Una Nueva Era de Bases de Datos: Lakebase
por Ali Ghodsi, Stas Kelvich, Heikki Linnakangas, Nikita Shamgunov, Arsalan Tavakoli-Shiraji, Patrick Wendell, Reynold Xin y Matei Zaharia
Durante décadas, las bases de datos han sido la columna vertebral del software: impulsando silenciosamente todo, desde los flujos de pago del comercio electrónico hasta la planificación de recursos empresariales. Cada pieza de software en el mundo, cada aplicación, cada flujo de trabajo, cada línea de código generada por IA, en última instancia, depende de una base de datos subyacente. En el camino, hemos reinventado por completo cómo se construyen las aplicaciones, pero las bases de datos subyacentes han cambiado muy poco desde la década de 1980. Se basan en gran medida en arquitecturas que preceden a la nube moderna y sufren de lo siguiente:
- Operaciones frágiles y costosas: Las bases de datos tradicionales se consideran una de las piezas de infraestructura más delicadas, y operarlas de manera confiable generalmente requiere un ejército de especialistas para "caminar sobre cáscaras de huevo". Agrupan la computación y el almacenamiento en una unidad monolítica y rígida. Esto obliga a los equipos a aprovisionar para la capacidad máxima, lo que genera recursos inactivos costosos. Cuando la carga supera la capacidad aprovisionada, las bases de datos pueden volverse no responsivas. Peor aún, tareas de mantenimiento simples como la instantánea de una base de datos o la ejecución de una consulta de limpieza GDPR pueden potencialmente derribar toda la base de datos.
- Experiencia de desarrollo torpe: Las bases de datos tradicionales chocan con los flujos de trabajo de desarrollo modernos y ágiles. Para el código, se tarda menos de un segundo en crear una rama de git para el desarrollo que sea un clon completamente aislado de la base de código. Para las bases de datos, se necesitan muchos minutos, si no horas, para aprovisionar una, y tomar un clon de alta fidelidad de la base de datos de producción es muy costoso y corre el riesgo de derribar la base de datos de producción. El auge del desarrollo impulsado por IA solo ha intensificado esta presión. Los agentes de IA necesitan iniciar entornos temporales y aislados al instante para la experimentación.
- Bloqueo de proveedor extremo: Las migraciones de bases de datos son uno de los proyectos técnicos más aterradores en cualquier organización. La arquitectura monolítica significa que la única forma de introducir o sacar datos es a través del propio motor de la base de datos. Esto impone un bloqueo de proveedor significativo, lo que hace que las organizaciones dependan profundamente del proveedor específico.
Es hora de que las bases de datos evolucionen.
¿Qué es una Lakebase?
Están comenzando a surgir nuevos sistemas que abordan las limitaciones de las bases de datos tradicionales. Una Lakebase es una arquitectura nueva y abierta que combina los mejores elementos de las bases de datos transaccionales con la flexibilidad y la economía del data lake. Las Lakebases son posibles gracias a un diseño fundamentalmente nuevo: separar la computación del almacenamiento y colocar los datos de la base de datos directamente en almacenamiento en la nube de bajo costo ("lake") en formatos abiertos, al tiempo que se permite que la capa de computación transaccional se ejecute de forma independiente encima.
Esta separación es el avance central. Las bases de datos tradicionales agrupan la CPU y el almacenamiento en un sistema monolítico que debe aprovisionarse, administrarse y pagarse como una sola máquina grande. Lakebase divide estas capas. Los datos viven abiertamente en el lake, mientras que el motor de la base de datos se convierte en una capa de computación sin servidor y totalmente administrada (por ejemplo, Postgres) que puede escalar instantáneamente. Esta arquitectura elimina gran parte del costo, la complejidad y el bloqueo que han definido las bases de datos durante décadas, y es especialmente potente para las cargas de trabajo modernas de IA y basadas en agentes, donde los desarrolladores quieren lanzar muchas instancias, experimentar libremente y pagar solo por lo que usan.
Una Lakebase tiene las siguientes características clave:
El almacenamiento está separado de la computación: Los datos se almacenan de forma económica en almacenes de objetos en la nube ("lake"), mientras que la computación se ejecuta de forma independiente y elástica. Esto permite una escala masiva, alta concurrencia y la capacidad de escalar hasta cero en menos de un segundo (algo no posible en los sistemas de bases de datos heredados), eliminando la necesidad de mantener máquinas de bases de datos costosas funcionando inactivas.
Almacenamiento ilimitado, de bajo costo y duradero: Con los datos viviendo en el lake, el almacenamiento se vuelve esencialmente infinito y drásticamente más barato que los sistemas de bases de datos tradicionales que requieren infraestructura de capacidad fija. Y su almacenamiento está respaldado por la durabilidad del almacenamiento de objetos en la nube (por ejemplo, S3), que ofrece un 99.999999999% de durabilidad por defecto. Esto es muy superior a la configuración tradicional de bases de datos de tener réplicas para redundancia de almacenamiento (la mayoría de las veces actualizadas asincrónicamente, lo que significa que existe la posibilidad de pérdida de datos en muchas configuraciones en caso de doble falla).
Computación Postgres elástica y sin servidor: Lakebase proporciona Postgres sin servidor y totalmente administrado que escala instantáneamente con la demanda y se reduce cuando está inactivo. Los costos se alinean directamente con el uso, lo que lo hace ideal para cargas de trabajo variables, entornos de desarrollo y agentes de IA que inician instancias temporales.
Ramificación, clonación y recuperación instantáneas: Las bases de datos se pueden ramificar y clonar de la misma manera que los desarrolladores ramifican el código. Incluso las bases de datos a escala de petabytes se pueden copiar en segundos, lo que permite una experimentación rápida, reversiones seguras y restauración instantánea sin sobrecarga operativa.
Cargas de trabajo transaccionales y analíticas unificadas: Lakebase se integra perfectamente con el Lakehouse, compartiendo la misma capa de almacenamiento para OLTP y OLAP. Esto hace posible ejecutar análisis en tiempo real, machine learning y optimización impulsada por IA directamente sobre datos transaccionales sin moverlos ni duplicarlos.
Abierto y multicloud por diseño: Los datos almacenados en formatos abiertos evitan el bloqueo propietario y permiten una portabilidad real en AWS, Azure y más allá. La flexibilidad multicloud incorporada admite la recuperación ante desastres, la libertad a largo plazo y mejores economías con el tiempo.
Estos son los atributos clave de Lakebase. Los sistemas transaccionales de nivel empresarial requieren capacidades adicionales como seguridad, gobernanza, auditoría y alta disponibilidad, pero con una Lakebase, estas características solo necesitan implementarse y administrarse una vez, en una única base abierta. Lakebase representa la próxima evolución de las bases de datos: sistemas transaccionales reconstruidos para la nube, para desarrolladores y para la era de la IA.
Evolución de la Arquitectura de Bases de Datos
Para comprender por qué se necesita una nueva era, es útil observar cómo ha evolucionado la arquitectura de bases de datos en los últimos cincuenta años. Vemos esta evolución en tres generaciones distintas:
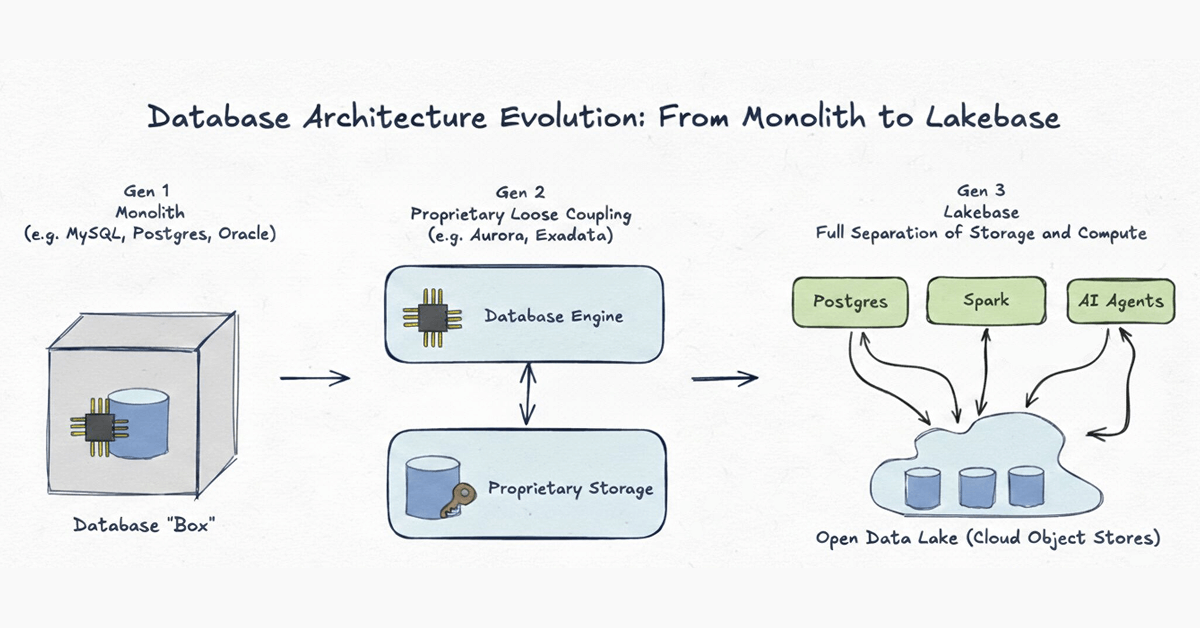
Generación 1: Monolito
Ejemplos: MySQL, Postgres, Oracle clásico
Los sistemas de bases de datos comenzaron como monolitos absolutos. En la era previa a la nube, la red era la parte más lenta de cualquier sistema. La única forma de diseñar una base de datos de alto rendimiento era unir estrechamente la computación (CPU/RAM) y el almacenamiento (disco) dentro de una sola máquina física. Si bien esto tenía sentido para las limitaciones de hardware de la década de 1980, creó una jaula rígida donde los datos quedaban atrapados en formatos propietarios y escalar significaba comprar una caja más grande.
Generación 2: Acoplamiento suelto propietario del almacenamiento
Ejemplos: Aurora, Oracle Exadata
A medida que la infraestructura en la nube mejoró, los proveedores separaron físicamente el almacenamiento de la computación, trasladando el almacenamiento a niveles de backend propietarios. Estos sistemas fueron maravillas de ingeniería que superaron los límites del rendimiento. Sin embargo, no llegaron lo suficientemente lejos. La separación fue puramente una optimización interna. Debido a que los datos permanecen bloqueados dentro de un formato propietario accesible solo por un único motor, los sistemas Gen 2 sufren puntos muertos estructurales:
- Estrangulamiento de un solo motor: Los datos son accesibles solo a través del motor de base de datos principal, que se convierte en el cuello de botella. Es difícil para los agentes de IA o los motores analíticos acceder a los datos a escala.
- Fricción analítica: Debido a que no se puede tener motores OLAP separados accediendo directamente a los archivos de la base de datos a escala, la ejecución de consultas analíticas sigue siendo difícil y generalmente requiere ETL complejo para mover datos.
- Bloqueo en la nube: La capa de almacenamiento a menudo está estrechamente acoplada a la infraestructura propietaria del proveedor de nube específico. Esto dificulta la interoperabilidad multicloud y hace imposibles la alta disponibilidad y la recuperación ante desastres (HADR) verdaderamente entre nubes. Si la región del proveedor falla, sus datos quedan atrapados.
Creemos que estos sistemas están en un estado de transición hacia la tercera generación definitiva.
Generación 3: Lakebase - Almacenamiento abierto en el Lake
Una Lakebase lleva la arquitectura desacoplada a su conclusión lógica definitiva. Al igual que la Gen 2, separa la computación del almacenamiento, pero con una diferencia crítica: tanto la infraestructura de almacenamiento como los formatos de datos son completamente abiertos.
Al construir sobre esta arquitectura, puede resolver los 3 desafíos mencionados anteriormente:
- Mayor confiabilidad y menor costo a través de operaciones más simples: Las operaciones comunes como aprovisionamiento, escalado (ascendente y descendente), ramificación, instantáneas y recuperación se pueden completar en segundos. Las consultas costosas se pueden ejecutar en diferentes instancias de cómputo elástico sin afectar el tráfico de producción.
- Experiencia de desarrollador similar a Git: Es más rápido experimentar y desarrollar aplicaciones, basándose en una rama de alta fidelidad de las bases de datos de producción. Para los desarrolladores y agentes de IA, esto significa que la base de datos se mueve tan rápido como su código.
- Resuelve el bloqueo extremo de proveedores: Con los datos en formatos abiertos almacenados en almacenes de objetos en la nube, usted está mucho menos bloqueado. Usted es dueño de sus datos, independientemente del motor.
En muchos sentidos, una Lakebase es lo que construirías si tuvieras que rediseñar bases de datos OLTP hoy, ahora que el almacenamiento de objetos barato y confiable y la elasticidad de la nube están disponibles. A medida que las organizaciones avanzan más rápido al adoptar la nube y la IA, esperamos que este modelo se convierta en una base estándar para la construcción de sistemas transaccionales.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.