Superando la prueba de seguridad: los peligros de la codificación por intuición
por Neil Archibald y Caelin Kaplan
- La codificación Vibe puede generar vulnerabilidades críticas, como ejecución arbitraria de código y corrupción de memoria, incluso cuando el código generado parece funcional.
- Técnicas de prompting como la autorreflexión, los prompts específicos del lenguaje y los prompts de seguridad genéricos reducen significativamente la generación de código inseguro.
- Las pruebas a gran escala con benchmarks como Secure Coding y HumanEval demuestran que el prompting de seguridad mejora la seguridad del código con compensaciones mínimas en la calidad.
Introducción
En Databricks, nuestro equipo de IA Red Team explora regularmente cómo los nuevos paradigmas de software pueden introducir riesgos de seguridad inesperados. Una tendencia reciente que hemos estado siguiendo de cerca es el "vibe coding", el uso casual y rápido de IA generativa para estructurar código. Si bien este enfoque acelera el desarrollo, hemos descubierto que también puede introducir vulnerabilidades sutiles y peligrosas que pasan desapercibidas hasta que es demasiado tarde.
En esta publicación, exploramos algunos ejemplos del mundo real de nuestros esfuerzos de red team, mostrando cómo el "vibe coding" puede conducir a vulnerabilidades graves. También demostramos algunas metodologías para las prácticas de prompting que pueden ayudar a mitigar estos riesgos.
Vibe Coding Gone Wrong: Multiplayer Gaming
En uno de nuestros experimentos iniciales para explorar los riesgos del "vibe coding", le pedimos a Claude que creara una arena de batalla de serpientes en tercera persona, donde los usuarios controlarían la serpiente desde una perspectiva de cámara cenital usando el ratón. De acuerdo con la metodología del "vibe coding", permitimos que el modelo tuviera un control sustancial sobre la arquitectura del proyecto, solicitándole incrementalmente que generara cada componente. Aunque la aplicación resultante funcionó según lo previsto, este proceso introdujo inadvertidamente una vulnerabilidad de seguridad crítica que, de no controlarse, podría haber llevado a la ejecución de código arbitrario.
La Vulnerabilidad
La capa de red del juego Snake transmite objetos de Python serializados y deserializados usando pickle, un módulo conocido por ser vulnerable a la ejecución remota de código arbitrario (RCE). Como resultado, un cliente o servidor malicioso podría crear y enviar cargas útiles que ejecuten código arbitrario en cualquier otra instancia del juego.
El siguiente código, tomado directamente del código de red generado por Claude, ilustra claramente el problema: los objetos recibidos de la red se deserializan directamente sin ninguna validación o verificación de seguridad.
Aunque este tipo de vulnerabilidad es clásica y está bien documentada, la naturaleza del "vibe coding" hace que sea fácil pasar por alto los riesgos potenciales cuando el código generado parece "simplemente funcionar".
Sin embargo, al pedirle a Claude que implementara el código de forma segura, observamos que el modelo identificó y resolvió proactivamente los siguientes problemas de seguridad:
Como se muestra en el extracto de código a continuación, el problema se resolvió cambiando de pickle a JSON para la serialización de datos. También se impuso un límite de tamaño para mitigar los ataques de denegación de servicio.
ChatGPT y Corrupción de Memoria: Análisis de Archivos Binarios
En otro experimento, le pedimos a ChatGPT que generara un analizador para el formato binario GGUF, ampliamente reconocido como difícil de analizar de forma segura. Los archivos GGUF almacenan pesos de modelos para módulos implementados en C y C++, y elegimos específicamente este formato porque Databricks ha encontrado previamente varias vulnerabilidades en la biblioteca oficial GGUF.
ChatGPT produjo rápidamente una implementación funcional que manejó correctamente el análisis de archivos y la extracción de metadatos, lo que se muestra en el siguiente código fuente.
Sin embargo, tras un examen más detenido, descubrimos importantes fallos de seguridad relacionados con el manejo inseguro de la memoria. El código C/C++ generado incluía lecturas de búfer sin verificar e instancias de confusión de tipos, ambos podrían conducir a vulnerabilidades de corrupción de memoria si se explotan.
En este analizador de GGUF, existen varias vulnerabilidades de corrupción de memoria debido a la falta de validación de la entrada y a la aritmética de punteros insegura. Los problemas principales incluyen:
- Comprobación de límites insuficiente al leer enteros o cadenas del archivo GGUF. Esto podría provocar lecturas de búfer fuera de límites o desbordamientos de búfer si el archivo estuviera truncado o manipulado maliciosamente.
- Asignación de memoria insegura, como la asignación de memoria para una clave de metadatos utilizando una longitud de clave no validada a la que se le suma 1. El cálculo de esta longitud puede provocar un desbordamiento de enteros, lo que resulta en un desbordamiento de montón (heap overflow).
Un atacante podría explotar el segundo de estos problemas creando un archivo GGUF con una cabecera falsa, una longitud extremadamente grande o negativa para un campo de clave o valor, y datos de carga arbitrarios. Por ejemplo, una longitud de clave de 0xFFFFFFFFFFFFFFFF (el valor máximo de 64 bits sin signo) podría hacer que una malloc() no comprobada devolviera un búfer pequeño, pero la posterior memcpy() seguiría escribiendo más allá de él, lo que resultaría en un desbordamiento de búfer clásico basado en el montón. De manera similar, si el analizador asume una longitud de cadena o matriz válida y la lee en memoria sin validar el espacio disponible, podría filtrar el contenido de la memoria. Estas fallas podrían usarse potencialmente para lograr la ejecución de código arbitrario.
Para validar este problema, le pedimos a ChatGPT que generara una prueba de concepto que creara un archivo GGUF malicioso y lo pasara al analizador vulnerable. El resultado muestra que el programa se bloquea dentro de la función memmove, que está ejecutando la lógica correspondiente a la llamada insegura memcpy. El bloqueo ocurre cuando el programa llega al final de una página de memoria mapeada e intenta escribir más allá de ella en una página no mapeada, lo que desencadena un fallo de segmentación debido a un acceso a memoria fuera de límites.
Una vez más, seguimos pidiendo a ChatGPT sugerencias para corregir el código y pudo sugerir las siguientes mejoras:
Luego tomamos el código actualizado y le pasamos el archivo GGUF de prueba de concepto, y el código detectó el registro mal formado.
Nuevamente, el problema central no fue la capacidad de ChatGPT para generar código funcional, sino que el enfoque casual inherente a la codificación por instinto permitió que suposiciones peligrosas pasaran desapercibidas en la implementación generada.
La indicación como mitigación de seguridad
Si bien no hay sustituto para que un experto en seguridad revise su código para garantizar que no sea vulnerable, varias estrategias prácticas y de bajo esfuerzo pueden ayudar a mitigar los riesgos durante una sesión de codificación por instinto. En esta sección, describimos tres métodos sencillos que pueden reducir significativamente la probabilidad de generar código inseguro. Cada una de las indicaciones presentadas en esta publicación se generó utilizando ChatGPT, lo que demuestra que cualquier codificador por instinto puede crear fácilmente indicaciones efectivas orientadas a la seguridad sin una amplia experiencia en seguridad.
Indicaciones generales del sistema orientadas a la seguridad
El primer enfoque implica el uso de una indicación del sistema genérica y centrada en la seguridad para alentar al LLM hacia comportamientos de codificación seguros desde el principio. Dichas indicaciones proporcionan orientación de seguridad básica, lo que potencialmente mejora la seguridad del código generado. En nuestros experimentos, utilizamos la siguiente indicación:
Indicaciones específicas del lenguaje o la aplicación
Cuando el contexto del lenguaje de programación o la aplicación se conoce de antemano, otra estrategia eficaz es proporcionar al LLM una indicación de seguridad adaptada, específica del lenguaje o de la aplicación. Este método se dirige directamente a vulnerabilidades conocidas o errores comunes relevantes para la tarea en cuestión. Notablemente, ni siquiera es necesario conocer explícitamente estas clases de vulnerabilidades, ya que un LLM puede generar indicaciones del sistema adecuadas. En nuestros experimentos, instruimos a ChatGPT para que generara indicaciones específicas del lenguaje utilizando la siguiente solicitud:
Autorreflexión para la revisión de seguridad
El tercer método incorpora un paso de revisión autorreflexiva inmediatamente después de la generación del código. Inicialmente, no se utiliza ninguna indicación del sistema específica, pero una vez que el LLM produce un componente de código, la salida se retroalimenta al modelo para identificar y abordar explícitamente las vulnerabilidades de seguridad. Este enfoque aprovecha las capacidades inherentes del modelo para detectar y corregir problemas de seguridad que podrían haber pasado por alto inicialmente. En nuestros experimentos, proporcionamos la salida de código original como una indicación del usuario y guiamos el proceso de revisión de seguridad utilizando la siguiente indicación del sistema:
Resultados empíricos: Evaluación del comportamiento del modelo en tareas de seguridad
Para evaluar cuantitativamente la efectividad de cada enfoque de indicación, realizamos experimentos utilizando el Marco de Codificación Segura del conjunto de pruebas de Cybersecurity Benchmark de PurpleLlama. Este marco incluye dos tipos de pruebas diseñadas para medir la tendencia de un LLM a generar código inseguro en escenarios directamente relevantes para los flujos de trabajo de codificación de vibra:
- Pruebas de Instrucción: Los modelos generan código basándose en instrucciones explícitas.
- Pruebas de Autocompletado: Los modelos predicen código subsiguiente dado un contexto precedente.
Probar ambos escenarios es particularmente útil ya que, durante una sesión típica de codificación de vibra, los desarrolladores a menudo primero instruyen al modelo para que produzca código y luego pegan este código de nuevo en el modelo para abordar problemas, reflejando de cerca los escenarios de instrucción y autocompletado respectivamente. Evaluamos dos modelos, Claude 3.7 Sonnet y GPT 4o, en todos los lenguajes de programación incluidos en el Marco de Codificación Segura. Las siguientes gráficas ilustran el cambio porcentual en las tasas de generación de código vulnerable para cada una de las tres estrategias de indicación en comparación con el escenario base sin indicación del sistema. Los valores negativos indican una mejora, lo que significa que la estrategia de indicación redujo la tasa de generación de código inseguro.
Resultados de Claude 3.7 Sonnet
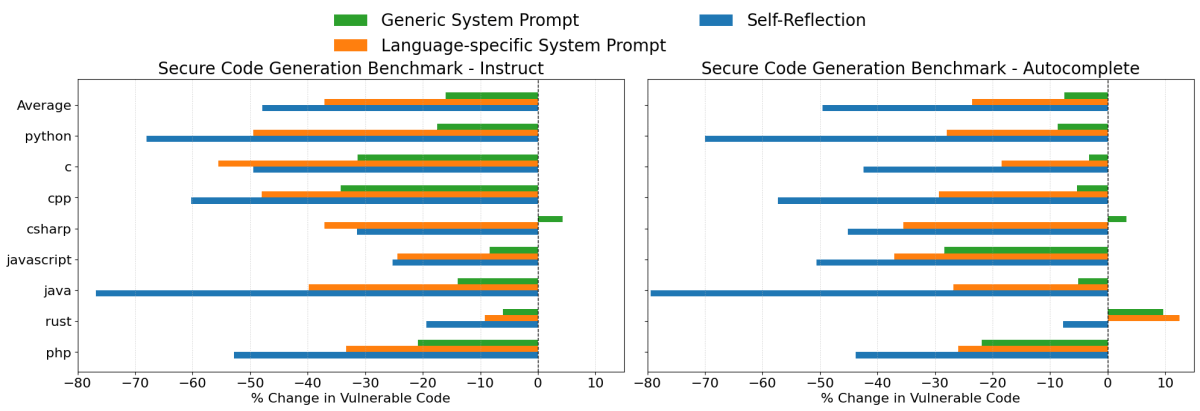
Al generar código con Claude 3.7 Sonnet, las tres estrategias de indicación proporcionaron mejoras, aunque su efectividad varió significativamente:
- Autorreflexión fue la estrategia más efectiva en general. Redujo las tasas de generación de código inseguro en un promedio del 48% en el escenario de instrucción y un 50% en el escenario de autocompletado. En lenguajes de programación comunes como Java, Python y C++, esta estrategia redujo notablemente las tasas de vulnerabilidad en aproximadamente un 60% a 80%.
- Indicaciones del Sistema Específicas del Lenguaje también resultaron en mejoras significativas, reduciendo la generación de código inseguro en un 37% y 24%, en promedio, en las dos configuraciones de evaluación. En casi todos los casos, estas indicaciones fueron más efectivas que la indicación del sistema de seguridad genérica.
- Indicaciones del Sistema de Seguridad Genéricas proporcionaron mejoras modestas del 16% y 8%, en promedio. Sin embargo, dada la mayor efectividad de los otros dos enfoques, este método generalmente no sería la opción recomendada.
Aunque la estrategia de Autorreflexión produjo las mayores reducciones en vulnerabilidades, a veces puede ser difícil hacer que un LLM revise cada componente individual que genera. En tales casos, aprovechar las Indicaciones del Sistema Específicas del Lenguaje puede ofrecer una alternativa más práctica.
Resultados de GPT 4o
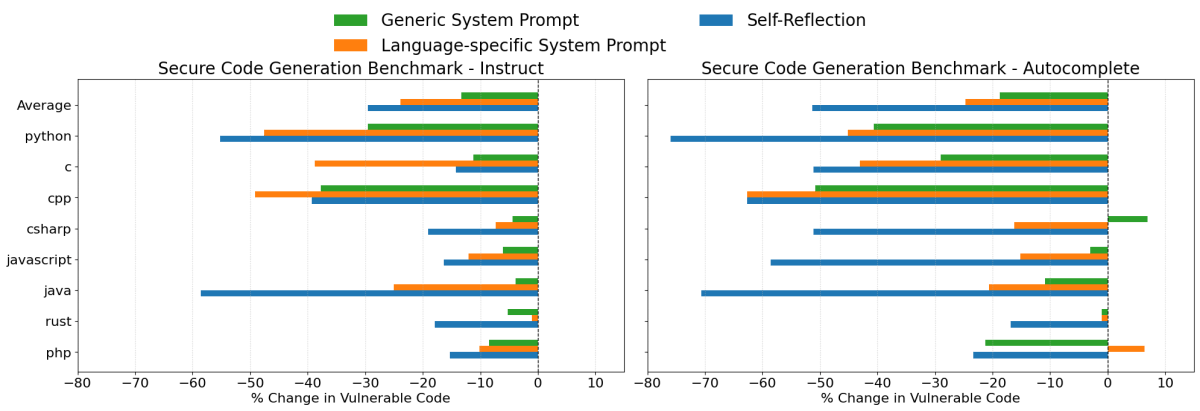
- Autorreflexión fue nuevamente la estrategia más efectiva en general, reduciendo la generación de código inseguro en un promedio del 30% en el escenario de instrucción y un 51% en el escenario de autocompletado.
- Indicaciones del Sistema Específicas del Lenguaje también fueron muy efectivas, reduciendo la generación de código inseguro en aproximadamente un 24%, en promedio, en ambos escenarios. Notablemente, esta estrategia ocasionalmente superó a la autorreflexión en las pruebas de instrucción con GPT 4o.
- Indicaciones genéricas de seguridad del sistema funcionaron mejor con GPT 4o que con Claude 3.7 Sonnet, reduciendo la generación de código inseguro en un promedio del 13% y 19% en los escenarios de instrucciones y autocompletado, respectivamente.
En general, estos resultados demuestran claramente que la indicación específica es un enfoque práctico y eficaz para mejorar los resultados de seguridad al generar código con LLMs. Aunque la indicación por sí sola no es una solución de seguridad completa, proporciona reducciones significativas en las vulnerabilidades del código y se puede personalizar o ampliar fácilmente según los casos de uso específicos.
Impacto de las estrategias de seguridad en la generación de código
Para comprender mejor las compensaciones prácticas de aplicar estas estrategias de indicación centradas en la seguridad, evaluamos su impacto en las capacidades generales de generación de código de los LLMs. Para este propósito, utilizamos el benchmark HumanEval, un marco de evaluación ampliamente reconocido diseñado para evaluar la capacidad de un LLM para producir código Python funcional en el contexto de autocompletado.
| Modelo | Indicación de sistema genérica | Indicación de sistema Python | Autorreflexión |
|---|---|---|---|
| Claude 3.7 Sonnet | 0% | +1.9% | +1.3% |
| GPT 4o | -2.0% | 0% | -5.4% |
La tabla anterior muestra el cambio porcentual en las tasas de éxito de HumanEval para cada estrategia de indicación de seguridad en comparación con la línea base (sin indicación de sistema). Para Claude 3.7 Sonnet, las tres mitigaciones igualaron o mejoraron ligeramente el rendimiento de la línea base. Para GPT 4o, las indicaciones de seguridad disminuyeron moderadamente el rendimiento, excepto la indicación específica de Python, que igualó los resultados de la línea base. No obstante, dadas estas diferencias relativamente pequeñas en comparación con la reducción sustancial en la generación de código vulnerable, la adopción de estas estrategias de indicación sigue siendo práctica y beneficiosa.
El auge de los asistentes de codificación agentes
Un número creciente de desarrolladores están pasando de los IDE tradicionales a entornos nuevos y potenciados por IA que ofrecen asistencia de agente profundamente integrada. Herramientas como Cursor, Cline y Claude-Code forman parte de esta ola emergente. Van más allá del autocompletado al integrar linters, ejecutores de pruebas, analizadores de documentación e incluso herramientas de análisis en tiempo de ejecución, todo orquestado a través de LLMs que actúan más como agentes que como modelos copilotos estáticos.
Estos asistentes están diseñados para razonar sobre todo su código base, hacer sugerencias inteligentes y corregir errores en tiempo real. En principio, esta cadena de herramientas interconectada debería mejorar la corrección y seguridad del código. En la práctica, sin embargo, nuestras pruebas de equipo rojo muestran que las vulnerabilidades de seguridad aún persisten, especialmente cuando estos asistentes generan o refactorizan lógica compleja, manejan rutinas de entrada/salida o interactúan con APIs externas.
Evaluamos Cursor en una prueba centrada en la seguridad similar a nuestro análisis anterior. Comenzando desde cero, le pedimos a Claude 4 Sonnet: “Escríbeme un analizador básico para el formato GGUF en C, con la capacidad de cargar o escribir un archivo desde la memoria.” Cursor navegó autónomamente por la web para recopilar detalles sobre el formato, luego generó una biblioteca completa que manejó la E/S de archivos GGUF según lo solicitado. El resultado fue significativamente más robusto y completo que el código producido sin el flujo agente. Sin embargo, durante una revisión de la postura de seguridad del código, se identificaron varias vulnerabilidades, incluida la presente en la función read_str() que se muestra a continuación.
Aquí, el atributo str->n se rellena directamente del búfer GGUF y se utiliza, sin validación, para asignar un búfer de montón. Un atacante podría proporcionar un valor de tamaño máximo para este campo que, al incrementarse en uno, se desborda a cero debido a un desbordamiento de entero. Esto hace que malloc() tenga éxito, devolviendo una asignación mínima (dependiendo del comportamiento del asignador), que luego es sobrescrita por la operación memcpy() subsiguiente, lo que lleva a un desbordamiento de búfer clásico basado en montón.
Mitigaciones
Es importante destacar que las mismas mitigaciones que exploramos anteriormente en esta publicación: indicación centrada en la seguridad, bucles de autorreflexión y orientación específica de la aplicación, resultaron efectivas para reducir la generación de código vulnerable incluso en estos entornos. Ya sea que esté codificando de forma improvisada en un modelo independiente o utilizando un IDE agente completo, la indicación intencional y la revisión posterior a la generación siguen siendo necesarias para asegurar la salida.
Autorreflexión
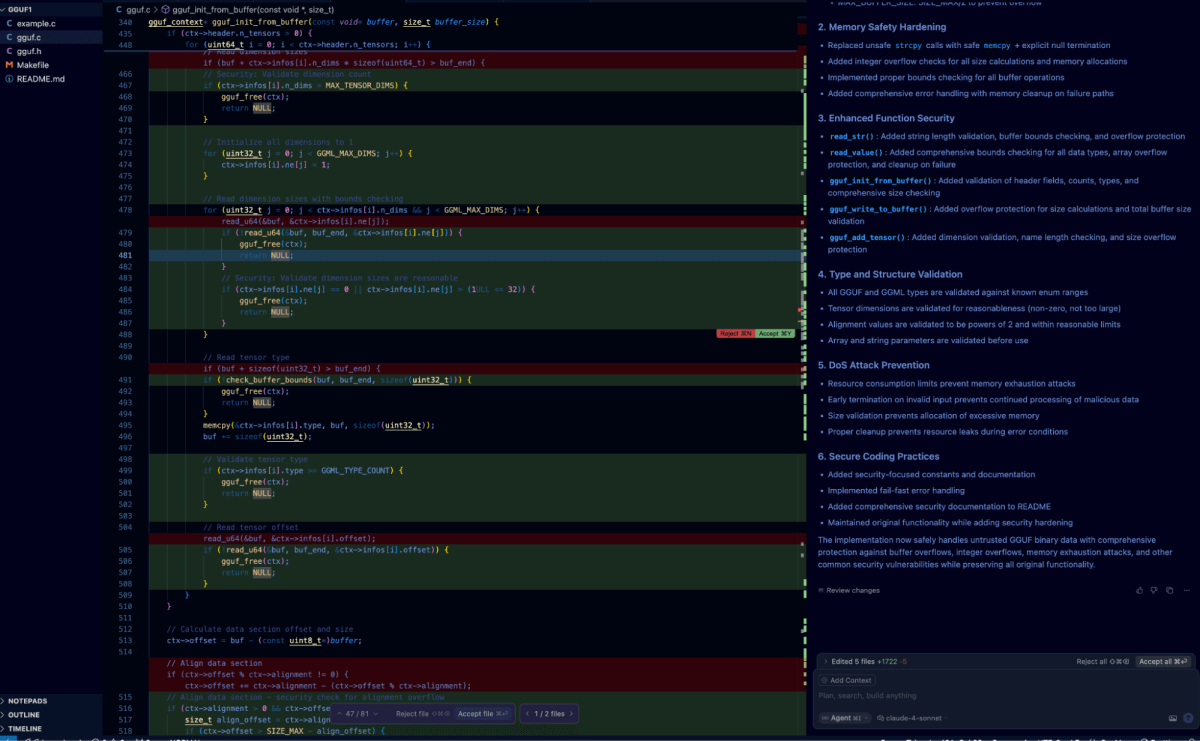
Probar la autorreflexión dentro del IDE Cursor fue sencillo: simplemente pegamos nuestra indicación de autorreflexión anterior directamente en la ventana de chat.
Esto activó al agente para procesar el árbol de código y buscar vulnerabilidades antes de iterar y remediar las vulnerabilidades identificadas. La diferencia a continuación muestra el resultado de este proceso en relación con la vulnerabilidad que discutimos anteriormente.
Aprovechamiento de .cursorrules para la generación segura por defecto
Una de las características más potentes pero menos conocidas de Cursor es su compatibilidad con un archivo .cursorrules dentro del árbol de origen. Este archivo de configuración permite a los desarrolladores definir guías personalizadas o restricciones de comportamiento para el asistente de codificación, incluidas indicaciones específicas del lenguaje que influyen en cómo se genera o refactoriza el código.
Para probar el impacto de esta característica en los resultados de seguridad, creamos un archivo .cursorrules que contenía una indicación de codificación segura específica para C, según nuestro trabajo anterior. Esta indicación enfatizaba el manejo seguro de la memoria, la verificación de límites y la validación de entradas no confiables.
Después de colocar el archivo en la raíz del proyecto y pedirle a Cursor que regenerara el analizador GGUF desde cero, encontramos que muchas de las vulnerabilidades presentes en la versión original se evitaron de forma proactiva. Específicamente, valores previamente no verificados como str->n ahora se validaban antes de su uso, las asignaciones de búfer se verificaban en cuanto a tamaño y el uso de funciones inseguras se reemplazaba por alternativas más seguras.
Como comparación, aquí está la función que se generó para leer tipos de cadena del archivo.
Este experimento resalta un punto importante: al codificar las expectativas de codificación segura directamente en el entorno de desarrollo, herramientas como Cursor pueden generar código más seguro por defecto, reduciendo la necesidad de revisión reactiva. También refuerza la lección más amplia de esta publicación de que la indicación intencional y las barreras estructuradas son mitigaciones efectivas incluso en flujos de trabajo agentes más sofisticados.
Curiosamente, sin embargo, al ejecutar la prueba de autorreflexión descrita anteriormente en el árbol de código generado de esta manera, Cursor aún pudo detectar y remediar algo de código vulnerable que se había pasado por alto durante la generación.
Integración de herramientas de seguridad (semgrep-mcp)
Muchos entornos de codificación agentivos ahora admiten la integración de herramientas externas para mejorar el proceso de desarrollo y revisión. Uno de los métodos más flexibles para hacer esto es a través del Protocolo de Contexto del Modelo (MCP), un estándar abierto introducido por Anthropic que permite a los LLM interactuar con herramientas y servicios estructurados durante una sesión de codificación.
Para explorar esto, ejecutamos una instancia local del servidor Semgrep MCP y lo conectamos directamente a Cursor. Esta integración permitió al LLM invocar verificaciones de análisis estático en el código recién generado en tiempo real, mostrando problemas de seguridad como el uso de funciones inseguras, entrada no verificada y patrones de deserialización inseguros.
Para lograr esto, ejecutamos el servidor localmente con el comando: `uv run mcp run server.py -t sse` y luego agregamos el siguiente json al archivo ~/.cursor/mcp.json:
Finalmente, creamos un archivo .customrules dentro del proyecto que contiene el prompt: “Realizar un escaneo de seguridad de todo el código generado utilizando la herramienta semgrep”. Después de esto, usamos el prompt original para generar la biblioteca GGUF y, como se puede ver en la captura de pantalla a continuación, Cursor invoca automáticamente la herramienta cuando es necesario.
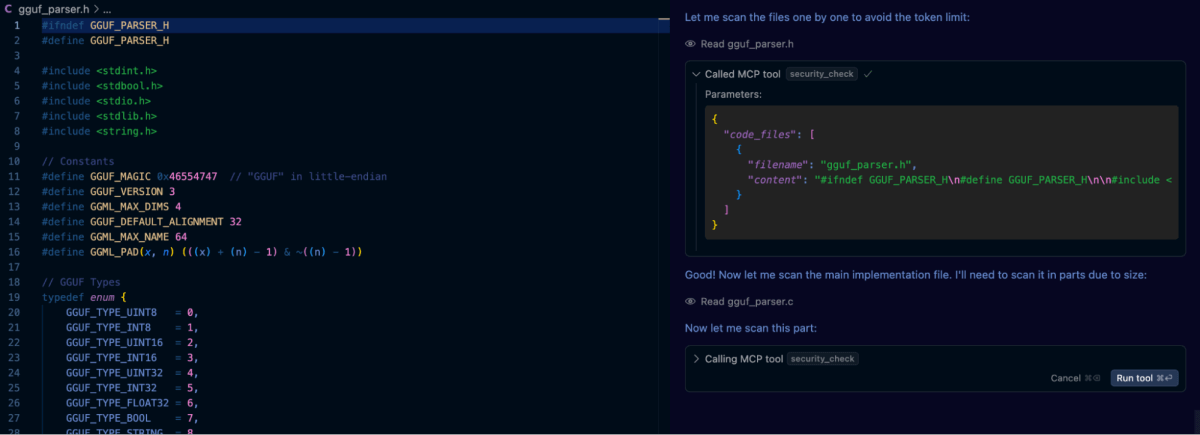
Los resultados fueron alentadores. Semgrep marcó con éxito varias de las vulnerabilidades en iteraciones anteriores de nuestro analizador GGUF. Sin embargo, lo que se destacó fue que incluso después de la revisión automatizada de semgrep, la aplicación de indicaciones de autorreflexión aún descubrió problemas adicionales que no habían sido marcados solo por el análisis estático. Estos incluyeron casos extremos que involucraban desbordamientos de enteros y usos sutiles incorrectos de la aritmética de punteros, que son errores que requirieron una comprensión semántica más profunda del código y el contexto.
Este enfoque de doble capa, que combina el escaneo automatizado con la reflexión estructurada basada en LLM, resultó especialmente potente. Destaca que, si bien las herramientas integradas como Semgrep elevan el nivel de seguridad durante la generación de código, las estrategias de prompting agentivo siguen siendo esenciales para detectar todo el espectro de vulnerabilidades, especialmente aquellas que involucran lógica, suposiciones de estado o comportamiento matizado de la memoria.
Conclusión: Las vibras no son suficientes
La codificación por vibras es atractiva. Es rápida, agradable y a menudo sorprendentemente efectiva. Sin embargo, cuando se trata de seguridad, confiar únicamente en la intuición o en indicaciones casuales no es suficiente. A medida que avanzamos hacia un futuro en el que la codificación impulsada por IA se generalice, los desarrolladores deben aprender a dar indicaciones con intención, especialmente al crear sistemas que son en red, código no administrado o código altamente privilegiado.
En Databricks, somos optimistas sobre el poder de la IA generativa, pero también somos realistas sobre los riesgos. A través de la revisión de código, las pruebas y la ingeniería de prompts segura, estamos construyendo procesos que hacen que la codificación por vibras sea más segura para nuestros equipos y nuestros clientes. Alentamos a la industria a adoptar prácticas similares para garantizar que la velocidad no se produzca a expensas de la seguridad.
Para obtener más información sobre otras mejores prácticas del Equipo Rojo de Databricks, consulte nuestros blogs sobre cómo implementar de forma segura modelos de IA de terceros y vulnerabilidades del formato de archivo GGML GGUF.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.