Empujando la Frontera para Agentes de Datos con Genie
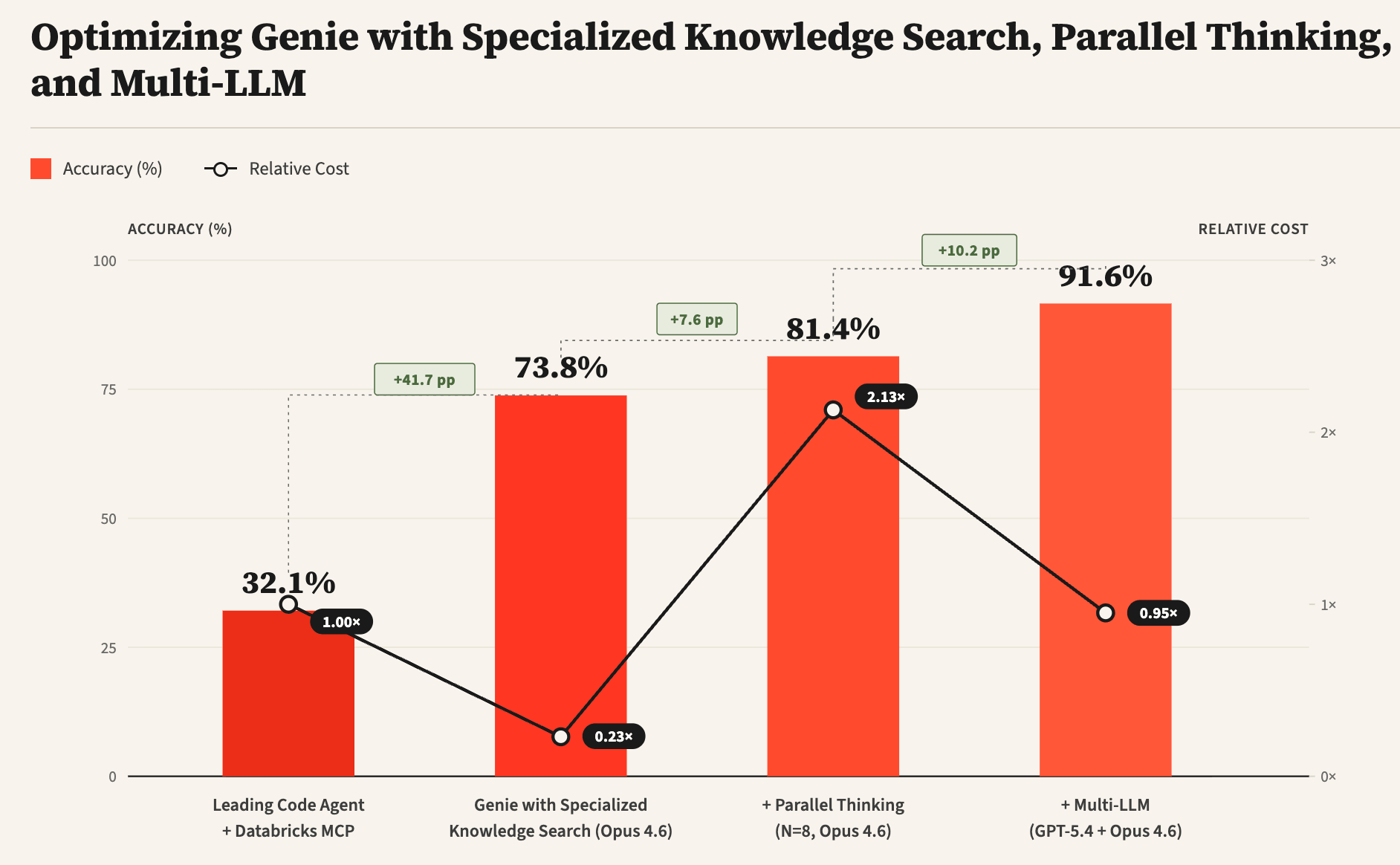
Genie es el agente de datos de última generación de Databricks, diseñado para responder preguntas complejas sobre datos empresariales que consisten en fuentes de datos tanto estructuradas (tablas, paneles, cuadernos, etc.) como no estructuradas (archivos del espacio de trabajo, Google Drive, Sharepoint, etc.). Este blog describe algunos de los desafíos únicos que enfrentan los agentes de datos y presenta técnicas para abordarlos, incluido el uso de búsqueda de conocimiento especializada, pensamiento paralelo y diseños Multi-LLM. A partir de nuestros experimentos en un benchmark interno de tareas de análisis de datos del mundo real, observamos que estas técnicas pueden mejorar significativamente la precisión general de Genie sobre un agente de codificación líder (del 32% a más del 90%), al tiempo que reducen significativamente los costos y la latencia.
Desafíos Clave para los Agentes de Datos
Los agentes de codificación han demostrado que un LLM potente puede hacer cosas increíbles de forma autónoma cuando está equipado con herramientas que le ayudan a comprender el contexto del código. Mientras que los agentes de codificación operan eficazmente en entornos estáticos y deterministas como el sistema de archivos de un disco, los agentes de datos introducen un paradigma completamente nuevo. Los agentes de datos trabajan dentro de un lakehouse de datos dinámico y en constante evolución que abarca una gran cantidad de contexto semántico en cientos de miles de tablas, cuadernos, paneles y documentos.
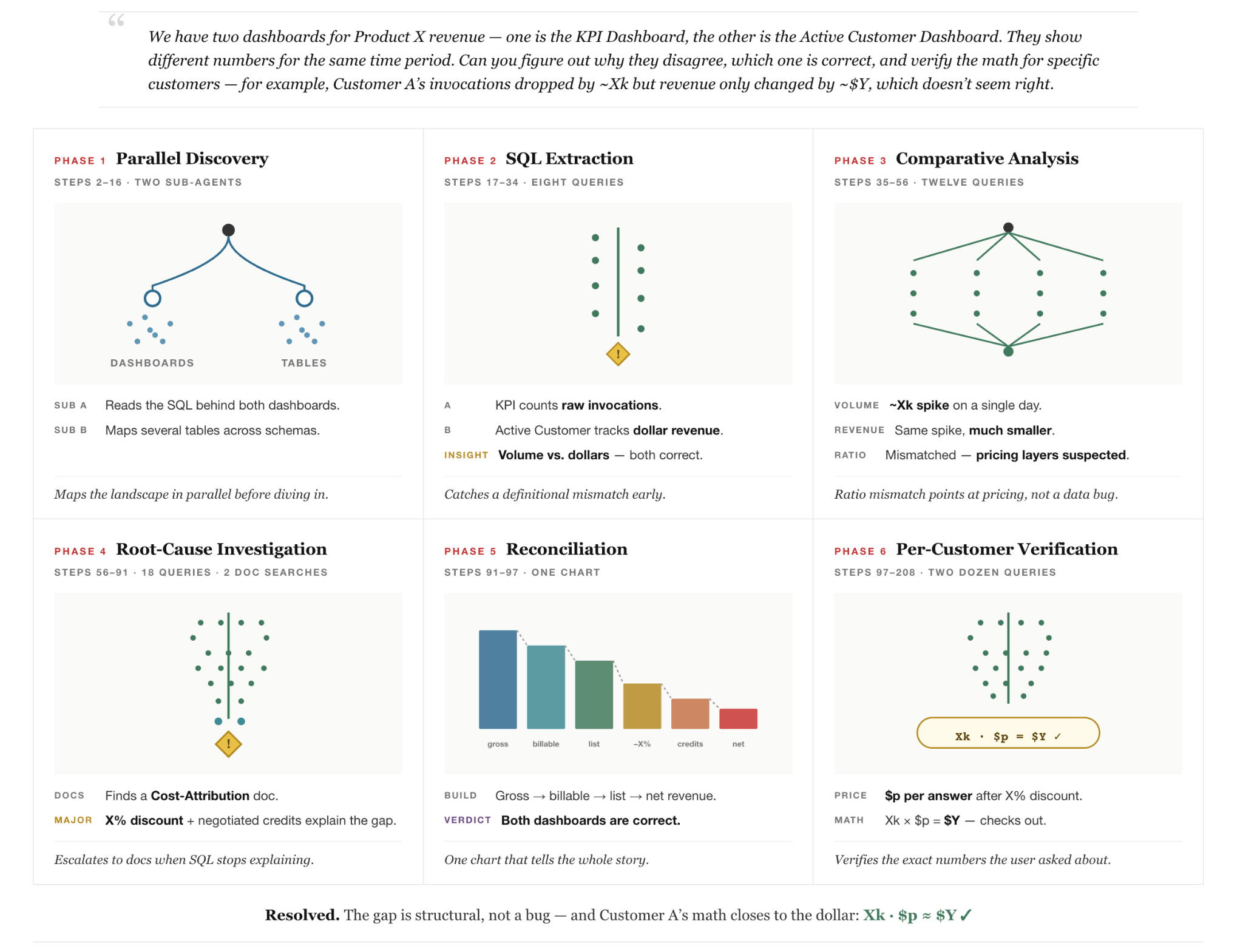
Por ejemplo, considere una consulta real (anonimizada) realizada por un usuario interno en la Figura 2: el usuario nota que dos paneles empresariales que informan sobre los ingresos del mismo producto muestran picos contradictorios en diferentes fechas y pide al agente que explique por qué. Esta pregunta razonable es engañosamente difícil porque ninguna fuente de datos única contiene la respuesta y resolver la pregunta requiere el descubrimiento entre sistemas a través de tablas, documentos internos y paneles, y el razonamiento sobre cómo se configuran los informes de varios días. Además, requiere que el agente profundice en los detalles de precios empresariales para encontrar las tarifas contractuales. Finalmente, requiere que el agente tenga la capacidad de corregirse automáticamente cuando los cálculos intermedios revelan suposiciones iniciales incorrectas. La figura muestra cómo el agente es capaz de resolver la tarea con éxito al proceder en diferentes fases: (1) descubrimiento de datos paralelo multiagente, (2) investigación de datos, (3) bucle de autocorrección y (4) verificación.
En comparación con los Agentes de Codificación, los Agentes de Datos tienen tres desafíos únicos clave:
- Escala del Descubrimiento de Datos: Encontrar las fuentes de datos adecuadas para responder a la consulta del usuario es uno de los mayores desafíos, ya que los clientes empresariales tienen millones de fuentes estructuradas y no estructuradas (como tablas, paneles y documentos), una escala que rompe los métodos de búsqueda convencionales.
- Determinación del Conocimiento Empresarial "Fuente de Verdad": Responder a preguntas empresariales requiere un conocimiento profundo y específico extraído de muchas fuentes (por ejemplo, metadatos de tablas, documentos de la empresa, mensajes internos) que a menudo están desactualizadas, son contradictorias o han sido reemplazadas, lo que obliga al agente a determinar la información más autorizada.
- Falta de Pruebas Verificables: A diferencia de los agentes de codificación que pueden usar pruebas deterministas y verificables para refinar iterativamente el código, los agentes de datos no tienen pruebas correspondientes porque la "especificación" es solo la consulta de alto nivel del usuario sin una noción de la respuesta correcta esperada. Además, las consultas no siempre pueden ser respondidas debido a la incompletitud de los datos, y es importante que los agentes de datos puedan identificar tales casos y comunicarlos a los usuarios.
Avances Técnicos Clave
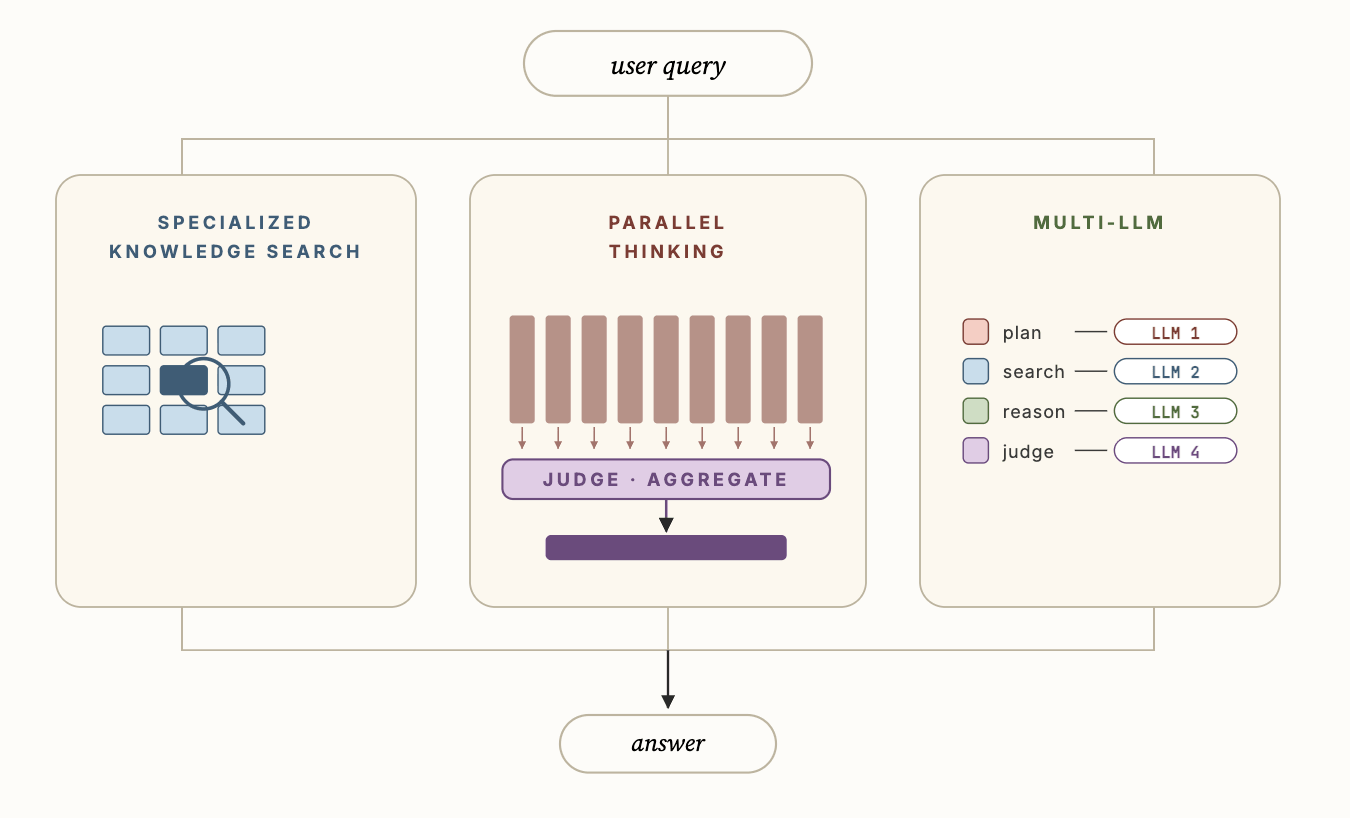
La Figura 3 muestra algunas de las innovaciones técnicas clave en Genie que le permiten tener un rendimiento significativamente mejor que los agentes de codificación genéricos, a saber: i) Búsqueda de Conocimiento Especializado, ii) Pensamiento Paralelo y iii) Multi-LLM. La búsqueda de conocimiento especializado utiliza datos contextuales semánticos para fundamentar los subagentes de descubrimiento de activos y mejorar significativamente la calidad de la búsqueda. El pensamiento paralelo permite al agente muestrear múltiples trayectorias diferentes y luego agregar los hallazgos de las trayectorias para calcular la respuesta final. Finalmente, Multi-LLM permite al agente utilizar diferentes LLMs para cada uno de los subagentes junto con sus prompts optimizados para mejorar aún más la precisión general y la latencia.
Búsqueda de Conocimiento Especializado
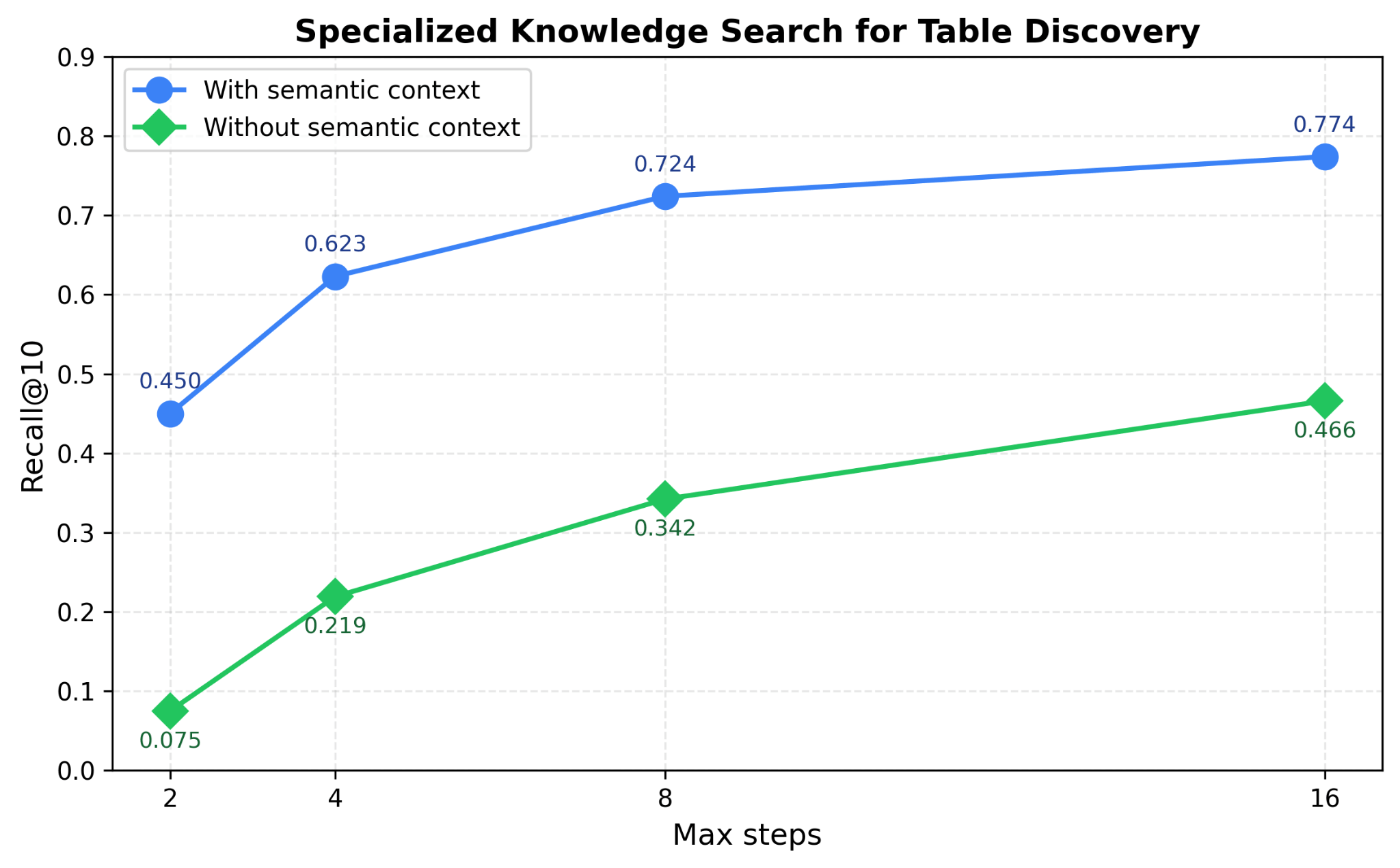
Genie utiliza los activos de datos existentes, como tablas del espacio de trabajo, cuadernos, paneles, documentos y archivos, para derivar un rico contexto empresarial semántico y luego utiliza este contexto para construir un índice de búsqueda. Utiliza múltiples índices de búsqueda en paralelo junto con señales de metadatos enriquecidas para descubrir eficientemente los activos más relevantes para la consulta de un usuario. La Figura 4 demuestra cómo el aprovechamiento de la búsqueda de conocimiento especializado ayuda a Genie a mejorar el rendimiento de la búsqueda de tablas hasta en un 40% en nuestros benchmarks de descubrimiento de tablas.
Pensamiento Paralelo
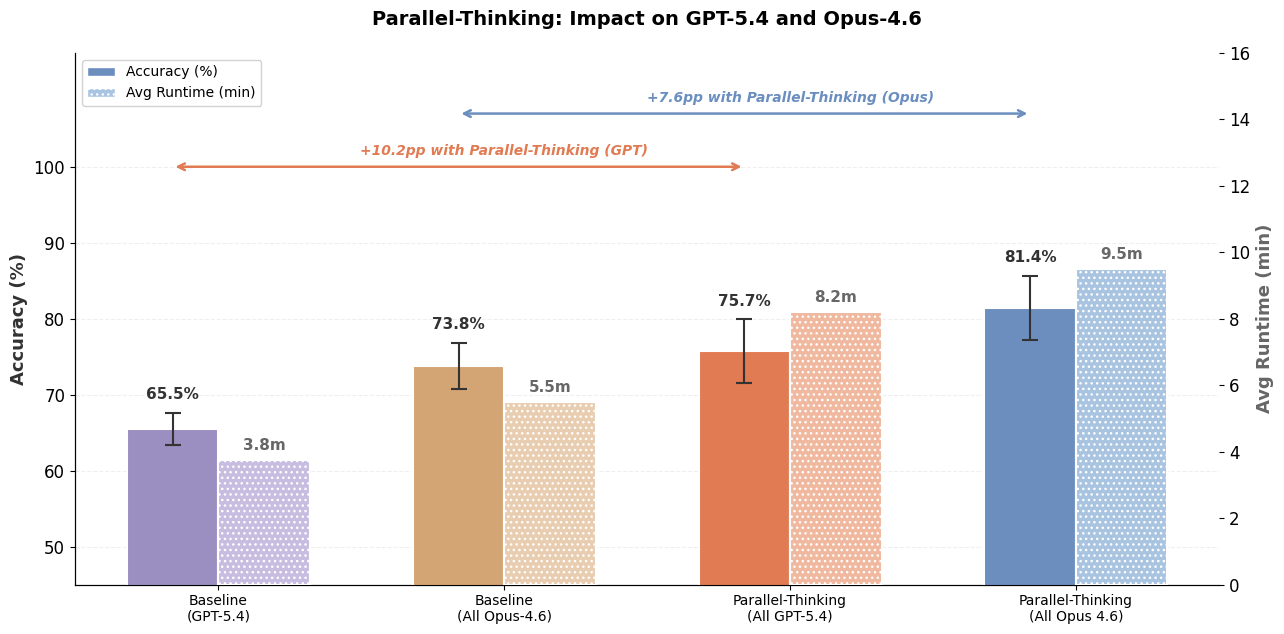
A diferencia de las tareas de ingeniería de software, donde los agentes de codificación pueden escribir primero pruebas para verificar la funcionalidad deseada y luego iterar en la generación de código hasta que las pruebas pasen, las consultas de datos abiertas no tienen pruebas unitarias correspondientes. En ausencia de pruebas, se vuelve difícil para los agentes de datos saber si la respuesta generada es correcta o necesita más refinamiento. Para abordar este desafío, aprovechamos el pensamiento paralelo muestreando múltiples trayectorias y agregando información relevante a través de las trayectorias para calcular la respuesta final. La Figura 5 muestra cómo el pensamiento paralelo puede mejorar significativamente la precisión de la respuesta, aunque con una latencia y costos de tokens adicionales. Además, como se muestra en la Figura 1, la combinación de Multi-LLM y optimizaciones adicionales puede reducir aún más significativamente los costos y la latencia.
Multi-LLM
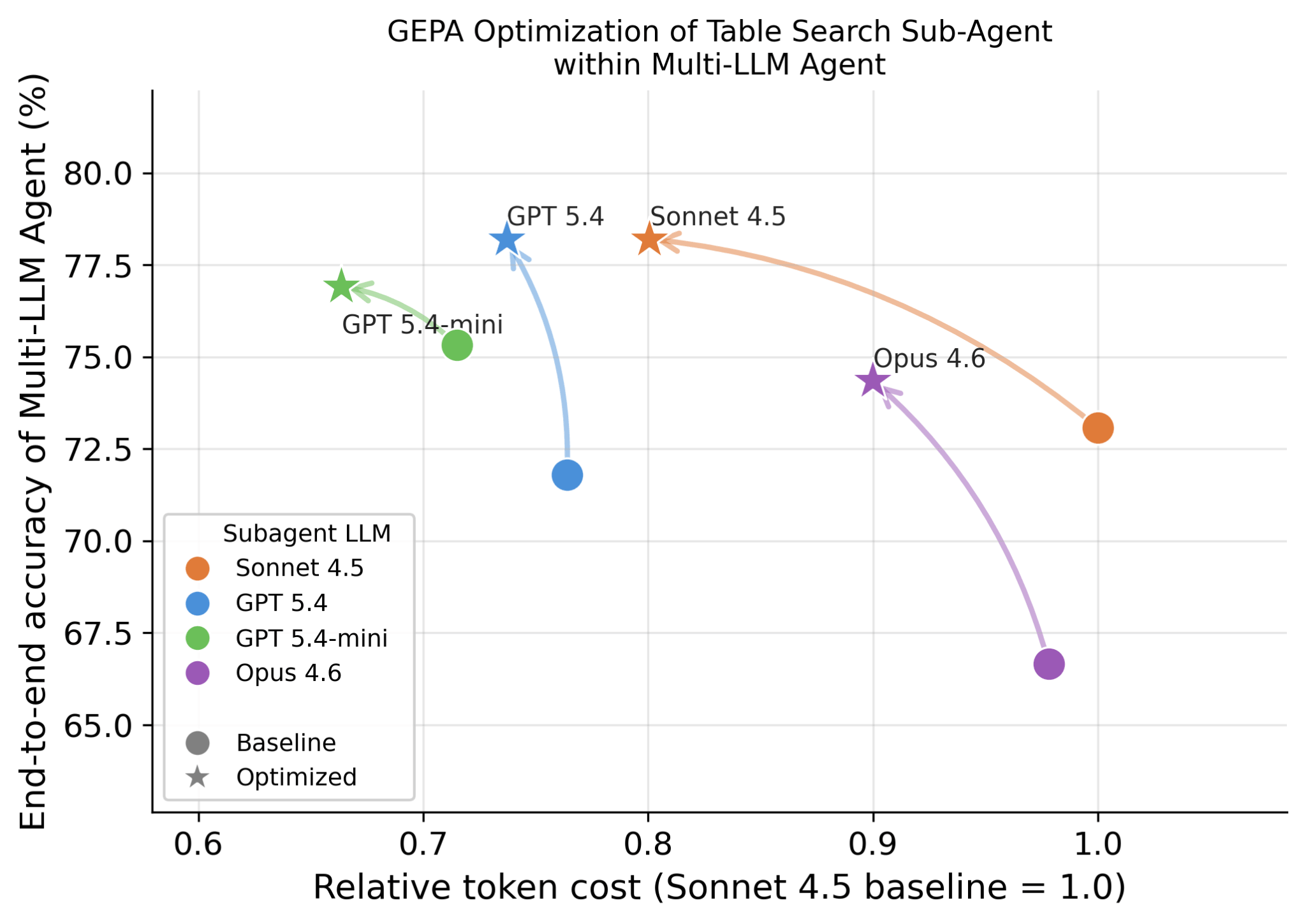
Uno de los avances técnicos clave en Genie es la capacidad de aprovechar diferentes LLMs para diferentes subagentes, ya que observamos que diferentes LLMs son buenos en capacidades complementarias. Por ejemplo, puede usar un LLM diferente para la etapa de planificación, un LLM diferente para varios subagentes de búsqueda, uno diferente para la generación de código y los jueces. Con la plataforma Databricks, es fácil probar cualquiera de los modelos de vanguardia (incluidos Opus, GPT y Gemini), modelos de código abierto, así como modelos entrenados personalizados. Además de la precisión, también observamos que diferentes LLMs resultan en características de latencia y costo muy diferentes. La Figura 6 muestra cómo se desempeñan diferentes LLMs en tareas de búsqueda de tablas y cómo la precisión y el costo correspondientes se pueden optimizar aún más utilizando métodos como GEPA.
Conclusión
Si bien la codificación y el análisis de datos comparten muchas similitudes conceptuales, la naturaleza dinámica de los sistemas de datos empresariales crea desafíos únicos. Los agentes de datos necesitan descubrir eficientemente los activos correctos en un contexto empresarial amplio, determinar la "verdad" en un entorno ambiguo y escribir código y consultas eficientes para responder correctamente a las preguntas de los usuarios. Desarrollamos varios enfoques novedosos para resolver estos problemas, como la búsqueda especializada de conocimiento para aprovechar información semántica rica y múltiples señales de metadatos, Multi-LLM para aprovechar diferentes LLM con indicaciones optimizadas usando GEPA, y el pensamiento paralelo para mejorar aún más la precisión general. La adición de estos enfoques a Genie lo ayuda a funcionar significativamente mejor que los agentes de codificación líderes en las tareas de referencia. Todavía quedan muchas preguntas abiertas y desafiantes por explorar, y nunca ha habido un momento más emocionante para explorar la investigación en esta área de la construcción de agentes de datos de última generación para empresas.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.