Cómo la arquitectura lakebase acelera 5 veces las escrituras de Postgres
Resolución del cuello de botella de rendimiento estructural en Postgres administrado
por David Wein y Vlad Lazar
- Lakebase ahora ofrece hasta 5 veces más rendimiento para cargas de trabajo OLTP con muchas escrituras, un problema común para aplicaciones Postgres a gran escala.
- La arquitectura lakebase nos permite descargar tareas críticas de recuperación ante fallos de la capa de cómputo al almacenamiento distribuido.
- El muestreo en producción muestra mejoras en el rendimiento de escritura de 4.5 veces en cómputos de 32 vCPU y una reducción del 94% en el tráfico WAL, todo ello mientras se reduce la latencia de cola de lectura en 2 veces sin arriesgar la durabilidad.
En una lakebase, el cómputo y el almacenamiento se separan por diseño. Si bien esta separación se creó originalmente para flexibilidad operativa, incluida la escalabilidad, la ramificación y la recuperación instantánea, también desbloquea una frontera de rendimiento masiva.
Al desacoplar estas capas, podemos descargar el trabajo de su cómputo Postgres a nuestro almacenamiento distribuido de maneras que son estructuralmente imposibles en implementaciones Postgres monolíticas tradicionales. En esta publicación, exploraremos cómo aprovechamos esta ventaja arquitectónica para eliminar un cuello de botella de Postgres de una década, mejorando el rendimiento de escritura de Postgres en 5 veces, al tiempo que reducimos las latencias de lectura de cola en 2 veces y el tráfico WAL en un 94%.
El costo oculto de la durabilidad tradicional de Postgres
Para comprender cómo logramos una mejora de 5 veces en el rendimiento de Postgres administrado, tenemos que ver cómo Postgres tradicional maneja la durabilidad.
En Postgres, cada cambio de base de datos se guarda primero en un registro secuencial (el Write-Ahead Log, o WAL) para garantizar que los datos no se pierdan en caso de un fallo. Para mantener rápidos los tiempos de recuperación ante fallos, Postgres realiza periódicamente un evento de limpieza en segundo plano llamado "checkpoint". A diferencia de una instantánea, un checkpoint es simplemente un marcador de hito en el registro. Durante un checkpoint, Postgres toma todos los datos modificados que se encuentran actualmente en la memoria (gestionados en fragmentos de 8 KB llamados "páginas") y los vuelca al disco principal, hasta un punto específico del registro. Si ocurre un fallo, Postgres restaura sus datos comenzando en ese hito de checkpoint y reproduciendo los registros WAL recientes sobre el disco.
Sin embargo, existe un riesgo: si el servidor falla exactamente mientras guarda una página de 8 KB en el disco, la página podría escribirse solo parcialmente, lo que resultaría en una "página rota" corrupta. Si Postgres intenta reproducir una pequeña actualización del registro sobre una página rota, los datos se arruinan permanentemente. Para solucionar esto, Postgres tiene que asegurarse de que nunca dependa de un disco corrupto para la recuperación.
Lo hace utilizando "Full Page Write" (FPW). La primera vez que se modifica una página *después* de un hito de checkpoint, Postgres no solo registra el pequeño cambio; copia la página de 8 KB *completa* en el WAL. Si ocurre un fallo y la página del disco está rota, Postgres ignora el disco arruinado, toma la copia de seguridad prístina de 8 KB del WAL y la utiliza como punto de partida perfecto para reproducir el resto de los registros. Si bien esto garantiza una seguridad absoluta, es costoso: en aplicaciones con muchas escrituras, el registro de páginas completas de 8 KB puede inflar el volumen del registro hasta 15 veces, convirtiéndose a menudo en el mayor cuello de botella de rendimiento del sistema.
La solución lakebase: eliminando el riesgo de páginas rotas
En la arquitectura lakebase, su cómputo no tiene estado. No depende de un directorio de datos local. En su lugar, transmite WAL a un quórum de safekeepers basado en Paxos.
Debido a que no hay una página de disco local que se rompa, el modo de fallo que FPW fue diseñado para prevenir simplemente no existe. Sin embargo, desactivar FPW de forma ingenua crea un problema secundario: el rendimiento de lectura. Sin esas imágenes de página completas periódicas en el registro, la capa de almacenamiento tendría que reproducir una cadena infinitamente larga de pequeños deltas para reconstruir una página para una solicitud de lectura. Lo que antes era una reproducción acotada O(frecuencia de checkpoint) se convierte en una cadena ilimitada, lo que provoca un pico en la latencia de lectura y el consumo de recursos.
Innovación: generación de imágenes enviada al almacenamiento distribuido
Resolvimos esto moviendo la inteligencia del nodo de cómputo a la capa de almacenamiento. Llamamos a esto generación de imágenes enviada (image generation pushdown).
Cuando el cómputo Postgres solicita una página del almacenamiento, el pageserver (un componente del sistema de almacenamiento distribuido Lakebase) la reconstruye encontrando la imagen materializada más reciente de esa página y reproduciendo cualquier delta WAL encima. Las imágenes de página completas que el cómputo solía incrustar en WAL sirvieron como puntos de reinicio periódicos en esa cadena de deltas, manteniendo naturalmente la cadena razonablemente acotada y las lecturas rápidas. Para un tratamiento más profundo de este mecanismo, consulte Inmersión profunda en el motor de almacenamiento de Neon.
Con las escrituras de página completas deshabilitadas, esos puntos de reinicio desaparecen. Sin inteligencia adicional en el sistema de almacenamiento distribuido, una página actualizada con frecuencia podría acumular una larga cadena de pequeños deltas sin una imagen intermedia. El resultado sería un aumento indeseable en la latencia de lectura y el consumo de recursos, ya que el pageserver reproduciría toda la cadena para servir una lectura, aumentando la latencia y el consumo de recursos.
Para evitar este problema, enviamos la responsabilidad de generación de imágenes desde el flujo WAL del cómputo a la capa de almacenamiento, preservando el comportamiento de lectura acotado del almacenamiento y al mismo tiempo eliminando la sobrecarga de WAL en el cómputo. El pageserver ahora genera imágenes de página completas cuando una página ha acumulado más registros delta que un umbral configurado sin una imagen intermedia. Este es un enfoque naturalmente mejor porque la decisión de generar una nueva imagen se basa en el número real de cambios en una página en lugar del proceso de checkpoint de Postgres, que no está relacionado.
Aquí le explicamos por qué esto es significativamente mejor para el rendimiento:
- Eficiencia de red: El cómputo envía solo los deltas compactos, que son los cambios reales, lo que genera una reducción del 94% en el tráfico en nuestras pruebas comparativas.
- Escalabilidad: El trabajo se traslada del único escritor de Postgres a la capa de almacenamiento distribuida y escalable de forma independiente. La generación de imágenes para una rama de proyecto ahora se comparte entre varios pageservers en segundo plano.
- Lecturas óptimas: La generación de imágenes ahora se basa en los cambios reales en una página en lugar del proceso de checkpoint de Postgres, que no está relacionado.
Cuantificando el impacto: del laboratorio a la producción
Evaluamos esta optimización utilizando HammerDB TPROC-C (una prueba de referencia OLTP derivada de TPC-C) y validamos los resultados en cargas de trabajo de producción del mundo real.
1. Escalado de cómputo sin servidor
El rendimiento se mide en nuevos pedidos por minuto (NOPM). Las ganancias escalan drásticamente con el tamaño de la instancia de cómputo:
Tamaño del cómputo | Antes (NOPM) | Después (NOPM) | Ganancia de rendimiento |
4 vCPU | 78,876 | 94,891 | 20% |
16 vCPU | 95,832 | 269,189 | 2.8x |
32 vCPU | 95,686 | 439,300 | 4.5x+ |

En un cómputo de 32 vCPU, la mejora superó el 450%.
Con imágenes de página completas generadas en el cómputo, cada transacción genera 58 KB de WAL en promedio. Con la generación de imágenes enviada, eso se reduce a menos de 4 KB, una reducción del 94%. La mejora del rendimiento se deriva directamente: menos WAL significa menos contención en la ruta de escritura, menos ancho de banda de red consumido y menos trabajo para que la capa de almacenamiento lo ingiera.

Al eliminar el cuello de botella FPW de Postgres, permitimos que el rendimiento escale linealmente con los recursos de cómputo. Esto es algo que Postgres monolítico tiene dificultades para hacer bajo una carga de escritura pesada.
2. Validación de producción en el mundo real
En un entorno de producción para un proyecto de alto perfil de 56 vCPU, habilitar el envío de imágenes redujo la generación de WAL en estado estable de 30 MB/s a solo 1 MB/s.

Esta disminución en el volumen se correlacionó directamente con un aumento en el rendimiento de las transacciones durante los picos diarios.
Esto no solo ayudó a las escrituras. Al optimizar las cadenas delta, el número de registros WAL que deben aplicarse por lectura se redujo significativamente. Vimos que las latencias de lectura p99 cayeron entre un 30% y un 50%, y las latencias p50 cayeron aproximadamente un 30%.

Ampliando la vista, a nivel regional, después de la habilitación, vimos que la cantidad total de WAL generada por las computaciones se redujo hasta en 4 veces. La latencia p99 de las lecturas del motor de almacenamiento mejoró hasta 3 veces y se volvió mucho más estable.

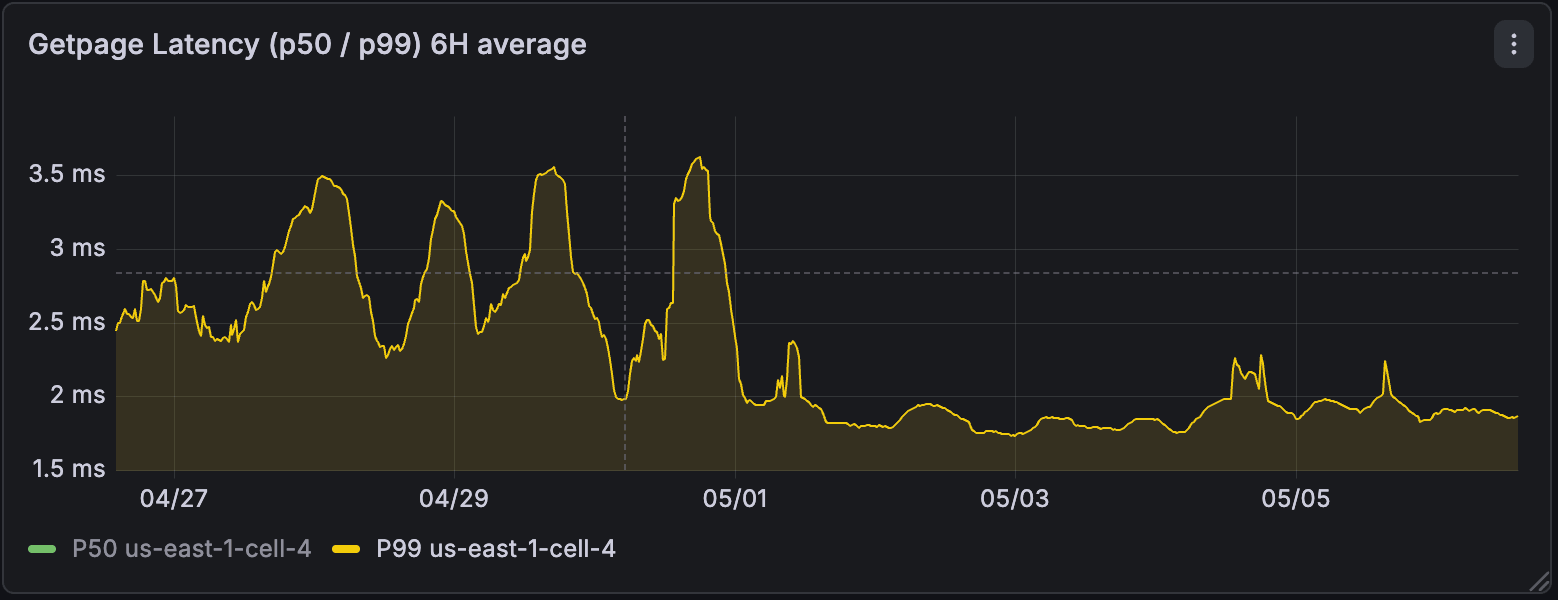
3. Tablas sincronizadas de Lakebase
Para las Tablas Sincronizadas intensivas en datos, el impacto fue inmediato. Un cliente vio cómo el rendimiento de la ingesta saltaba de 17k filas por segundo a 62k filas por segundo, lo que supone un aumento de 3 veces, simplemente al habilitar la reducción de imágenes.
Despliegue sin interrupciones: rendimiento sin interrupciones
Desde finales de marzo, hemos desplegado esto en toda nuestra flota. Ahora está activo para todas las bases de datos Lakebase Serverless y Neon a nivel mundial.
El cambio se aplicó a las computaciones en ejecución a través de nuestro plano de control y sistema de almacenamiento, que coordinaron la transición automáticamente. Esto se logró utilizando el mecanismo de registro WAL de Postgres XLOG_FPW_CHANGE WAL existente, lo que significa que no se requirieron reinicios ni interrupciones para nuestros clientes.
¿Qué sigue para el rendimiento de Postgres administrado?
La arquitectura de Lakebase se construyó para la flexibilidad, pero se diseñó para el rendimiento. La reducción de escrituras de página completa es parte de un esfuerzo sistemático para cosechar los beneficios de la separación de almacenamiento y cómputo.
Así como introdujimos el precalentamiento de caché para el parcheo sin tiempo de inactividad, continuamos trasladando las tareas pesadas de sus transacciones a nuestro stack de almacenamiento en segundo plano escalable. El impuesto de escritura de Postgres es oficialmente cosa del pasado.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.