Navegando la migración de Oracle a Databricks: Consejos para una transición fluida
Estrategias, Herramientas y Mejores Prácticas para la Transición a la Arquitectura Lakehouse
por Laurent Léturgez
- Comprende cómo la arquitectura Lakehouse se compara con el modelo tradicional de almacén de datos relacionales de Oracle.
- Descubre cómo inventariar objetos de base de datos y traducir esquemas específicos de Oracle a formatos compatibles con Databricks.
- Ejecuta pasos posteriores a la migración para validar la integridad de los datos, ejecutar sistemas paralelos para pruebas de negocio y optimizar el rendimiento.
A medida que más organizaciones adoptan arquitecturas lakehouse, migrar de almacenes de datos heredados como Oracle a plataformas modernas como Databricks se ha convertido en una prioridad común. Los beneficios —mejor escalabilidad, rendimiento y eficiencia de costos— son claros, pero el camino para llegar allí no siempre es sencillo.
En esta publicación, compartiré estrategias prácticas para navegar la migración de Oracle a Databricks, incluyendo consejos para evitar errores comunes y preparar su proyecto para el éxito a largo plazo.
Comprender las diferencias clave
Antes de discutir las estrategias de migración, es importante comprender las diferencias fundamentales entre Oracle y Databricks, no solo en tecnología sino también en diferencias arquitectónicas.
El modelo relacional de Oracle frente a la arquitectura lakehouse de Databricks
Los almacenes de datos de Oracle siguen un modelo relacional tradicional optimizado para cargas de trabajo transaccionales y estructuradas. Databricks es una solución perfecta para alojar cargas de trabajo de almacenes de datos, independientemente del modelo de datos utilizado, similar a otros sistemas de gestión de bases de datos como Oracle. En contraste, Databricks se basa en una arquitectura lakehouse, que fusiona la flexibilidad de los data lakes con el rendimiento y la fiabilidad de los data warehouses.
Este cambio modifica cómo se almacenan, procesan y acceden los datos, pero también desbloquea posibilidades completamente nuevas. Con Databricks, las organizaciones pueden:
- Soportar casos de uso modernos como machine learning (ML), IA tradicional e IA generativa
- Aprovechar la separación de almacenamiento y cómputo, permitiendo que múltiples equipos inicien almacenes independientes mientras acceden a los mismos datos subyacentes
- Romper silos de datos y reducir la necesidad de pipelines ETL redundantes
Dialectos SQL y diferencias de procesamiento
Ambas plataformas soportan SQL, pero existen diferencias en la sintaxis, funciones integradas y cómo se optimizan las consultas. Estas variaciones deben abordarse durante la migración para garantizar la compatibilidad y el rendimiento.
Procesamiento de datos y escalado
Oracle utiliza una arquitectura basada en filas y escalada verticalmente (con escalado horizontal limitado a través de Real Application Clusters). Databricks, por otro lado, utiliza el modelo distribuido de Apache Spark™, que soporta escalado horizontal y vertical en grandes conjuntos de datos.
Databricks también funciona de forma nativa con Delta Lake y Apache Iceberg, formatos de almacenamiento columnar optimizados para análisis a gran escala y de alto rendimiento. Estos formatos soportan características como transacciones ACID, evolución de esquemas y viaje en el tiempo, que son críticas para construir pipelines resilientes y escalables.
Pasos previos a la migración (comunes a todas las migraciones de data warehouse)
Independientemente de su sistema de origen, una migración exitosa comienza con algunos pasos críticos:
- Inventaríe su entorno: Comience catalogando todos los objetos de la base de datos, dependencias, patrones de uso y flujos de trabajo de ETL o integración de datos. Esto proporciona la base para comprender el alcance y la complejidad.
- Analice los patrones de flujo de trabajo: Identifique cómo fluyen los datos a través de su sistema actual. Esto incluye cargas de trabajo por lotes frente a streaming, dependencias de carga de trabajo y cualquier lógica específica de la plataforma que pueda requerir rediseño.
- Priorice y fase su migración: Evite un enfoque de “big bang”. En su lugar, divida su migración en fases manejables basadas en el riesgo, el impacto comercial y la preparación. Colabore con los equipos de Databricks y socios de integración certificados para crear un plan realista y de bajo riesgo que se alinee con sus objetivos y plazos.
Estrategias de migración de datos
Una migración de datos exitosa requiere un enfoque reflexivo que aborde tanto las diferencias técnicas entre las plataformas como las características únicas de sus activos de datos. Las siguientes estrategias le ayudarán a planificar y ejecutar un proceso de migración eficiente mientras maximiza los beneficios de la arquitectura de Databricks.
Traducción y optimización de esquemas
Evite copiar esquemas de Oracle directamente sin repensar su diseño para Databricks. Por ejemplo, el tipo de datos NUMBER de Oracle soporta una mayor precisión que la que permite Databricks (precisión y escala máximas de 38). En tales casos, puede ser más apropiado usar tipos DOUBLE en lugar de intentar mantener coincidencias exactas.
Traducir esquemas de forma reflexiva garantiza la compatibilidad y evita problemas de rendimiento o precisión de datos a largo plazo.
Para más detalles, consulte la Guía de Migración de Oracle a Databricks.
Enfoques de extracción y carga de datos
Las migraciones de Oracle a menudo implican mover datos de bases de datos locales a Databricks, donde el ancho de banda y el tiempo de extracción pueden convertirse en cuellos de botella. Su estrategia de extracción debe alinearse con el volumen de datos, la frecuencia de actualización y la tolerancia a las interrupciones.
Las opciones comunes incluyen:
- Conexiones JDBC – útiles para conjuntos de datos más pequeños o transferencias de bajo volumen
- Lakehouse Federation – para replicar data marts directamente a Databricks
- Azure Data Factory o AWS Database Migration Services – para movimiento de datos orquestado a escala
- Herramientas de exportación nativas de Oracle:
- DBMS_CLOUD.EXPORT_DATA (disponible en Oracle Cloud)
- Descarga de SQL Developer (para uso local o en las instalaciones)
- Configuración manual de DBMS_CLOUD en implementaciones locales de Oracle 19.9+
- Opciones de transferencia masiva – como AWS Snowball o Microsoft Data Box, para mover tablas históricas grandes a la nube
La elección de la herramienta adecuada depende del tamaño de sus datos, los límites de conectividad y las necesidades de recuperación.
Optimizar para el rendimiento
Los datos migrados a menudo necesitan ser remodelados para que funcionen bien en Databricks. Esto comienza con repensar cómo se particionan los datos.
Si su almacén de datos de Oracle utilizaba particiones estáticas o desequilibradas, esas estrategias pueden no traducirse bien. Analice sus patrones de consulta y reestructure las particiones en consecuencia. Databricks ofrece varias técnicas para mejorar el rendimiento:
- Clustering Líquido Automático para optimización continua sin ajustes manuales
- Z-Ordering para agrupar por columnas filtradas frecuentemente
- Clustering Líquido para organizar datos dinámicamente
Además:
- Comprimir archivos pequeños para reducir la sobrecarga
- Separar datos calientes y fríos para optimizar el costo y la eficiencia del almacenamiento
- Evitar el sobreparticionamiento, que puede ralentizar los escaneos y aumentar la sobrecarga de metadatos
Por ejemplo, el particionamiento basado en fechas de transacciones que resulta en una distribución desigual de los datos se puede reequilibrar utilizando el Clustering Líquido Automático, mejorando el rendimiento de las consultas basadas en tiempo.
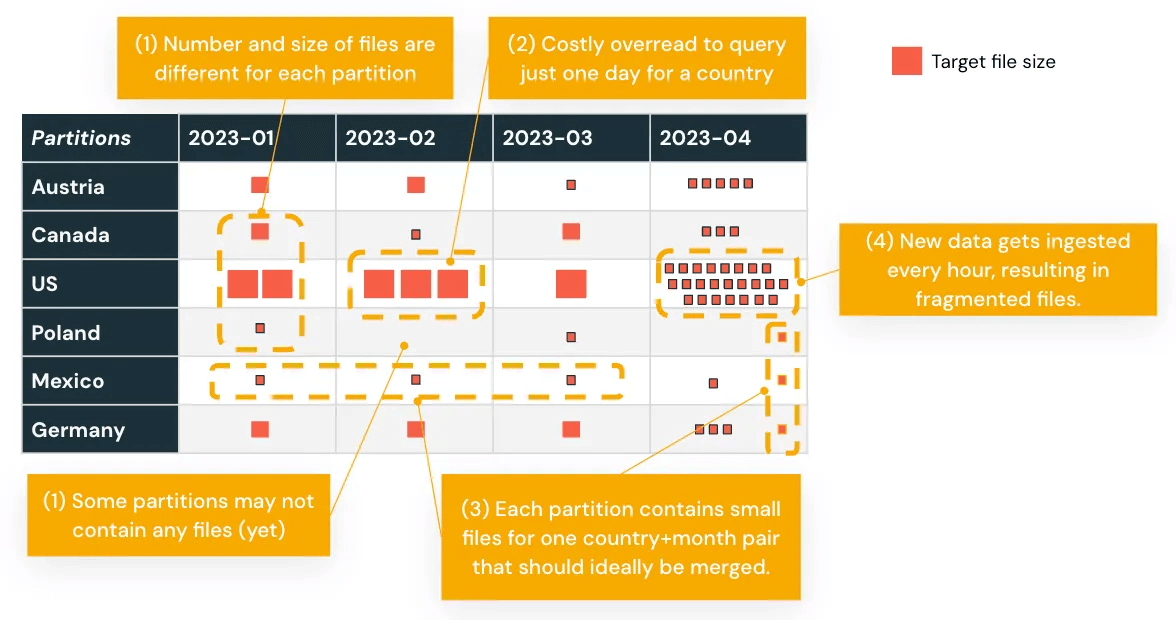
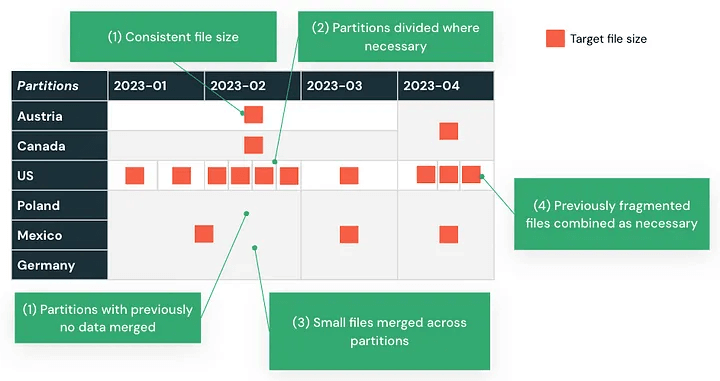
Diseñar teniendo en cuenta el modelo de procesamiento de Databricks garantiza que sus cargas de trabajo escalen de manera eficiente y se mantengan manejables después de la migración.
Migración de código y lógica
Si bien la migración de datos constituye la base de su transición, mover la lógica de su aplicación y el código SQL representa uno de los aspectos más complejos de la migración de Oracle a Databricks. Este proceso implica traducir la sintaxis y adaptarse a diferentes paradigmas de programación y técnicas de optimización que se alinean con el modelo de procesamiento distribuido de Databricks.
Estrategias de traducción de SQL
Convierta Oracle SQL a Databricks SQL utilizando un enfoque estructurado. Herramientas automatizadas como BladeBridge (ahora parte de Databricks) pueden analizar la complejidad del código y realizar traducciones masivas. Dependiendo de la base de código, las tasas de conversión típicas son alrededor del 75% o más.
Estas herramientas ayudan a reducir el esfuerzo manual e identificar áreas que requieren reelaboración o cambios arquitectónicos posteriores a la migración.
Migración de procedimientos almacenados
Evite intentar encontrar reemplazos exactos uno a uno para las construcciones de Oracle PL/SQL. Paquetes como DBMS_X, UTL_X y CTX_X no existen en Databricks y requerirán reescribir la lógica para que se ajuste a la plataforma.
Para construcciones comunes como:
- Cursores
- Manejo de excepciones
- Bucles y sentencias de flujo de control
Databricks ahora ofrece SQL Scripting, que admite SQL procedural en notebooks. Alternativamente, considere convertir estos flujos de trabajo a Python o Scala dentro de Databricks Workflows o pipelines DLT, que ofrecen mayor flexibilidad e integración con el procesamiento distribuido.
BladeBridge puede ayudar a traducir esta lógica a notebooks de Databricks SQL o PySpark como parte de la migración.
Transformación del flujo de trabajo ETL
Databricks ofrece varios enfoques para crear procesos ETL que simplifican el ETL heredado de Oracle:
- Notebooks de Databricks con parámetros – para tareas ETL simples y modulares
- DLT – para definir pipelines declarativamente con soporte para procesamiento por lotes y de streaming, procesamiento incremental y verificaciones de calidad de datos integradas
- Databricks Workflows – para la programación y orquestación dentro de la plataforma
Estas opciones brindan a los equipos flexibilidad para refactorizar y operar ETL post-migración, alineándose con los patrones modernos de ingeniería de datos.
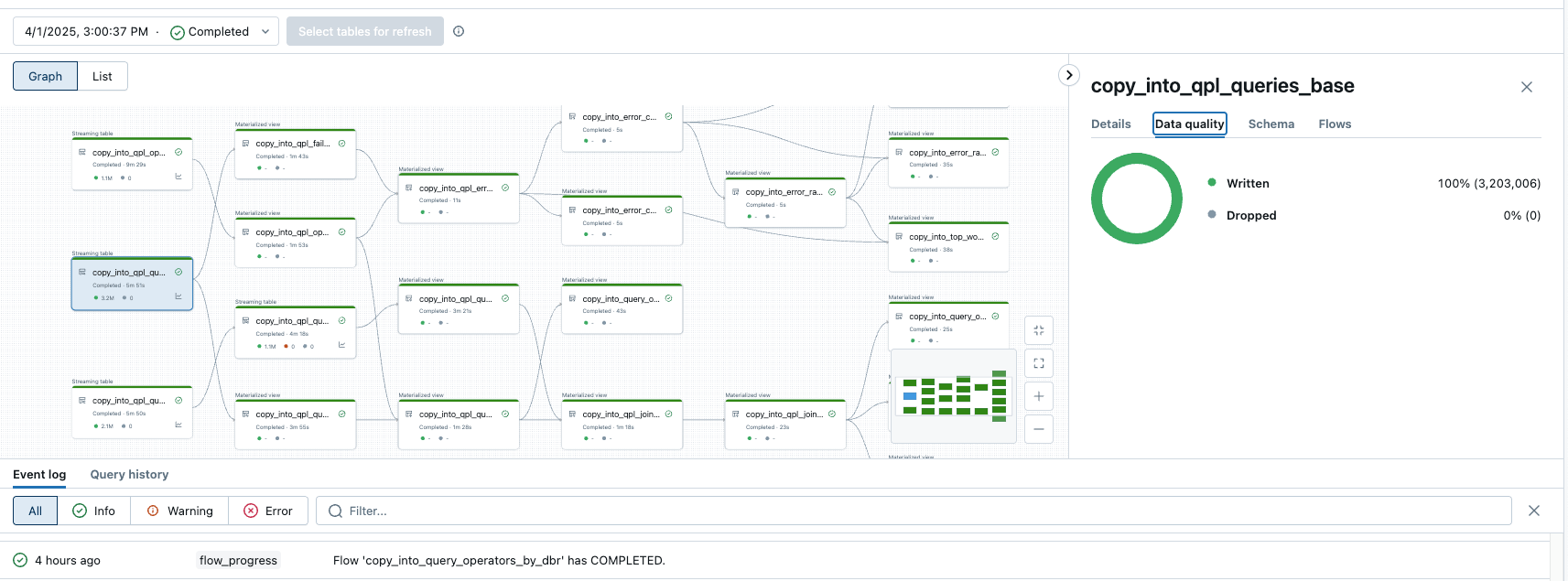
Post-migración: validación, optimización y adopción
Validar con pruebas técnicas y de negocio
Después de migrar un caso de uso, es fundamental validar que todo funcione como se espera, tanto técnica como funcionalmente.
- La validación técnica debe incluir:
- Recuento de filas y conciliación de agregados entre sistemas
- Comprobaciones de integridad y calidad de los datos
- Comparaciones de resultados de consultas entre plataformas de origen y destino
- La validación de negocio implica ejecutar ambos sistemas en paralelo y hacer que las partes interesadas confirmen que los resultados coinciden con las expectativas antes del corte.
Optimizar costos y rendimiento
Después de la validación, evalúe y ajuste el entorno basándose en las cargas de trabajo reales. Las áreas de enfoque incluyen:
- Estrategias de partición y clustering (por ejemplo, Z-Ordering, Liquid Clustering)
- Optimización del tamaño y formato de archivo
- Configuración de recursos y políticas de escalado. Estos ajustes ayudan a alinear la infraestructura con los objetivos de rendimiento y los objetivos de costos.
Transferencia de conocimiento y preparación organizacional
Una migración exitosa no termina con la implementación técnica. Asegurarse de que los equipos puedan usar la nueva plataforma de manera efectiva es igual de importante.
- Planifique la capacitación práctica y la documentación
- Permita que los equipos adopten nuevos flujos de trabajo, incluido el desarrollo colaborativo, la lógica basada en notebooks y las canalizaciones declarativas
- Asigne la propiedad para la calidad de los datos, la gobernanza y el monitoreo del rendimiento en el nuevo sistema
La migración es más que un cambio técnico
Migrar de Oracle a Databricks no es solo un cambio de plataforma, es un cambio en cómo se administran, procesan y consumen los datos.
Una planificación exhaustiva, una ejecución por fases y una estrecha coordinación entre los equipos técnicos y las partes interesadas del negocio son esenciales para reducir el riesgo y garantizar una transición fluida.
Igualmente importante es preparar a su organización para trabajar de manera diferente: adoptando nuevas herramientas, nuevos procesos y una nueva mentalidad en torno a la analítica o la IA. Con un enfoque equilibrado tanto en la implementación como en la adopción, su equipo puede desbloquear todo el valor de una arquitectura moderna de lakehouse.
Consejos prácticos de Deloitte
Deloitte compartió algunos consejos prácticos en la migración de un data warehouse heredado a Databricks en este webinar. ¡Échale un vistazo para saber cómo funcionó la migración en una empresa global de finanzas automotrices! Los puntos destacados incluyen:
- implementar y modernizar la plataforma de análisis en la nube con controles de privacidad cibernética y PII
- aprovechar el marco basado en metadatos de Databricks Unity Catalog para configurar las canalizaciones ELT y almacenar los datos en el lakehouse
- integrar Databricks Workflows con ServiceNow para facilitar el monitoreo y el manejo de fallos
Qué hacer a continuación
La migración rara vez es sencilla. Las compensaciones, los retrasos y los desafíos inesperados son parte del proceso, especialmente al alinear personas, procesos y tecnología.
Es por eso que es importante trabajar con equipos que ya han hecho esto. Databricks Professional Services y nuestros socios de migración certificados aportan una profunda experiencia en la entrega de migraciones de alta calidad a tiempo y a escala. Contáctenos para comenzar su evaluación de migración.
¿Busca más orientación? Descargue la Guía de migración de Oracle a Databricks completa con pasos prácticos, información sobre herramientas y plantillas de planificación para ayudarle a moverse con confianza.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.