Presentamos DBRX: Un Nuevo LLM Abierto de Vanguardia
Hoy, nos complace presentar DBRX, un LLM de propósito general y de código abierto creado por Databricks. En una variedad de benchmarks estándar, DBRX establece un nuevo estado del arte para LLMs de código abierto establecidos. Además, proporciona a la comunidad de código abierto y a las empresas que desarrollan sus propios LLMs capacidades que antes estaban limitadas a las APIs de modelos cerrados; según nuestras mediciones, supera a GPT-3.5 y es competitivo con Gemini 1.0 Pro. Es un modelo de código especialmente capaz, que supera a modelos especializados como CodeLLaMA-70B en programación, además de su fortaleza como LLM de propósito general.
Esta calidad de vanguardia viene con mejoras notables en el rendimiento de entrenamiento e inferencia. DBRX avanza el estado del arte en eficiencia entre los modelos de código abierto gracias a su arquitectura de mezcla de expertos (MoE) de grano fino. La inferencia es hasta 2 veces más rápida que LLaMA2-70B, y DBRX es aproximadamente el 40% del tamaño de Grok-1 en términos de recuentos de parámetros totales y activos. Cuando se aloja en Databricks Model Serving, DBRX puede generar texto a hasta 150 tok/s/usuario. Nuestros clientes encontrarán que entrenar MoEs también es aproximadamente 2 veces más eficiente en FLOPs que entrenar modelos densos para la misma calidad de modelo final. De principio a fin, nuestra receta general para DBRX (incluyendo los datos de preentrenamiento, la arquitectura del modelo y la estrategia de optimización) puede igualar la calidad de nuestros modelos MPT de generación anterior con casi 4 veces menos cómputo.
Los pesos del modelo base (DBRX Base) y el modelo afinado (DBRX Instruct) están disponibles en Hugging Face bajo una licencia abierta. A partir de hoy, DBRX está disponible para que los clientes de Databricks lo usen a través de APIs, y los clientes de Databricks pueden preentrenar sus propios modelos de clase DBRX desde cero o continuar entrenando sobre uno de nuestros checkpoints utilizando las mismas herramientas y ciencia que usamos para construirlo. DBRX ya se está integrando en nuestros productos impulsados por GenAI, donde, en aplicaciones como SQL, los lanzamientos tempranos han superado a GPT-3.5 Turbo y están desafiando a GPT-4 Turbo. También es un modelo líder entre los modelos de código abierto y GPT-3.5 Turbo en tareas de RAG.
Entrenar modelos de mezcla de expertos es difícil. Tuvimos que superar una variedad de desafíos científicos y de rendimiento para construir un pipeline lo suficientemente robusto como para entrenar modelos de clase DBRX de manera repetible y eficiente. Ahora que lo hemos hecho, tenemos una pila de entrenamiento única que permite a cualquier empresa entrenar modelos fundacionales de MoE de clase mundial desde cero. Esperamos compartir esa capacidad con nuestros clientes y compartir nuestras lecciones aprendidas con la comunidad.
Descarga DBRX hoy mismo desde Hugging Face (DBRX Base, DBRX Instruct), o prueba DBRX Instruct en nuestro HF Space, o consulta nuestro repositorio de modelos en github: databricks/dbrx.
¿Qué es DBRX?
DBRX es un modelo de lenguaje grande (LLM) de solo decodificador basado en transformer que fue entrenado usando predicción del siguiente token. Utiliza una arquitectura de mezcla de expertos (MoE) de grano fino con 132 mil millones de parámetros totales de los cuales 36 mil millones de parámetros están activos en cualquier entrada. Fue preentrenado en 12 billones de tokens de datos de texto y código. En comparación con otros modelos MoE de código abierto como Mixtral y Grok-1, DBRX es de grano fino, lo que significa que utiliza un mayor número de expertos más pequeños. DBRX tiene 16 expertos y elige 4, mientras que Mixtral y Grok-1 tienen 8 expertos y eligen 2. Esto proporciona 65 veces más combinaciones posibles de expertos y encontramos que esto mejora la calidad del modelo. DBRX utiliza codificaciones de posición rotatoria (RoPE), unidades lineales con puerta (GLU) y atención de consulta agrupada (GQA). Utiliza el tokenizador GPT-4 tal como se proporciona en el repositorio tiktoken. Tomamos estas decisiones basándonos en evaluaciones exhaustivas y experimentos de escalado.
DBRX fue preentrenado en 12 billones de tokens de datos cuidadosamente curados y una longitud de contexto máxima de 32k tokens. Estimamos que estos datos son al menos 2 veces mejores token por token que los datos que utilizamos para preentrenar la familia de modelos MPT. Este nuevo conjunto de datos se desarrolló utilizando el conjunto completo de herramientas de Databricks, incluyendo Apache Spark™ y Databricks notebooks para el procesamiento de datos, Unity Catalog para la gestión y gobernanza de datos, y MLflow para el seguimiento de experimentos. Utilizamos aprendizaje curricular para el preentrenamiento, cambiando la mezcla de datos durante el entrenamiento de maneras que encontramos que mejoran sustancialmente la calidad del modelo.
Calidad en Benchmarks vs. Modelos Abiertos Líderes
La Tabla 1 muestra la calidad de DBRX Instruct y los modelos abiertos establecidos líderes. DBRX Instruct es el modelo líder en benchmarks compuestos, benchmarks de programación y matemáticas, y MMLU. Supera a todos los modelos de chat o instrucción afinados en benchmarks estándar.
Benchmarks compuestos. Evaluamos DBRX Instruct y sus pares en dos benchmarks compuestos: la Hugging Face Open LLM Leaderboard (el promedio de ARC-Challenge, HellaSwag, MMLU, TruthfulQA, WinoGrande y GSM8k) y el Databricks Model Gauntlet (un conjunto de más de 30 tareas que abarcan seis categorías: conocimiento del mundo, razonamiento de sentido común, comprensión del lenguaje, comprensión de lectura, resolución de problemas simbólicos y programación).
Entre los modelos que evaluamos, DBRX Instruct obtiene la puntuación más alta en dos benchmarks compuestos: la Hugging Face Open LLM Leaderboard (74.5% vs. 72.7% para el siguiente modelo más alto, Mixtral Instruct) y el Databricks Gauntlet (66.8% vs. 60.7% para el siguiente modelo más alto, Mixtral Instruct).
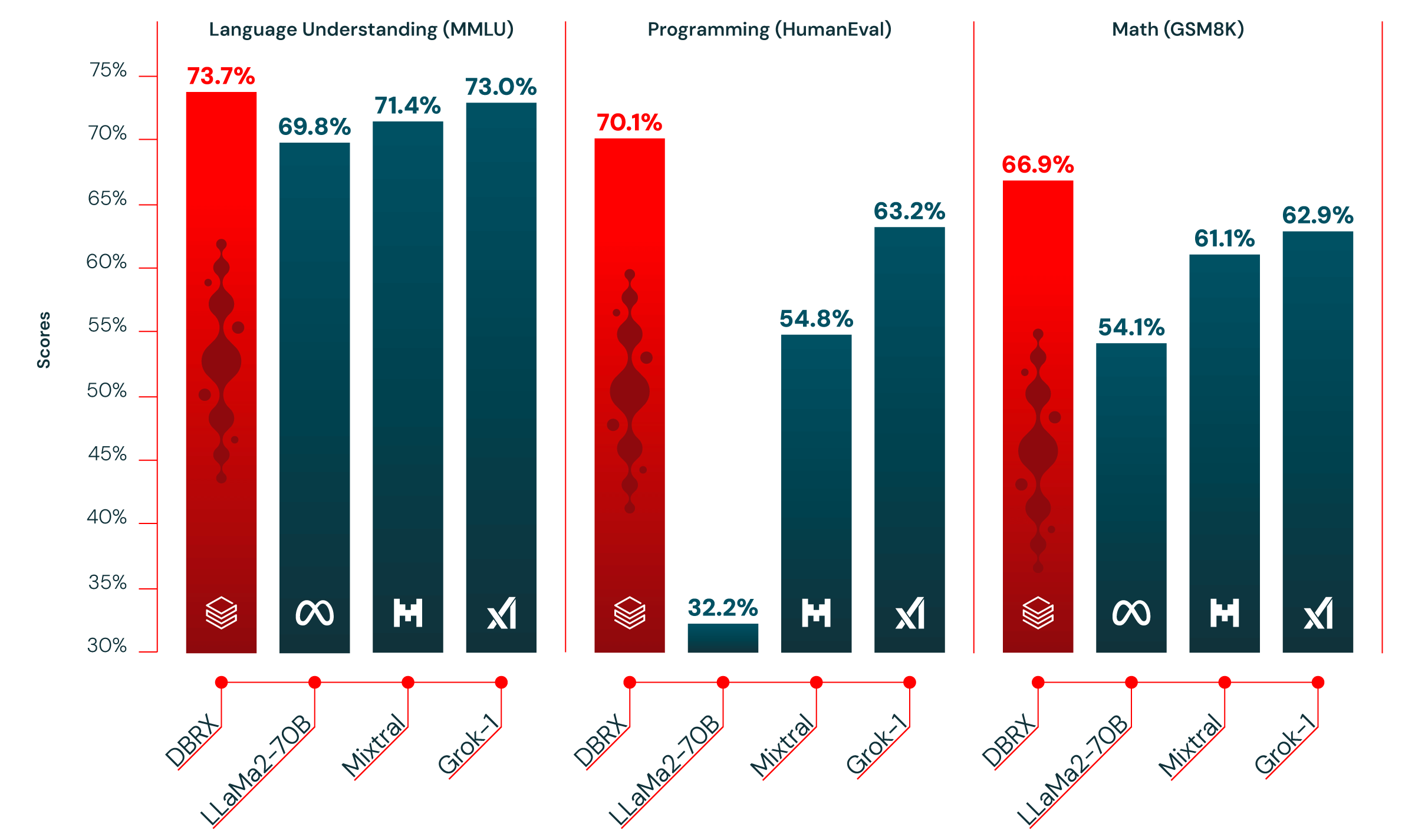
Programación y matemáticas. DBRX Instruct es especialmente fuerte en programación y matemáticas. Obtiene una puntuación más alta que los otros modelos de código abierto que evaluamos en HumanEval (70.1% vs. 63.2% para Grok-1, 54.8% para Mixtral Instruct y 32.2% para la variante LLaMA2-70B de mejor rendimiento) y GSM8k (66.9% vs. 62.9% para Grok-1, 61.1% para Mixtral Instruct y 54.1% para la variante LLaMA2-70B de mejor rendimiento). DBRX supera a Grok-1, el siguiente mejor modelo en estos benchmarks, a pesar de que Grok-1 tiene 2.4 veces más parámetros. En HumanEval, DBRX Instruct incluso supera a CodeLLaMA-70B Instruct, un modelo construido explícitamente para programación, a pesar de que DBRX Instruct está diseñado para uso de propósito general (70.1% vs. 67.8% en HumanEval según lo informado por Meta en el blog de CodeLLaMA).
MMLU. DBRX Instruct obtiene una puntuación más alta que todos los demás modelos que consideramos en MMLU, alcanzando el 73.7%.
Tabla 1. Calidad de DBRX Instruct y modelos abiertos líderes. Consulte las notas al pie para obtener detalles sobre cómo se recopilaron los números. En negrita y subrayado se encuentra la puntuación más alta.
Calidad en Benchmarks vs. Modelos Cerrados Líderes
La Tabla 2 muestra la calidad de DBRX Instruct y los modelos cerrados líderes. Según las puntuaciones reportadas por cada creador de modelos, DBRX Instruct supera a GPT-3.5 (como se describe en el paper de GPT-4), y es competitivo con Gemini 1.0 Pro y Mistral Medium.
En casi todos los benchmarks que consideramos, DBRX Instruct supera o, en el peor de los casos, iguala a GPT-3.5. DBRX Instruct supera a GPT-3.5 en conocimiento general medido por MMLU (73.7% vs. 70.0%) y razonamiento de sentido común medido por HellaSwag (89.0% vs. 85.5%) y WinoGrande (81.8% vs. 81.6%). DBRX Instruct brilla especialmente en programación y razonamiento matemático medido por HumanEval (70.1% vs. 48.1%) y GSM8k (72.8% vs. 57.1%).
DBRX Instruct es competitivo con Gemini 1.0 Pro y Mistral Medium. Las puntuaciones de DBRX Instruct son más altas que las de Gemini 1.0 Pro en Inflection Corrected MTBench, MMLU, HellaSwag y HumanEval, mientras que Gemini 1.0 Pro es más fuerte en GSM8k. Las puntuaciones de DBRX Instruct y Mistral Medium son similares en HellaSwag, mientras que Mistral Medium es más fuerte en Winogrande y MMLU, y DBRX Instruct es más fuerte en HumanEval, GSM8k e Inflection Corrected MTBench.
Tabla 2. Calidad de DBRX Instruct y modelos cerrados líderes. Aparte de Inflection Corrected MTBench (que medimos nosotros mismos en los puntos de acceso del modelo), las cifras se informaron según lo indicado por los creadores de estos modelos en sus respectivos documentos técnicos. Consulte las notas al pie para obtener detalles adicionales.
Calidad en Tareas de Contexto Largo y RAG
DBRX Instruct se entrenó con una ventana de contexto de hasta 32K tokens. La Tabla 3 compara su rendimiento con el de Mixtral Instruct y las últimas versiones de las API de GPT-3.5 Turbo y GPT-4 Turbo en un conjunto de benchmarks de contexto largo (Pares Clave-Valor del artículo Lost in the Middle y HotpotQAXL, una versión modificada de HotPotQA que extiende la tarea a longitudes de secuencia más largas). GPT-4 Turbo es generalmente el mejor modelo en estas tareas. Sin embargo, con una excepción, DBRX Instruct se desempeña mejor que GPT-3.5 Turbo en todas las longitudes de contexto y en todas las partes de la secuencia. El rendimiento general de DBRX Instruct y Mixtral Instruct es similar.
% | ||||
% | ||||
% | ||||
Tabla 3. El rendimiento promedio de los modelos en los benchmarks KV-Pairs y HotpotQAXL. En negrita se indica la puntuación más alta. Subrayado se indica la puntuación más alta, excluyendo GPT-4 Turbo. GPT-3.5 Turbo admite una longitud de contexto máxima de 16K, por lo que no pudimos evaluarlo a 32K. *Los promedios para el principio, medio y final de la secuencia para GPT-3.5 Turbo incluyen solo contextos de hasta 16K.
Una de las formas más populares de aprovechar el contexto de un modelo es la generación aumentada por recuperación (RAG). En RAG, el contenido relevante para una indicación se recupera de una base de datos y se presenta junto con la indicación para dar al modelo más información de la que tendría de otro modo. La Tabla 4 muestra la calidad de DBRX en dos benchmarks de RAG — Natural Questions y HotPotQA — cuando al modelo también se le proporcionan los 10 pasajes principales recuperados de un corpus de artículos de Wikipedia utilizando el modelo de incrustación bge-large-en-v1.5. DBRX Instruct es competitivo con modelos abiertos como Mixtral Instruct y LLaMA2-70B Chat y la versión actual de GPT-3.5 Turbo.
Tabla 4. El rendimiento de los modelos medido cuando a cada modelo se le dan los 10 pasajes principales recuperados de un corpus de Wikipedia usando bge-large-en-v1.5. La precisión se mide comparando la respuesta del modelo. En negrita está la puntuación más alta. Subrayado está la puntuación más alta aparte de GPT-4 Turbo.
Eficiencia de Entrenamiento
La calidad del modelo debe considerarse junto con la eficiencia con la que se entrena y se usa. Esto es especialmente cierto en Databricks, donde creamos modelos como DBRX para establecer un proceso para que nuestros clientes entrenen sus propios modelos fundacionales.
Descubrimos que entrenar modelos de mezcla de expertos (mixture-of-experts) proporciona mejoras sustanciales en la eficiencia de cómputo para el entrenamiento (Tabla 5). Por ejemplo, entrenar un miembro más pequeño de la familia DBRX llamado DBRX MoE-B (23.5B parámetros totales, 6.6B parámetros activos) requirió 1.7 veces menos FLOPs para alcanzar una puntuación del 45.5% en el Databricks LLM Gauntlet que los que necesitó LLaMA2-13B para alcanzar el 43.8%. DBRX MoE-B también contiene la mitad de parámetros activos que LLaMA2-13B.
Mirando de forma integral, nuestro pipeline de preentrenamiento de LLM de extremo a extremo se ha vuelto casi 4 veces más eficiente en cómputo en los últimos diez meses. El 5 de mayo de 2023, lanzamos MPT-7B, un modelo de 7B parámetros entrenado en 1T tokens que alcanzó una puntuación de 30.9% en el Databricks LLM Gauntlet. Un miembro de la familia DBRX llamado DBRX MoE-A (7.7B parámetros totales, 2.2B parámetros activos) alcanzó una puntuación de 30.5% en el Databricks Gauntlet con 3.7 veces menos FLOPs. Esta eficiencia es el resultado de varias mejoras, que incluyen el uso de una arquitectura MoE, otros cambios arquitectónicos en la red, mejores estrategias de optimización, mejor tokenización y, muy importante, mejores datos de preentrenamiento.
Por sí sola, una mejor calidad de datos de preentrenamiento tuvo un impacto sustancial en la calidad del modelo. Entrenamos un modelo de 7B con 1T tokens (llamado DBRX Dense-A) usando los datos de preentrenamiento de DBRX. Alcanzó un 39.0% en el Databricks Gauntlet en comparación con el 30.9% de MPT-7B. Estimamos que nuestros nuevos datos de preentrenamiento son al menos 2 veces mejores por token que los datos utilizados para entrenar MPT-7B. En otras palabras, estimamos que se necesitan la mitad de tokens para alcanzar la misma calidad de modelo. Determinamos esto entrenando DBRX Dense-A con 500B tokens; superó a MPT-7B en el Databricks Gauntlet, alcanzando el 32.1%. Además de una mejor calidad de datos, otro contribuyente importante a esta eficiencia de tokens puede ser el tokenizador GPT-4, que tiene un vocabulario grande y se cree que es especialmente eficiente en tokens. Estas lecciones sobre la mejora de la calidad de los datos se traducen directamente en prácticas y herramientas que nuestros clientes utilizan para entrenar modelos fundacionales con sus propios datos.
Tabla 5. Detalles de varios artículos de prueba que utilizamos para validar la eficiencia de entrenamiento de la arquitectura DBRX MoE y el pipeline de entrenamiento de extremo a extremo
Eficiencia de Inferencia
La Figura 2 muestra la eficiencia de inferencia de extremo a extremo al servir DBRX y modelos similares usando NVIDIA TensorRT-LLM con nuestra infraestructura de servicio optimizada y precisión de 16 bits. Nuestro objetivo es que este benchmark refleje el uso en el mundo real lo más fielmente posible, incluyendo múltiples usuarios golpeando el mismo servidor de inferencia simultáneamente. Generamos un nuevo usuario por segundo, cada solicitud de usuario contiene un prompt de aproximadamente 2000 tokens y cada respuesta consta de 256 tokens.
En general, los modelos MoE son más rápidos en inferencia de lo que sugeriría su recuento total de parámetros. Esto se debe a que utilizan relativamente pocos parámetros para cada entrada. Descubrimos que DBRX no es una excepción en este aspecto. El rendimiento de inferencia de DBRX es 2-3 veces mayor que el de un modelo no-MoE de 132B.
La eficiencia de inferencia y la calidad del modelo suelen estar en tensión: los modelos más grandes suelen alcanzar mayor calidad, pero los modelos más pequeños son más eficientes para la inferencia. El uso de una arquitectura MoE hace posible lograr mejores compensaciones entre la calidad del modelo y la eficiencia de inferencia que los modelos densos suelen lograr. Por ejemplo, DBRX tiene mayor calidad que LLaMA2-70B y, gracias a tener aproximadamente la mitad de parámetros activos, el rendimiento de inferencia de DBRX es hasta 2 veces más rápido (Figura 2). Mixtral es otro punto en la frontera de Pareto mejorada alcanzada por los modelos MoE: es más pequeño que DBRX, y en consecuencia tiene menor calidad, pero alcanza un mayor rendimiento de inferencia. Los usuarios de las APIs de Databricks Foundation Model pueden esperar ver hasta 150 tokens por segundo para DBRX en nuestra plataforma de servicio de modelos optimizada con cuantización de 8 bits.

Cómo Construimos DBRX
DBRX fue entrenado en 3072 NVIDIA H100s conectados por 3.2Tbps Infiniband. El proceso principal de construcción de DBRX, incluyendo preentrenamiento, postentrenamiento, evaluación, red-teaming y refinamiento, tuvo lugar durante tres meses. Fue la continuación de meses de ciencia, investigación de datasets y experimentos de escalado, sin mencionar años de desarrollo de LLM en Databricks que incluyen los proyectos MPT y Dolly y los miles de modelos que hemos construido y puesto en producción con nuestros clientes.
Para construir DBRX, aprovechamos el mismo conjunto de herramientas de Databricks que están disponibles para nuestros clientes. Gestionamos y gobernamos nuestros datos de entrenamiento usando Unity Catalog. Exploramos estos datos usando el recién adquirido Lilac AI. Procesamos y limpiamos estos datos usando Apache Spark™ y notebooks de Databricks. Entrenamos DBRX usando versiones optimizadas de nuestras bibliotecas de entrenamiento de código abierto: MegaBlocks, LLM Foundry, Composer y Streaming. Gestionamos el entrenamiento y ajuste fino de modelos a gran escala en miles de GPUs usando nuestro servicio de Entrenamiento Databricks. Registramos nuestros resultados usando MLflow. Recopilamos feedback humano para mejoras de calidad y seguridad a través de Databricks Model Serving e Inference Tables. Experimentamos manualmente con el modelo usando el Databricks Playground. Encontramos que las herramientas de Databricks son de primera clase para cada uno de sus propósitos, y nos beneficiamos del hecho de que todas formaban parte de una experiencia de producto unificada.
Comienza con DBRX en Databricks
Si buscas empezar a trabajar con DBRX de inmediato, es fácil hacerlo con las APIs de Databricks Foundation Model APIs. Puedes empezar rápidamente con nuestros precios de pago por uso y consultar el modelo desde nuestra interfaz de chat AI Playground. Para aplicaciones de producción, ofrecemos una opción de rendimiento aprovisionado para proporcionar garantías de rendimiento, soporte para modelos ajustados y seguridad y cumplimiento adicionales. Para alojar DBRX de forma privada, puedes descargar el modelo desde el Databricks Marketplace y desplegar el modelo en Model Serving.
Conclusiones
En Databricks, creemos que cada empresa debería tener la capacidad de controlar sus datos y su destino en el mundo emergente de GenAI. DBRX es un pilar central de nuestra próxima generación de productos GenAI, y esperamos con ansias el emocionante viaje que espera a nuestros clientes mientras aprovechan las capacidades de DBRX y las herramientas que utilizamos para construirlo. En el último año, hemos entrenado miles de LLMs con nuestros clientes. DBRX es solo un ejemplo de los modelos potentes y eficientes que se construyen en Databricks para una amplia gama de aplicaciones, desde características internas hasta casos de uso ambiciosos para nuestros clientes.
Como con cualquier modelo nuevo, el viaje con DBRX es solo el comienzo, y el mejor trabajo lo harán aquellos que construyan sobre él: empresas y la comunidad abierta. Este es también solo el comienzo de nuestro trabajo en DBRX, y debes esperar mucho más por venir.
Contribuciones
El desarrollo de DBRX fue liderado por el equipo Mosaic, que previamente construyó la familia de modelos MPT, en colaboración con docenas de ingenieros, abogados, especialistas en adquisiciones y finanzas, gerentes de programas, especialistas en marketing, diseñadores y otros colaboradores de Databricks. Agradecemos a nuestros colegas, amigos, familiares y a la comunidad por su paciencia y apoyo durante los últimos meses.
Al crear DBRX, nos apoyamos en los gigantes de la comunidad abierta y académica. Al poner DBRX a disposición de forma abierta, pretendemos reinvertir en la comunidad con la esperanza de que construyamos tecnologías aún mayores juntos en el futuro. Teniendo esto en cuenta, agradecemos sinceramente el trabajo y la colaboración de Trevor Gale y su proyecto MegaBlocks (el asesor de doctorado de Trevor es el CTO de Databricks, Matei Zaharia), el equipo de PyTorch y el proyecto FSDP, NVIDIA y el proyecto TensorRT-LLM, el equipo y proyecto vLLM, EleutherAI y su proyecto de evaluación de LLM, Daniel Smilkov y Nikhil Thorat en Lilac AI, y nuestros amigos del Allen Institute for Artificial Intelligence (AI2).
Acerca de Databricks
Databricks es la empresa de Datos e IA. Más de 10.000 organizaciones en todo el mundo —incluyendo Comcast, Condé Nast, Grammarly y más del 50% de las empresas Fortune 500— confían en la Plataforma de Inteligencia de Datos de Databricks para unificar y democratizar datos, análisis e IA. Databricks tiene su sede en San Francisco, con oficinas en todo el mundo, y fue fundada por los creadores originales de Lakehouse, Apache Spark™, Delta Lake y MLflow. Para obtener más información, sigue a Databricks en LinkedIn, X y Facebook.
1 Números según lo informado por xAI. Debido a la falta de un checkpoint compatible con Hugging Face en el momento del lanzamiento, no pudimos evaluar Grok-1 nosotros mismos en nuestro conjunto completo de benchmarks.
2 DBRX fue medido por nosotros usando el EleutherAI Harness. Todos los demás números fueron según lo informado en la Tabla de Clasificación de LLM Abiertos de Hugging Face.
3 DBRX fue medido por nosotros usando el EleutherAI Harness con el mismo commit antiguo que se utiliza en la Tabla de Clasificación de LLM Abiertos de Hugging Face. Todos los demás números fueron según lo informado en la Tabla de Clasificación de LLM Abiertos de Hugging Face. Tenga en cuenta que al usar el último commit del EleutherAI Harness, que incluye varias correcciones de análisis, la puntuación de 5-shot de DBRX en GSM8k aumenta a 72.8% según se informa en la Tabla 2. LLaMA2-70B Chat también aumenta a 48.4%.
4 Medido por Databricks usando Gauntlet v0.3.0 en LLM Foundry.
5 A menos que se indique lo contrario, medido por Databricks.
6 Este número proviene del paper de Mixtral Arxiv. Reportamos este número porque es más alto que lo que medimos al evaluar el modelo nosotros mismos (36.7%)
7 Todas las puntuaciones según lo informado en el paper de GPT-4. No pudimos recopilar Inflection Corrected MTBench porque esta versión de GPT-3.5 no está disponible. Encontramos que la versión actual de GPT-3.5 Turbo obtiene una puntuación de 8.58 ± 0.04 en Inflection Corrected MTBench en comparación con 8.39 +/- 0.08 para DBRX Instruct.
8 Todas las puntuaciones según lo informado en el paper de GPT-4. No pudimos recopilar Inflection Corrected MTBench porque esta versión de GPT-4 no está disponible. Encontramos que la versión actual de GPT-4 Turbo obtiene una puntuación de 9.27 ± 0.10 en Inflection Corrected MTBench en comparación con 8.39 +/- 0.08 para DBRX Instruct.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.