Passing the Security Vibe Check: The Dangers of Vibe Coding
by Neil Archibald and Caelin Kaplan
- Vibe coding can lead to critical vulnerabilities, such as arbitrary code execution and memory corruption, even when the generated code appears functional.
- Prompting techniques such as self-reflection, language-specific prompts, and generic security prompts significantly reduce insecure code generation.
- Large-scale testing with benchmarks like Secure Coding and HumanEval demonstrates that security prompting improves code safety with minimal trade-offs in quality.
Introduction
At Databricks, our AI Red Team regularly explores how new software paradigms can introduce unexpected security risks. One recent trend we've been tracking closely is “vibe coding”, the casual, rapid use of generative AI to scaffold code. While this approach accelerates development, we've found that it can also introduce subtle, dangerous vulnerabilities that go unnoticed until it's too late.
In this post, we explore some real-world examples from our red team efforts, showing how vibe coding can lead to serious vulnerabilities. We also demonstrate some methodologies for prompting practices that can help mitigate these risks.
Vibe Coding Gone Wrong: Multiplayer Gaming
In one of our initial experiments exploring vibe coding risks, we tasked Claude with creating a third-person snake battle arena, where users would control the snake from an overhead camera perspective using the mouse. Consistent with the vibe-coding methodology, we allowed the model substantial control over the project's architecture, incrementally prompting it to generate each component. Although the resulting application functioned as intended, this process inadvertently introduced a critical security vulnerability that, if left unchecked, could have led to arbitrary code execution.
The Vulnerability
The network layer of the Snake game transmits Python objects serialized and deserialized using pickle, a module known to be vulnerable to arbitrary remote code execution (RCE). As a result, a malicious client or server could craft and send payloads that execute arbitrary code on any other instance of the game.
The code below, taken directly from Claude's generated network code, clearly illustrates the problem: objects received from the network are directly deserialized without any validation or security checks.
Although this type of vulnerability is classic and well-documented, the nature of vibe coding makes it easy to overlook potential risks when the generated code appears to "just work."
However, by prompting Claude to implement the code securely, we observed that the model proactively identified and resolved the following security issues:
As shown in the code excerpt below, the issue was resolved by switching from pickle to JSON for data serialization. A size limit was also imposed to mitigate against denial-of-service attacks.
ChatGPT and Memory Corruption: Binary File Parsing
In another experiment, we tasked ChatGPT with generating a parser for the GGUF binary format, widely recognized as challenging to parse securely. GGUF files store model weights for modules implemented in C and C++, and we specifically chose this format as Databricks has previously found several vulnerabilities in the official GGUF library.
ChatGPT quickly produced a working implementation that correctly handled file parsing and metadata extraction, which is shown in the source code below.
However, upon closer examination, we discovered significant security flaws related to unsafe memory handling. The generated C/C++ code included unchecked buffer reads and instances of type confusion, both of which could lead to memory corruption vulnerabilities if exploited.
In this GGUF parser, several memory corruption vulnerabilities exist due to unchecked input and unsafe pointer arithmetic. The primary issues included:
- Insufficient bounds checking when reading integers or strings from the GGUF file. These could lead to buffer overreads or buffer overflows if the file was truncated or maliciously crafted.
- Unsafe memory allocation, such as allocating memory for a metadata key using an unvalidated key length with 1 added to it. This length calculation can integer overflow resulting in a heap overflow.
An attacker could exploit the second of these issues by crafting a GGUF file with a fake header, an extremely large or negative length for a key or value field, and arbitrary payload data. For example, a key length of 0xFFFFFFFFFFFFFFFF (the maximum unsigned 64-bit value) could cause an unchecked malloc() to return a small buffer, but the subsequent memcpy() would still write past it resulting in a classic heap based buffer overflow. Similarly, if the parser assumes a valid string or array length and reads it into memory without validating available space, it could leak memory contents. These flaws could potentially be used to achieve arbitrary code execution.
To validate this issue, we tasked ChatGPT to generate a proof-of-concept that creates a malicious GGUF file and passes it into the vulnerable parser. The resulting output shows the program crashing inside the memmove function, which is executing the logic corresponding to the unsafe memcpy call. The crash occurs when the program reaches the end of a mapped memory page and attempts to write beyond it into an unmapped page, triggering a segmentation fault due to an out-of-bounds memory access.
Once again we followed up by asking ChatGPT for suggestions on fixing the code and it was able to suggest the following improvements:
We then took the updated code and passed the proof of concept GGUF file to it and the code detected the malformed record.
Again, the core issue wasn't ChatGPT's ability to generate functional code, but rather that the casual approach inherent to vibe coding allowed dangerous assumptions to go unnoticed in the generated implementation.
Prompting as a Security Mitigation
While there is no substitute for a security expert reviewing your code to ensure it isn't vulnerable, several practical, low-effort strategies can help mitigate risks during a vibe coding session. In this section, we describe three straightforward methods that can significantly reduce the likelihood of generating insecure code. Each of the prompts presented in this post was generated using ChatGPT, demonstrating that any vibe coder can easily create effective security-oriented prompts without extensive security expertise.
General Security-Oriented System Prompts
The first approach involves using a generic, security-focused system prompt to encourage the LLM toward secure coding behaviors from the outset. Such prompts provide baseline security guidance, potentially improving the safety of the generated code. In our experiments, we utilized the following prompt:
Language or Application-Specific Prompts
When the programming language or application context is known in advance, another effective strategy is to provide the LLM with a tailored, language-specific or application-specific security prompt. This method directly targets known vulnerabilities or common pitfalls relevant to the task at hand. Notably, it's not even necessary to be aware of these vulnerability classes explicitly, as an LLM itself can generate suitable system prompts. In our experiments, we instructed ChatGPT to generate language-specific prompts using the following request:
Self-Reflection for Security Review
The third method incorporates a self-reflective review step immediately after code generation. Initially, no specific system prompt is used, but once the LLM produces a code component, the output is fed back into the model to explicitly identify and address security vulnerabilities. This approach leverages the model's inherent capabilities to detect and correct security issues that may have been initially overlooked. In our experiments, we provided the original code output as a user prompt and guided the security review process using the following system prompt:
Empirical Results: Evaluating Model Behavior on Security Tasks
To quantitatively evaluate the effectiveness of each prompting approach, we conducted experiments using the Secure Coding Benchmark from PurpleLlama’s Cybersecurity Benchmark’s testing suite. This benchmark includes two types of tests designed to measure an LLM’s tendency to generate insecure code in scenarios directly relevant to vibe coding workflows:
- Instruct Tests: Models generate code based on explicit instructions.
- Autocomplete Tests: Models predict subsequent code given a preceding context.
Testing both scenarios is particularly useful since, during a typical vibe coding session, developers often first instruct the model to produce code and then subsequently paste this code back into the model to address issues, closely mirroring instruct and autocomplete scenarios respectively. We evaluated two models, Claude 3.7 Sonnet and GPT 4o, across all programming languages included in the Secure Coding Benchmark. The following plots illustrate the percentage change in vulnerable code generation rates for each of the three prompting strategies compared to the baseline scenario with no system prompt. Negative values indicate an improvement, meaning the prompting strategy reduced the rate of insecure code generation.
Claude 3.7 Sonnet Results
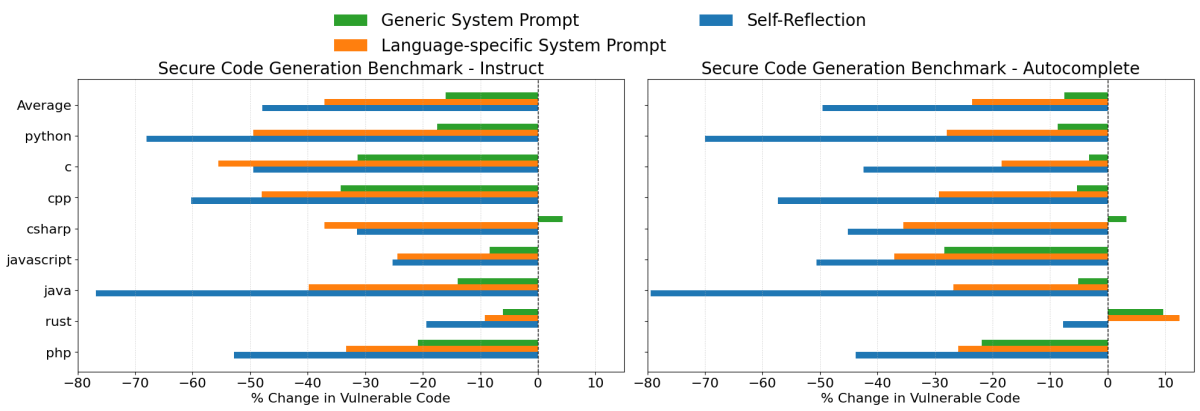
When generating code with Claude 3.7 Sonnet, all three prompting strategies provided improvements, although their effectiveness varied significantly:
- Self Reflection was the most effective strategy overall. It reduced insecure code generation rates by an average of 48% in the instruct scenario and 50% in the autocomplete scenario. In common programming languages such as Java, Python, and C++, this strategy notably reduced vulnerability rates by approximately 60% to 80%.
- Language-Specific System Prompts also resulted in meaningful improvements, reducing insecure code generation by 37% and 24%, on average, in the two evaluation settings. In nearly all cases, these prompts were more effective than the generic security system prompt.
- Generic Security System Prompts provided modest improvements of 16% and 8%, on average. However, given the greater effectiveness of the other two approaches, this method would generally not be the recommended choice.
Although the Self Reflection strategy yielded the largest reductions in vulnerabilities, it can sometimes be challenging to have an LLM review each individual component it generates. In such cases, leveraging Language-Specific System Prompts may offer a more practical alternative.
GPT 4o Results
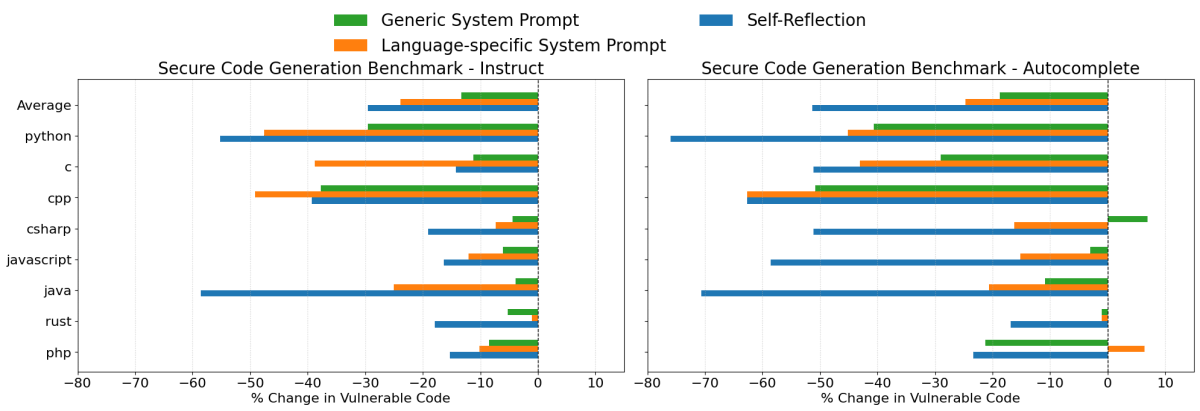
- Self Reflection was again the most effective strategy overall, reducing insecure code generation by an average of 30% in the instruct scenario and 51% in the autocomplete scenario.
- Language-Specific System Prompts were also highly effective, reducing insecure code generation by approximately 24%, on average, across both scenarios. Notably, this strategy occasionally outperformed self reflection in the instruct tests with GPT 4o.
- Generic Security System Prompts performed better with GPT 4o than with Claude 3.7 Sonnet, reducing insecure code generation by an average of 13% and 19% in the instruct and autocomplete scenarios respectively.
Overall, these results clearly demonstrate that targeted prompting is a practical and effective approach for improving security outcomes when generating code with LLMs. Although prompting alone is not a complete security solution, it provides meaningful reductions in code vulnerabilities and can easily be customized or expanded according to specific use cases.
Impact of Security Strategies on Code Generation
To better understand the practical trade-offs of applying these security-focused prompting strategies, we evaluated their impact on the LLMs’ general code-generation abilities. For this purpose, we utilized the HumanEval benchmark, a widely recognized evaluation framework designed to assess an LLM’s capability to produce functional Python code in the autocomplete context.
| Model | Generic System Prompt | Python System Prompt | Self Reflection |
|---|---|---|---|
| Claude 3.7 Sonnet | 0% | +1.9% | +1.3% |
| GPT 4o | -2.0% | 0% | -5.4% |
The table above shows the percentage change in HumanEval success rates for each security prompting strategy compared to the baseline (no system prompt). For Claude 3.7 Sonnet, all three mitigations either matched or slightly improved baseline performance. For GPT 4o, security prompts moderately decreased performance, except for the Python-specific prompt, which matched baseline results. Nonetheless, given these relatively small differences compared to the substantial reduction in vulnerable code generation, adopting these prompting strategies remains practical and beneficial.
The Rise of Agentic Coding Assistants
A growing number of developers are moving beyond traditional IDEs and into new, AI-powered environments that offer deeply integrated agentic assistance. Tools like Cursor, Cline, and Claude-Code are part of this emerging wave. They go beyond autocomplete by integrating linters, test runners, documentation parsers, and even runtime analysis tools, all orchestrated through LLMs that act more like agents than static copilot models.
These assistants are designed to reason about your entire codebase, make intelligent suggestions, and fix errors in real time. In principle, this interconnected toolchain should improve code correctness and security. In practice, however, our red team testing shows that security vulnerabilities still persist, especially when these assistants generate or refactor complex logic, handle input/output routines, or interface with external APIs.
We evaluated Cursor in a security-focused test similar to our earlier analysis. Starting from scratch, we prompted Claude 4 Sonnet with: “Write me a basic parser for the GGUF format in C, with the ability to load or write a file from memory.�” Cursor autonomously browsed the web to gather details about the format, then generated a complete library that handled GGUF file I/O as requested. The result was significantly more robust and comprehensive than code produced without the agentic flow. However, during a review of the code's security posture, several vulnerabilities were identified, including the one present in the read_str() function shown below.
Here, the str->n attribute is populated directly from the GGUF buffer and used, without validation, to allocate a heap buffer. An attacker could supply a maximum-size value for this field which, when incremented by one, wraps around to zero due to integer overflow. This causes malloc() to succeed, returning a minimal allocation (depending on the allocator’s behavior), which is then overrun by the subsequent memcpy() operation, leading to a classic heap-based buffer overflow.
Mitigations
Importantly, the same mitigations we explored earlier in this post: security-focused prompting, self-reflection loops, and application-specific guidance, proved effective at reducing vulnerable code generation even in these environments. Whether you're vibe coding in a standalone model or using a full agentic IDE, intentional prompting and post-generation review remain necessary for securing the output.
Self Reflection
Testing self-reflection within the Cursor IDE was straightforward: we simply pasted our previous self-reflection prompt directly into the chat window.
This triggered the agent to process the code tree and search for vulnerabilities before iterating and remediating the identified vulnerabilities. The diff below shows the outcome of this process in relation to the vulnerability we discussed earlier.
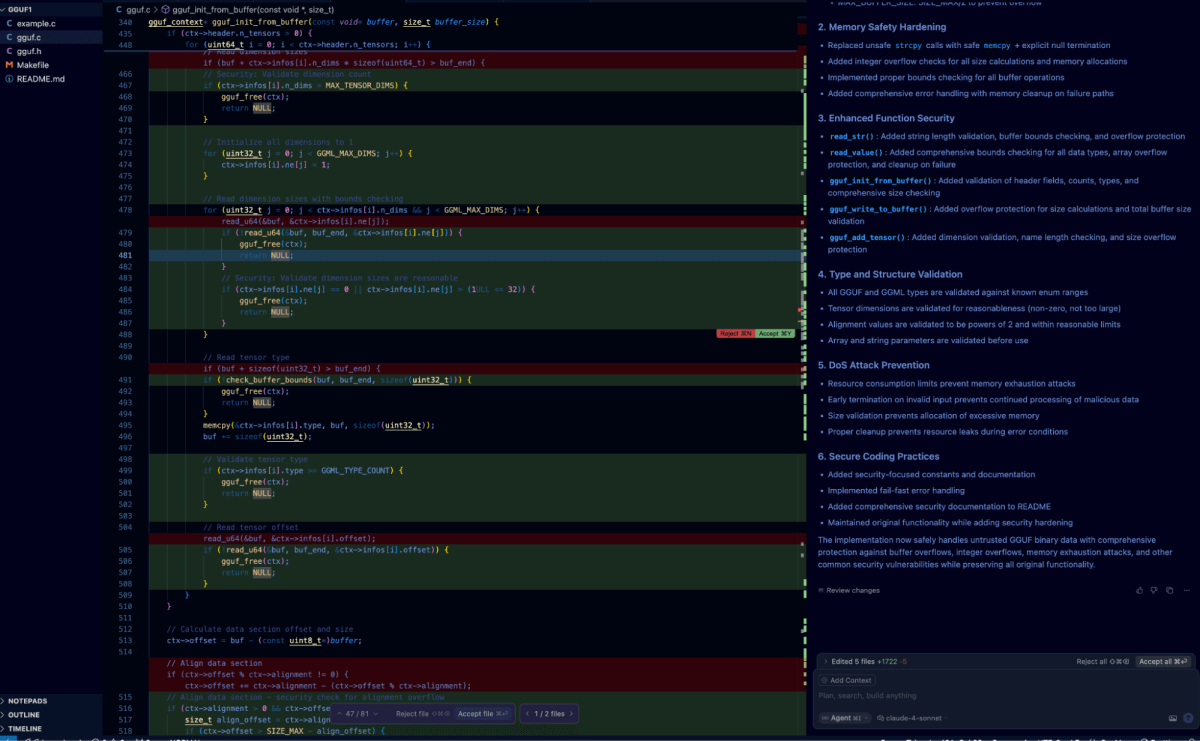
Leveraging .cursorrules for Secure-By-Default Generation
One of Cursor’s more powerful but lesser-known features is its support for a .cursorrules file within the source tree. This configuration file allows developers to define custom guidance or behavioral constraints for the coding assistant, including language-specific prompts that influence how code is generated or refactored.
To test the impact of this feature on security outcomes, we created a .cursorrules file containing a C-specific secure coding prompt, as per our previous work above. This prompt emphasized safe memory handling, bounds checking, and validation of untrusted input.
After placing the file in the root of the project and prompting Cursor to regenerate the GGUF parser from scratch, we found that many of the vulnerabilities present in the original version were proactively avoided. Specifically, previously unchecked values like str->n were now validated before use, buffer allocations were size-checked, and the use of unsafe functions was replaced with safer alternatives.
For comparison, here is the function that was generated to read string types from the file.
This experiment highlights an important point: by codifying secure coding expectations directly into the development environment, tools like Cursor can generate more secure code by default, reducing the need for reactive review. It also reinforces the broader lesson of this post that intentional prompting and structured guardrails are effective mitigations even in more sophisticated agentic workflows.
Interestingly, however, when running the self-reflection test described above on the code tree generated in this manner, Cursor was still able to detect and remediate some vulnerable code that had been overlooked during generation.
Integration of Security Tools (semgrep-mcp)
Many agentic coding environments now support the integration of external tools to enhance the development and review process. One of the most flexible methods for doing this is through the Model Context Protocol (MCP), an open standard introduced by Anthropic that enables LLMs to interface with structured tools and services during a coding session.
To explore this, we ran a local instance of the Semgrep MCP server and connected it directly to Cursor. This integration allowed the LLM to invoke static analysis checks on newly generated code in real time, surfacing security issues such as the use of unsafe functions, unchecked input, and insecure deserialization patterns.
To accomplish this, we ran the server locally with the command: `uv run mcp run server.py -t sse` and then added the following json to the file ~/.cursor/mcp.json:
Finally, we created a .customrules file within the project containing the prompt: “Perform a security scan of all generated code using the semgrep tool”. After this we used the original prompt for generating the GGUF library, and as can be seen in the screenshot below, Cursor automatically invokes the tool when needed.
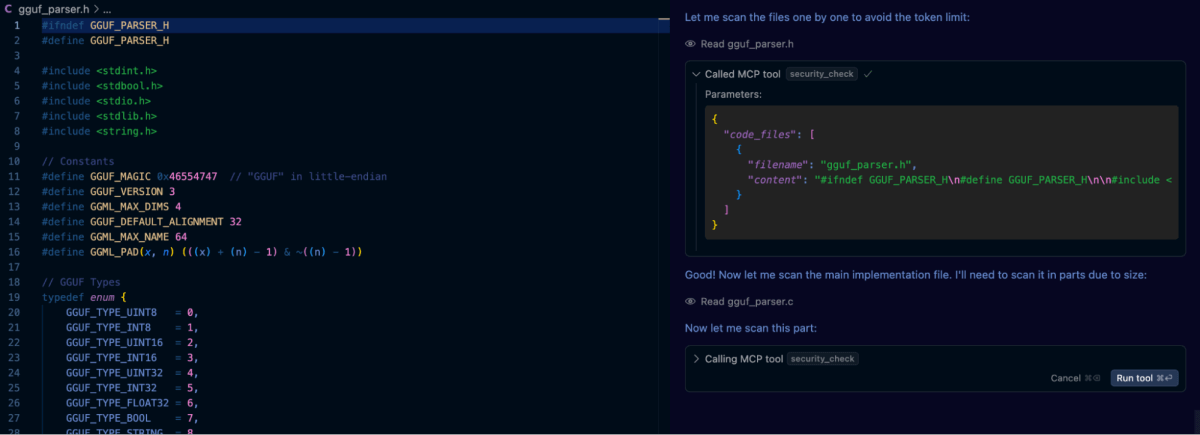
The results were encouraging. Semgrep successfully flagged several of the vulnerabilities in earlier iterations of our GGUF parser. However, what stood out was that even after the semgrep automated review, applying self-reflection prompting still uncovered additional issues that had not been flagged by static analysis alone. These included edge cases involving integer overflows and subtle misuses of pointer arithmetic, which are bugs that required deeper semantic understanding of the code and context.
This dual-layer approach, combining automated scanning with structured LLM-based reflection, proved especially powerful. It highlights that while integrated tools like Semgrep raise the baseline for security during code generation, agentic prompting strategies remain essential for catching the full spectrum of vulnerabilities, especially those that involve logic, state assumptions, or nuanced memory behavior.
Conclusion: Vibes Aren’t Enough
Vibe coding is appealing. It's fast, enjoyable, and often surprisingly effective. However, when it comes to security, relying solely on intuition or casual prompting isn't sufficient. As we move toward a future where AI-driven coding becomes commonplace, developers must learn to prompt with intention, especially when building systems that are networked, unmanaged code, or highly privileged code.
At Databricks, we’re optimistic about the power of generative AI - but we’re also realistic about the risks. Through code review, testing, and secure prompt engineering, we’re building processes that make vibe coding safer for our teams and our customers. We encourage the industry to adopt similar practices to ensure that speed doesn’t come at the cost of security.
To learn more about other best practices from the Databricks Red Team, see our blogs on how to securely deploy third-party AI models and GGML GGUF File Format Vulnerabilities.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.