Parcheo sin tiempo de inactividad en Lakebase Parte 1: Precalentamiento
La primera de varias características que hacen invisibles los reinicios de cómputo
por Hans Norheim
- El mantenimiento planificado causa más interrupciones que los fallos no planificados para la mayoría de las bases de datos, ya que los parches ocurren con más frecuencia que los fallos de hardware. El objetivo es hacer que las actualizaciones de versión y los parches de seguridad sean completamente imperceptibles.
- El problema principal con los reinicios de bases de datos es que las cachés en memoria se borran, lo que provoca una degradación del rendimiento de hasta el 70% mientras los datos se recargan desde el almacenamiento. Bajo una carga de trabajo pesada, esto puede escalar de un problema de rendimiento a un problema de disponibilidad.
- Lakebase aborda esto iniciando un nuevo nodo de cómputo en segundo plano antes de un reinicio programado, precalentando su caché utilizando la lista de páginas del principal actual y el flujo WAL, y luego promocionándolo a principal sin costo adicional ni sobrecarga de réplica.
Garantizar que las bases de datos de los clientes estén siempre disponibles es una de las cosas más importantes que hacemos en Lakebase. Hemos diseñado el sistema con redundancia en todos los niveles, conmutando automáticamente y recuperando su base de datos en caso de fallos de hardware o software.
En un sistema a gran escala, tales fallos no planificados son una expectativa estadística, pero para una base de datos individual, no son tan frecuentes. Para una base de datos individual, el mantenimiento planificado tiende a causar más interrupciones en la carga de trabajo. Después de todo, una base de datos típica se parchea con más frecuencia de la que experimenta fallos de hardware.
Hoy en día, casi todos los proveedores de bases de datos operan con ventanas de mantenimiento: períodos en los que su base de datos interrumpe todas las conexiones activas y se actualiza y reinicia en un proceso que puede durar desde unos pocos segundos hasta minutos. Si bien Lakebase le permite programar actualizaciones en un momento que sea óptimo para usted, sigue siendo una breve interrupción cuando ocurre.
Creemos que podemos hacerlo mejor. Esta publicación de blog es la primera de una serie sobre cómo estamos aprovechando la arquitectura de lakebase para eliminar por completo el impacto del mantenimiento planificado. Nuestro objetivo: hacer que las actualizaciones de versión y los parches de seguridad sean completamente imperceptibles.
En esta publicación, cubriremos el precalentamiento: una técnica que previene cualquier degradación del rendimiento que sigue a un reinicio de la base de datos. En futuras publicaciones, analizaremos las mejoras en el propio proceso de conmutación por error y optimizaciones adicionales que nos acercan al verdadero parcheo sin tiempo de inactividad.
El problema con los reinicios en frío
El desafío al reiniciar PostgreSQL es que las cachés en memoria (específicamente la caché de búfer y la caché de archivos local) se pierden. A pesar de que la base de datos vuelve a estar en línea muy rápidamente (1 segundo @ P99), la carga de trabajo puede experimentar una desaceleración en los primeros minutos después del reinicio; vimos una reducción de ~70% en pgbench TPS. Esto se debe a una baja tasa de aciertos de caché mientras los datos se vuelven a leer del almacenamiento y la caché se calienta. Si bien esto puede parecer solo un problema de rendimiento, puede ser un problema de disponibilidad si la desaceleración es lo suficientemente grave como para que la base de datos no pueda seguir el ritmo de la carga de trabajo y ocurran tiempos de espera agotados.
Existen técnicas para abordar esto en Postgres: se puede usar pg_prewarm para precalentar las cachés de búfer. Sin embargo, esto se ejecuta después de un reinicio, cuando la carga de trabajo ya está afectada. La replicación de transmisión se puede usar para configurar una réplica, que puede precalentarse antes de conmutar por error a ella (promoviéndola a principal). Sin embargo, esto requiere crear una réplica completa y orquestar cuidadosamente el precalentamiento antes de la conmutación por error.
Precalentamiento en la arquitectura Lakebase
En la arquitectura de lakebase, combinamos nodos de cómputo elásticos y sin estado con almacenamiento compartido y desagregado. Los nodos de cómputo emplean cachés locales para ofrecer el máximo rendimiento sin sacrificar las propiedades sin servidor. Si bien la caché enfrenta los mismos problemas de arranque en frío descritos anteriormente, tenemos más opciones con la arquitectura Lakebase.
Dado que las réplicas de cómputo de Postgres de Lakebase no tienen estado, podemos iniciarlas y detenerlas según sea necesario. Utilizamos esto y lo combinamos con el precalentamiento automático en reinicios planificados para minimizar el impacto en el rendimiento de la carga de trabajo. Así es como funciona:
- Una nueva versión de la imagen de cómputo de Postgres de Lakebase está disponible. Recibe una notificación y puede programar el reinicio para un momento que le convenga.
- Poco antes de la hora programada, nuestro plano de control inicia un nuevo cómputo de Postgres en segundo plano. Usted no lo ve y no se le factura por él. La carga de trabajo del principal actual no se ve afectada.
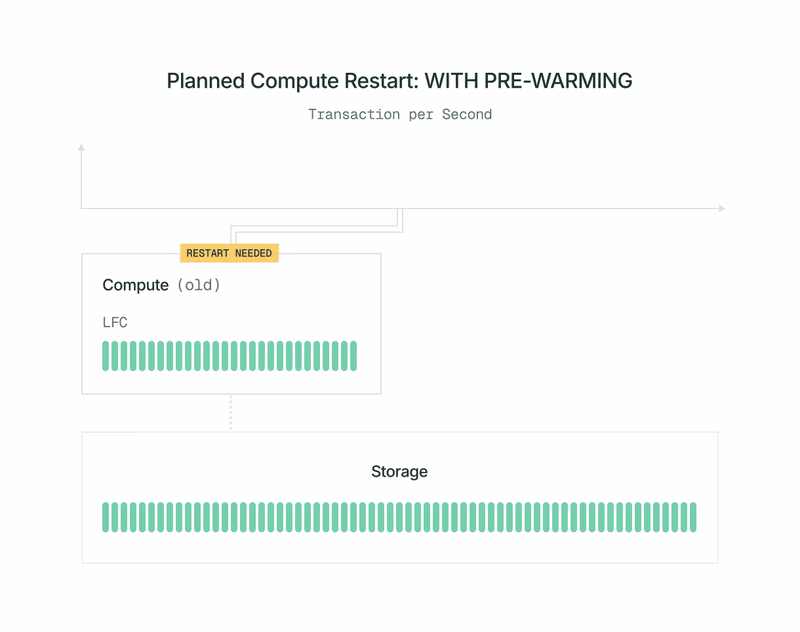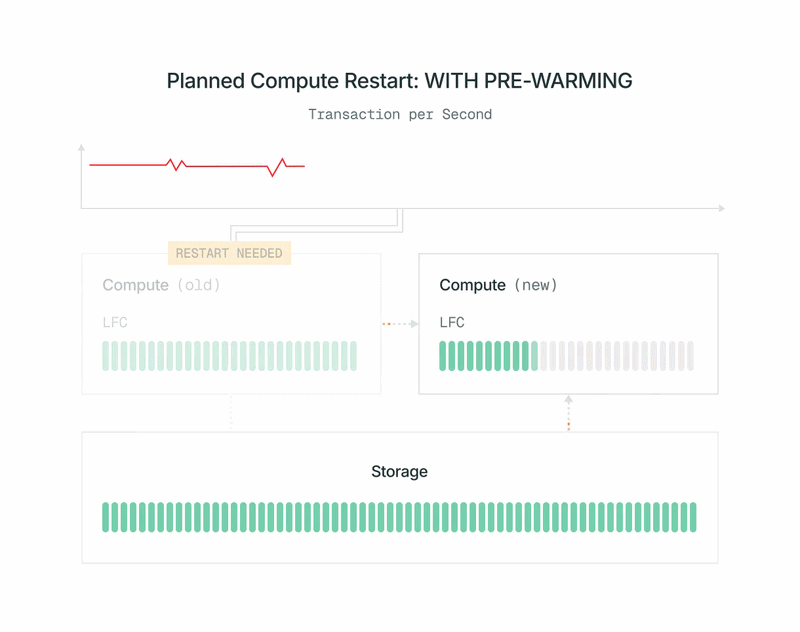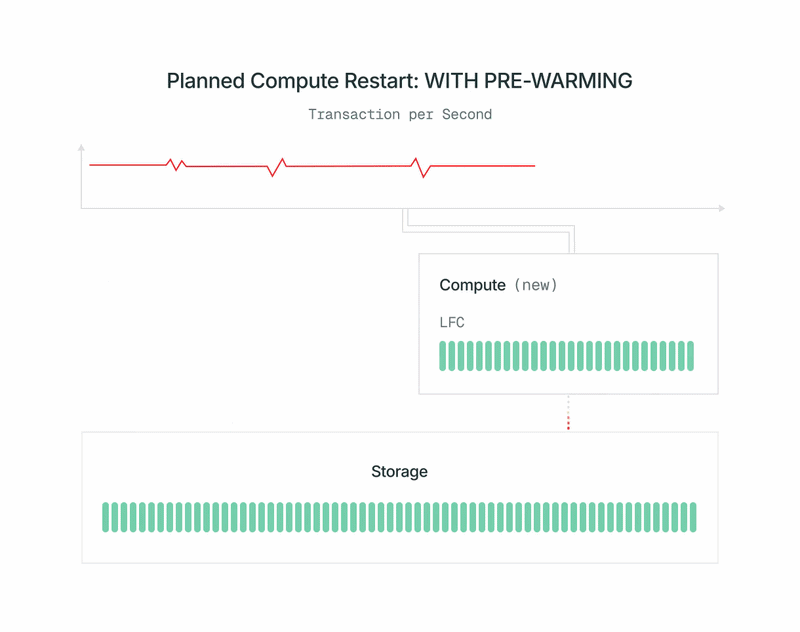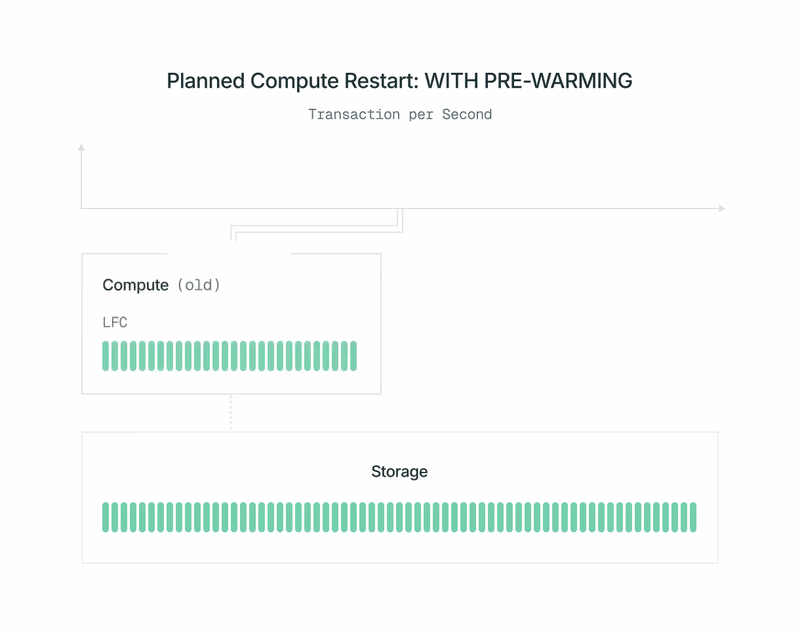
- Se envía una lista de páginas en la caché del principal actual al nuevo cómputo. El nuevo cómputo carga esas páginas en la caché desde nuestro nivel de almacenamiento compartido sin afectar al principal.
- El nuevo cómputo se suscribe al WAL (registro de escritura anticipada) para mantener su caché actualizada. Para mayor eficiencia, a diferencia de una réplica normal de Postgres, puede ignorar todos los registros WAL que no afecten a su caché. Obtiene el WAL de nuestros Safekeepers, lo que no supone una carga adicional para el cómputo principal.
- Cuando se completa el precalentamiento, apagamos rápidamente el principal antiguo, promovemos el nuevo cómputo a principal y lo cambiamos. La promoción utiliza el estándar pg_promote de OSS Postgres y no reinicia el servidor de la base de datos.
Antes:

Después:
Con la arquitectura lakebase, obtiene esto sin costo adicional, sin pagar por réplicas adicionales. A partir de hoy, todos los reinicios planificados de los puntos de conexión de lectura/escritura se realizan de esta manera sin que usted tenga que hacer nada. Pronto lo extenderemos también a los puntos de conexión de solo lectura.
Resultados
Para medir el impacto de las cachés en frío, ejecutamos pgbench de 10 GB (factor de escala 670) en una base de datos mientras la reiniciábamos, primero con precalentamiento habilitado, y luego sin precalentamiento. El primer gráfico muestra una carga de trabajo de solo lectura (pgbench “select only”), mientras que el segundo muestra una carga de trabajo de lectura/escritura (pgbench “simple update”).


En ambos casos, vemos que el rendimiento se recupera casi instantáneamente con el precalentamiento. Sin precalentamiento, la recuperación es mucho más lenta mientras la caché fría se calienta. La diferencia es más marcada para la carga de trabajo de solo lectura porque el precalentamiento mejora la tasa de aciertos de caché, lo que ayuda a las lecturas proporcionalmente más que a las escrituras.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.