Presentamos el tipo de dato Variant en Delta Lake y Apache Spark
Procesamiento más rápido y mayor flexibilidad al trabajar con datos semiestructurados
por Kent Marten, Gene Pang, Chenhao Li y Han Xiao
Nos complace anunciar un nuevo tipo de dato llamado variant para datos semiestructurados. Variant ofrece mejoras de rendimiento de un orden de magnitud en comparación con el almacenamiento de estos datos como cadenas JSON, al tiempo que mantiene la flexibilidad para admitir esquemas altamente anidados y en evolución.
Trabajar con datos semiestructurados ha sido durante mucho tiempo una capacidad fundamental del Lakehouse. Endpoint Detection & Response (EDR), análisis de clics de anuncios y telemetría IoT son solo algunos de los casos de uso populares que dependen de datos semiestructurados. A medida que migramos cada vez más clientes de almacenes de datos propietarios, hemos escuchado que dependen del tipo de dato variant que ofrecen esos almacenes propietarios, y nos encantaría ver un estándar de código abierto para evitar cualquier dependencia.
El tipo variant abierto es el resultado de nuestra colaboración tanto con la comunidad de código abierto de Apache Spark como con la comunidad de Linux Foundation Delta Lake:
- El tipo de dato Variant, las expresiones binarias Variant y el formato de codificación binaria Variant ya se han fusionado en el código abierto de Spark. Los detalles sobre la codificación binaria se pueden revisar aquí.
- El formato de codificación binaria permite un acceso y una navegación más rápidos de los datos en comparación con las cadenas. La implementación del formato de codificación binaria Variant está empaquetada en una biblioteca de código abierto, para que pueda usarse en otros proyectos.
- El soporte para el tipo de dato Variant también es de código abierto para Delta, y el protocolo RFC se puede encontrar aquí. El soporte de Variant se incluirá en Spark 4.0 y Delta 4.0.
“Somos un defensor de la comunidad de código abierto con un enfoque en datos a través de nuestra plataforma de datos de código abierto Legend”, dijo Neema Raphael, Chief Data Officer y Head of Data Engineering en Goldman Sachs. “El lanzamiento de Open Source Variant en Spark es otro gran paso adelante para un ecosistema de datos abierto”.
Y a partir de DBR 15.3, todas las capacidades mencionadas anteriormente estarán disponibles para que nuestros clientes las utilicen.
¿Qué es Variant?
Variant es un nuevo tipo de dato para almacenar datos semiestructurados. En la vista previa pública de la próxima versión de Databricks Runtime 15.3, se admitirá la entrada y salida de datos jerárquicos a través de JSON. Sin Variant, los clientes tenían que elegir entre flexibilidad y rendimiento. Para mantener la flexibilidad, los clientes almacenaban JSON en columnas únicas como cadenas. Para ver un mejor rendimiento, los clientes aplicaban enfoques de esquematización estrictos con structs, que requieren procesos separados para mantener y actualizar con cambios de esquema. Con Variant, los clientes pueden mantener la flexibilidad (no es necesario definir un esquema explícito) y recibir un rendimiento enormemente mejorado en comparación con la consulta del JSON como una cadena.
Variant es particularmente útil cuando las fuentes JSON tienen esquemas desconocidos, cambiantes y en constante evolución. Por ejemplo, los clientes han compartido casos de uso de Endpoint Detection & Response (EDR), con la necesidad de leer y combinar registros que contienen diferentes esquemas JSON. De manera similar, para usos que involucran clics de anuncios y telemetría de aplicaciones, donde el esquema es desconocido y cambia constantemente, Variant es muy adecuado. En ambos casos, la flexibilidad del tipo de dato Variant permite que los datos se ingieran y sean eficientes sin requerir un esquema explícito.
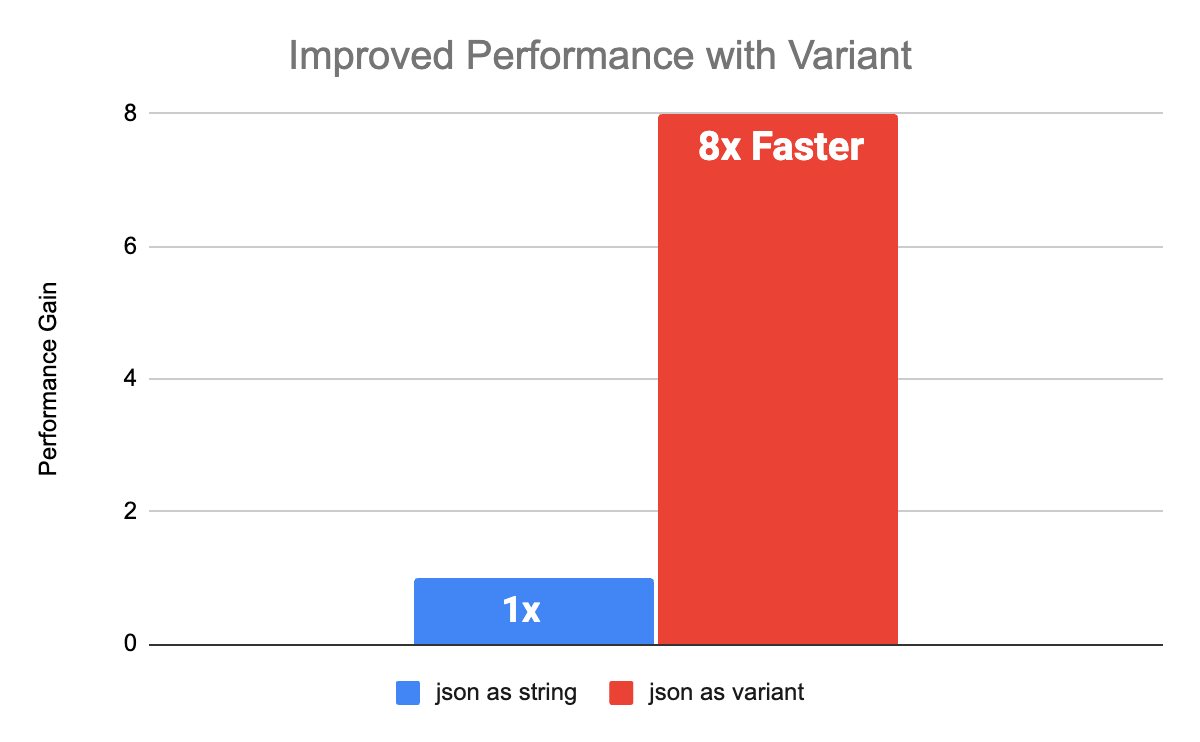
Benchmarks de rendimiento
Variant proporcionará un rendimiento mejorado sobre las cargas de trabajo existentes que mantienen JSON como una cadena. Ejecutamos múltiples benchmarks con esquemas inspirados en datos de clientes para comparar el rendimiento de String vs Variant. Tanto para esquemas anidados como planos, el rendimiento con Variant mejoró 8 veces en comparación con las columnas String. Los benchmarks se realizaron con Databricks Runtime 15.0 con Photon habilitado.
¿Cómo puedo usar Variant?
Hay una serie de nuevas funciones para admitir tipos Variant, que le permiten inspeccionar el esquema de un variant, expandir una columna variant y convertirla a JSON. La función PARSE_JSON() se usará comúnmente para devolver un valor variant que representa la entrada de cadena JSON.
Para cargar datos Variant, puede crear una columna de tabla con el tipo Variant. Puede convertir cualquier cadena con formato JSON a Variant con la función PARSE_JSON(), e insertar en una columna Variant.
Puede usar CTAS para crear una tabla con columnas Variant. El esquema de la tabla que se está creando se deriva del resultado de la consulta. Por lo tanto, el resultado de la consulta debe tener columnas Variant en el esquema de salida para poder crear una tabla con columnas Variant.
También puede usar COPY INTO para copiar datos JSON en una tabla con una o más columnas Variant.
La navegación de rutas sigue una sintaxis intuitiva de notación de puntos.
Totalmente de código abierto, sin dependencia de datos propietarios
Recapitulemos:
- El tipo de dato Variant, las expresiones binarias y el formato de codificación binaria ya se han fusionado en Apache Spark. El formato de codificación binaria se puede revisar en detalle aquí.
- El formato de codificación binaria es lo que permite un acceso y una navegación más rápidos de los datos en comparación con las cadenas. La implementación del formato de codificación binaria está empaquetada en una biblioteca de código abierto, para que pueda usarse en otros proyectos.
- El soporte para el tipo de dato Variant también es de código abierto para Delta, y el protocolo RFC se puede encontrar aquí. El soporte de Variant se incluirá en Spark 4.0 y Delta 4.0.
Además, tenemos planes para implementar el desmenuzamiento/sub-columnarización para el tipo Variant. El desmenuzamiento es una técnica para mejorar el rendimiento de la consulta de rutas particulares dentro de los datos Variant. Con el desmenuzamiento, las rutas se pueden almacenar en su propia columna, y eso puede reducir la E/S y la computación requeridas para consultar esa ruta. El desmenuzamiento también permite la poda de datos para evitar trabajos adicionales innecesarios. El desmenuzamiento también estará disponible en Apache Spark y Delta Lake.
¿Asistirá a la DATA + AI Summit de este año del 10 al 13 de junio en San Francisco?
Por favor, asista a "Variant Data Type - Making Semi-Structured Data Fast and Simple".
Variant estará habilitado por defecto en Databricks Runtime 15.3 en vista previa pública y en el canal DBSQL Preview poco después. Pruebe sus casos de uso de datos semiestructurados y comience una conversación en los foros de la comunidad de Databricks si tiene ideas o preguntas. ¡Nos encantaría saber qué piensa la comunidad!
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.