Publicar en Múltiples Catálogos y Esquemas desde una Única Canalización de DLT
Simplifica la sintaxis, optimiza los costos y reduce la complejidad operativa
por Zoé Durand, Jonathan Chang y Matt Jones
- Soporte Multi-Schema y Catálogo: Publica en múltiples esquemas y catálogos desde una única canalización de DLT.
- Sintaxis Simplificada y Costos Reducidos: Elimina la palabra clave LIVE y reduce la sobrecarga de infraestructura.
- Mejor Observabilidad: Publica registros de eventos en Unity Catalog y administra datos en diferentes ubicaciones con SQL y Python.
DLT ofrece una plataforma robusta para crear pipelines de procesamiento de datos fiables, mantenibles y probables dentro de Databricks. Al aprovechar su marco declarativo y aprovisionar automáticamente cómputo serverless óptimo, DLT simplifica las complejidades de la transmisión, transformación y gestión de datos, ofreciendo escalabilidad y eficiencia para flujos de trabajo de datos modernos.
Estamos emocionados de anunciar una mejora muy esperada: la capacidad de publicar tablas en múltiples esquemas y catálogos dentro de un único pipeline DLT. Esta capacidad reduce la complejidad operativa, disminuye los costos y simplifica la gestión de datos al permitirle consolidar su arquitectura medallion (Bronze, Silver, Gold) en un único pipeline, manteniendo al mismo tiempo las mejores prácticas organizativas y de gobernanza.
Con esta mejora, puede:
- Simplificar la sintaxis del pipeline: No necesita la sintaxis
LIVEpara denotar dependencias entre tablas. Se admiten nombres de tabla completos o parciales, junto con los comandosUSE SCHEMAyUSE CATALOG, al igual que en SQL estándar. - Reducir la complejidad operativa: Procese y publique todas las tablas dentro de un pipeline DLT unificado, eliminando la necesidad de pipelines separados por esquema o catálogo.
- Disminuir costos: Minimice la sobrecarga de infraestructura consolidando múltiples cargas de trabajo en un único pipeline.
- Mejorar la observabilidad: Publique su registro de eventos como una tabla estándar en el metastore de Unity Catalog para una monitorización y gobernanza mejoradas.
“La capacidad de publicar en múltiples catálogos y esquemas desde un pipeline DLT, y de ya no requerir la palabra clave LIVE, nos ha ayudado a estandarizar las mejores prácticas de los pipelines, optimizar nuestros esfuerzos de desarrollo y facilitar la transición de equipos de cargas de trabajo no DLT a DLT como parte de nuestra adopción empresarial a gran escala de las herramientas.” —Ron DeFreitas, Principal Data Engineer, HealthVerity

Cómo empezar
Creación de un pipeline
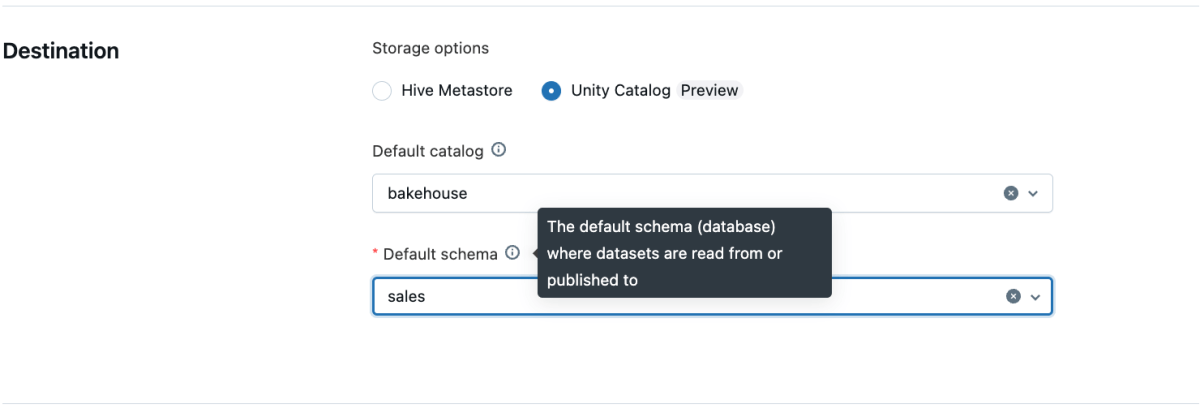
Todos los pipelines creados desde la UI ahora admiten por defecto múltiples catálogos y esquemas. Puede establecer un catálogo y esquema predeterminados a nivel de pipeline a través de la UI, la API o Databricks Asset Bundles (DAB).
Desde la UI:
- Cree un nuevo pipeline como de costumbre.
- Establezca el catálogo y el esquema predeterminados en la configuración del pipeline.
Desde la API:
Si está creando un pipeline mediante programación, puede habilitar esta capacidad especificando el campo schema en PipelineSettings. Esto reemplaza el campo target existente, asegurando que los conjuntos de datos se puedan publicar en múltiples catálogos y esquemas.
Para crear un pipeline con esta capacidad a través de la API, puede seguir esta muestra de código (Nota: la autenticación de Token de Acceso Personal debe estar habilitada para el espacio de trabajo):
Al establecer el campo schema, el pipeline admitirá automáticamente la publicación de tablas en múltiples catálogos y esquemas sin necesidad de la palabra clave LIVE.
Desde el DAB
- Asegúrese de que su Databricks CLI tenga la versión v0.230.0 o superior. Si no es así, actualice la CLI siguiendo la documentación.
- Configure el entorno de Databricks Asset Bundle (DAB) siguiendo la documentación. Siguiendo estos pasos, debería tener un directorio DAB generado desde Databricks CLI que contiene todos los archivos de configuración y código fuente.
- Encuentre el archivo YAML que define el pipeline DLT en:
<su carpeta dab>/<recurso>/<nombre del pipeline>_pipeline.yml - Establezca el campo
schemaen el YAML del pipeline y elimine el campotargetsi existe. - Ejecute “
databricks bundle validate“ para validar que la configuración del DAB es correcta. - Ejecute “
databricks bundle deploy -t <environment>“ para desplegar su primer pipeline DPM.
“¡La función funciona tal como esperábamos! Pude dividir los diferentes conjuntos de datos dentro de DLT en nuestros esquemas de stage, core y UDM (básicamente una configuración bronze, silver, gold) dentro de un único pipeline.” —Florian Duhme, Expert Data Software Developer, Arvato

Publicación de tablas en múltiples catálogos y esquemas
Una vez configurado su pipeline, puede definir tablas utilizando nombres completos o parciales tanto en SQL como en Python.
Ejemplo SQL
Ejemplo Python
Lectura de conjuntos de datos
Puede hacer referencia a conjuntos de datos utilizando nombres completos o parciales, siendo la palabra clave LIVE opcional para compatibilidad con versiones anteriores.
Ejemplo SQL
Ejemplo Python
Cambios en el comportamiento de la API
Con esta nueva capacidad, los métodos clave de la API se han actualizado para admitir múltiples catálogos y esquemas de manera más fluida:
dlt.read() y dlt.read_stream()
Anteriormente, estos métodos solo podían hacer referencia a conjuntos de datos definidos dentro del pipeline actual. Ahora, pueden hacer referencia a conjuntos de datos en múltiples catálogos y esquemas, rastreando automáticamente las dependencias según sea necesario. Esto facilita la creación de pipelines que integran datos de diferentes ubicaciones sin configuración manual adicional.
spark.read() y spark.readStream()
En el pasado, estos métodos requerían referencias explícitas a conjuntos de datos externos, lo que hacía que las consultas entre catálogos fueran más engorrosas. Con la nueva actualización, las dependencias ahora se rastrean automáticamente y ya no se requiere el esquema LIVE. Esto simplifica el proceso de lectura de datos de múltiples fuentes dentro de un solo pipeline.
Usando USE CATALOG y USE SCHEMA
La sintaxis de Databricks SQL ahora admite el establecimiento dinámico de catálogos y esquemas activos, lo que facilita la gestión de datos en múltiples ubicaciones.
Ejemplo de SQL
Ejemplo de Python
Gestión de registros de eventos en Unity Catalog
Esta función también permite a los propietarios de pipelines publicar registros de eventos en el metastore de Unity Catalog para mejorar la observabilidad. Para habilitar esto, especifique el campo event_log en el JSON de configuración del pipeline. Por ejemplo:
Con eso, ahora puede emitir GRANTS en la tabla de registros de eventos como cualquier tabla normal:
También puede crear una vista sobre la tabla de registros de eventos:
Además de todo lo anterior, también puede transmitir desde la tabla de registros de eventos:
¿Qué sigue?
En el futuro, estas mejoras se convertirán en el valor predeterminado para todos los pipelines creados recientemente, ya sea a través de la UI, API o Databricks Asset Bundles. Además, pronto estará disponible una herramienta de migración para ayudar a migrar los pipelines existentes al nuevo modelo de publicación.
Lea más en la documentación aquí.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.