Ingeniería de rendimiento para inferencia de LLM: Mejores prácticas
por Megha Agarwal, Asfandyar Qureshi, Nikhil Sardana, Linden Li, Julian Quevedo y Daya Khudia
En esta publicación de blog, el equipo de ingeniería de MosaicML comparte las mejores prácticas sobre cómo aprovechar los modelos de lenguaje grandes (LLM) de código abierto populares para uso en producción. También proporcionamos pautas para implementar servicios de inferencia creados en torno a estos modelos para ayudar a los usuarios en la selección de modelos y el hardware de implementación. Hemos trabajado con varios backends basados en PyTorch en producción; estas pautas se basan en nuestra experiencia con FasterTransformers, vLLM, el próximo lanzamiento de NVIDIA TensorRT-LLM y otros.
Comprendiendo la Generación de Texto de LLM
Los Modelos de Lenguaje Grandes (LLM) generan texto en un proceso de dos pasos: "prefill", donde los tokens de la indicación de entrada se procesan en paralelo, y "decodificación", donde el texto se genera un 'token' a la vez de manera autorregresiva. Cada token generado se adjunta a la entrada y se retroalimenta al modelo para generar el siguiente token. La generación se detiene cuando el LLM genera un token de parada especial o cuando se cumple una condición definida por el usuario (por ejemplo, se ha generado un número máximo de tokens). Si desea más información sobre cómo los LLM utilizan los bloques decodificadores, consulte esta publicación de blog.
Los tokens pueden ser palabras o sub-palabras; las reglas exactas para dividir el texto en tokens varían de un modelo a otro. Por ejemplo, puede comparar cómo los modelos Llama tokenizan texto con cómo los modelos de OpenAI tokenizan texto. Aunque los proveedores de inferencia de LLM a menudo hablan de rendimiento en métricas basadas en tokens (por ejemplo, tokens/segundo), estos números no siempre son comparables entre tipos de modelos dadas estas variaciones. Como ejemplo concreto, el equipo de Anyscale descubrió que la tokenización de Llama 2 es un 19% más larga que la tokenización de ChatGPT (pero aún tiene un costo general mucho menor). Y los investigadores de HuggingFace también descubrieron que Llama 2 requirió ~20% más de tokens para entrenar sobre la misma cantidad de texto que GPT-4.
Métricas Importantes para el Servicio de LLM
Entonces, ¿cómo debemos pensar exactamente en la velocidad de inferencia?
Nuestro equipo utiliza cuatro métricas clave para el servicio de LLM:
- Tiempo Hasta el Primer Token (TTFT): Qué tan r�ápido los usuarios comienzan a ver la salida del modelo después de ingresar su consulta. Los tiempos de espera bajos para una respuesta son esenciales en interacciones en tiempo real, pero menos importantes en cargas de trabajo fuera de línea. Esta métrica está impulsada por el tiempo requerido para procesar la indicación y luego generar el primer token de salida.
- Tiempo por Token de Salida (TPOT): Tiempo para generar un token de salida para *cada* usuario que consulta nuestro sistema. Esta métrica corresponde a cómo cada usuario percibirá la "velocidad" del modelo. Por ejemplo, un TPOT de 100 milisegundos/token serían 10 tokens por segundo por usuario, o ~450 palabras por minuto, lo cual es más rápido de lo que una persona típica puede leer.
- Latencia: El tiempo total que tarda el modelo en generar la respuesta completa para un usuario. La latencia de respuesta general se puede calcular utilizando las dos métricas anteriores: latencia = (TTFT) + (TPOT) * (el número de tokens a generar).
- Rendimiento (Throughput): El número de tokens de salida por segundo que un servidor de inferencia puede generar para todos los usuarios y solicitudes.
¿Nuestro objetivo? El tiempo más rápido hasta el primer token, el mayor rendimiento y el tiempo más rápido por token de salida. En otras palabras, queremos que nuestros modelos generen texto lo más rápido posible para tantos usuarios como podamos soportar.
Notablemente, existe una compensación entre el rendimiento y el tiempo por token de salida: si procesamos 16 consultas de usuario concurrentemente, tendremos un rendimiento *mayor* en comparación con la ejecución secuencial de las consultas, pero tardaremos *más* en generar tokens de salida para cada usuario.
Si tiene objetivos generales de latencia de inferencia, aquí hay algunas heurísticas útiles para evaluar modelos:
- La longitud de la salida domina la latencia general de la respuesta: Para la latencia promedio, generalmente puede tomar su longitud esperada/máxima de tokens de salida y multiplicarla por un tiempo promedio general por token de salida para el modelo.
- La longitud de entrada no es significativa para el rendimiento, pero es importante para los requisitos de hardware: La adición de 512 tokens de *entrada* aumenta la latencia menos que la producción de 8 tokens de *salida* adicionales en los modelos MPT. Sin embargo, la necesidad de admitir entradas largas puede dificultar el servicio de los modelos. Por ejemplo, recomendamos usar el A100-80GB (o más reciente) para servir MPT-7B con su longitud de contexto máxima de 2048 tokens.
- La latencia general escala de forma sublineal con el tamaño del modelo: En el mismo hardware, los modelos más grandes son más lentos, pero la relación de velocidad no coincidirá necesariamente con la relación del recuento de parámetros. La latencia de MPT-30B es ~2.5 veces la latencia de MPT-7B. La latencia de Llama2-70B es ~2 veces la latencia de Llama2-13B.
A menudo, los clientes potenciales nos preguntan si podemos proporcionar una latencia de inferencia promedio. Recomendamos que, antes de fijarse en objetivos de latencia específicos ("necesitamos menos de 20 ms por token"), dedique tiempo a caracterizar sus longitudes de entrada esperadas y deseadas.
Desafíos en la Inferencia de LLM
La optimización de la inferencia de LLM se beneficia de técnicas generales como:
- Fusión de Operadores (Operator Fusion): Combinar diferentes operadores adyacentes a menudo resulta en una mejor latencia.
- Cuantización (Quantization): Las activaciones y los pesos se comprimen para usar un menor número de bits.
- Compresión (Compression): Sparsity o Distillation.
- Paralelización (Parallelization): Paralelismo tensorial entre múltiples dispositivos o paralelismo de pipeline para modelos más grandes.
Más allá de estos métodos, existen muchas optimizaciones importantes específicas de Transformer. Un ejemplo principal de esto es el almacenamiento en caché KV (clave-valor). El mecanismo de Atención (Attention) en modelos basados en Transformer solo decodificadores es computacionalmente ineficiente. Cada token atiende a todos los tokens vistos previamente, y por lo tanto, se vuelven a calcular muchos de los mismos valores a medida que se genera cada nuevo token. Por ejemplo, al generar el enésimo token, el (n-1)ésimo token atiende a los (n-2)ésimos, (n-3)ésimos... primeros tokens. De manera similar, al generar el (n+1)ésimo token, la atención para el enésimo token nuevamente necesita mirar los (n-1)ésimos, (n-2)ésimos, (n-3)ésimos... primeros tokens. El almacenamiento en caché KV, es decir, el guardado de claves/valores intermedios para las capas de atención, se utiliza para preservar esos resultados para su reutilización posterior, evitando cálculos repetidos.
El Ancho de Banda de Memoria es Clave
Los cálculos en LLM están dominados principalmente por operaciones de multiplicación de matrices, estas operaciones con dimensiones pequeñas suelen estar limitadas por el ancho de banda de la memoria en la mayoría del hardware. Al generar tokens de manera autorregresiva, una de las dimensiones de la matriz de activación (definida por el tamaño del lote y el número de tokens en la secuencia) es pequeña en tamaños de lote pequeños. Por lo tanto, la velocidad depende de la rapidez con la que podamos cargar los parámetros del modelo desde la memoria de la GPU a las cachés/registros locales, en lugar de la rapidez con la que podamos calcular sobre los datos cargados. El ancho de banda de memoria disponible y alcanzado en el hardware de inferencia es un mejor predictor de la velocidad de generación de tokens que su rendimiento de cómputo pico.
La utilización del hardware de inferencia es muy importante en términos de costos de servicio. Las GPU son caras y necesitamos que hagan el mayor trabajo posible. Los servicios de inferencia compartidos prometen mantener bajos los costos al combinar cargas de trabajo de muchos usuarios, llenando las brechas individuales y agrupando solicitudes superpuestas. Para modelos grandes como Llama2-70B, solo logramos un buen costo/rendimiento con tamaños de lote grandes. Tener un sistema de servicio de inferencia que pueda operar con tamaños de lote grandes es fundamental para la eficiencia de costos. Sin embargo, un lote grande significa un tamaño de caché KV mayor, y eso a su vez aumenta el número de GPU requeridas para servir el modelo. Hay un tira y afloja aquí y los operadores de servicios compartidos deben tomar algunas decisiones de costos e implementar optimizaciones del sistema.
Utilización del Ancho de Banda del Modelo (MBU)
¿Qué tan optimizado está un servidor de inferencia de LLM?
Como se explicó brevemente antes, la inferencia para LLM en tamaños de lote más pequeños, especialmente en el momento de la decodificación, se ve limitada por la rapidez con la que podemos cargar los parámetros del modelo desde la memoria del dispositivo a las unidades de cómputo. El ancho de banda de la memoria dicta la rapidez con la que se mueven los datos. Para medir la utilización del hardware subyacente, introducimos una nueva métrica llamada Utilización del Ancho de Banda del Modelo (MBU). MBU se define como (ancho de banda de memoria alcanzado) / (ancho de banda de memoria pico), donde el ancho de banda de memoria alcanzado es ((tamaño total de parámetros del modelo + tamaño de caché KV) / TPOT).
Por ejemplo, si un modelo de 7B parámetros ejecutándose con precisión de 16 bits tiene un TPOT de 14 ms, entonces está moviendo 14 GB de parámetros en 14 ms, lo que se traduce en un uso de ancho de banda de 1 TB/segundo. Si el ancho de banda pico de la máquina es de 2 TB/segundo, estamos operando con un MBU del 50%. Para simplificar, este ejemplo ignora el tamaño de la caché KV, que es pequeño para tamaños de lote más pequeños y longitudes de secuencia más cortas. Los valores de MBU cercanos al 100% implican que el sistema de inferencia está utilizando eficazmente el ancho de banda de memoria disponible. El MBU también es útil para comparar diferentes sistemas de inferencia (hardware + software) de manera normalizada. El MBU es complementario a la métrica de Utilización de Flops del Modelo (MFU; introducida en el paper de PaLM), que es importante en entornos limitados por cómputo.
La Figura 1 muestra una representación pictórica del MBU en un gráfico similar a un gráfico de línea de techo (roofline plot). La línea inclinada sólida de la región sombreada de naranja muestra el rendimiento máximo posible si el ancho de banda de la memoria está completamente saturado al 100%. Sin embargo, en la realidad, para tamaños de lote pequeños (punto blanco), el rendimiento observado es menor que el máximo; cuánto menor es una medida del MBU. Para tamaños de lote grandes (región amarilla), el sistema está limitado por cómputo, y el rendimiento alcanzado como fracción del rendimiento pico posible se mide como la Utilización de Flops del Modelo (MFU).
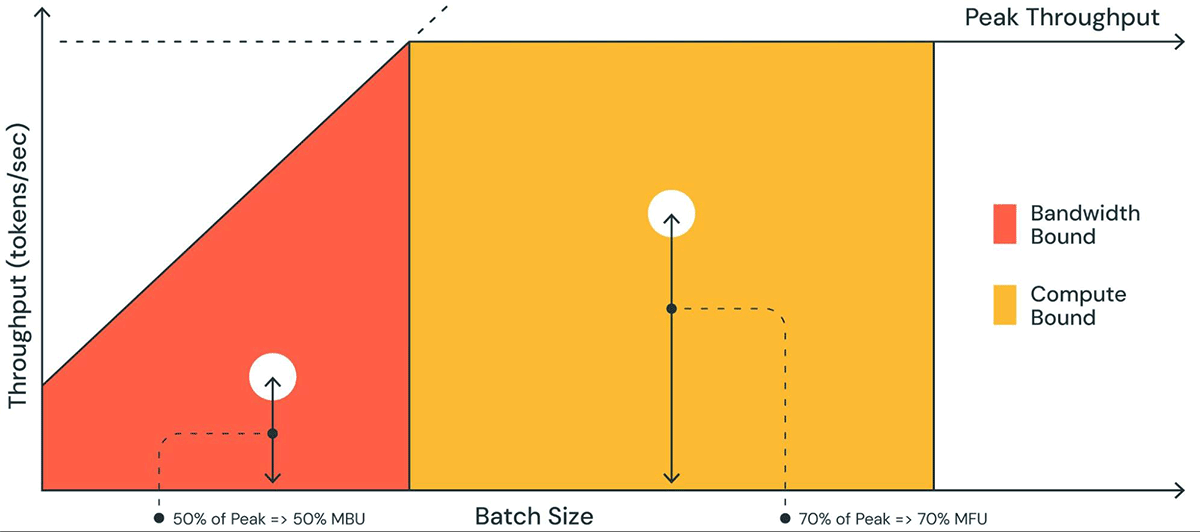
El MBU y el MFU determinan cuánto espacio adicional hay disponible para aumentar la velocidad de inferencia en una configuración de hardware dada. La Figura 2 muestra el MBU medido para diferentes grados de paralelismo tensorial con nuestro servidor de inferencia basado en TensorRT-LLM. La utilización pico del ancho de banda de la memoria se alcanza al transferir fragmentos de memoria grandes y contiguos. Cuando modelos más pequeños como MPT-7B se distribuyen en múltiples GPUs, observamos un MBU menor ya que movemos fragmentos de memoria más pequeños en cada GPU.
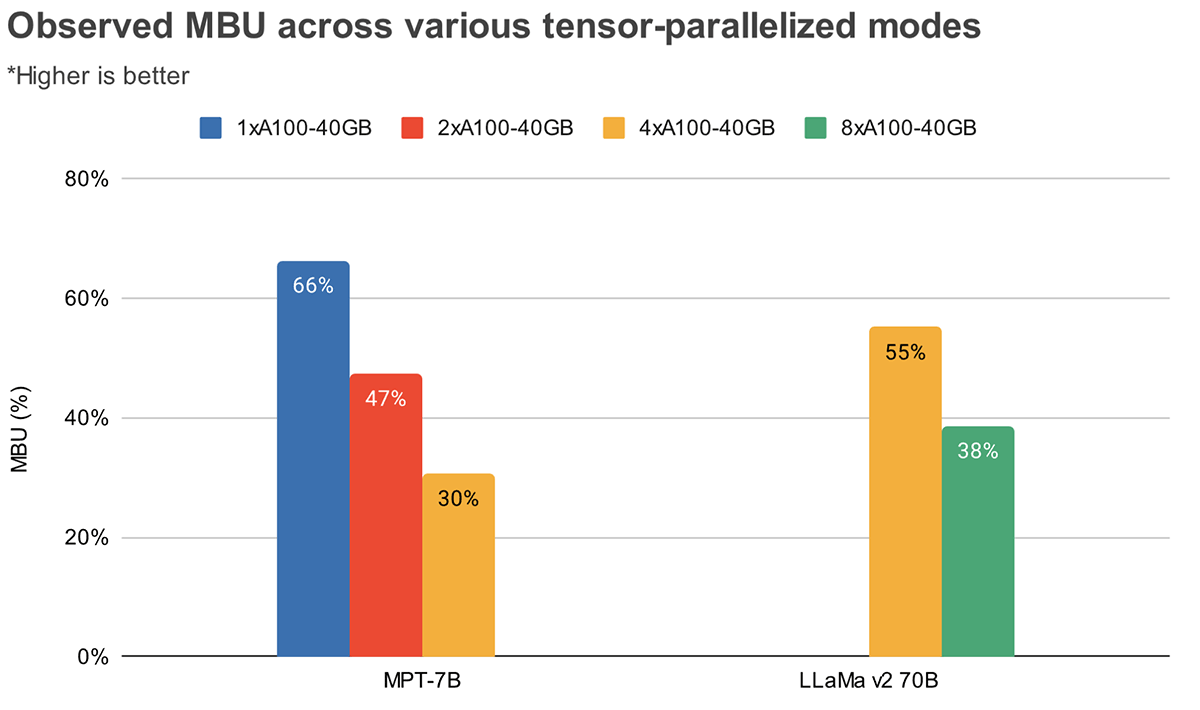
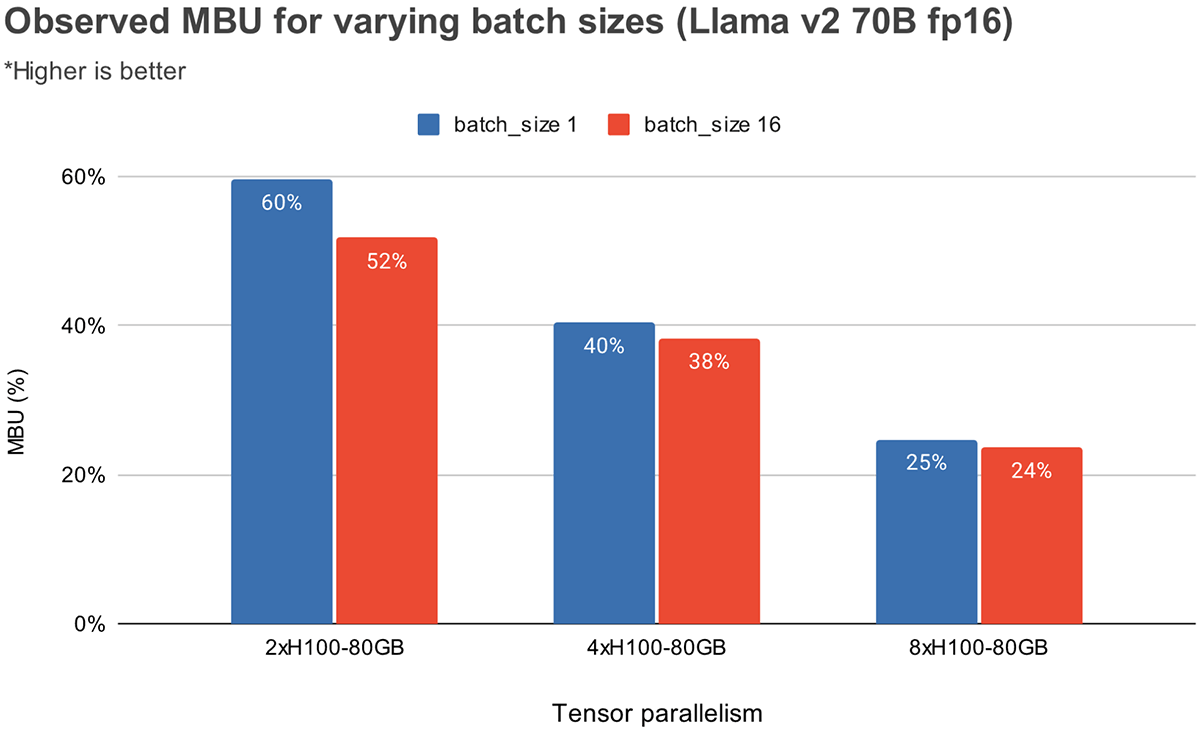
La Figura 3 muestra el MBU observado empíricamente para diferentes grados de paralelismo tensorial y tamaños de lote en las GPUs NVIDIA H100. El MBU disminuye a medida que aumenta el tamaño del lote. Sin embargo, al escalar las GPUs, la disminución relativa del MBU es menos significativa. También vale la pena señalar que elegir hardware con mayor ancho de banda de memoria puede mejorar el rendimiento con menos GPUs. Con un tamaño de lote de 1, podemos lograr un MBU más alto del 60% en 2xH100-80GB en comparación con el 55% en 4xA100-40GB GPUs (Figura 2).
Resultados de Benchmarking
Latencia
Hemos medido el tiempo hasta el primer token (TTFT) y el tiempo por token de salida (TPOT) en diferentes grados de paralelismo tensorial para los modelos MPT-7B y Llama2-70B. A medida que las indicaciones de entrada se alargan, el tiempo para generar el primer token comienza a consumir una porción sustancial de la latencia total. El paralelismo tensorial a través de múltiples GPUs ayuda a reducir esta latencia.
A diferencia del entrenamiento de modelos, escalar a más GPUs ofrece rendimientos decrecientes significativos para la latencia de inferencia. Por ejemplo, para Llama2-70B, pasar de 4x a 8x GPUs solo reduce la latencia en 0.7x con tamaños de lote pequeños. Una razón para esto es que un mayor paralelismo tiene un MBU más bajo (como se discutió anteriormente). Otra razón es que el paralelismo tensorial introduce sobrecarga de comunicación a través de un nodo de GPU.
| Tiempo hasta el primer token (ms) | ||||
|---|---|---|---|---|
| Modelo | 1xA100-40GB | 2xA100-40GB | 4xA100-40GB | 8xA100-40GB |
| MPT-7B | 46 (1x) | 34 (0.73x) | 26 (0.56x) | - |
| Llama2-70B | No cabe | 154 (1x) | 114 (0.74x) | |
Tabla 1: Tiempo hasta el primer token dadas las solicitudes de entrada de 512 tokens de longitud con un tamaño de lote de 1. Modelos más grandes como Llama2 70B necesitan al menos 4 GPUs A100-40B para caber en memoria.
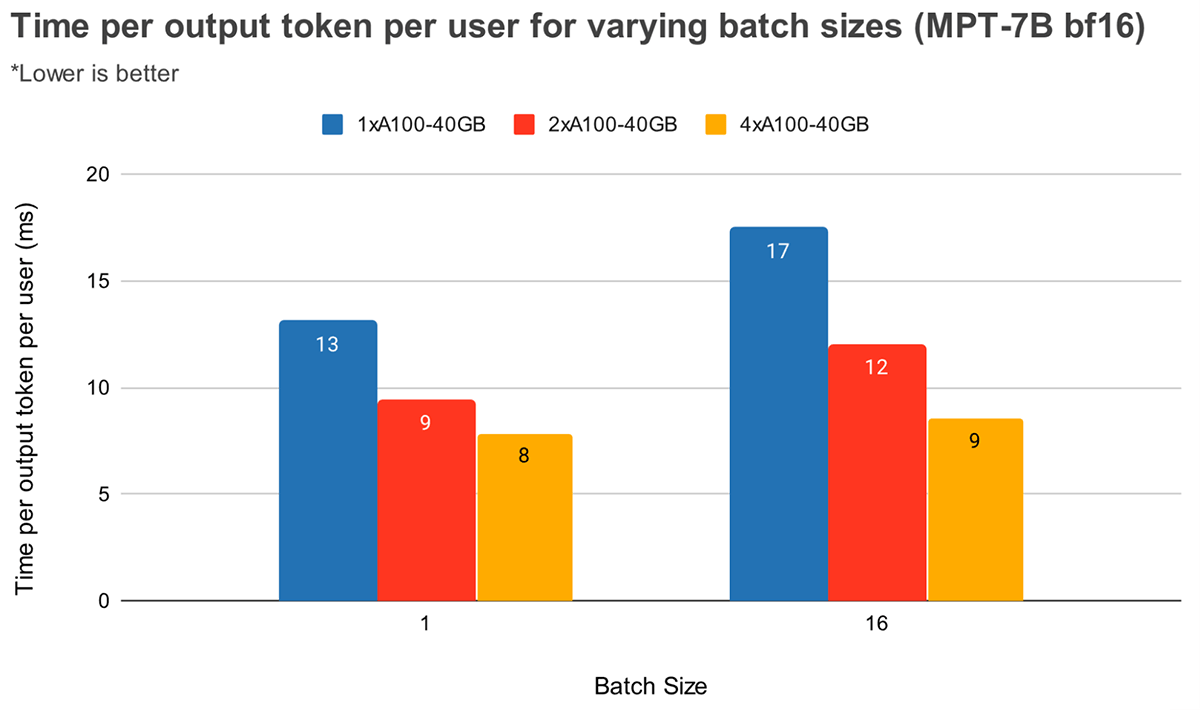
Con tamaños de lote más grandes, un mayor paralelismo tensorial conduce a una disminución relativa más significativa en la latencia por token. La Figura 4 muestra cómo varía el tiempo por token de salida para MPT-7B. Con un tamaño de lote de 1, pasar de 2x a 4x solo reduce la latencia del token en ~12%. Con un tamaño de lote de 16, la latencia con 4x es un 33% menor que con 2x. Esto concuerda con nuestra observación anterior de que la disminución relativa en el MBU es menor con grados más altos de paralelismo tensorial para el tamaño de lote 16 en comparación con el tamaño de lote 1.
La Figura 5 muestra resultados similares para Llama2-70B, excepto que la mejora relativa entre 4x y 8x es menos pronunciada. También comparamos el escalado de GPUs en dos hardware diferentes. Debido a que H100-80GB tiene 2.15 veces más ancho de banda de memoria por GPU en comparación con A100-40GB, podemos ver que la latencia es un 36% menor con un tamaño de lote de 1 y un 52% menor con un tamaño de lote de 16 para sistemas 4x.
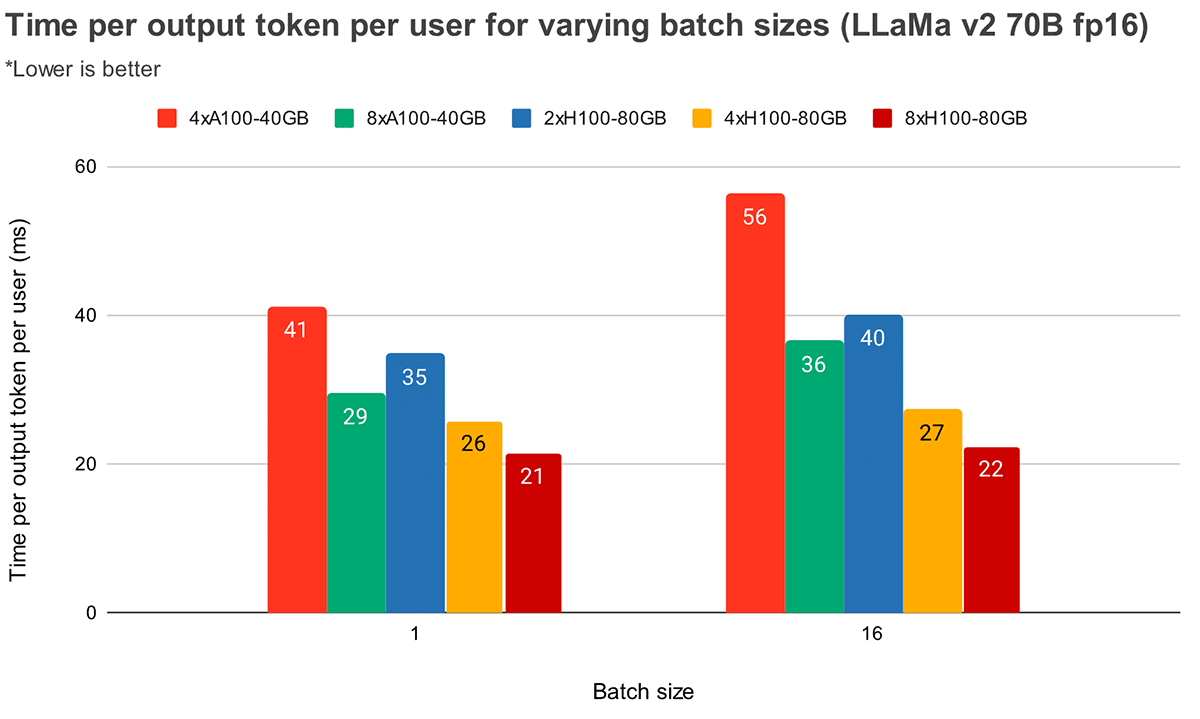
Rendimiento (Throughput)
Podemos intercambiar rendimiento y tiempo por token agrupando solicitudes. Agrupar consultas durante la evaluación de la GPU aumenta el rendimiento en comparación con procesar consultas secuencialmente, pero cada consulta tardará más en completarse (ignorando los efectos de la cola).
Existen algunas técnicas comunes para agrupar solicitudes de inferencia:
- Agrupación estática (Static batching): El cliente empaqueta múltiples prompts en solicitudes y se devuelve una respuesta después de que todas las secuencias en el lote se hayan completado. Nuestros servidores de inferencia admiten esto pero no lo requieren.
- Agrupación dinámica (Dynamic batching): Los prompts se agrupan sobre la marcha dentro del servidor. Típicamente, este método funciona peor que la agrupación estática, pero puede acercarse al óptimo si las respuestas son cortas o de longitud uniforme. No funciona bien cuando las solicitudes tienen parámetros diferentes.
- Agrupación continua (Continuous batching): La idea de agrupar solicitudes a medida que llegan se introdujo en este excelente paper y es actualmente el método SOTA (estado del arte). En lugar de esperar a que todas las secuencias de un lote terminen, agrupa secuencias a nivel de iteración. Puede lograr un rendimiento 10x-20x mejor que la agrupación dinámica.
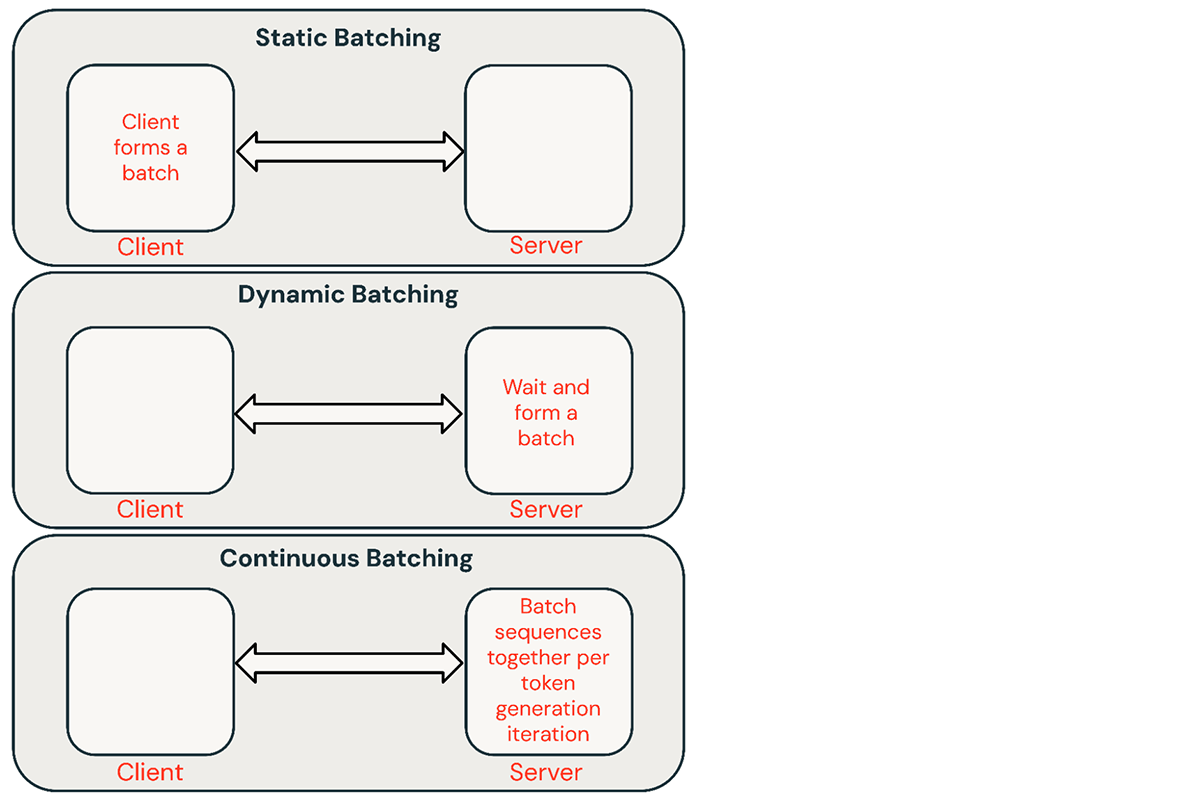
La agrupación continua suele ser el mejor enfoque para servicios compartidos, pero hay situaciones en las que los otros dos pueden ser mejores. En entornos de QPS (consultas por segundo) bajos, la agrupación dinámica puede superar a la agrupación continua. A veces es más fácil implementar optimizaciones de GPU de bajo nivel en un marco de agrupación más simple. Para cargas de trabajo de inferencia por lotes (offline), la agrupación estática puede evitar sobrecargas significativas y lograr un mejor rendimiento.
Tamaño del Lote
La efectividad del procesamiento por lotes depende en gran medida del flujo de solicitudes. Pero podemos obtener un límite superior de su rendimiento evaluando el rendimiento del procesamiento por lotes estático con solicitudes uniformes.
| Tamaño del lote | |||||||
|---|---|---|---|---|---|---|---|
| Hardware | 1 | 4 | 8 | 16 | 32 | 64 | 128 |
| 1 x A10 | 0.4 (1x) | 1.4 (3.5x) | 2.3 (6x) | 3.5 (9x) | Error OOM (Fuera de Memoria) | ||
| 2 x A10 | 0.8 | 2.5 | 4.0 | 7.0 | 8.0 | ||
| 1 x A100 | 0.9 (1x) | 3.2 (3.5x) | 5.3 (6x) | 8.0 (9x) | 10.5 (12x) | 12.5 (14x) | |
| 2 x A100 | 1.3 | 3.0 | 5.5 | 9.5 | 14.5 | 17.0 | 22.0 |
| 4 x A100 | 1.7 | 6.2 | 11.5 | 18.0 | 25.0 | 33.0 | 36.5 |
Tabla 2: Rendimiento pico de MPT-7B (req/seg) con procesamiento por lotes estático y un backend basado en FasterTransformers. Solicitudes: 512 tokens de entrada y 64 de salida. Para entradas más grandes, el límite OOM se encontrará en tamaños de lote más pequeños.
Compensación de latencia
La latencia de las solicitudes aumenta con el tamaño del lote. Con una sola GPU NVIDIA A100, por ejemplo, si maximizamos el rendimiento con un tamaño de lote de 64, la latencia aumenta 4 veces mientras que el rendimiento aumenta 14 veces. Los servicios de inferencia compartidos suelen elegir un tamaño de lote equilibrado. Los usuarios que alojan sus propios modelos deben decidir la compensación adecuada entre latencia y rendimiento para sus aplicaciones. En algunas aplicaciones, como los chatbots, la baja latencia para respuestas rápidas es la máxima prioridad. En otras aplicaciones, como el procesamiento por lotes de PDFs no estructurados, podríamos querer sacrificar la latencia para procesar un documento individual y procesar todos rápidamente en paralelo.
La Figura 7 muestra la curva de rendimiento frente a latencia para el modelo de 7B. Cada línea en esta curva se obtiene aumentando el tamaño del lote de 1 a 256. Esto es útil para determinar cuán grande podemos hacer el tamaño del lote, sujeto a diferentes restricciones de latencia. Recordando nuestro gráfico de tejado anterior, encontramos que estas mediciones son consistentes con lo que esperaríamos. Después de un cierto tamaño de lote, es decir, cuando cruzamos al régimen limitado por cómputo, cada duplicación del tamaño del lote solo aumenta la latencia sin aumentar el rendimiento.
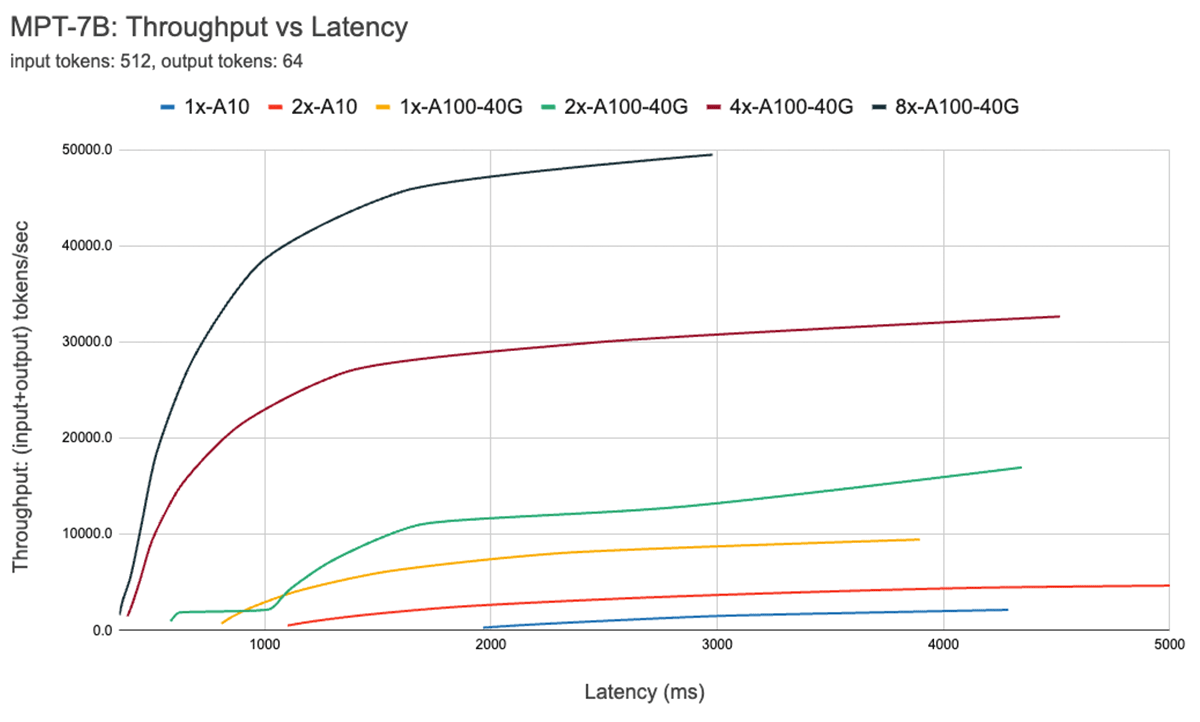
Al usar paralelismo, es importante comprender los detalles de hardware de bajo nivel. Por ejemplo, no todas las instancias 8xA100 son iguales en diferentes nubes. Algunos servidores tienen conexiones de alto ancho de banda entre todas las GPUs, otros emparejan GPUs y tienen conexiones de menor ancho de banda entre pares. Esto podría introducir cuellos de botella, haciendo que el rendimiento del mundo real se desvíe significativamente de las curvas anteriores.
Estudio de caso de optimización: Cuantización
La cuantización es una técnica común utilizada para reducir los requisitos de hardware para la inferencia de LLM. Reducir la precisión de los pesos y activaciones del modelo durante la inferencia puede reducir drásticamente los requisitos de hardware. Por ejemplo, cambiar de pesos de 16 bits a pesos de 8 bits puede reducir a la mitad el número de GPUs requeridas en entornos con memoria limitada (por ejemplo, Llama2-70B en A100s). Reducir a pesos de 4 bits hace posible ejecutar la inferencia en hardware de consumo (por ejemplo, Llama2-70B en Macbooks).
En nuestra experiencia, la cuantización debe implementarse con precaución. Las técnicas de cuantización ingenuas pueden provocar una degradación sustancial de la calidad del modelo. El impacto de la cuantización también varía según las arquitecturas (por ejemplo, MPT vs Llama) y los tamaños de los modelos. Exploraremos esto con más detalle en una futura publicación de blog.
Al experimentar con técnicas como la cuantización, recomendamos utilizar un benchmark de calidad de LLM como Mosaic Eval Gauntlet para evaluar la calidad del sistema de inferencia, no solo la calidad del modelo de forma aislada. Además, es importante explorar optimizaciones de sistemas más profundas. En particular, la cuantización puede hacer que las cachés KV sean mucho más eficientes.
Como se mencionó anteriormente, en la generación de tokens autorregresiva, las Claves/Valores (KV) pasados de las capas de atención se almacenan en caché en lugar de recalcularse en cada paso. El tamaño de la caché KV varía según el número de secuencias procesadas a la vez y la longitud de estas secuencias. Además, durante cada iteración de la generación del siguiente token, se agregan nuevos elementos KV a la caché existente, lo que la hace más grande a medida que se generan nuevos tokens. Por lo tanto, la gestión eficaz de la memoria de la caché KV al agregar estos nuevos valores es fundamental para un buen rendimiento de inferencia. Los modelos Llama2 utilizan una variante de atención llamada Grouped Query Attention (GQA). Tenga en cuenta que cuando el número de cabezales KV es 1, GQA es lo mismo que Multi-Query-Attention (MQA). GQA ayuda a reducir el tamaño de la caché KV compartiendo Claves/Valores. La fórmula para calcular el tamaño de la caché KV es
tamaño_lote * longitud_secuencia * (d_modelo/n_cabezales) * n_capas * 2 (K y V) * 2 (bytes por Float16) * n_cabezales_kv
La Tabla 3 muestra el tamaño de la caché KV de GQA calculado en diferentes tamaños de lote con una longitud de secuencia de 1024 tokens. El tamaño de los parámetros para los modelos Llama, en comparación, es de 140 GB (Float16) para el modelo de 70B. La cuantización de la caché KV es otra técnica (además de GQA/MQA) para reducir el tamaño de la caché KV, y estamos evaluando activamente su impacto en la calidad de la generación.
| Tamaño del lote | Memoria de caché KV GQA (FP16) | Memoria de caché KV GQA (Int8) |
|---|---|---|
| 1 | 0.312 GiB | 0.156 GiB |
| 16 | 5 GiB | 2.5 GiB |
| 32 | 10 GiB | 5 GiB |
| 64 | 20 GiB | 10 GiB |
Tabla 3: Tamaño de la caché KV para Llama-2-70B a una longitud de secuencia de 1024
Como se mencionó anteriormente, la generación de tokens con LLMs en tamaños de lote pequeños es un problema limitado por el ancho de banda de la memoria de la GPU, es decir, la velocidad de generación depende de la rapidez con la que los parámetros del modelo se puedan mover de la memoria de la GPU a las cachés en el chip. Convertir los pesos del modelo de FP16 (2 bytes) a INT8 (1 byte) o INT4 (0.5 byte) requiere mover menos datos y, por lo tanto, acelera la generación de tokens. Sin embargo, la cuantización puede afectar negativamente la calidad de la generación del modelo. Actualmente estamos evaluando el impacto en la calidad del modelo utilizando Model Gauntlet y planeamos publicar una publicación de blog de seguimiento al respecto pronto.
Conclusiones y resultados clave
Cada uno de los factores que hemos descrito anteriormente influye en la forma en que construimos e implementamos modelos. Utilizamos estos resultados para tomar decisiones basadas en datos que tengan en cuenta el tipo de hardware, la pila de software, la arquitectura del modelo y los patrones de uso típicos. Aquí hay algunas recomendaciones extraídas de nuestra experiencia.
Identifique su objetivo de optimización: ¿Le importa el rendimiento interactivo? ¿Maximizar el rendimiento? ¿Minimizar el costo? Existen compensaciones predecibles aquí.
Preste atención a los componentes de la latencia: Para aplicaciones interactivas, el tiempo hasta el primer token (time-to-first-token) determina qué tan receptivo se sentirá su servicio y el tiempo por token de salida (time-per-output-token) determina qué tan rápido se sentirá.
El ancho de banda de la memoria es clave: La generación del primer token suele estar limitada por el cómputo, mientras que la decodificación posterior es una operación limitada por la memoria. Dado que la inferencia de LLM a menudo opera en entornos limitados por la memoria, MBU (Memory Bandwidth Utilization) es una métrica útil para optimizar y se puede utilizar para comparar la eficiencia de los sistemas de inferencia.
El procesamiento por lotes es fundamental: Procesar múltiples solicitudes de forma concurrente es fundamental para lograr un alto rendimiento y para utilizar eficazmente las costosas GPUs. Para los servicios en línea compartidos, el procesamiento continuo por lotes es indispensable, mientras que las cargas de trabajo de inferencia por lotes sin conexión pueden lograr un alto rendimiento con técnicas de procesamiento por lotes más sencillas.
Optimizaciones en profundidad: Las técnicas estándar de optimización de inferencia son importantes (por ejemplo, fusión de operadores, cuantificación de pesos) para los LLM, pero es importante explorar optimizaciones de sistemas más profundas, especialmente aquellas que mejoran la utilización de la memoria. Un ejemplo es la cuantificación de la caché KV.
Configuraciones de hardware: El tipo de modelo y la carga de trabajo esperada deben utilizarse para decidir el hardware de implementación. Por ejemplo, al escalar a múltiples GPUs, la MBU (Utilización de Bloques de Modelo) cae mucho más rápidamente para modelos más pequeños, como MPT-7B, que para modelos más grandes, como Llama2-70B. El rendimiento también tiende a escalar de forma sublineal con mayores grados de paralelismo tensorial. Dicho esto, un alto grado de paralelismo tensorial aún puede tener sentido para modelos más pequeños si el tráfico es alto o si los usuarios están dispuestos a pagar una prima por una latencia extra baja.
Decisiones basadas en datos: Comprender la teoría es importante, pero recomendamos medir siempre el rendimiento del servidor de extremo a extremo. Hay muchas razones por las que una implementación de inferencia puede tener un rendimiento inferior al esperado. La MBU podría ser inesperadamente baja debido a ineficiencias del software. O las diferencias de hardware entre los proveedores de nube podrían generar sorpresas (hemos observado una diferencia de latencia de 2x entre servidores 8xA100 de dos proveedores de nube).
Para empezar con la inferencia de LLM, prueba Databricks Model Serving. Consulta la documentación para obtener más información.
Ver todas las entradas anteriores del blog de MosaicML
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.