Lakeflow Connect: Ingestión de datos eficiente y sencilla con el conector de SQL Server
Explora el conector SQL Server totalmente administrado de Databricks Lakeflow Connect para simplificar la ingesta e integración de datos sin problemas con las herramientas de Databricks para el procesamiento y análisis de datos.
por Andrea Tardif, Prasanna Selvaraj, Hector Bustamante y Phanitha Kommareddi
- Las principales empresas tecnológicas se enfrentan a desafíos complejos al extraer valor de sus datos de SQL Server para IA y análisis.
- Lakeflow Connect para SQL Server proporciona una ingesta incremental y eficiente tanto para bases de datos locales como en la nube.
- Este blog revisa las consideraciones arquitectónicas, los requisitos previos y las instrucciones paso a paso para ingerir datos de SQL Server en tu lakehouse.
Complejidades de la Extracción de Datos de SQL Server
Si bien las empresas nativas digitales reconocen el papel fundamental de la IA en el impulso de la innovación, muchas todavía enfrentan desafíos para que sus datos estén fácilmente disponibles para usos posteriores, como el desarrollo de machine learning y el análisis avanzado. Para estas organizaciones, dar soporte a equipos de negocio que dependen de SQL Server significa contar con recursos de ingeniería de datos y mantener conectores personalizados, preparar datos para análisis y asegurar que estén disponibles para los equipos de datos para el desarrollo de modelos. A menudo, estos datos deben enriquecerse con fuentes adicionales y transformarse antes de que puedan informar decisiones basadas en datos.
Mantener estos procesos rápidamente se vuelve complejo y frágil, lo que frena la innovación. Es por eso que Databricks desarrolló Lakeflow Connect, que incluye conectores de datos integrados para bases de datos populares, aplicaciones empresariales y fuentes de archivos. Estos conectores proporcionan una ingesta incremental eficiente de extremo a extremo, son flexibles y fáciles de configurar, y están completamente integrados con la Plataforma de Inteligencia de Datos de Databricks para una gobernanza, observabilidad y orquestación unificadas. El nuevo conector Lakeflow para SQL Server es el primer conector de base de datos con una integración robusta tanto para bases de datos locales como en la nube para ayudar a obtener información de los datos desde dentro de Databricks.
En este blog, revisaremos las consideraciones clave para cuándo usar Lakeflow Connect para SQL Server y explicaremos cómo configurar el conector para replicar datos de una instancia de Azure SQL Server. Luego, revisaremos un caso de uso específico, las mejores prácticas y cómo empezar.
Consideraciones Clave de Arquitectura
A continuación, se presentan las consideraciones clave para ayudar a decidir cuándo usar el conector de SQL Server.
Compatibilidad de Región y Características
Lakeflow Connect admite una amplia gama de variaciones de bases de datos de SQL Server, incluida Microsoft Azure SQL Database, Amazon RDS para SQL Server, Microsoft SQL Server que se ejecuta en Azure VMs y Amazon EC2, y SQL Server local al que se accede a través de Azure ExpressRoute o AWS Direct Connect.
Dado que Lakeflow Connect se ejecuta en canalizaciones sin servidor (Serverless) internamente, se pueden aprovechar características integradas como la observabilidad de la canalización, las alertas de registro de eventos y la supervisión del lakehouse. Si la computación sin servidor no es compatible en su región, comuníquese con su equipo de cuenta de Databricks para presentar una solicitud que ayude a priorizar el desarrollo o la implementación en esa región.
Lakeflow Connect se basa en la Plataforma de Inteligencia de Datos, que proporciona una integración perfecta con Unity Catalog (UC) para reutilizar permisos y controles de acceso establecidos en nuevas fuentes de SQL Server para una gobernanza unificada. Si sus tablas y vistas de Databricks están en Hive, le recomendamos actualizarlas a UC para beneficiarse de estas características (AWS | Azure | GCP)!
Requisitos de Datos de Cambio
Lakeflow Connect se puede integrar con SQL Server con seguimiento de cambios (CT) de Microsoft o captura de datos de cambios (CDC) de Microsoft habilitada para admitir una ingesta incremental eficiente.
CDC proporciona información histórica de cambios sobre operaciones de inserción, actualización y eliminación, y cuándo los datos reales han cambiado. El seguimiento de cambios identifica qué filas se modificaron en una tabla sin capturar los cambios reales de los datos. Obtenga más información sobre CDC y los beneficios de usar CDC con SQL Server.
Databricks recomienda usar el seguimiento de cambios para cualquier tabla con una clave principal para minimizar la carga en la base de datos de origen. Para tablas de origen sin clave principal, use CDC. Obtenga más información sobre cuándo usarlo aquí.
El conector de SQL Server captura una carga inicial de datos históricos en la primera ejecución de su canalización de ingesta. Luego, el conector rastrea e ingiere solo los cambios realizados en los datos desde la última ejecución, aprovechando las características CT/CDC de SQL Server para optimizar las operaciones y la eficiencia.
Gobernanza y Seguridad de Red Privada
Cuando se establece una conexión con SQL Server usando Lakeflow Connect:
- El tráfico entre la interfaz del cliente y el plano de control está cifrado en tránsito usando TLS 1.2 o posterior.
- El volumen de staging, donde se almacenan los archivos sin procesar durante la ingesta, está cifrado por el proveedor de almacenamiento en la nube subyacente.
- Los datos en reposo están protegidos siguiendo las mejores prácticas y los estándares de cumplimiento.
- Cuando se configura con puntos de conexión privados, todo el tráfico de datos permanece dentro de la red privada del proveedor de la nube, evitando Internet público.
Una vez que los datos se ingieren en Databricks, se cifran como otros conjuntos de datos dentro de UC. La puerta de enlace de ingesta que extrae instantáneas, registros de cambios y metadatos de la base de datos de origen aterriza en un Volumen de UC, una abstracción de almacenamiento ideal para registrar conjuntos de datos no tabulares como archivos JSON. Este Volumen de UC reside dentro de la cuenta de almacenamiento en la nube del cliente dentro de sus Redes Virtuales o Nubes Privadas Virtuales.
Además, UC aplica controles de acceso de grano fino y mantiene pistas de auditoría para gobernar el acceso a estos datos recién ingeridos. Las credenciales de servicio de UC y las credenciales de almacenamiento se almacenan como objetos protegibles dentro de UC, lo que garantiza una gestión de autenticación segura y centralizada. Estas credenciales nunca se exponen en los registros ni se codifican en canalizaciones de ingesta SQL, lo que proporciona una protección y un control de acceso robustos.
Si su organización cumple con los criterios anteriores, considere Lakeflow Connect para SQL Server para ayudar a simplificar la ingesta de datos en Databricks.
Desglose de la Solución Técnica
A continuación, revise los pasos para configurar Lakeflow Connect para SQL Server y replicar datos de una instancia de Azure SQL Server.
Configurar Permisos de Unity Catalog
Dentro de Databricks, asegúrese de que la computación sin servidor esté habilitada para notebooks, flujos de trabajo y canalizaciones (AWS | Azure | GCP). Luego, valide que el usuario o principal de servicio que crea la canalización de ingesta tenga los siguientes permisos de UC:
| Tipo de Permiso | Razón | Documentación |
| CREATE CONNECTION en el metastore | Lakeflow Connect necesita establecer una conexión segura con SQL Server. | CREATE CONNECTION |
| USE CATALOG en el catálogo de destino | Requerido ya que proporciona acceso al catálogo donde Lakeflow Connect depositará las tablas de datos de SQL Server en UC. | USE CATALOG |
| USE SCHEMA, CREATE TABLE, y CREATE VOLUME en un esquema existente o CREATE SCHEMA en el catálogo de destino | Proporciona los derechos necesarios para acceder a esquemas y crear ubicaciones de almacenamiento para las tablas de datos ingeridas. | GRANT PRIVILEGES |
| Permisos sin restricciones para crear clústeres o una política de clúster personalizada | Requerido para iniciar los recursos de cómputo necesarios para el proceso de ingesta de la puerta de enlace | MANAGE COMPUTE POLICIES |
Configurar Azure SQL Server
Para usar el conector de SQL Server, confirme que se cumplen los siguientes requisitos:
- Confirmar la versión de SQL
- SQL Server 2012 o una versión posterior debe estar habilitada para usar el seguimiento de cambios. Sin embargo, se recomienda 2016+*. Revise los requisitos de la versión de SQL aquí.
- Configurar la cuenta de servicio de la base de datos dedicada a la ingesta de Databricks.
- Habilitar el seguimiento de cambios o CDC incorporado
- Debe tener SQL Server 2012 o una versión posterior para usar CDC. Las versiones anteriores a SQL Server 2016 requieren adicionalmente la edición Enterprise.
* Requisitos a partir de mayo de 2025. Sujetos a cambios.
Ejemplo: Ingesta desde Azure SQL Server a Databricks
A continuación, ingeriremos una tabla de una base de datos de Azure SQL Server a Databricks usando Lakeflow Connect. En este ejemplo, CDC y CT proporcionan una descripción general de todas las opciones disponibles. Dado que la tabla en este ejemplo tiene una clave principal, CT podría haber sido la opción principal. Sin embargo, dado que solo hay una tabla pequeña en este ejemplo, no hay preocupación por la sobrecarga de carga, por lo que también se incluyó CDC. Se recomienda revisar cuándo usar CDC, CT o ambos para determinar cuál es el mejor para sus datos y requisitos de actualización.
1. [Azure SQL Server] Verificar y configurar Azure SQL Server para CDC y CT
Comience accediendo al portal de Azure e iniciando sesión con sus credenciales de cuenta de Azure. En el lado izquierdo, haga clic en Todos los servicios y busque SQL Servers. Busque y haga clic en su servidor, y haga clic en el ‘Editor de consultas’; en este ejemplo, se seleccionó sqlserver01.
La siguiente captura de pantalla muestra que la base de datos de SQL Server tiene una tabla llamada ‘drivers’.
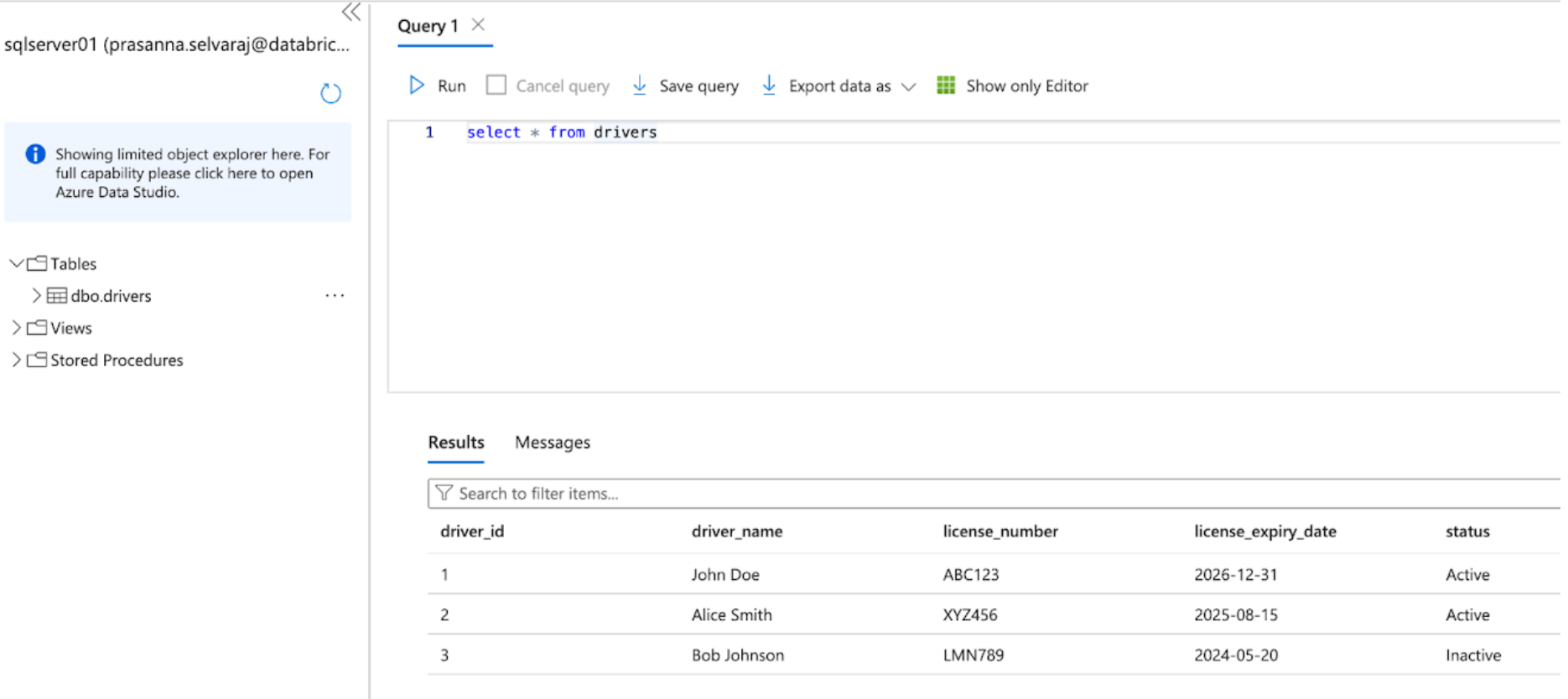
Antes de replicar los datos a Databricks, se debe habilitar la captura de datos de cambios, el seguimiento de cambios o ambos.
Para este ejemplo, se ejecuta el siguiente script en la base de datos para habilitar CT:
Este comando habilita el seguimiento de cambios para la base de datos con los siguientes parámetros:
- CHANGE_RETENTION = 3 DAYS: Este valor rastrea los cambios durante 3 días (72 horas). Se requerirá una actualización completa si su puerta de enlace está fuera de línea durante más tiempo que el tiempo establecido. Se recomienda aumentar este valor si se esperan interrupciones más prolongadas.
- AUTO_CLEANUP = ON: Esta es la configuración predeterminada. Para mantener el rendimiento, elimina automáticamente los datos de seguimiento de cambios anteriores al período de retención.
Luego, se ejecuta el siguiente script en la base de datos para habilitar CDC:
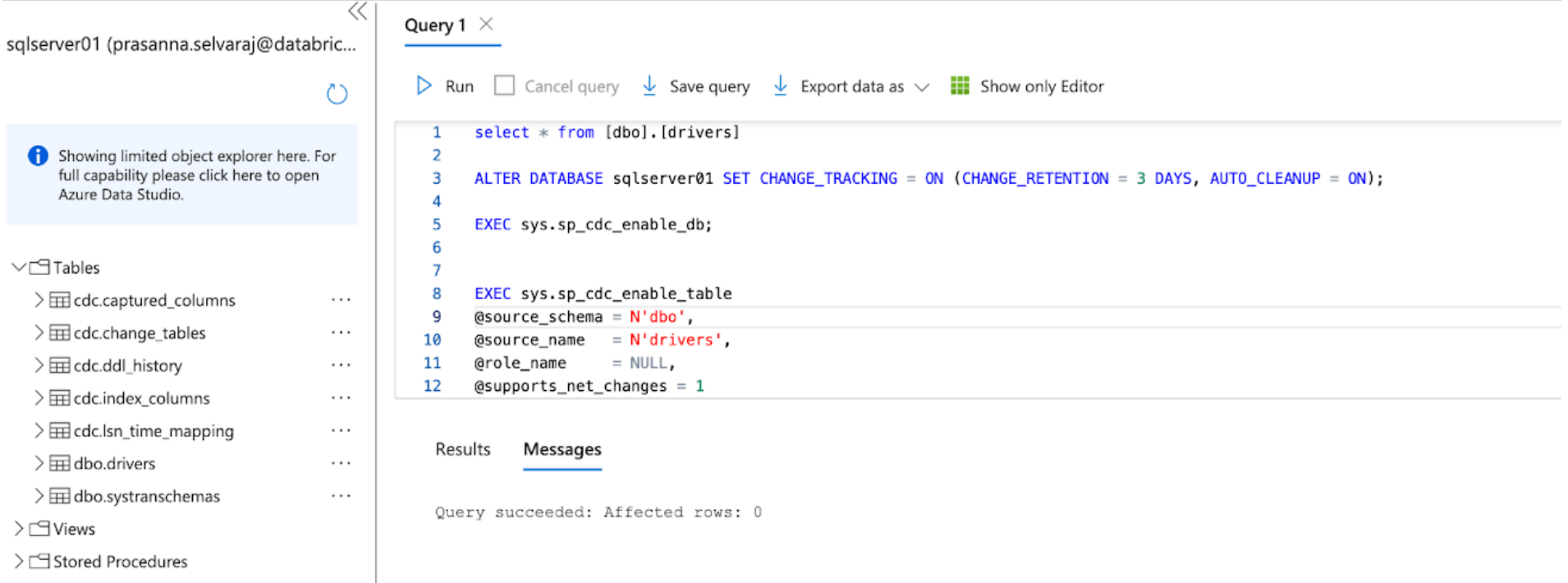
Cuando ambos scripts terminen de ejecutarse, revise la sección de tablas bajo la instancia de SQL Server en Azure y asegúrese de que se creen todas las tablas de CDC y CT.
2. [Databricks] Configurar el conector de SQL Server en Lakeflow Connect
En el siguiente paso, se mostrará la interfaz de usuario de Databricks para configurar el conector de SQL Server. Alternativamente, también se pueden aprovechar los Databricks Asset Bundles (DABs), una forma programática de administrar las canalizaciones de Lakeflow Connect como código. Un ejemplo del script completo de DABs se encuentra en el apéndice a continuación.
Una vez que se establecen todos los permisos, como se describe en la sección Requisitos previos de permisos, está listo para ingerir datos. Haga clic en el botón + Nuevo en la parte superior izquierda, luego seleccione Agregar o cargar datos.
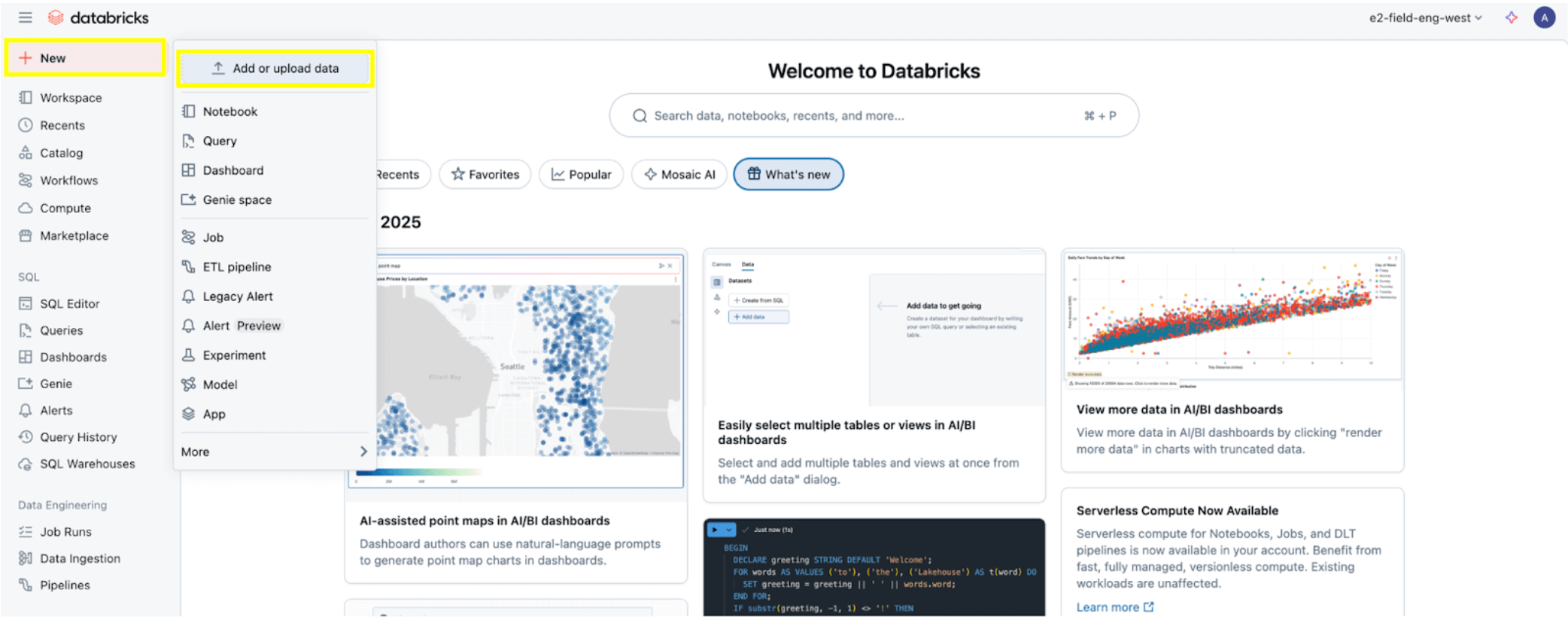
Luego, seleccione la opción SQL Server.
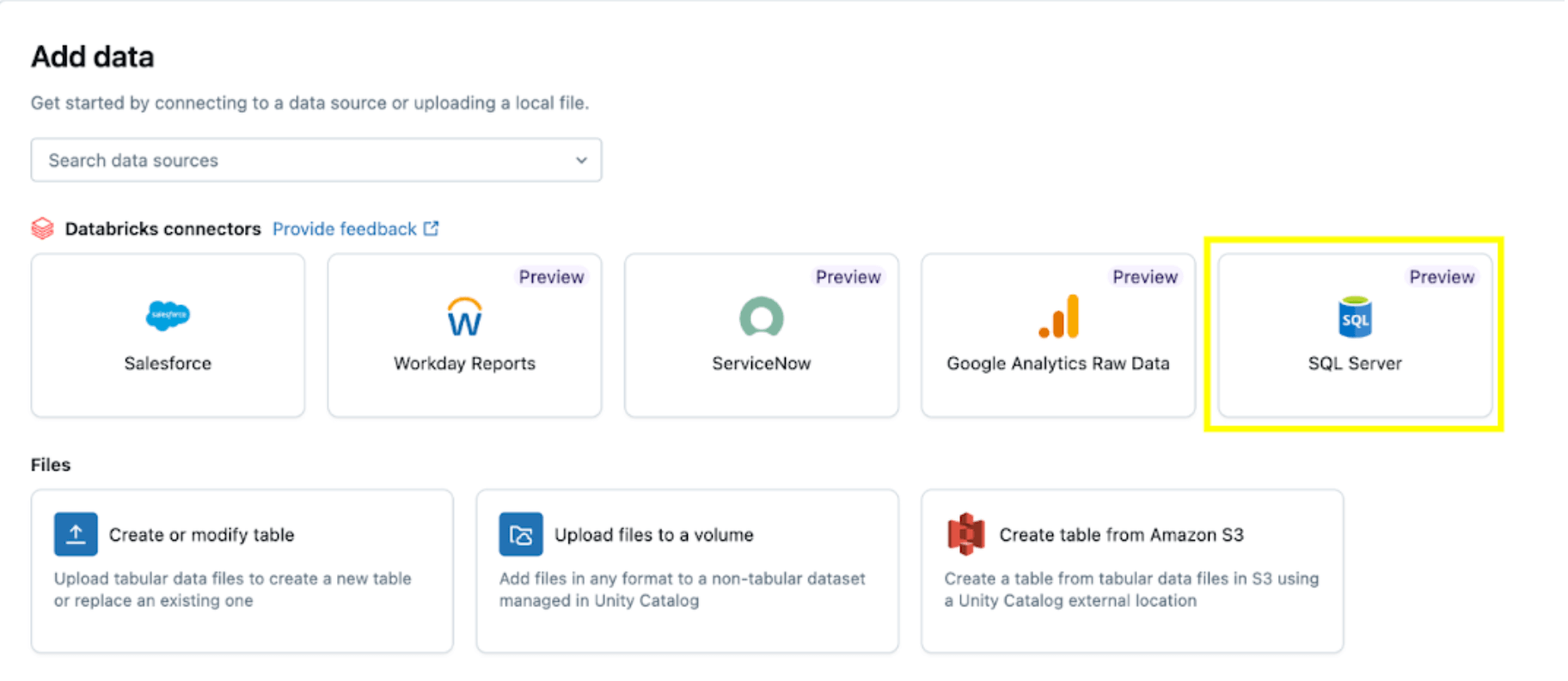
El conector de SQL Server se configura en varios pasos.
1. Configure la puerta de enlace de ingesta (AWS | Azure | GCP). En este paso, proporcione un nombre para la pipeline de la puerta de enlace de ingesta y un catálogo y esquema para la ubicación del volumen de UC para extraer instantáneas y cambiar continuamente los datos de la base de datos de origen.
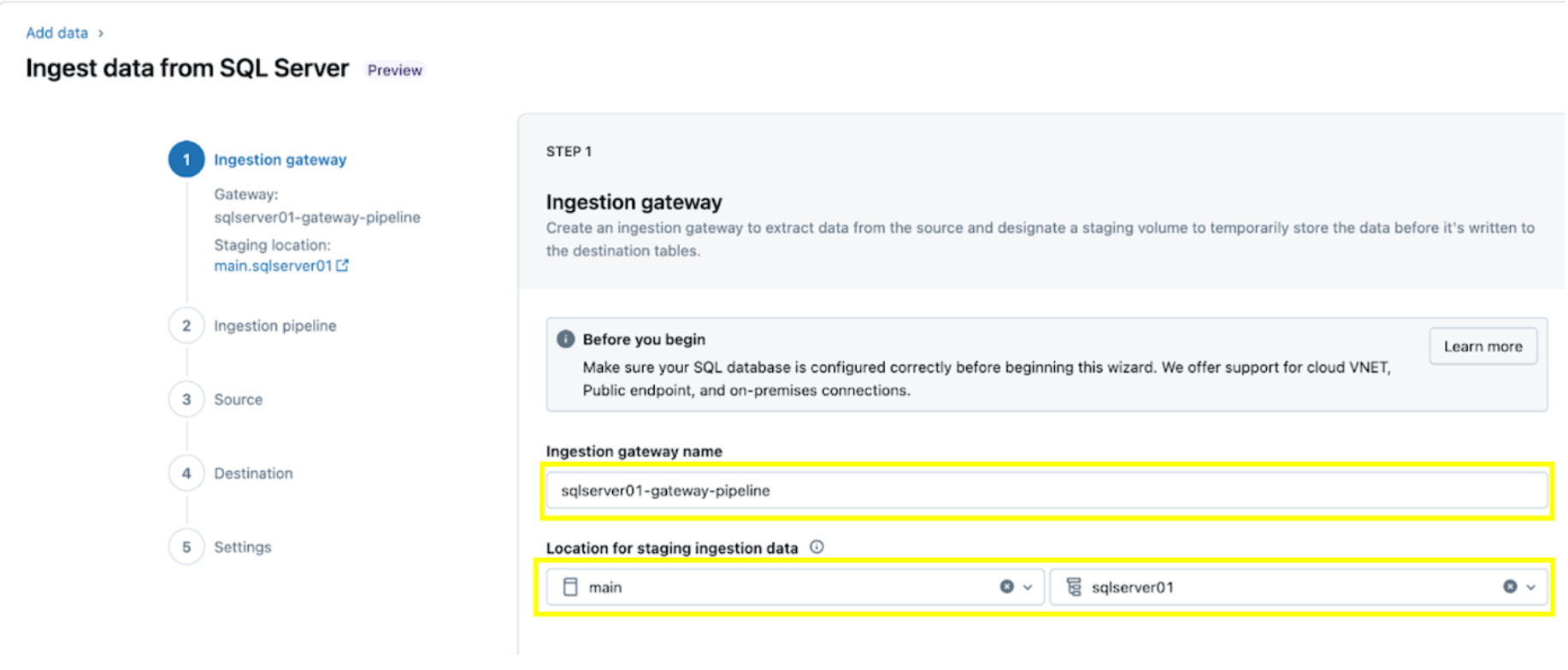
2. Configure la pipeline de ingesta. Esto replica la fuente de datos CDC/CT y los eventos de evolución del esquema. Se requiere una conexión de SQL Server, que se crea a través de la interfaz de usuario siguiendo estos pasos o con el siguiente código SQL a continuación:
Para este ejemplo, nombre la conexión del servidor SQL rebel como se muestra.
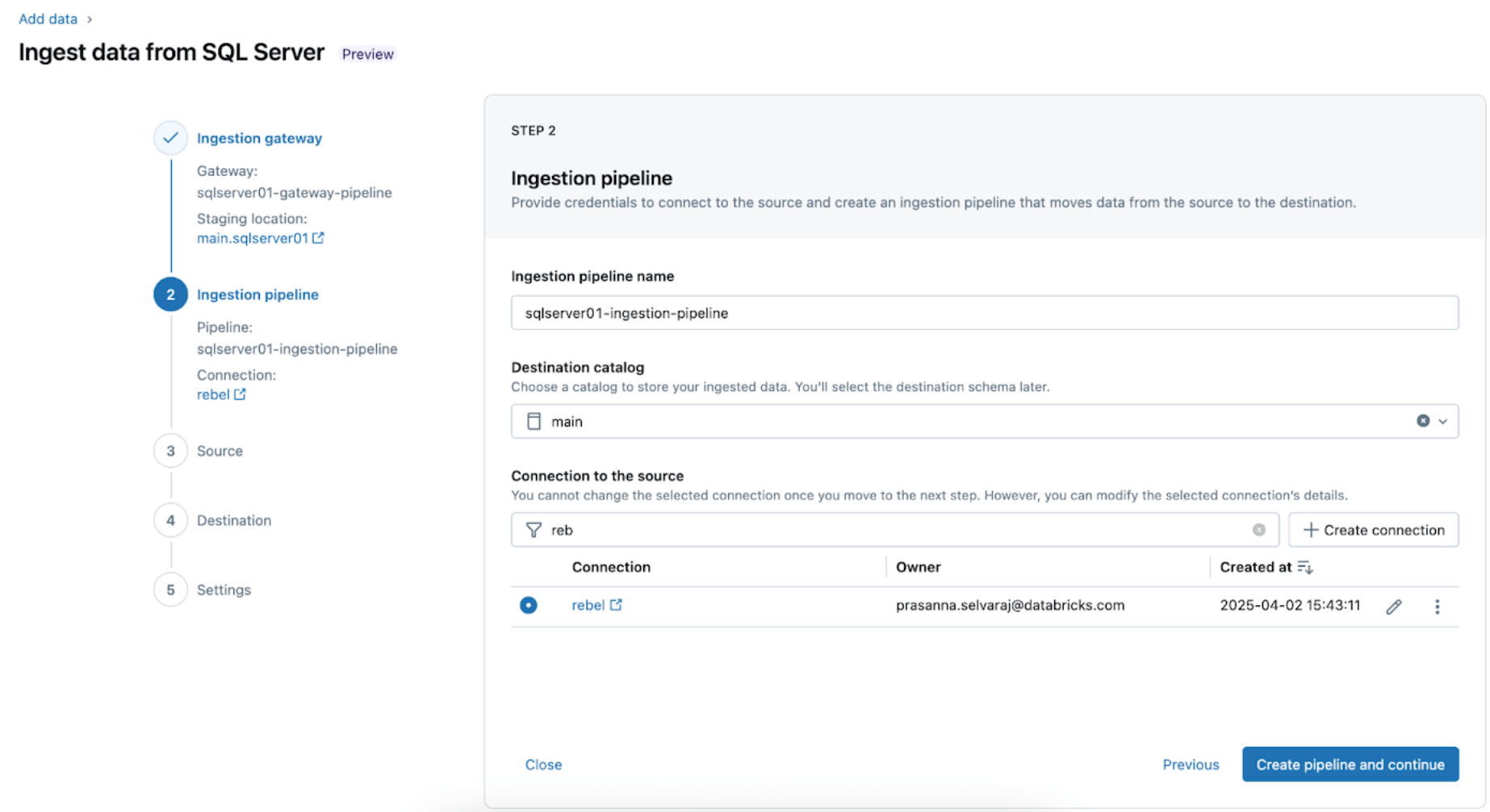
3. Seleccionar las tablas de SQL Server para la replicación. Selecciona todo el esquema para que se ingiera en Databricks en lugar de elegir tablas individuales para ingerir.
Todo el esquema se puede ingerir en Databricks durante la exploración inicial o las migraciones. Si el esquema es grande o excede el número permitido de tablas por canalización (consulta los límites del conector), Databricks recomienda dividir la ingesta en varias canalizaciones para mantener un rendimiento óptimo. Para flujos de trabajo específicos de casos de uso, como un único modelo de ML, un panel o un informe, generalmente es más eficiente ingerir tablas individuales adaptadas a esa necesidad específica, en lugar de todo el esquema.
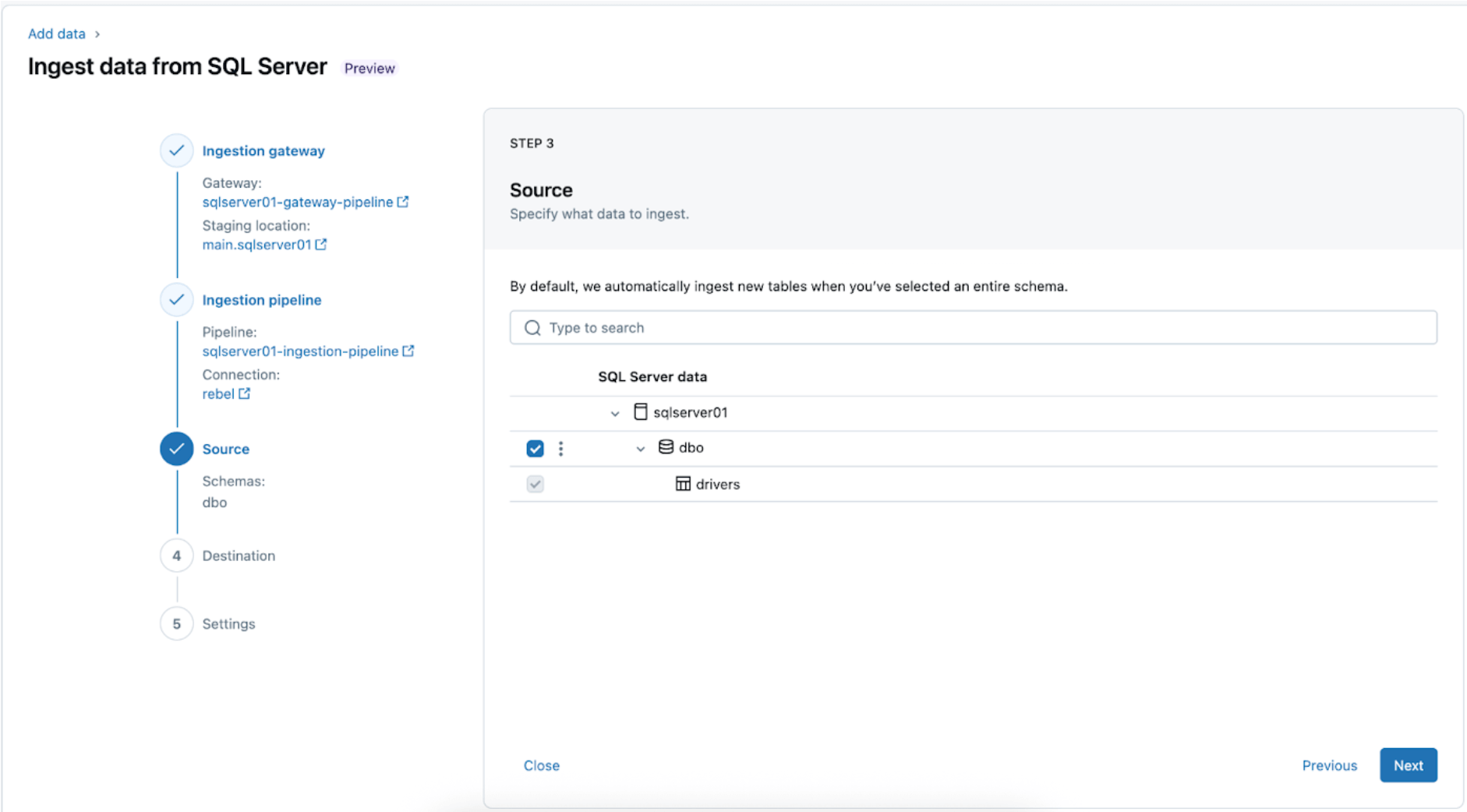
4. Configura el destino donde se replicarán las tablas de SQL Server dentro de UC. Selecciona el catálogo main y el esquema sqlserver01 para depositar los datos en UC.
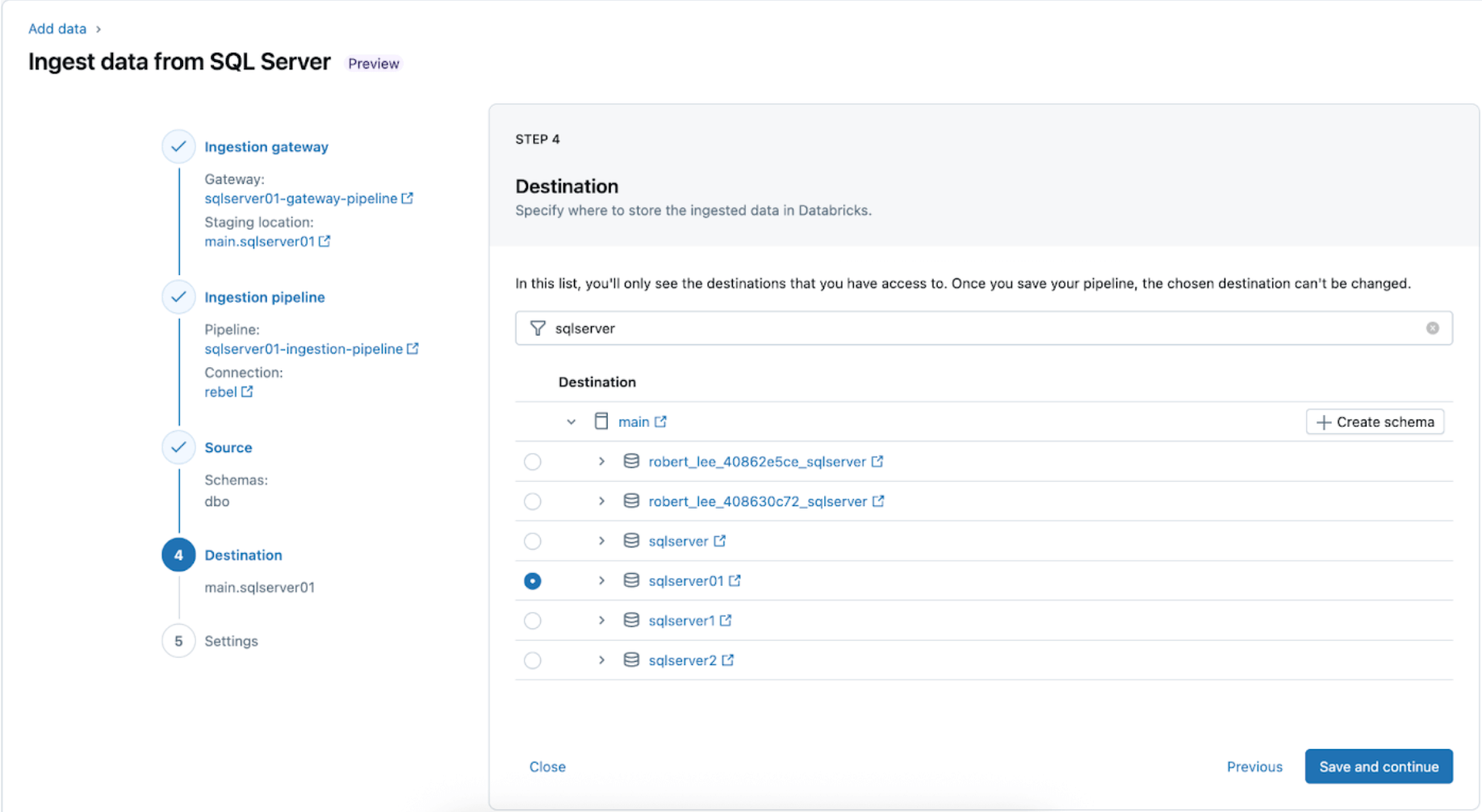
5. Configura las programaciones y las notificaciones (AWS | Azure | GCP). Este paso final ayudará a determinar con qué frecuencia se ejecutará la canalización y a dónde se enviarán los mensajes de éxito o error. Configura la canalización para que se ejecute cada 6 horas y notifique al usuario solo de los errores de la canalización. Este intervalo se puede configurar para satisfacer las necesidades de tu carga de trabajo.
La canalización de ingesta se puede activar con una programación personalizada. Lakeflow Connect creará automáticamente un trabajo dedicado para cada activación de canalización programada. La canalización de ingesta es una tarea dentro del trabajo. Opcionalmente, se pueden agregar más tareas antes o después de la tarea de ingesta para cualquier procesamiento posterior.
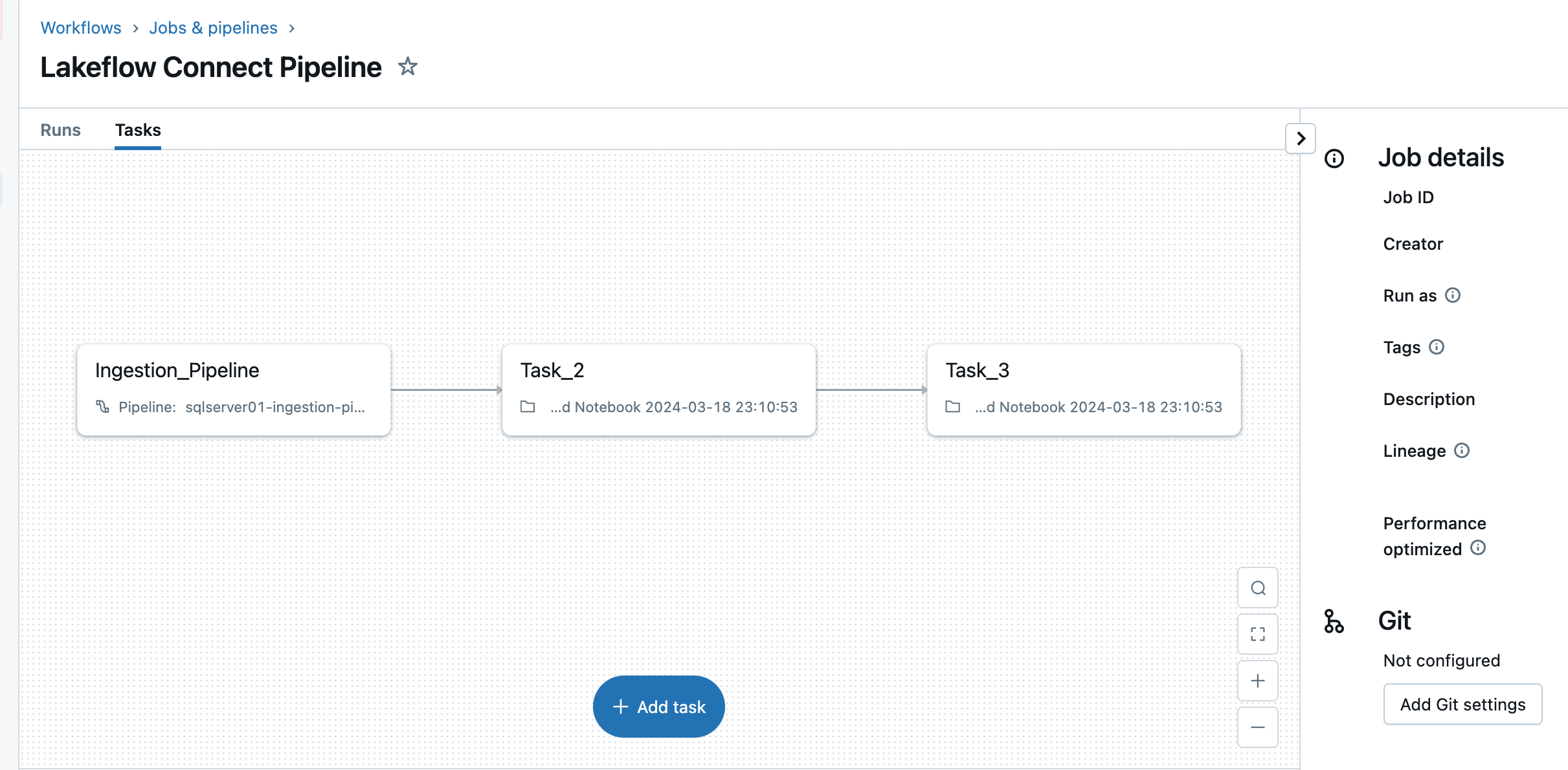
Después de este paso, la canalización de ingesta se guarda y se activa, iniciando una carga completa de datos desde SQL Server a Databricks.
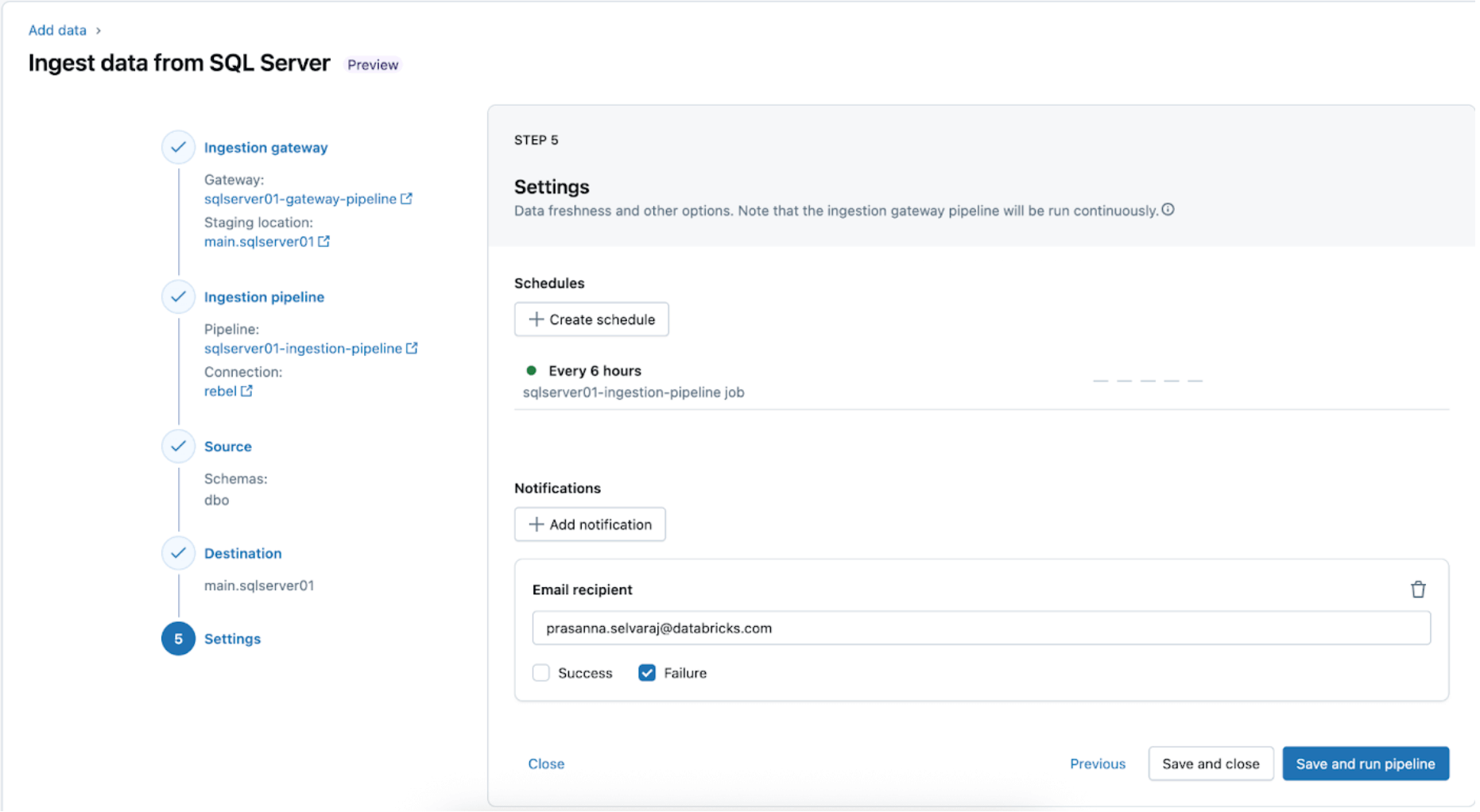
3. [Databricks] Validar ejecuciones exitosas de las canalizaciones de puerta de enlace e ingesta
Navega al menú de Canalizaciones para verificar si la canalización de ingesta de la puerta de enlace se está ejecutando. Una vez completada, busca 'update_progress' en la interfaz del registro de eventos de la canalización en el panel inferior para asegurarte de que la puerta de enlace ingiere correctamente los datos de origen.
Para verificar el estado de sincronización, navega al menú de canalizaciones. La captura de pantalla a continuación muestra que la canalización de ingesta ha realizado tres operaciones de inserción y actualización (UPSERT).
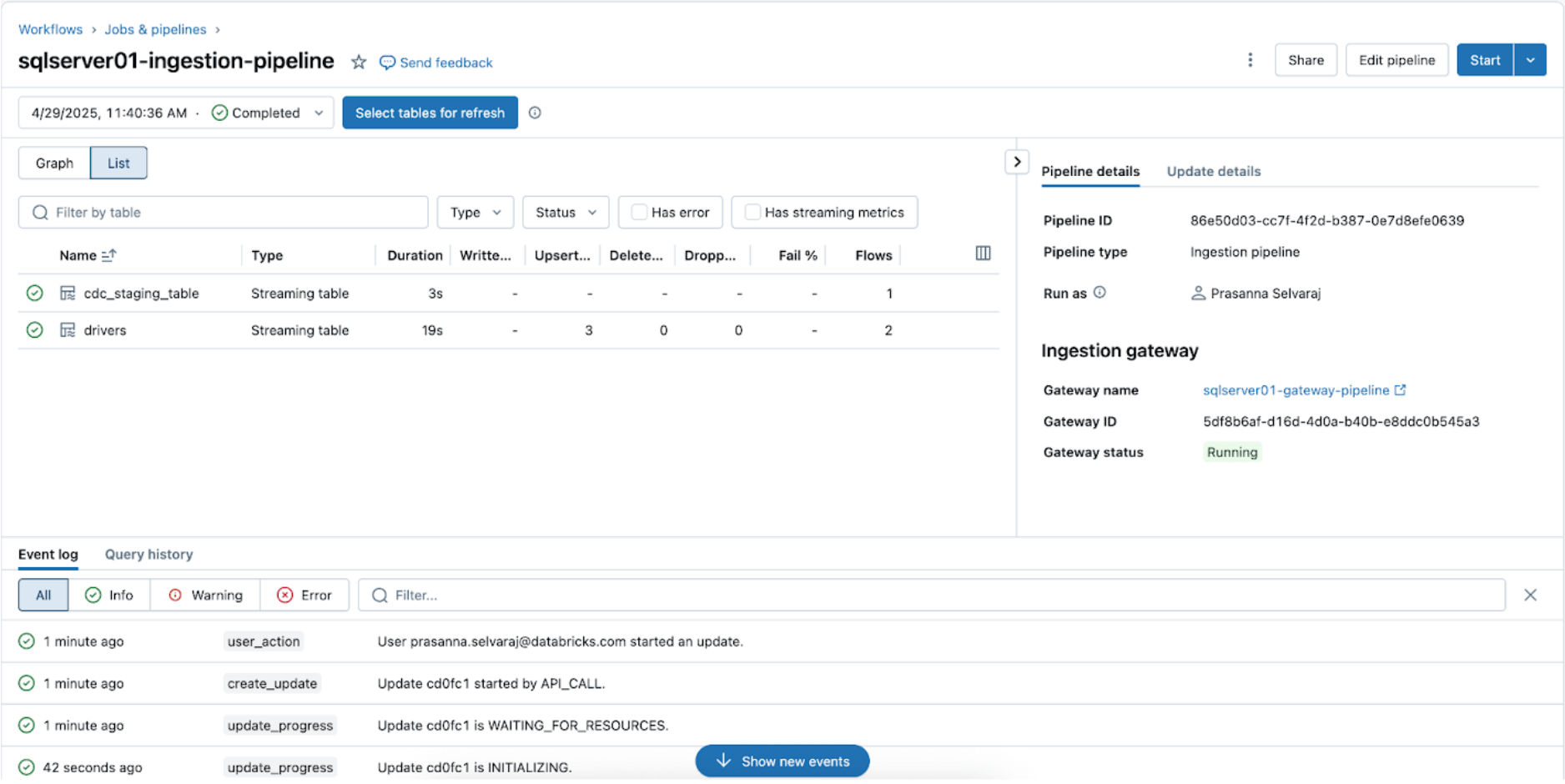
Navega al catálogo de destino, main, y esquema, sqlserver01, para ver la tabla replicada, como se muestra a continuación.

4. [Databricks] Probar CDC y evolución del esquema
A continuación, verifica un evento CDC realizando operaciones de inserción, actualización y eliminación en la tabla de origen. La captura de pantalla del SQL Server de Azure a continuación muestra los tres eventos.
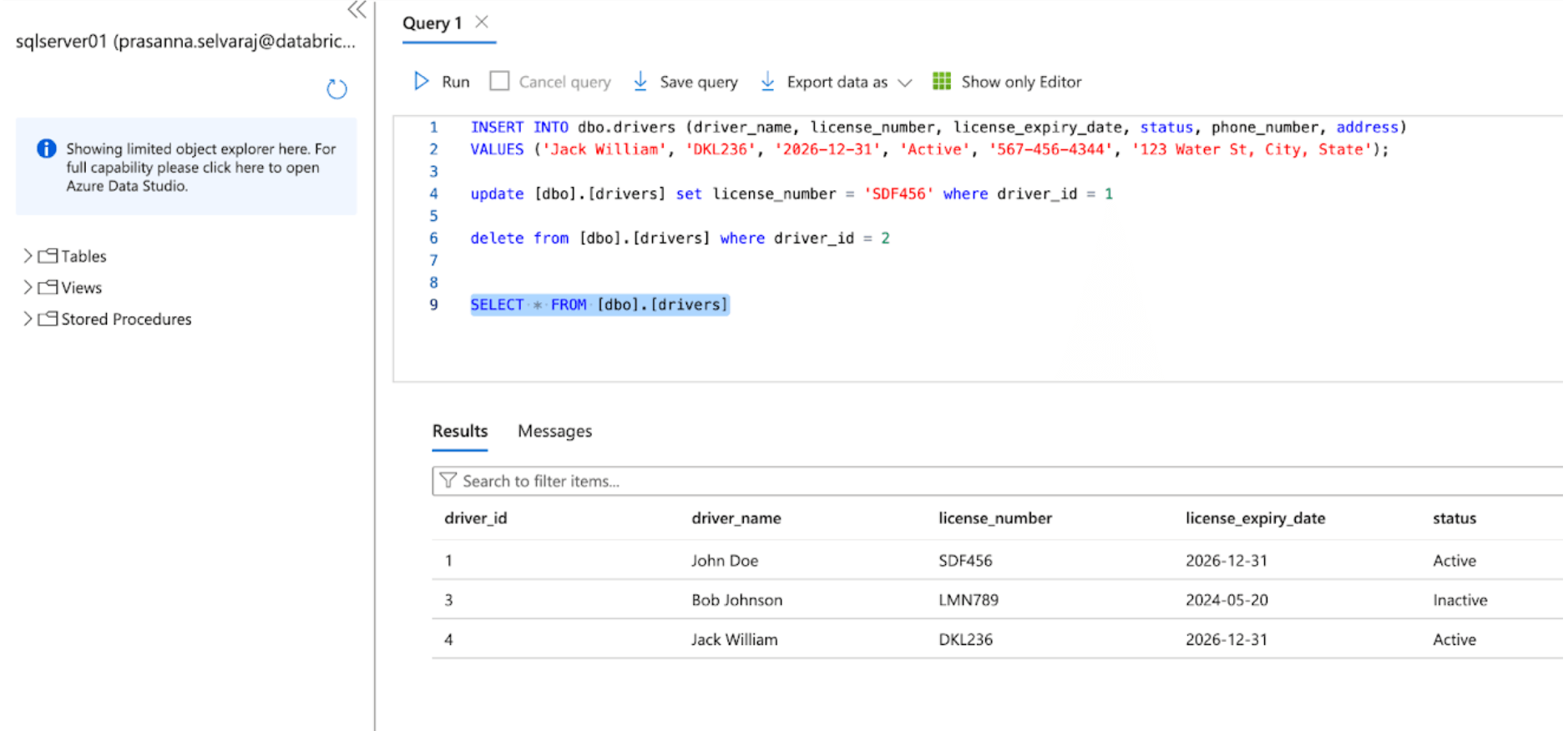
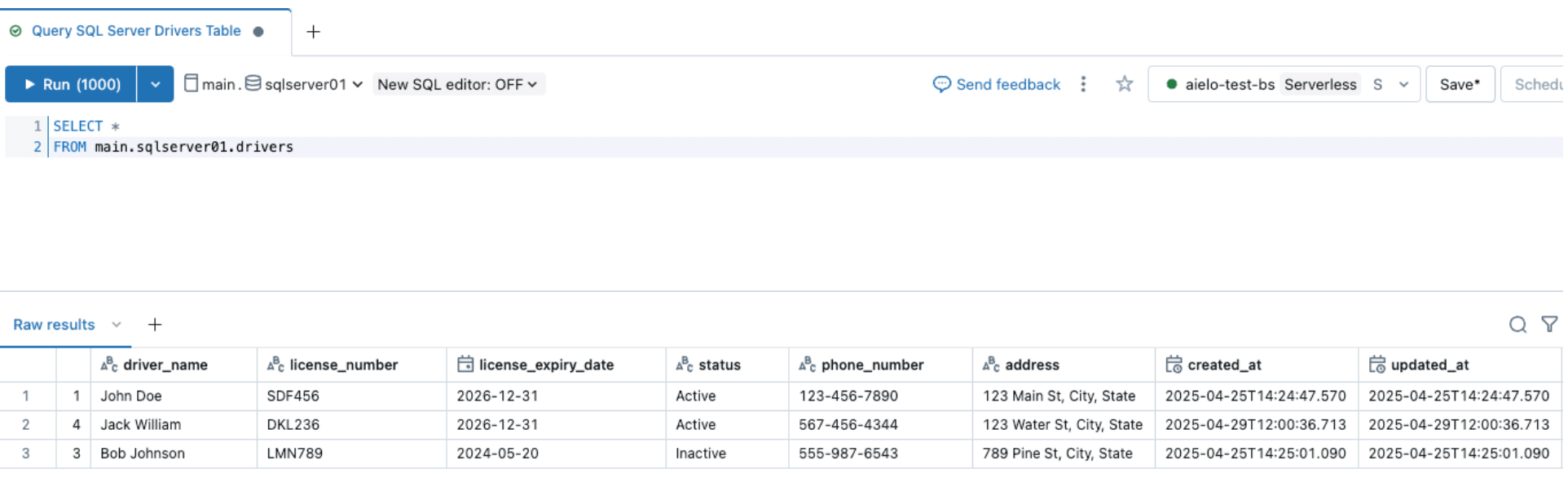
Una vez que la canalización se active y se complete, consulta la tabla delta bajo el esquema de destino y verifica los cambios.
Del mismo modo, realicemos un evento de evolución de esquema y agreguemos una columna a la tabla de origen de SQL Server, como se muestra a continuación

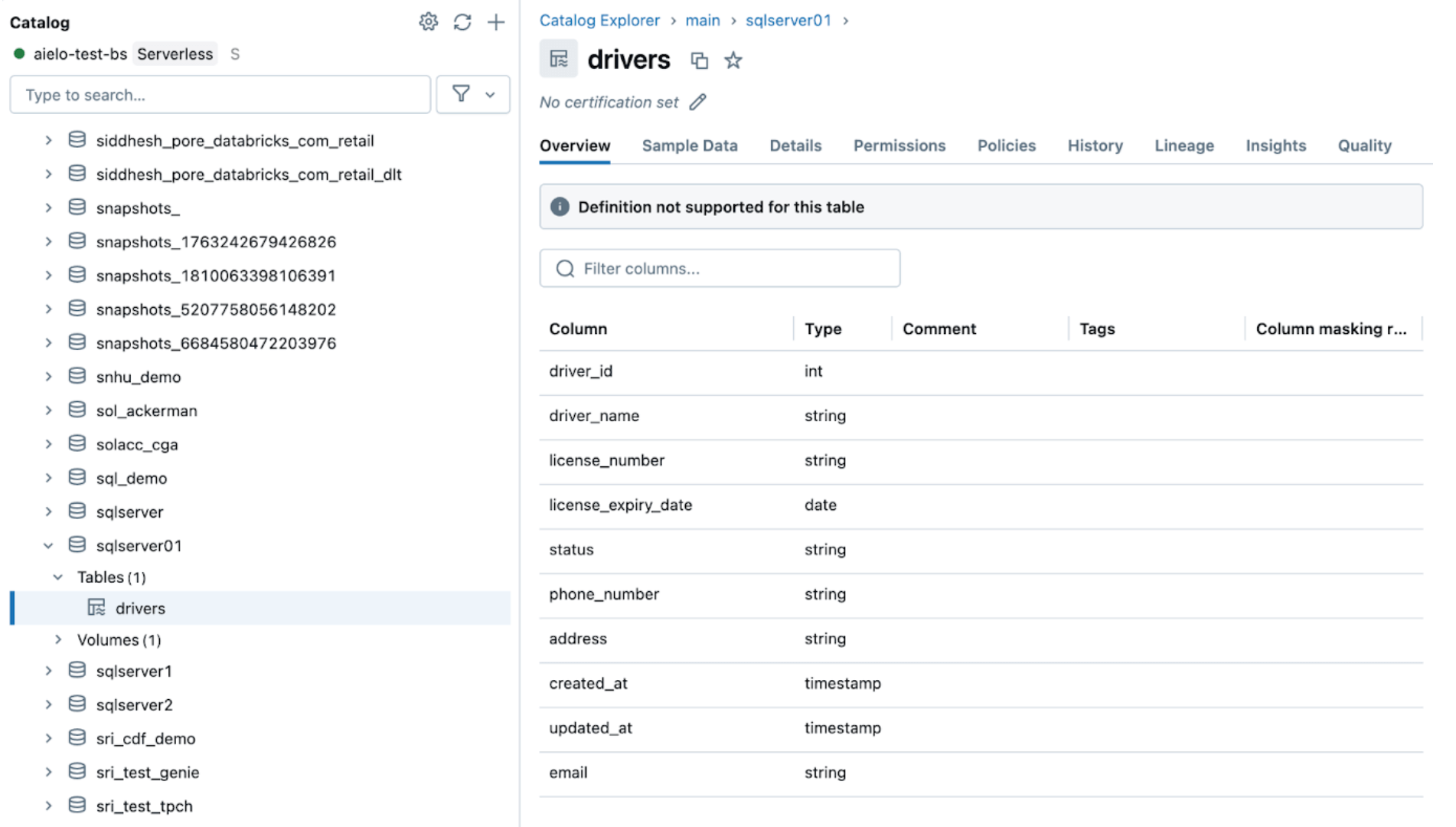
Después de cambiar los orígenes, activa la canalización de ingesta haciendo clic en el botón de inicio dentro de la UI de DLT de Databricks. Una vez que la canalización se haya completado, verifica los cambios navegando por la tabla de destino, como se muestra a continuación. La nueva columna email se agregará al final de la tabla de drivers.
5. [Databricks] Monitoreo continuo de canalizaciones
Una vez que los pipelines de ingesta y de puerta de enlace se ejecutan correctamente, es crucial supervisar su estado y comportamiento. La interfaz de usuario del pipeline proporciona comprobaciones de calidad de datos, progreso del pipeline e información sobre el linaje de datos. Para ver las entradas del registro de eventos en la interfaz de usuario del pipeline, localice el panel inferior debajo del DAG del pipeline, como se muestra a continuación.

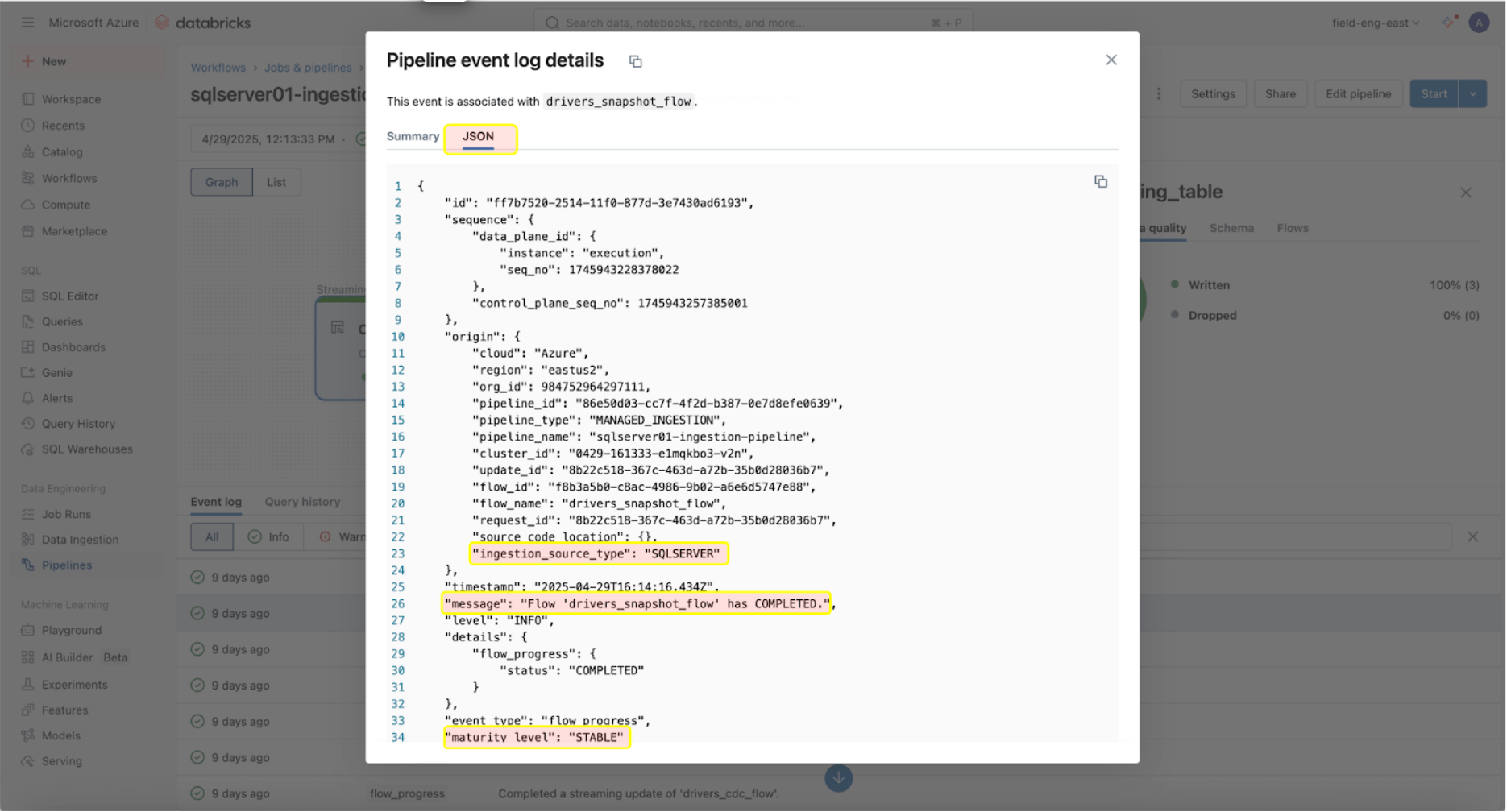
La entrada del registro de eventos anterior muestra que el flujo ‘drives_snapshot_flow’ se ingirió desde SQL Server y se completó. El nivel de madurez STABLE indica que el esquema es estable y no ha cambiado. Puede encontrar más información sobre el esquema del registro de eventos aquí.
Ejemplo del mundo real
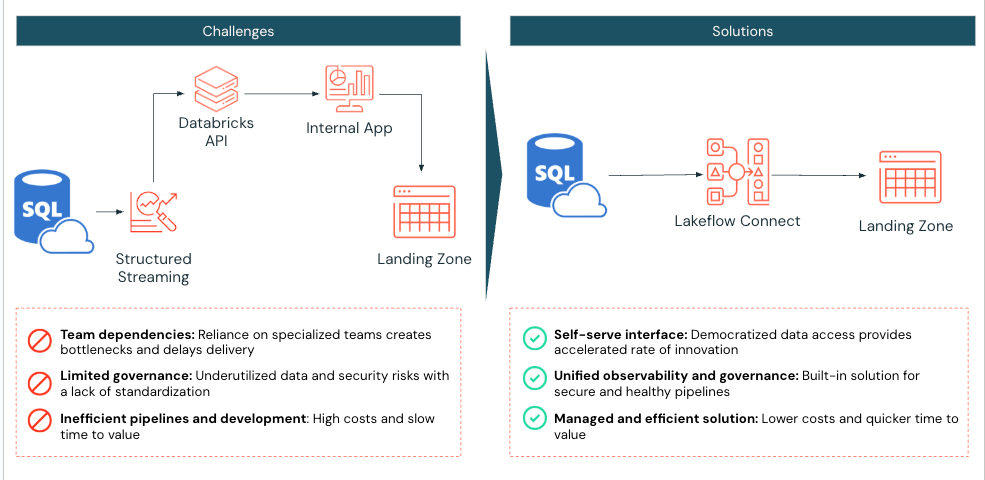
Un laboratorio de diagnóstico médico a gran escala que utilizaba Databricks se enfrentó a desafíos para ingerir eficientemente datos de SQL Server en su lakehouse. Antes de implementar Lakeflow Connect, el laboratorio utilizaba notebooks de Databricks Spark para extraer dos tablas de Azure SQL Server a Databricks. Su aplicación interactuaba luego con la API de Databricks para gestionar la ejecución de cómputo y trabajos.
El laboratorio de diagnóstico médico implementó Lakeflow Connect para SQL Server, reconociendo que este proceso podía simplificarse. Una vez habilitada, la implementación se completó en solo un día, lo que permitió al laboratorio de diagnóstico médico aprovechar las herramientas integradas de Databricks para la observabilidad con actualizaciones incrementales diarias de ingesta.
Consideraciones operativas
Una vez que el conector de SQL Server haya establecido correctamente una conexión con su Azure SQL Database, el siguiente paso es programar eficientemente sus pipelines de datos para optimizar el rendimiento y la utilización de recursos. Además, es esencial seguir las mejores prácticas para la configuración programática de pipelines para garantizar la escalabilidad y la coherencia entre entornos.
Orquestación de Pipelines
No hay límite en la frecuencia con la que se puede programar la ejecución del pipeline de ingesta. Sin embargo, para minimizar costos y garantizar la coherencia en las ejecuciones de pipelines sin superposiciones, Databricks recomienda un intervalo de al menos 5 minutos entre las ejecuciones de ingesta. Esto permite que se introduzcan nuevos datos en el origen, teniendo en cuenta los recursos computacionales y el tiempo de inicio.
El pipeline de ingesta se puede configurar como una tarea dentro de un trabajo. Cuando las cargas de trabajo posteriores dependen de la llegada de datos frescos, se pueden establecer dependencias de tareas para garantizar que la ejecución del pipeline de ingesta se complete antes de ejecutar las tareas posteriores.
Además, si el pipeline todavía se está ejecutando cuando se programa la próxima actualización, el pipeline de ingesta se comportará de manera similar a un trabajo y omitirá la actualización hasta la próxima programada, asumiendo que la actualización en curso se completa a tiempo.
Observabilidad y seguimiento de costos
Lakeflow Connect opera con un modelo de precios basado en cómputo, lo que garantiza la eficiencia y la escalabilidad para diversas necesidades de integración de datos. El pipeline de ingesta opera con cómputo sin servidor, lo que permite flexibilidad en la escalabilidad según la demanda y simplifica la gestión al eliminar la necesidad de que los usuarios configuren y administren la infraestructura subyacente.
Sin embargo, es importante tener en cuenta que, si bien el pipeline de ingesta puede ejecutarse en cómputo sin servidor, la puerta de enlace de ingesta para conectores de bases de datos opera actualmente con cómputo clásico para simplificar las conexiones a la fuente de la base de datos. Como resultado, los usuarios pueden ver una combinación de cargos DLT DBU clásicos y sin servidor reflejados en su facturación.
La forma más fácil de rastrear y monitorear el uso de Lakeflow Connect es a través de tablas del sistema. A continuación, se muestra un ejemplo de consulta para ver el uso de un pipeline específico de Lakeflow Connect:

La documentación oficial de precios de Lakeflow Connect (AWS | Azure | GCP) proporciona información detallada sobre las tarifas. Pueden aplicarse costos adicionales, como las tarifas de salida sin servidor (precios). Los costos de salida del proveedor de la nube para cómputo clásico se pueden encontrar aquí (AWS | Azure | GCP).
Mejores prácticas y puntos clave
A partir de mayo de 2025, a continuación se presentan algunas de las mejores prácticas y consideraciones a seguir al implementar este conector de SQL Server:
- Configure cada Ingestion Gateway para autenticarse con un usuario o entidad que tenga acceso únicamente a la base de datos de origen replicada.
- Asegúrese de que al usuario se le otorguen los permisos necesarios para crear conexiones en UC e ingerir los datos.
- Utilice DABs para configurar de manera confiable los pipelines de ingesta de Lakeflow Connect, asegurando la repetibilidad y la coherencia en la gestión de la infraestructura.
- Para tablas de origen con claves primarias, habilite el Seguimiento de Cambios para lograr una menor sobrecarga y un mejor rendimiento.
- Para tablas de origen sin clave primaria, habilite CDC debido a su capacidad para capturar cambios a nivel de columna, incluso sin identificadores de fila únicos.
Lakeflow Connect para SQL Server proporciona una integración totalmente administrada y nativa tanto para bases de datos locales como en la nube para una ingesta incremental eficiente en Databricks.
Próximos pasos y recursos adicionales
Pruebe el conector de SQL Server hoy mismo para ayudar a resolver sus desafíos de ingesta de datos. Siga los pasos descritos en este blog o revise la documentación. Obtenga más información sobre Lakeflow Connect en la página del producto, vea un recorrido por el producto o vea una demostración del conector de Salesforce para ayudar a predecir la rotación de clientes.
Los Arquitectos de Soluciones de Entrega (DSA) de Databricks aceleran las iniciativas de Datos e IA en las organizaciones. Proporcionan liderazgo arquitectónico, optimizan las plataformas en cuanto a costos y rendimiento, mejoran la experiencia del desarrollador e impulsan la ejecución exitosa de proyectos. Los DSA cierran la brecha entre la implementación inicial y las soluciones de nivel de producción, trabajando en estrecha colaboración con varios equipos, incluyendo ingeniería de datos, líderes técnicos, ejecutivos y otras partes interesadas para garantizar soluciones personalizadas y un valor más rápido. Para beneficiarse de un plan de ejecución personalizado, orientación estratégica y soporte durante su viaje de datos e IA de un DSA, póngase en contacto con su equipo de cuentas de Databricks.
Apéndice
En este paso opcional, para administrar las canalizaciones de Lakeflow Connect como código usando DABs, simplemente necesita agregar dos archivos a su paquete existente:
- Un archivo de flujo de trabajo que controla la frecuencia de ingesta de datos (resources/sqlserver.yml).
- Un archivo de definición de canalización (resources/sqlserver_pipeline.yml).
resources/sqlserver.yml:
resources/sqlserver_job.yml:
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.