De monolito a Lakebase a LTAP: replanteando la base de datos desde el almacenamiento
por Reynold Xin
- Casi todas las bases de datos tradicionales guardan su registro de escritura anticipada y sus archivos de datos en el disco de una sola máquina, lo que es la causa principal del riesgo de pérdida de datos, de las costosas réplicas de lectura y clones de alta disponibilidad, y de las consultas analíticas que ralentizan las transacciones.
- Lakebase hace que el cómputo de Postgres sea sin estado al externalizar los archivos de registro y de datos en servicios en la nube independientes (SafeKeeper y PageServer), lo que permite un almacenamiento ilimitado, cómputo elástico, escrituras duraderas, una HA más sencilla y ramificación instantánea, todo ello sin una latencia adicional significativa.
- LTAP va más allá al almacenar los datos operativos una sola vez en formatos columnares abiertos que leen tanto Postgres como los motores de Lakehouse, de modo que la analítica se ejecuta sobre los mismos datos actualizados que las transacciones acaban de escribir, sin pipelines de CDC, sin segundas copias y sin ralentizar la carga de trabajo transaccional. A diferencia de HTAP, que intenta unificar ambas cargas de trabajo en un solo motor, LTAP unifica en la capa de almacenamiento y mantiene el mejor motor para cada tarea.
Cuando comencé mi doctorado en UC Berkeley hace 16 años, mi asesor me dijo: "Las bases de datos OLTP son un problema resuelto. Funcionan. Concéntrate en la analítica". Estábamos en las primeras etapas de poder recopilar muchos más datos, estructurados y no estructurados, y aplicar el aprendizaje automático (que ahora llamamos “AI”). Así que seguí el consejo y me uní a mis cofundadores en el proyecto de investigación que se convirtió en Apache Spark, y más tarde fundamos Databricks.
A medida que construíamos Databricks, comenzamos a usar varias bases de datos existentes y nos dimos cuenta de que las bases de datos OLTP estaban lejos de ser un problema resuelto: eran toscas, difíciles de escalar e increíblemente frágiles. En cierto momento, nos sentimos tan frustrados que nos preguntamos cómo sería una base de datos OLTP si la diseñáramos hoy. Esa pregunta nos llevó a Lakebase, nuestra base de datos Postgres serverless.
Este artículo analiza en profundidad la arquitectura OLTP de Lakebase. Comenzamos en la capa de almacenamiento de una base de datos monolítica tradicional para ver de dónde provienen los problemas, y luego analizamos cómo Lakebase reorganiza esas mismas piezas en servicios independientes y externalizados. Finalmente, pasamos a LTAP, donde esa misma arquitectura permite que las transacciones y la analítica se ejecuten en una sola copia de los datos, en tiempo real, sin los retrasos y el costo adicional de CDC o "mirroring".
La base de datos como un monolito
La gran mayoría de las bases de datos que se ejecutan hoy en el mundo son monolitos. Esto incluye MySQL, Postgres y el Oracle clásico. Lakebase está construido sobre Postgres (que, por cierto, también nació en Berkeley), por lo que usaremos Postgres como ejemplo principal aquí, pero la mayoría de las bases de datos funcionan de manera similar: se aprovisiona una máquina que ejecuta el motor de la base de datos y el almacenamiento. En estos sistemas de bases de datos, hay dos cosas en el disco que son las más importantes: el registro de escritura anticipada (WAL) y los archivos de datos.
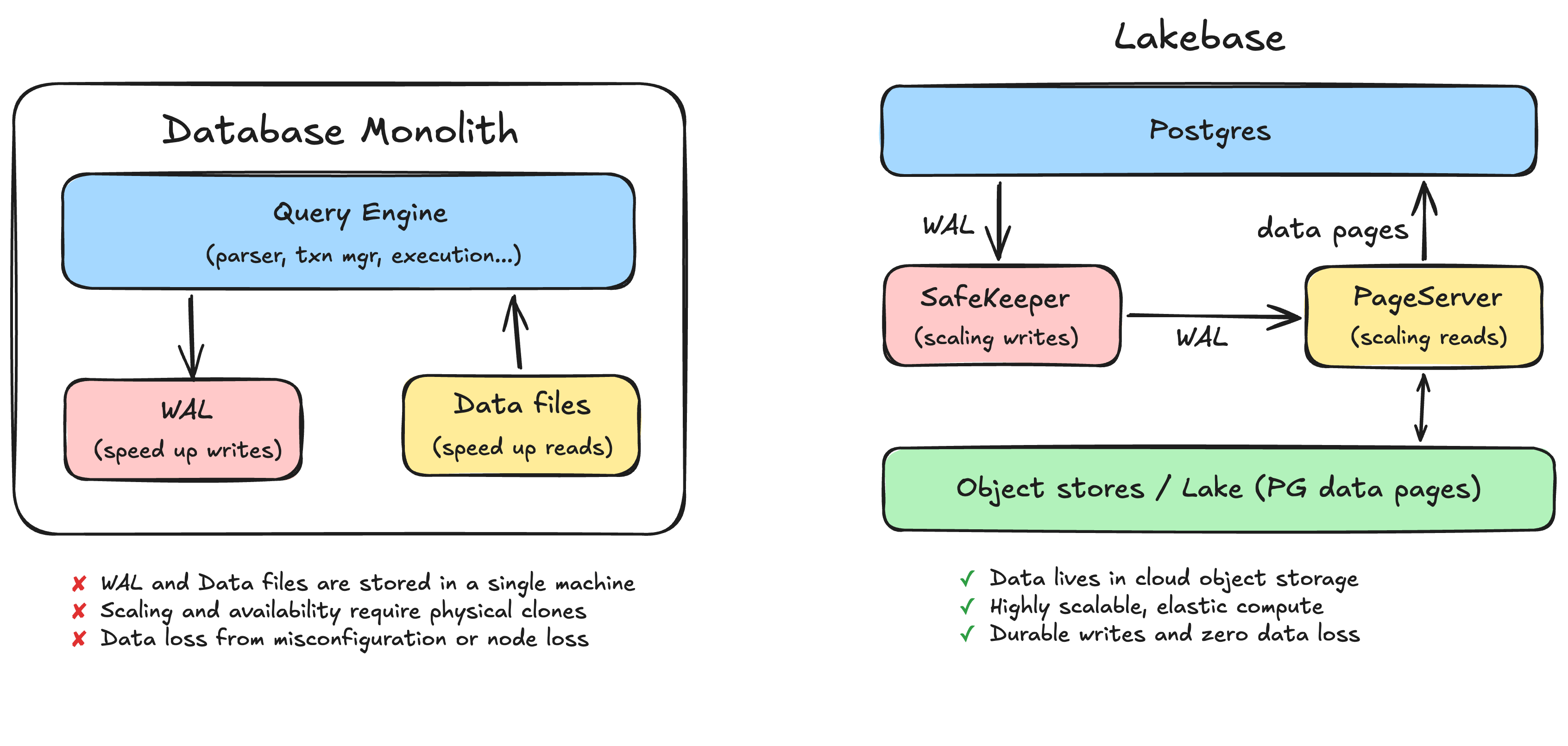
Cuando confirmas una transacción, la base de datos no va inmediatamente a reescribir los archivos de datos. Eso sería lento, porque las filas que estás modificando están dispersas por el archivo en lugares que requieren I/O aleatoria. En su lugar, la base de datos primero añade una descripción del cambio al WAL, que es un registro secuencial en el disco. Una transacción se considera confirmada en el momento en que esa entrada del registro se escribe de forma duradera. Solo más tarde, de forma asíncrona, la base de datos regresa y actualiza los archivos de datos reales para reflejar el cambio.
Una forma sencilla de pensar en esto: el WAL existe para que las escrituras sean rápidas (y seguras), y los archivos de datos existen para que las lecturas sean rápidas. El registro te permite confirmar una transacción con una sola adición secuencial en lugar de una dispersión de I/O aleatoria. Los archivos de datos te permiten responder a una consulta leyendo el estado actual directamente, en lugar de tener que reproducir todo el historial de la base de datos desde el principio de los tiempos. (Si deseas comprender todos los detalles intrincados de este diseño, lee el artículo de ARIES de 69 páginas. Te advertimos que este es uno de los artículos más complejos de la informática).
Dado que este diseño se ha convertido en la base de prácticamente todas las bases de datos existentes, la arquitectura monolítica también genera muchos desafíos:
Pérdida de datos por configuración incorrecta. Una confirmación es tan duradera como el vaciado en disco que la respalda. Si la base de datos, el sistema operativo o la capa de almacenamiento están configurados de tal manera que se confirma una escritura en el WAL al cliente antes de que realmente se haya vaciado en un medio duradero, entonces una confirmación puede desaparecer en un corte de energía o un pánico del kernel. Estos ajustes son sutiles, fáciles de configurar mal y el fallo suele ser silencioso. ¡El sistema operativo incluso podría decidir mentirte sobre el vaciado!
Pérdida de datos por pérdida de nodos. Incluso con los vaciados configurados correctamente, el WAL y los archivos de datos residen en una sola máquina. Si el disco de esa máquina falla, los datos que contiene también se pierden. Ten en cuenta que el almacenamiento conectado a la red o las técnicas de redundancia como RAID-1/RAID-10 pueden mejorar la durabilidad, pero no resuelven este problema de raíz. Si el montaje de almacenamiento falla, también lo hace tu acceso a los datos.
Escalar las lecturas requiere un clon físico. Cuando un solo equipo ya no puede manejar tu tráfico, la respuesta estándar es agregar una réplica de lectura. Pero una réplica de lectura es una copia física completa de toda la base de datos, que transmite el WAL desde la primaria y lo reproduce. Aprovisionar una significa copiar todo el conjunto de datos y luego ponerse al día con el registro. Para una base de datos grande, esa no es una operación rápida e incluso podría provocar la caída de la base de datos.
La alta disponibilidad también requiere un clon físico. Sobrevivir a la pérdida de la primaria significa ejecutar al menos un nodo de reserva (standby) adicional, que es en sí mismo una copia física completa de la base de datos mantenida en sincronía desde el WAL. Pagas por al menos el doble de infraestructura, esperas mucho tiempo para poner en línea un nodo de reserva y debes configurar la replicación síncrona para evitar perder datos cuando la primaria se caiga. (En la práctica, muchos recomiendan 3 o más nodos).
La analítica compite con tu tráfico transaccional. Una consulta analítica pesada se ejecuta con los mismos recursos de hardware que tu carga de trabajo transaccional sensible a la latencia. Una sola consulta de informe grande o una limpieza de GDPR pueden degradar tus consultas OLTP principales. Puedes ejecutar las consultas analíticas en una réplica separada, pero terminarás pagando por la réplica y aun así no obtendrás un rendimiento óptimo debido a la naturaleza orientada a filas del almacenamiento OLTP (la analítica requiere un almacenamiento orientado a columnas para un alto rendimiento).
Casi todos estos problemas se remontan a la misma causa raíz de la arquitectura monolítica: el WAL y los archivos de datos se almacenan dentro de una sola máquina. La durabilidad está ligada al disco de esa máquina. El escalamiento y la disponibilidad requieren clonar físicamente esa máquina. Las cargas de trabajo interfieren entre sí porque comparten esa máquina.
Arquitectura de Lakebase
Si fueras a rediseñar una base de datos OLTP hoy, comenzarías con los componentes de la nube moderna: almacenamiento de objetos en la nube económico y altamente duradero combinado con computación elástica. Este es el camino que tomó el equipo de Neon y la base de lo que se convirtió en Lakebase.
El paso fundamental es hacer que las instancias de computación de Postgres sean sin estado (stateless). Hacemos esto externalizando el WAL y los archivos de datos de los discos locales en servicios diseñados específicamente y escalables de forma independiente. La capa de computación se convierte en un motor Postgres sin estado que se puede iniciar, detener y replicar libremente, porque ya no es el propietario de los datos.
Veamos cómo estos dos servicios de almacenamiento pueden trabajar juntos para resolver los desafíos mencionados anteriormente sin sacrificar el rendimiento.
Escalar las escrituras: el WAL se convierte en SafeKeeper
En un monolito, una escritura se hace duradera al vaciarla en el disco local. En Lakebase, el WAL se externaliza a un servicio de almacenamiento distribuido llamado SafeKeeper. En lugar de depender del vaciado de disco para la durabilidad, una confirmación se hace duradera al replicar el registro de log en un cuórum de nodos SafeKeeper mediante replicación de red basada en Paxos. Ya no hay un disco cuya falla provoque la pérdida de tus datos, y ya no hay un vaciado mal configurado que debilite silenciosamente tu garantía de durabilidad.
Es natural preguntarse en este punto: ¿mover las confirmaciones del WAL en el disco local al WAL en SafeKeeper aumenta la latencia de escritura debido al salto de red adicional? La respuesta es no. Para cualquier implementación seria de Postgres que se preocupe por la durabilidad y la disponibilidad, tendrías que configurar la replicación síncrona, lo que requiere ese salto de red adicional, por lo que externalizar el WAL en SafeKeeper no genera una sobrecarga adicional. De hecho, debido a cómo funciona Postgres internamente, la combinación de SafeKeeper y PageServer puede ofrecer un rendimiento de escritura 5 veces mayor y una latencia de lectura 2 veces menor.
Escalar las lecturas: los archivos de datos se convierten en PageServer
Los archivos de datos se trasladan a otro servicio de almacenamiento distribuido llamado PageServer. El WAL se transmite desde el SafeKeeper al PageServer, y el PageServer aplica de forma asíncrona esos cambios a su versión de los datos, materializando páginas en un almacenamiento de objetos en la nube de bajo costo (el lago). Puedes pensar en el PageServer como una caché de escritura directa (write-through) para el almacenamiento de objetos subyacente.
Esto es similar a la relación de WAL y luego archivos de datos del monolito, excepto que ahora las dos partes residen en servicios separados e independientemente escalables conectados por la red en lugar de estar en el mismo disco. Cuando se solicita una página al PageServer, y si el PageServer aún no tiene la última versión (tenga en cuenta que los cambios se escriben primero en el SafeKeeper antes de llegar al PageServer), el PageServer aplica los registros del SafeKeeper para reconstruir el estado más reciente.
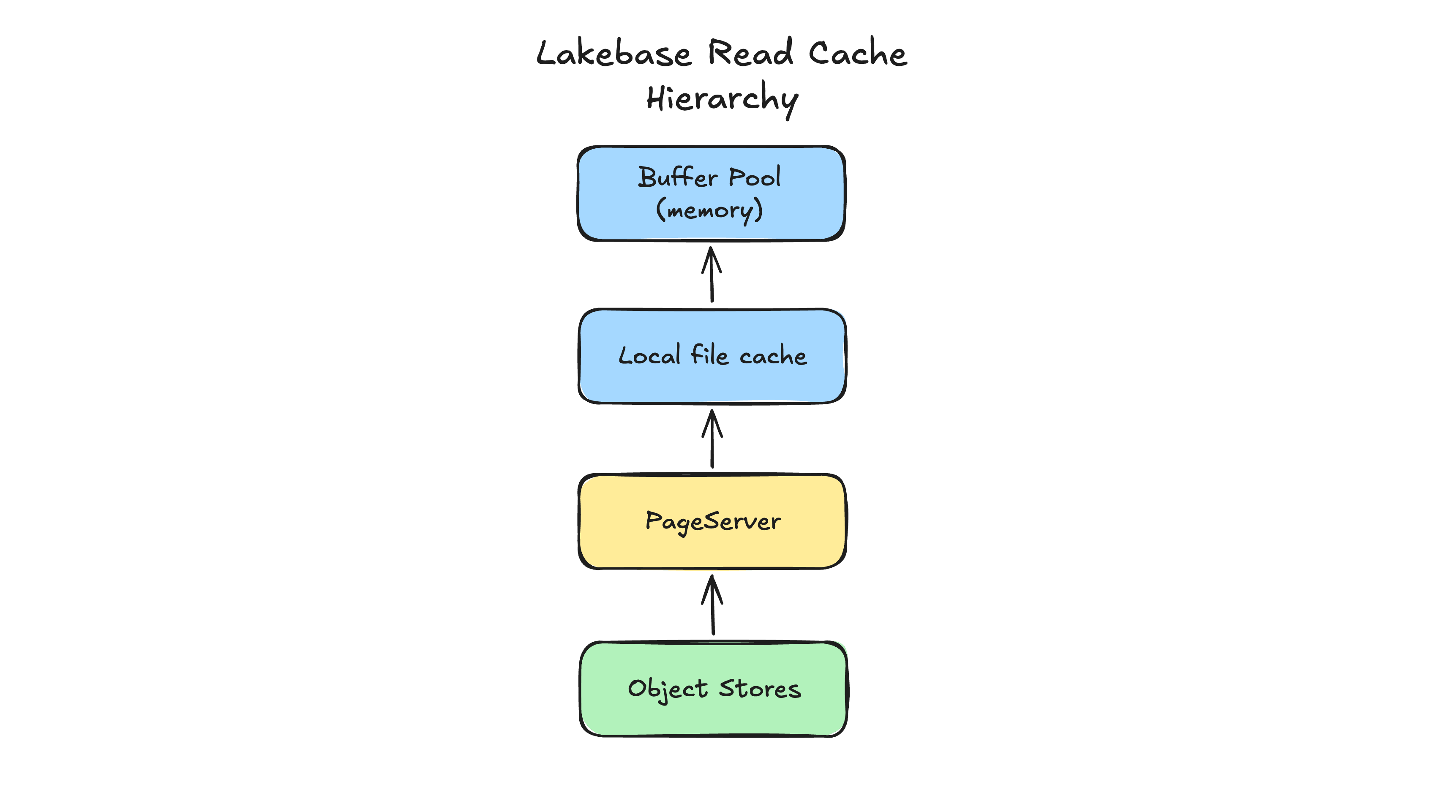
Una pregunta similar: ¿mover los archivos de datos de los discos locales al PageServer aumenta la latencia de lectura debido al salto de red adicional? La respuesta también es no a efectos prácticos. El sistema está diseñado para aislar y minimizar el impacto de la latencia mediante un almacenamiento en caché agresivo y de múltiples capas. Para recuperar una página, Postgres busca primero en su buffer pool, que está en la memoria local del nodo. Cuando la página no está presente, busca en una caché de disco local. Solo necesita ir al PageServer si hay un fallo de caché. Debido a que un nodo de cómputo se puede configurar con capacidades de memoria local y disco idénticas a las de una configuración monolítica, su tasa de aciertos de caché local permanece sin cambios. Para la gran mayoría de las operaciones, la latencia de lectura es indistinguible de la de un monolito, pero usted obtiene el beneficio de un almacenamiento desacoplado y virtualmente infinito.
Lo que esto hace posible
Una vez que el WAL reside en el SafeKeeper y los archivos de datos residen en el PageServer, una larga lista de capacidades que eran difíciles o imposibles en el monolito se convierten en consecuencias naturales de la arquitectura. Las siguientes ya están ampliamente disponibles como parte del producto Lakebase tanto en Databricks como en Neon:
Sigue siendo Postgres. Este es Postgres real, por lo que el protocolo de conexión, SQL, los controladores y las extensiones funcionan tal cual.
Almacenamiento ilimitado. Los datos residen en el almacenamiento de objetos en la nube en lugar de en un disco local aprovisionado. Ya no tiene que dimensionar un servidor para un límite de capacidad. El almacenamiento es, a efectos prácticos, infinito.
Cómputo elástico y serverless. Debido a que el cómputo no tiene estado, puede escalar instantáneamente bajo carga y reducirse por completo a cero cuando está inactivo. Deja de pagar por una máquina grande que se queda allí esperando tráfico.
Escrituras duraderas y cero pérdida de datos. Un commit es duradero una vez que se replica en los nodos de SafeKeeper a través de Paxos, no cuando un solo disco local afirma haberlo escrito en disco. La pérdida de cualquier nodo individual no provoca la pérdida de datos confirmados.
Alta disponibilidad más simple. En el monolito, HA significaba mantener un segundo clon físico completo, pagar el doble y aun así arriesgarse a perder datos en la transición. Aquí, el estado duradero ya reside en una capa de almacenamiento replicada que es independiente de cualquier instancia de cómputo individual. La conmutación por error ya no significa promover una copia física separada de la base de datos y esperar que el último segmento del registro se haya transferido.
Creación de ramas, clonación y recuperación instantáneas. Esta es mi parte favorita. Para el código, crear una rama es una copia completamente aislada de todo el código base que toma menos de un segundo, y lo hacemos docenas de veces al día sin pensarlo. Para una base de datos monolítica, la clonación significa copiar físicamente todo el conjunto de datos, lo cual es lento, costoso y riesgoso para el sistema de producción. Cuando los datos residen en una capa de almacenamiento externa y con versiones, una rama o un clon es una operación de metadatos en lugar de una copia física. Puede crear una rama de una gran base de datos de producción en segundos, ejecutar un experimento o una migración riesgosa en la rama y luego desecharla. La recuperación a un punto en el tiempo funciona de la misma manera. Finalmente, la base de datos se mueve tan rápido como su código.
Separar el cómputo del almacenamiento no es algo nuevo en sí mismo. La publicación anterior analizó las bases de datos en la nube de generación 2 que habían hecho esto. Sin embargo, la clave con Lakebase es que almacenamos datos operativos en un almacenamiento de objetos estándar en un formato abierto. Con esto, abrimos las oportunidades para que otros motores lo lean directamente, lo que conduce a LTAP.
LTAP: una sola copia para transacciones y analítica
Todo hasta ahora ha consistido en mejorar una única base de datos operativa: más duradera, más elástica, más barata de ejecutar, más rápida de ramificar. Pero una vez que los datos residen en una capa de almacenamiento externa, algo más interesante se vuelve posible. Podemos dejar de tratar la base de datos transaccional y el sistema analítico como dos mundos separados.
Volvamos al PageServer por un momento. Este ya toma el flujo de cambios del WAL y materializa de forma asíncrona las páginas en el almacenamiento de objetos. Ese paso de materialización, el momento en que los datos aterrizan en el lago, resulta ser exactamente el lugar adecuado para resolver un problema mucho más antiguo...
Incluso con un Lakebase, los datos en el almacenamiento de objetos todavía se escribían en el formato de página nativo de Postgres, dispuesto fila por fila. Ese formato es excelente para transacciones y deficiente para la analítica, por lo que cualquier motor analítico que quisiera leerlo tenía que pagar un costo de conversión en cada lectura o, más comúnmente, depender de una copia separada de los datos mantenida sincronizada por un pipeline. El pipeline puede ser frágil, y las dos copias de los datos pueden convertirse en una pesadilla de gobernanza con permisos divergentes.
Recientemente anunciamos LTAP, de Lake Transactional/Analytical Processing, que elimina el problema de las dos copias de datos. La idea clave es unificar los dos mundos en la capa de almacenamiento en lugar de en la capa del motor. No intentamos construir un solo motor que de alguna manera sea excelente tanto para transacciones como para analítica. Mantenemos la mejor herramienta para cada trabajo: Postgres, con semántica ACID completa para transacciones, y los motores de Lakehouse para analítica. Lo que cambia son los datos debajo de ellos. En lugar de dos copias en dos formatos, hay una copia duradera, en formatos columnares abiertos como Delta e Iceberg, almacenada como Parquet, que ambas partes leen (y con varios niveles de caché para un mejor rendimiento).
Materialización en formato columnar
Nota: esta sección requiere más conocimientos internos de Postgres para comprenderse que otras secciones.
A medida que el PageServer materializa las páginas en el almacenamiento de objetos, transcodifica los datos de Postgres de un formato de fila al diseño columnar de Parquet a medida que aterrizan en el lago. Preservamos la representación exacta de Postgres de cada valor, hasta el último bit, para que cualquier motor compatible con Postgres pueda reinterpretarlo sin perder información. Esto es diferente del enfoque basado en CDC, ya que CDC envía un flujo de eventos de cambio lógico a un esquema externo y deja atrás la semántica física y transaccional de Postgres; aquí las conservamos. Con un motor hiperoptimizado, la CPU libre en la capa del PageServer realiza la transcodificación de fila a columnar como parte de la materialización de los datos en el almacenamiento de objetos, por lo que no agrega carga al cómputo de Postgres que atiende sus transacciones. Para servir lecturas transaccionales de manera eficiente, el PageServer aún materializa páginas tradicionales basadas en filas en una caché local, pero esta es estrictamente una caché de rendimiento. El almacén duradero subyacente permanece unificado en el lago, accesible por ambas partes.
Preservar la semántica de Postgres en formato columnar se reduce a dos cosas: el sistema de tipos y la multiversión.
Sistema de tipos. La mayoría de los tipos de Postgres se asignan directamente a los tipos nativos de Parquet. El puñado de valores sin un equivalente columnar sin pérdidas, por ejemplo, NaN e ±Infinity, NUMERICs más allá del rango decimal, tipos exóticos o de extensión, no se descartan ni se fuerzan. Se transportan junto con las columnas originales en un campo de desbordamiento estructurado dentro de la misma tabla, que contiene el texto canónico de Postgres para esos valores. Ese campo es directamente consultable por cualquier motor y suficiente para reconstruir exactamente los bytes originales de Postgres de regreso.
Multiversión. En Postgres, se conserva cada versión de fila que alguna transacción podría observar, que es exactamente lo que hace posible el aislamiento de instantáneas y la recuperación a un punto en el tiempo. Por el contrario, los formatos de tabla abiertos exponen instantáneas consistentes a nivel de tabla sin versiones de fila intermedias. Obtenemos los beneficios de ambos enfoques al separar la durabilidad de la visibilidad. Cada fila materializada a columnar lleva su dirección de heap física (bloque y desplazamiento), por lo que las páginas de heap siguen siendo completamente reconstruibles. La clásica página de heap de Postgres se convierte en una caché que acelera las lecturas puntuales, mientras que la fuente de verdad duradera reside en los archivos columnares en el almacenamiento de objetos. Los índices de Postgres no se transcodifican en columnas; se sirven y reconstruyen desde ese nivel de caché rápida. Las versiones de fila intermedias se retienen para preservar la semántica MVCC de Postgres y PITR, pero no son visibles para los lectores de Iceberg/Delta y eventualmente se recolectan como basura. El resultado neto: los motores analíticos ven tablas limpias y consistentes con las instantáneas, mientras que el sistema Postgres subyacente todavía ve un historial de versiones completo con capacidad de viaje en el tiempo.
También hay un efecto secundario positivo. Los datos orientados a columnas se comprimen mucho mejor que los datos por filas, a menudo más de diez veces, por lo que la conversión al almacenamiento en columnas reduce sustancialmente el volumen de datos que cruzan la red entre la capa de almacenamiento en caché y el almacenamiento de objetos, hasta el punto de que a menudo es insignificante. El formato que agiliza las analíticas también abarata la ruta de almacenamiento. Incluso aprovechamos esto para realizar una doble escritura tanto en formato de filas como en formato de columnas en los almacenamientos de objetos para la verificación de datos durante la fase de despliegue de transición de LTAP (ya que queremos ser extremadamente cuidadosos con los cambios de almacenamiento).
Lectura de los datos más recientes sin afectar a Postgres
Un gran desafío es la frescura de los datos. Si las analíticas leen de una copia en el lago, ¿cómo ven los datos que se confirmaron hace un momento y que aún no se han materializado en el almacenamiento de objetos? Esta es la pregunta que echa por tierra la mayoría de los diseños de "simplemente apunta las analíticas al lago", por lo que vale la pena analizar cómo la responde LTAP.
Cuando comienza una consulta analítica (por ejemplo, desde el producto Lakehouse//RT que acabamos de anunciar), primero le pide a Postgres el LSN actual, el número de secuencia de registro que marca la posición exacta en el WAL a partir de la cual leer. Esta es una búsqueda de metadatos económica. Con ese LSN, el motor analítico lee la gran mayoría de los datos, incluido todo lo que ya se ha materializado hasta ese momento, directamente desde el almacenamiento de objetos. Lo único que queda es el pequeño conjunto de cambios muy recientes que aún no se han materializado en el lago, los cuales recupera del PageServer y los fusiona encima.
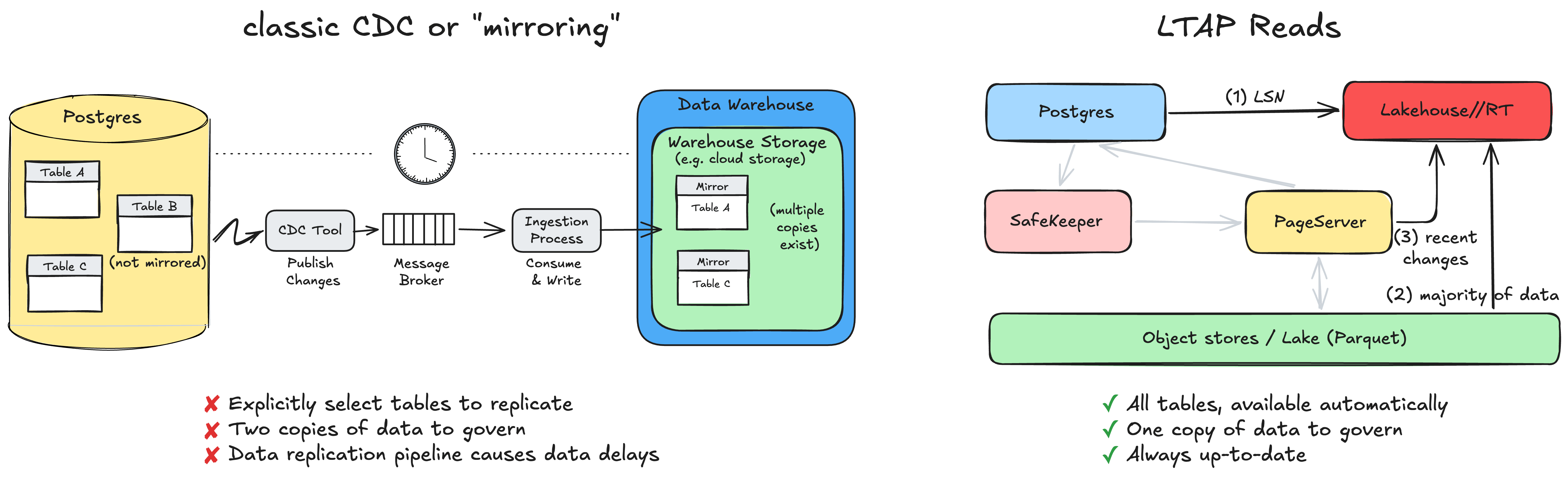
El resultado es una lectura consistente y totalmente actualizada de sus datos a partir de ese LSN. Casi todo el trabajo recae en un almacenamiento de objetos económico y escalable. Y lo que es más importante, el propio Postgres no atiende nada del tráfico de lectura analítica, aparte de devolver un único número (LSN). Su carga de trabajo transaccional no se ralentiza porque alguien haya iniciado una gran consulta analítica.
Hay una optimización práctica que vale la pena mencionar aquí: para tablas muy pequeñas, las que contienen un puñado de filas, no nos molestamos en convertirlas a formato de columnas ni en crear los metadatos de Iceberg asociados. El registro costaría más de lo que ahorra, y una tabla tan pequeña no tiene un efecto medible en el rendimiento analítico, independientemente de cómo esté estructurada. Esas tablas siguen estando presentes y se pueden consultar como parte de la copia única.
Cada tabla, de forma automática
Debido a la importancia de este problema, ha habido mucho ruido en el mercado sobre la integración de OLTP y las analíticas. Un enfoque clásico es CDC, que replica eficazmente los datos del almacenamiento OLTP en un nivel de almacenamiento de analíticas independiente. Es posible que haya oído hablar de sus otros nombres, como "mirroring", "zero CDC" o "zero ETL".
En CDC o "mirroring", debido a que la canalización de replicación de datos tiene un costo, no se puede aplicar a todas las tablas. Tendría que seleccionar explícitamente qué tablas le interesan, y esta replicación suele tener un retraso.
En LTAP no hay nada que activar. Una tabla que existe ya está, por diseño, en el lago y ya se puede consultar. No hay una lista de tablas replicadas o reflejadas, porque no hay replicación. Existe una única copia gobernada de los datos en formatos abiertos, sin canalizaciones ETL que crear, monitorear o reparar (ya sea por parte de nuestros clientes o de nosotros). Los motores transaccionales y analíticos se escalan de forma independiente, cada uno adaptado a su propia carga de trabajo. Y como no hay movimiento de datos ni una segunda copia, las dos vistas nunca pueden diferir: las analíticas siempre leen los mismos datos que la aplicación acaba de escribir.
Para ver de otra manera cómo se integra LTAP, eche un vistazo a esta demostración de Data and AI Summit.
¿Qué pasa con HTAP?
Si conoce este campo, ya habrá notado que LTAP es un juego de palabras deliberado con HTAP: procesamiento híbrido transaccional y analítico. HTAP ha sido el santo grial de la ingeniería de bases de datos, centrándose en la creación de un único motor capaz de gestionar cargas de trabajo tanto transaccionales como analíticas.
En la práctica, no ha habido un solo sistema de base de datos HTAP ampliamente adoptado en el mercado. ¿A qué se debe esto? En mi opinión, los sistemas HTAP sufren de uno o más de los siguientes problemas:
Conjunto de características incompleto. Diseñar un nuevo motor propietario desde cero para realizar una sola tarea es una inversión de varios años. Intentar crear un único motor que pueda hacer el trabajo de varios motores multiplica la inversión necesaria para alcanzar el conjunto de características que los ingenieros dan por sentado en una base de datos madura. Estos sistemas a menudo se quedan atrás en aspectos que la gente asume que siempre están ahí, desde la amplitud del soporte de SQL (por ejemplo, el soporte de claves foráneas) hasta la madurez del optimizador de consultas.
Sin ecosistema. Postgres y Spark se encuentran en el centro de un vasto ecosistema: controladores, extensiones, herramientas y décadas de conocimiento operativo acumulado. Un motor completamente nuevo comienza fuera de todo esto, y un motor es tan útil como el ecosistema sobre el cual un equipo realmente puede construir.
Sin aislamiento de rendimiento. Muchos sistemas HTAP ejecutan transacciones y analíticas en el mismo hardware, por lo que las dos cargas de trabajo compiten por la misma CPU y memoria. Este es el mismo fallo con el que empezamos en el monolito, donde una consulta analítica agota los recursos de la carga de trabajo transaccional.
Los tres problemas se remontan a la misma decisión de unificar las dos cargas de trabajo en un solo motor. Lakebase y LTAP evitan estos desafíos al unificarse en la capa de almacenamiento, mientras utilizan diferentes motores de cómputo para las distintas cargas de trabajo, aprovechando al máximo sus conjuntos de características y el soporte de sus ecosistemas, con un aislamiento total del rendimiento.
Reflexión final
Cuando propusimos por primera vez la arquitectura Lakebase el año pasado, ya sabíamos que desbloquearía almacenamiento ilimitado, cómputo elástico, escrituras duraderas, una HA más sencilla y ramificación instantánea, basándonos en lo que habíamos visto con la plataforma Neon. Todo eso ocurrió casi de forma mecánica una vez que el WAL residió en el SafeKeeper y los archivos de datos en el PageServer.
La idea de LTAP surgió más tarde, después de que los equipos de Neon y Databricks se unieran para resolver el problema histórico de ejecutar analíticas sobre los datos transaccionales más recientes. A medida que solucionemos los pequeños detalles de LTAP y lo implementemos en los próximos meses, todas sus tablas de Lakebase estarán disponibles para analíticas con un rendimiento tan alto como el de los datos de Lakehouse.
Lo que más me entusiasma es lo que está por venir. Si bien LTAP es un paso siguiente natural, el mismo diseño también abre muchas oportunidades de optimización para separar otras operaciones de mantenimiento pesadas de las cargas de trabajo transaccionales principales. Apenas estamos comenzando a explorar lo que esta arquitectura hace posible, y esperamos compartir lo que vendrá después.
Agradecimientos: Me gustaría agradecer al equipo de Lakebase por hacer realidad todo lo que analizamos en este blog, revisar esta publicación y ayudarme a mantener la precisión en los detalles técnicos.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.