecnología de captura de datos de cambios (CDC) para hacer que sea simple, fiable y operativamente eficiente llevar estos datos a su lakehouse.
Los clientes de Databricks que utilizan Lakeflow Connect encuentran que una solución de ingesta sencilla mejora la productividad y les permite avanzar más rápido de los datos a las perspectivas. Insulet, un fabricante de un sistema de gestión de insulina portátil, el Omnipod, utiliza el conector de ingesta de Salesforce para ingerir datos relacionados con los comentarios de los clientes en su solución de datos que está construida sobre Databricks. Estos datos se ponen a disposición para su análisis a través de Databricks SQL para obtener información sobre problemas de calidad y rastrear quejas de clientes. El equipo encontró un valor significativo en el uso de las nuevas capacidades de Lakeflow Connect.
"Con el nuevo conector de ingesta de Salesforce de Databricks, hemos optimizado significativamente nuestro proceso de integración de datos al eliminar middleware frágil y problemático. Esta mejora permite que Databricks SQL analice directamente los datos de Salesforce dentro de Databricks. Como resultado, nuestros profesionales de datos ahora pueden ofrecer información actualizada en tiempo casi real, reduciendo la latencia de días a minutos." —Bill Whiteley, Director Senior de IA, Análisis y Algoritmos Avanzados, Insulet
Lakeflow Pipelines: Canalizaciones de datos declarativas eficientes
Lakeflow Pipelines reduce la complejidad de crear y gestionar canalizaciones de datos por lotes y en streaming eficientes. Construidas sobre el marco declarativo Delta Live Tables, le liberan para escribir lógica de negocio en SQL y Python, mientras que Databricks automatiza la orquestación de datos, el procesamiento incremental y la autoscalabilidad de la infraestructura de cómputo en su nombre. Además, Lakeflow Pipelines ofrece monitorización de calidad de datos integrada y su Modo en Tiempo Real le permite habilitar la entrega consistente de conjuntos de datos sensibles al tiempo con baja latencia sin ningún cambio de código.
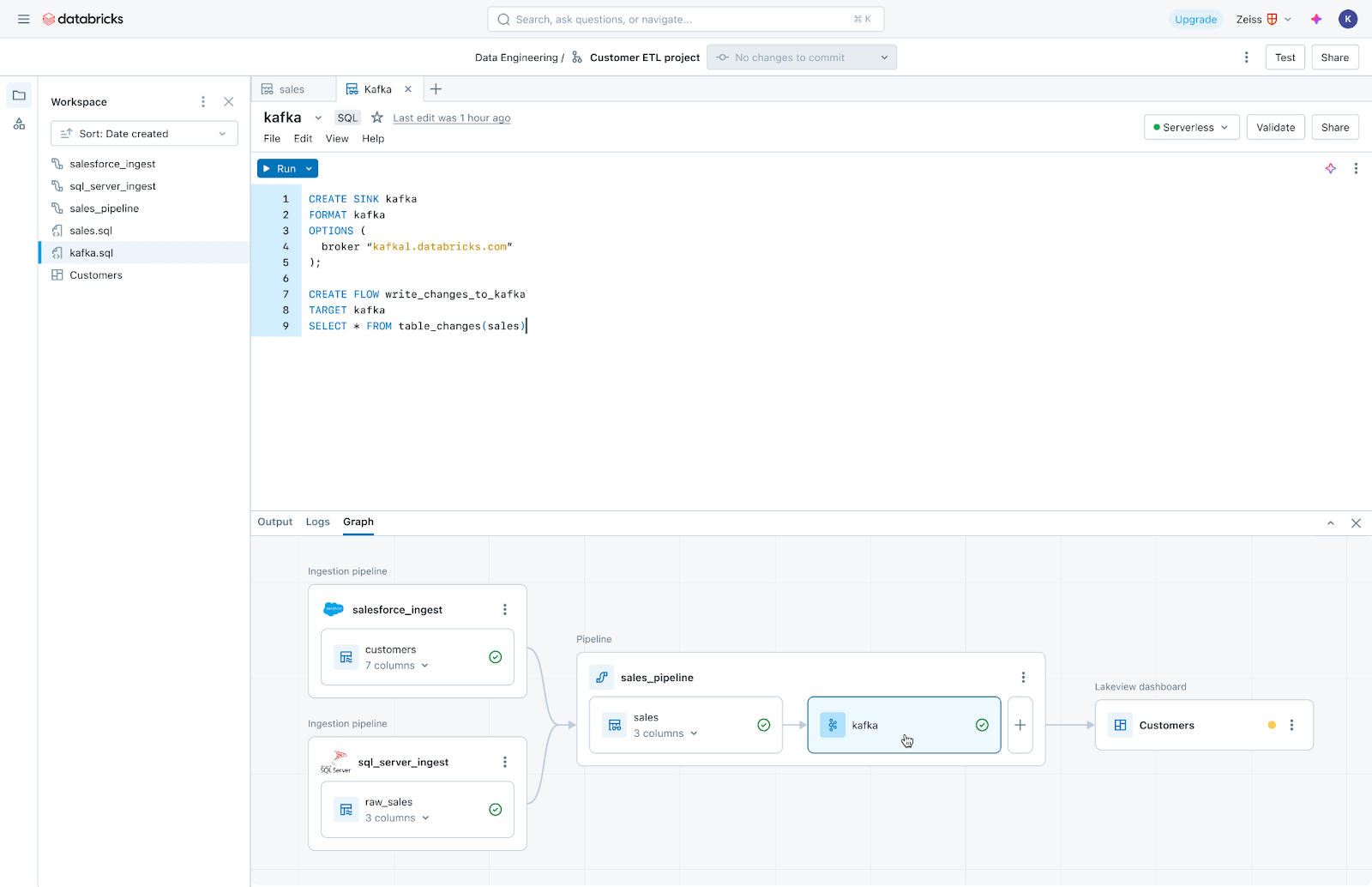
Lakeflow Jobs: Orquestación fiable para cada carga de trabajo
Lakeflow Jobs orquesta y supervisa de forma fiable las cargas de trabajo de producción. Construido sobre las capacidades avanzadas de Databricks Workflows, orquesta cualquier carga de trabajo, incluyendo ingesta, canalizaciones, notebooks, consultas SQL, entrenamiento de modelos de machine learning, despliegue de modelos e inferencia. Los equipos de datos también pueden aprovechar desencadenadores, ramificaciones y bucles para satisfacer casos de uso complejos de entrega de datos.
Lakeflow Jobs también automatiza y simplifica el proceso de comprensión y seguimiento de la salud y entrega de datos. Adopta una vista centrada en los datos de la salud, proporcionando a los equipos de datos un linaje completo que incluye las relaciones entre la ingesta, las transformaciones, las tablas y los paneles. Además, rastrea la frescura y la calidad de los datos, permitiendo a los equipos de datos agregar monitores a través de Lakehouse Monitoring con solo hacer clic en un botón.
Construido sobre la Plataforma de Inteligencia de Datos
Databricks Lakeflow está integrado de forma nativa con nuestra Plataforma de Inteligencia de Datos, que aporta estas capacidades:
- Inteligencia de datos: La inteligencia impulsada por IA no es solo una característica de Lakeflow, es una capacidad fundamental que toca todos los aspectos del producto. Databricks Assistant potencia el descubrimiento, la creación y la supervisión de canalizaciones de datos, para que pueda dedicar más tiempo a crear datos fiables.
- Gobernanza unificada: Lakeflow también está profundamente integrado con Unity Catalog, que potencia el linaje y la calidad de los datos.
- Cómputo sin servidor: Cree y orqueste canalizaciones a escala y ayude a su equipo a centrarse en el trabajo sin tener que preocuparse por la infraestructura.
El futuro de la ingeniería de datos es sencillo, unificado e inteligente
Creemos que Lakeflow permitirá a nuestros clientes ofrecer datos más frescos, completos y de mayor calidad a sus negocios. Lakeflow entrará pronto en vista previa comenzando con Lakeflow Connect. Si desea solicitar acceso, regístrese aquí. Durante los próximos meses, espere más anuncios de Lakeflow a medida que estén disponibles capacidades adicionales.
¿Quiere verlo en acción?
Pruebe el Tour del Producto Lakeflow para ingerir, transformar y desplegar datos sin problemas desde múltiples orígenes tanto en lotes como en tiempo real a producción.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.