Integración de Datos Multimodales: Arquitecturas de Producción para IA en Salud
La mayoría de los esfuerzos de IA multimodal en atención médica se detienen antes de la producción. Aquí tienes un plano práctico para unificar genómica, imágenes, notas clínicas y wearables con gobernanza, pipelines y estrategias de fusión que...
por Maks Khomutskyi
- Construye una base multimodal gobernada: Integra flujos de genómica, características de imágenes, entidades de notas clínicas y wearables en Delta con controles de acceso de Unity Catalog, auditoría, linaje y etiquetas gobernadas.
- Elige una fusión que resista la realidad de producción: Usa fusión temprana/intermedia/tardía/basada en atención según la disponibilidad de la modalidad, dimensionalidad y tiempo — diseñada para modalidades faltantes, no cohortes perfectas.
- Operacionaliza de extremo a extremo: Usa Lakeflow SDP para streaming + ventanas de características, búsqueda vectorial para similitud/cohortes y pipelines reproducibles (versionado/viaje en el tiempo + CI/CD + MLflow) para pasar de POC a producción.
Los casos de uso de IA más valiosos en el sector de la salud rara vez residen en un solo conjunto de datos. La integración de datos multimodales —combinar genómica, imágenes, notas clínicas y dispositivos portátiles— es esencial para la oncología de precisión y la detección temprana, sin embargo, muchas iniciativas se estancan antes de llegar a producción.
La oncología de precisión requiere comprender tanto los impulsores moleculares de la genómica como el contexto anatómico de las imágenes. La detección temprana mejora cuando las señales de riesgo hereditario se encuentran con los datos longitudinales de los dispositivos portátiles. Y muchos de los detalles del “por qué” —síntomas, respuesta, justificación— todavía residen en las notas clínicas.
A pesar del progreso real en la investigación, muchas iniciativas multimodales se estancan antes de llegar a producción, no porque el modelado sea imposible, sino porque los datos y el modelo operativo no están listos para la realidad clínica. La limitación no es la sofisticación del modelo, sino la arquitectura: pilas separadas por modalidad crean canalizaciones frágiles, gobernanza duplicada y movimiento de datos costoso que falla ante las necesidades de implementación clínica.
Esta publicación describe un patrón de lakehouse orientado a la producción para medicina de precisión multimodal: cómo cargar cada modalidad en tablas Delta gobernadas, crear características intermodales y elegir estrategias de fusión que sobrevivan a la falta de datos en el mundo real.
Arquitectura de referencia
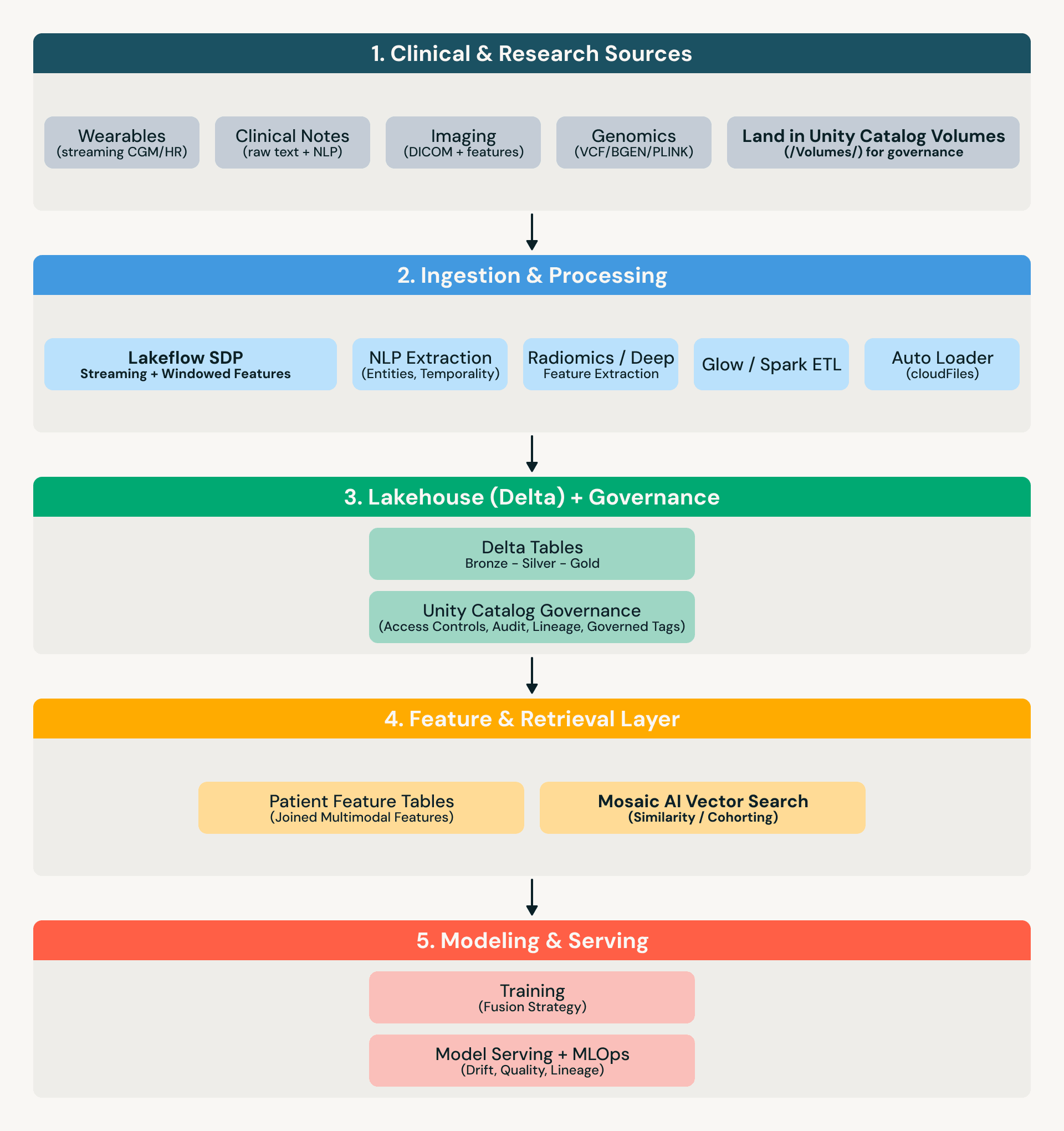
Lo que significa “gobernado” en la práctica
A lo largo de esta publicación, “tablas gobernadas” significa que los datos están asegurados y operativizados utilizando Unity Catalog (o controles equivalentes), incluyendo:
Clasificación de datos con etiquetas gobernadas: PHI/PII/28 CFR Part 202/StudyID/…
- Controles de acceso detallados: permisos de catálogo/esquema/tabla/volumen, más controles a nivel de fila/columna donde sea necesario para PHI.
- Auditoría: quién accedió a qué, cuándo (crítico para entornos regulados).
- Linaje: rastrear características y entradas de modelos hasta los conjuntos de datos de origen.
- Compartición controlada: límites de políticas consistentes entre equipos y herramientas.
Reproducibilidad: versionado y viaje en el tiempo para conjuntos de datos, CI/CD para canalizaciones/trabajos, y MLflow para el seguimiento de experimentos y versiones de modelos.
Esto conecta la arquitectura técnica con los resultados comerciales: menos copias de datos sensibles, análisis reproducibles y aprobaciones más rápidas para la puesta en producción.
Por qué lo multimodal se está convirtiendo en el estándar
Los modelos unimodales alcanzan límites reales en entornos clínicos complejos. Las imágenes pueden ser potentes, pero muchas predicciones complejas se benefician del contexto molecular + longitudinal. La genómica captura los impulsores, pero no el fenotipo, el entorno o la fisiología diaria. Las notas y los dispositivos portátiles añaden las señales “entre líneas” que los datos estructurados a menudo pierden.
La realidad del volumen importa: Databricks señala que aproximadamente el 80% de los datos médicos no están estructurados (por ejemplo, texto e imágenes). Es por eso que la integración de datos multimodales debe manejar notas e imágenes no estructuradas a escala, no solo campos estructurados de EHR.
La conclusión práctica: cada modalidad está incompleta por sí sola. Los sistemas multimodales funcionan cuando están diseñados para:
- Preservar la señal específica de la modalidad.
- Mantenerse robustos cuando faltan algunas entradas.
Cuatro estrategias de fusión (y cuándo cada una sobrevive a la producción)
La elección de la fusión rara vez es la única razón por la que los equipos fallan, pero a menudo explica por qué los pilotos no se traducen: los datos son escasos, las modalidades llegan en diferentes momentos y los requisitos de gobernanza difieren según el tipo de datos.
1) Fusión temprana (Concatenar entradas crudas antes del entrenamiento.)
- Usar cuando: cohortes pequeñas y estrictamente controladas con disponibilidad de modalidad consistente.
- Compromiso: escala mal con genómica de alta dimensionalidad y conjuntos de características grandes.
2) Fusión intermedia (Codificar cada modalidad por separado, luego fusionar representaciones ocultas.)
- Usar cuando: combinar ómicas de alta dimensionalidad con características de EHR/clínicas de menor dimensionalidad.
- Compromiso: requiere un aprendizaje de representación cuidadoso por modalidad y una evaluación disciplinada.
3) Fusión tardía (Entrenar modelos por modalidad, luego combinar predicciones.)
- Usar cuando: implementaciones en producción donde faltan modalidades con frecuencia.
- Beneficio: se degrada con gracia cuando una o más modalidades están ausentes.
4) Fusión basada en atención (Aprender ponderación dinámica entre modalidades y tiempo.)
- Usar cuando: el tiempo importa (dispositivos portátiles + notas longitudinales, imágenes repetidas) y las interacciones son complejas.
- Compromiso: más difícil de validar; requiere controles cuidadosos para evitar correlaciones espurias.
Marco de decisión: emparejar la fusión con su realidad de implementación: patrones de disponibilidad de modalidad, equilibrio de dimensionalidad y dinámicas temporales.
El lakehouse como sustrato multimodal
Un enfoque de lakehouse reduce el movimiento de datos entre modalidades: la genómica, los metadatos/características de imágenes, las entidades derivadas de texto y los dispositivos portátiles en streaming pueden ser gobernados y consultados en un solo lugar, sin reconstruir canalizaciones para cada equipo.
Procesamiento de genómica (Glow + Delta)
Glow permite el procesamiento distribuido de genómica en Spark sobre formatos comunes (por ejemplo, VCF/BGEN/PLINK), con los resultados derivados almacenados como tablas Delta que se pueden unir a características clínicas.
Similitud de imágenes (características derivadas + Búsqueda Vectorial)
Para imágenes, el patrón es: (1) derivar características/incrustaciones aguas arriba (radiómica o salidas de modelos profundos), (2) almacenar características como tablas Delta gobernadas (aseguradas a través de Unity Catalog), y (3) usar búsqueda vectorial para consultas de similitud (por ejemplo, “encontrar fenotipos similares dentro de glioblastoma”).
Esto permite el descubrimiento de cohortes y comparaciones retrospectivas sin exportar datos a sistemas separados.
Notas clínicas (NLP a características gobernadas)
Las notas a menudo contienen contexto faltante: cronologías, síntomas, respuesta, justificación. Un enfoque práctico es extraer entidades + temporalidad en tablas (cambios de medicación, síntomas, procedimientos, historial familiar, cronologías), mantener el texto crudo bajo gobernanza estricta (Unity Catalog + controles de acceso), y unir las características derivadas de notas a imágenes y ómicas para modelado y cohortes.
Datos de dispositivos portátiles (Lakeflow SDP para streaming + ventanas de características)
Los flujos de dispositivos portátiles introducen requisitos operativos: evolución del esquema, eventos que llegan tarde y agregación continua. Lakeflow Spark Declarative Pipelines (SDP) proporciona un patrón robusto de ingesta a características para tablas de streaming y vistas materializadas. Para facilitar la lectura, nos referimos a él como Lakeflow SDP a continuación.
Nota de sintaxis: El módulo pyspark.pipelines (importado como dp) con decoradores @dp.table y @dp.materialized_view sigue la semántica actual de Python de Databricks Lakeflow SDP.
Por qué importa el modelo unificado de almacenamiento + gobernanza
La ventaja operativa es la coherencia:
Un modo de falla común en las implementaciones en la nube es un enfoque de “almacén especializado por modalidad” (por ejemplo: un almacén FHIR, un almacén de ómicas separado, un almacén de imágenes separado y un almacén de características o vectores separado). En la práctica, eso a menudo significa gobernanza duplicada y canalizaciones inter-almacenes frágiles, lo que hace que el linaje, la reproducibilidad y las uniones multimodales sean mucho más difíciles de operacionalizar.
- Reproducibilidad: ACID + viaje en el tiempo para conjuntos de entrenamiento consistentes y reanálisis.
- Auditabilidad: registros de acceso + linaje (qué datos produjeron qué característica/modelo).
- Seguridad: límites de políticas consistentes entre modalidades (PHI seguro por diseño).
- Velocidad: menos traspasos y menos copias de datos entre equipos.
Esto es lo que convierte un prototipo multimodal en algo que puedes ejecutar, monitorear y defender en producción.
Resolviendo el problema de la modalidad faltante
Los despliegues reales se enfrentan a datos incompletos. No todos los pacientes reciben un perfil genómico completo. Los estudios de imagen pueden no estar disponibles. Los wearables solo existen para las poblaciones inscritas. La falta de datos no es un caso extremo, es la norma.
Los diseños de producción deben asumir la escasez y planificarla:
- Enmascaramiento de modalidad durante el entrenamiento: eliminar entradas durante el desarrollo para simular la realidad del despliegue.
- Atención dispersa / modelos conscientes de la modalidad: aprender a usar lo que está disponible sin depender excesivamente de una sola modalidad.
- Estrategias de aprendizaje por transferencia: entrenar en cohortes más ricas y adaptarse a poblaciones clínicas dispersas con validación cuidadosa.
Idea clave: las arquitecturas que asumen datos completos tienden a fallar en producción. Las arquitecturas diseñadas para la escasez generalizan.
Patrón de oncología de precisión: de la arquitectura al flujo de trabajo clínico
Un patrón práctico de oncología de precisión se ve así:
- Perfil genómico -> tablas moleculares gobernadas (Unity Catalog). Almacenar variantes, biomarcadores y anotaciones como tablas consultables con linaje y acceso controlado.
- Características derivadas de imágenes -> similitud + cohortes. Indexar vectores de características de imágenes para "encontrar casos similares" y correlaciones fenotipo-genotipo.
- Cronologías derivadas de notas -> elegibilidad + contexto. Extraer entidades conscientes del tiempo para apoyar la selección de ensayos y la comprensión longitudinal consistente.
- Capa de soporte de junta de tumores (humano en el bucle). Combinar evidencia multimodal en una vista de revisión consistente con procedencia. El objetivo no es automatizar decisiones, sino reducir el tiempo de ciclo y mejorar la consistencia en la recopilación de evidencia.
Impacto empresarial: qué cambia cuando lo multimodal se vuelve operativo
El crecimiento del mercado es una razón por la que esto importa, pero el impulsor inmediato es operativo:
- Ensamblaje y reanálisis más rápidos de cohortes cuando llegan nuevas modalidades.
- Menos copias de datos y menos pipelines únicos.
- Ciclos de iteración más cortos (semanas frente a meses) para flujos de trabajo traslacionales.
El análisis de similitud de pacientes también puede permitir un razonamiento práctico "N=1" al identificar coincidencias históricas con perfiles multimodales similares, especialmente valioso en enfermedades raras y poblaciones de oncología heterogéneas.
Primeros pasos: unos pragmáticos primeros 30 días
- Selecciona una decisión clínica (por ejemplo, emparejamiento de ensayos, estratificación de riesgos) y define las métricas de éxito.
- Inventaría las modalidades + la falta de datos (¿quién tiene genómica? ¿imágenes? ¿wearables longitudinales?).
- Configura tablas gobernadas de bronce/plata/oro protegidas a través de Unity Catalog.
- Elige una línea base de fusión que tolere la falta de datos (la fusión tardía suele ser un comienzo seguro).
- Operacionaliza: linaje, comprobaciones de calidad de datos, monitoreo de deriva, conjuntos de entrenamiento reproducibles.
- Planifica la validación: cohortes de evaluación, comprobaciones de sesgos, puntos de control del flujo de trabajo clínico.
Palabras clave: IA multimodal, medicina de precisión, procesamiento genómico, IA de imágenes médicas, integración de datos de atención médica, estrategias de fusión, arquitectura lakehouse
Alta prioridad
Unity Catalog: https://www.databricks.com/product/unity-catalog
Salud y Ciencias de la Vida: https://www.databricks.com/solutions/industries/healthcare-and-life-sciences
Plataforma de Inteligencia de Datos para Salud y Ciencias de la Vida: https://www.databricks.com/resources/guide/data-intelligence-platform-for-healthcare-and-life-sciences
Prioridad media
Documentación de Databricks AI Search: https://docs.databricks.com/en/generative-ai/vector-search.html
Delta Lake en Databricks: https://www.databricks.com/product/delta-lake-on-databricks
Data Lakehouse (glosario): https://www.databricks.com/glossary/data-lakehouse
Blogs relacionados adicionales
Une los datos de tu paciente con RAG multimodal: https://www.databricks.com/blog/unite-your-patients-data-multi-modal-rag
Transformación de la gestión de datos ómicos en la Plataforma de Inteligencia de Datos de Databricks: https://www.databricks.com/blog/transforming-omics-data-management-databricks-data-intelligence-platform
Presentamos Glow (Genómica): https://www.databricks.com/blog/2019/10/18/introducing-glow-an-open-source-toolkit-for-large-scale-genomic-analysis.html
Procesamiento de imágenes DICOM a escala con databricks.pixels: https://www.databricks.com/blog/2023/03/16/building-lakehouse-healthcare-and-life-sciences-processing-dicom-images.html
Aceleradores de Soluciones para Salud y Ciencias de la Vida: https://www.databricks.com/solutions/accelerators
¿Listo para llevar la IA multimodal en salud de pilotos a producción? Explora los recursos de Databricks para arquitecturas HLS, gobernanza con Unity Catalog y patrones de implementación de extremo a extremo.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.