Inferencia confiable de LLM a escala
Lecciones de la construcción de infraestructura de inferencia de LLM confiable
por Ying Chen, Wendy Hu, Ankit Mathur, Mike Eastham, Pei-Lun Liao, Wai Wu y Arjun DCunha
- El servicio de LLM multitenant requiere razonar sobre la capacidad en todas las cargas de trabajo. Las "unidades de modelo" proporcionan una abstracción similar a una VM que permite asignar, enrutar y escalar recursos de GPU por cliente.
- El balanceo de carga y el escalado automático conscientes de los costos, basados en unidades de modelo, ahorraron más del 80% en costos de GPU en comparación con la provisión estática, al tiempo que se mantenían los objetivos de latencia.
- Los mecanismos de confiabilidad en tiempo de ejecución, como las comprobaciones de estado de "caja negra", detectan y se recuperan automáticamente de fallos silenciosos, mientras que la optimización de los cuellos de botella multimodales desbloqueó ganancias de rendimiento de 3 veces.
En Databricks, hemos creado una plataforma de inferencia única que da servicio a todos los modelos de vanguardia, desde modelos de código abierto como Kimi y Qwen hasta modelos propietarios como OpenAI, Gemini y Claude. Potenciamos la inferencia para algunas de las aplicaciones agentivas más grandes del mundo, incluyendo Superhuman, Yipit Data, Fox Sports y otras. Hoy, damos servicio a más de 120T tokens por mes.
Lo que hace difícil el servicio de LLM a escala es la fiabilidad. Dado que los agentes se están convirtiendo en la interfaz de cómo trabajamos y vivimos, la demanda de inferencia está creciendo exponencialmente. Vemos curvas de demanda extremadamente variables que alcanzan su punto máximo durante las horas de trabajo.
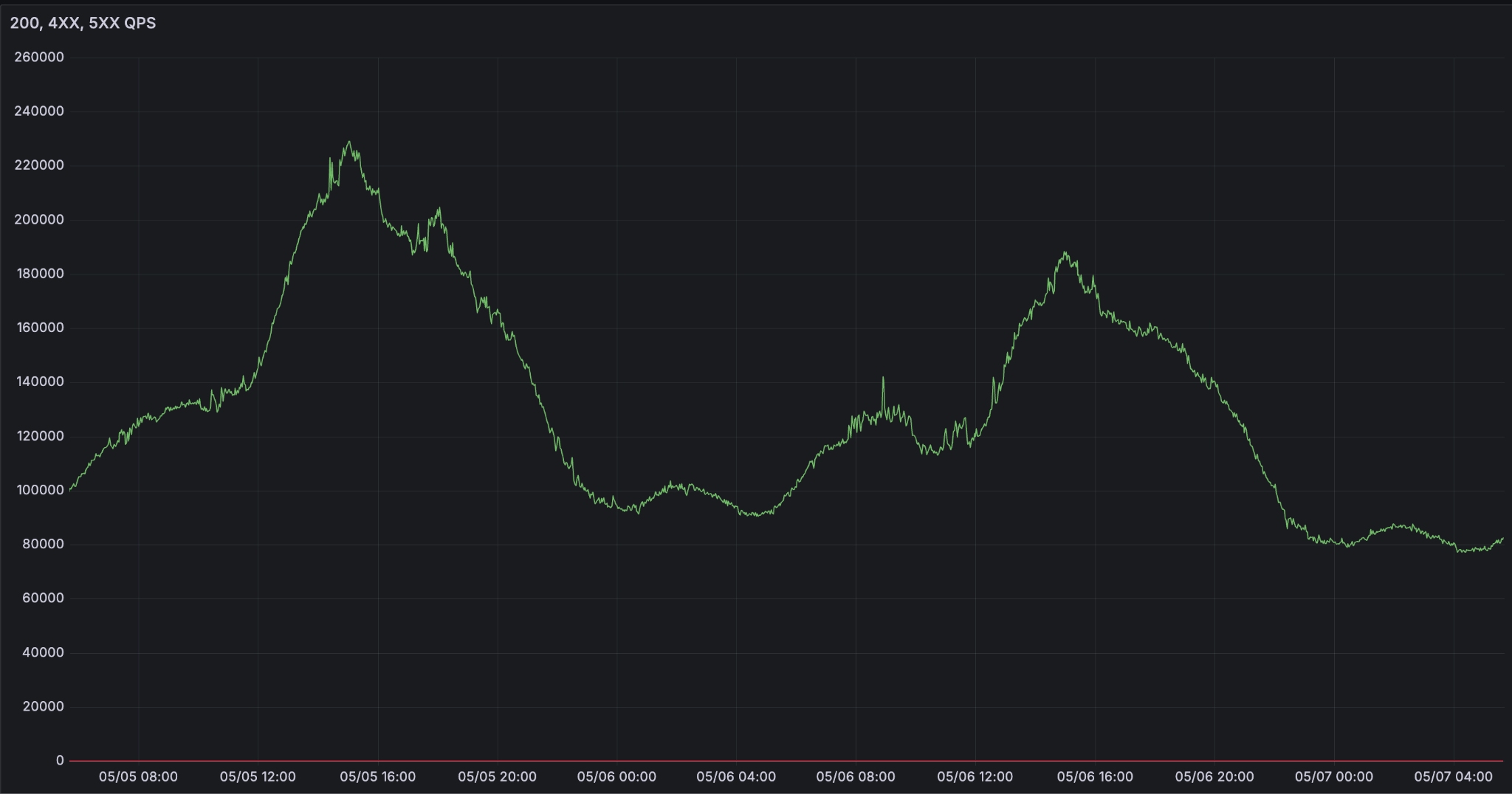
Desafíos de ejecutar inferencia de LLM a escala
¿Qué significa ser una plataforma de inferencia fiable? El contrato parece sencillo. La disponibilidad es si la solicitud puede ser procesada. Pero, en la práctica, los diferentes casos de uso tienen requisitos de latencia significativamente diferentes, y esto influye en la disponibilidad. Los agentes más avanzados no pueden permitirse que la latencia p95 hasta el primer token (TTFT) y los tokens de salida por segundo (OPTS) se degraden.
En un sistema multi-inquilino para el servicio de LLM, lograr tanto la fiabilidad como la latencia es un desafío.
Fiabilidad
El rendimiento de vanguardia requiere las últimas GPUs con interconexión de alto ancho de banda para la transferencia de caché KV. Estas configuraciones de cómputo son fundamentalmente menos fiables que los sistemas de CPU clásicos, y son caras. Dado que se requiere comunicación de todos a todos, la caída de un solo nodo requiere la reconfiguración de varios otros nodos en configuraciones de pre-llenado/decodificación desvinculadas. La red de mayor ancho de banda requiere conectividad de una sola espina en un solo rack físico (por ejemplo, sistemas NVL72). Esto significa que los fallos en sistemas específicos dentro de un solo rack de centro de datos pueden crear una interrupción de amplio radio de impacto. Los trucos estándar en sistemas distribuidos como multi-AZ o el aprovechamiento de tipos de instancia de respaldo significan mantener GPUs de respaldo caras inactivas, una opción prohibitiva en cuanto a costes. El sobreaprovisionamiento es otro truco clásico, pero dado que la oferta de cómputo está tan limitada, es extremadamente caro e impracticable. Por lo tanto, los sistemas deben permanecer operativos bajo una fuerte presión.
La velocidad de lanzamiento también debe mantenerse alta bajo estas restricciones: nuestra demanda de inferencia ha crecido varios órdenes de magnitud año tras año, y alimentar ese crecimiento mientras se lanzan funciones innovadoras fue un desafío. Funciones como imágenes, videos y clasificación de seguridad requieren sistemas de preprocesamiento diferentes que deben escalar de forma independiente.
Finalmente, lograr el mejor rendimiento de su clase y soportar nuevas arquitecturas de modelos requiere optimizaciones que abarcan desde kernels personalizados hasta motores de inferencia propietarios. A medida que las arquitecturas cambian sutilmente, a menudo se introduce nuevo software de bajo nivel que puede fallar de maneras opacas a escala, apareciendo en escenarios de depuración difíciles que van desde bloqueos de servidores hasta fallos de GPU.
Latencia
Mantener la latencia bajo control con patrones de carga diversos es un desafío. Esto se debe a que el coste de servir una solicitud es muy variable y difícil de estimar a priori. Incluso los servidores sanos bajo mayor carga procesan todas las solicitudes más lentamente, exponiendo una compensación entre el rendimiento (y por lo tanto la eficiencia de costes) y la latencia más rápida que los productos necesitan manejar. Esto también puede manifestarse como un problema de fiabilidad, ya que los servidores pueden entrar inesperadamente en estados no saludables muy rápidamente basándose en la mezcla de solicitudes que se les asignan.
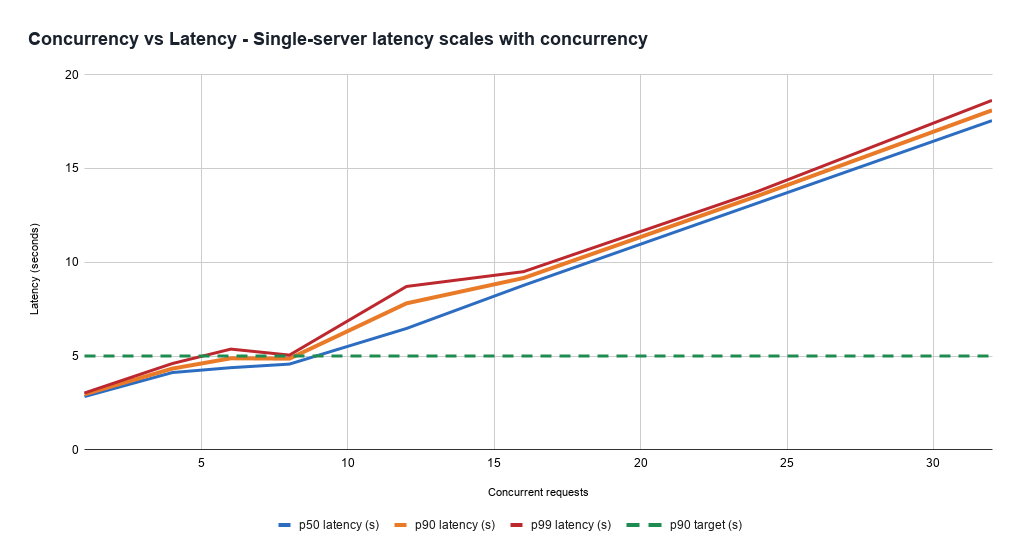
Además, la latencia está dominada por la generación de tokens de salida, pero la estimación inicial del coste es difícil, ya que es complicado predecir cuánto tiempo hablará el modelo. Por lo tanto, el servicio de baja latencia requiere una gestión compleja de la capacidad, balanceo de carga y sistemas de priorización de solicitudes.
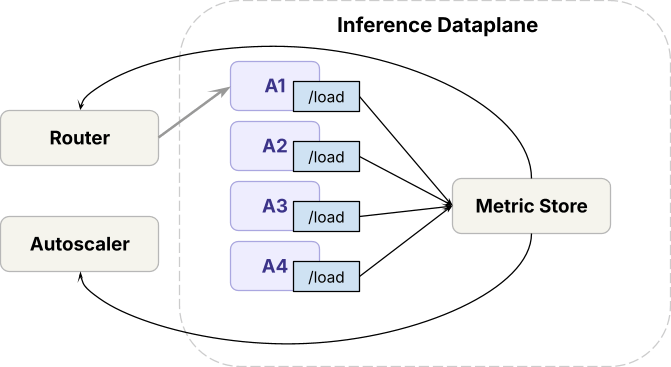
Arquitectura general
Antes de profundizar en los detalles de cómo abordar estos problemas, repasemos una visión general de alto nivel de nuestra infraestructura de servicio.
En el plano de datos,
- El runtime de inferencia (motores de código abierto y propietarios internos) se implementa en GPUs de vanguardia
- Para manejar el tráfico entre despliegues de modelos, el plano de datos ejecuta un router, al que llamamos Axon, que equilibra la carga entre réplicas del mismo modelo, y un autoscaler que ajusta los recuentos de réplicas.
En el plano de control,
- Las solicitudes pasan por limitación de tasa antes de llegar al plano de datos.
- Basado en las métricas de las solicitudes, el algoritmo de gestión de capacidad determina cuánta capacidad de GPU obtiene cada carga de trabajo, lo que el autoscaler luego aplica.
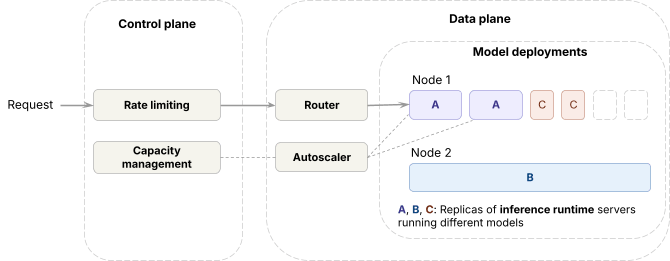
Controlando la capacidad
Necesitamos poder razonar aproximadamente sobre la capacidad: cuánta tenemos, cuánta hemos vendido y cuánta están utilizando los clientes. Para hacer esto, introdujimos una abstracción llamada "unidades de modelo". Si proyectamos que una réplica puede procesar un número fijo de unidades de modelo por minuto (por ejemplo, 100), podemos hacer las siguientes suposiciones:
- Las solicitudes con entradas o salidas largas consumen más unidades de modelo, ya que se pueden completar menos en la misma ventana de tiempo.
- El pre-llenado y la decodificación tienen diferentes características de rendimiento, por lo que las solicitudes con salida larga cuestan más que las que tienen entrada larga.
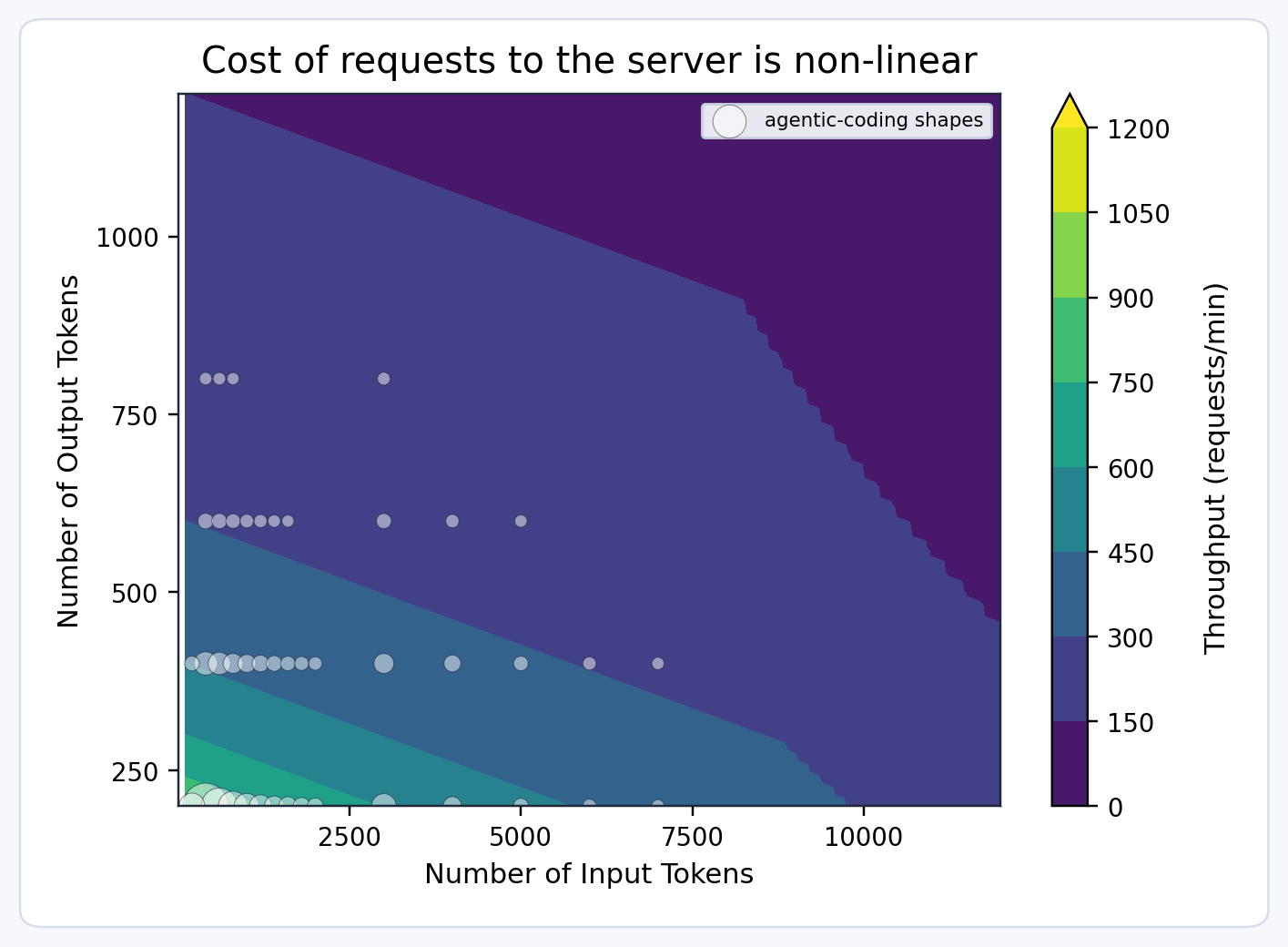
Por lo tanto, modelamos el coste de la solicitud utilizando una función multidimensional como:
Los coeficientes α, β, γ se determinan mediante benchmarking automatizado para cada modelo en cada tipo de hardware. Las unidades de modelo se pueden ajustar aún más para optimizaciones como el caché de prefijo, y deben tener en cuenta características como la multimodalidad.
Tales estimaciones son estructuralmente imperfectas, pero sirven como una forma para que rompamos un sistema multi-inquilino en algo más manejable que se asemeja a las VMs en la nube. Las VMs tienen la propiedad deseable de ofrecer un rendimiento predecible que puede ser asignado a clientes específicos. Para cargas de trabajo agentivas de producción, es importante ofrecer garantías sobre baja latencia y capacidad, y sin tales sistemas de asignación, lo mejor que podemos hacer es ofrecer capacidad de "mejor esfuerzo" que podría ser recuperada si demasiados clientes usan el sistema.
Balanceo de carga y escalado automático basado en costes
Dado que las solicitudes tienen un impacto muy variable en los servidores, es importante tomar decisiones de enrutamiento casi óptimas. En general, el balanceo de carga tiende a basarse en enfoques estadísticos como P2C (potencia de dos opciones), que estiman la carga basándose en el tamaño de la cola y utilizan el muestreo para reducir los sobrecostes de memoria y latencia de la comprensión de todos los objetivos posibles. Sin embargo, las latencias de LLM tienden a ser altas, el número de servidores es menor que en los sistemas de CPU escalados, y el coste de un enrutamiento erróneo es severo. Por lo tanto, el servicio de LLM requiere un enfoque diferente.
Hoy en día, utilizamos Dicer, el auto-sharder de Databricks, para enrutar dinámicamente las cargas de trabajo entre servidores. Sin un enrutamiento consciente de la carga, las solicitudes de contexto largo hacen que los servidores individuales se conviertan en puntos calientes mientras que otros permanecen infrautilizados. Hemos integrado las unidades de modelo con Dicer para que las decisiones de enrutamiento se basen en la carga del servidor en unidades de modelo en lugar de en heurísticas tradicionales basadas en solicitudes. Dicer también proporciona sesiones con estado, haciendo que el enrutamiento de solicitudes sea persistente. Las solicitudes de una carga de trabajo van a solo un subconjunto de servidores, lo que mejora las tasas de acierto de caché (crucial para cargas de trabajo sensibles a la latencia como los agentes de codificación) y limita el radio de impacto.
También podemos ajustar las métricas de carga e incluso utilizar sistemas de enrutamiento más óptimos en el futuro basados en métricas de costos de mayor fidelidad, a medida que aprendemos más.
Un problema similar existe en el escalado automático. Los recuentos de solicitudes pendientes por sí solos no reflejan la carga real. Un pico en las solicitudes de contexto largo se ve idéntico a un pico en las cortas, y las métricas de CPU y memoria están igualmente descorrelacionadas con la utilización real de la GPU.
Usando unidades de modelo, nuestro escalador automático puede decidir si escalar hacia arriba o hacia abajo basándose en la relación de utilización de unidades de modelo. Cuando el motor de inferencia se ejecuta cerca de un cierto porcentaje de sus unidades de modelo máximas (determinado por el tipo de hardware y la forma de la carga de trabajo), se acerca al rendimiento máximo, lo que desencadena el escalado hacia arriba. Lo contrario desencadena el escalado hacia abajo. En lugar de ajustar manualmente las reglas de escalado automático para cada modelo, este enfoque permite una infraestructura de escalado agnóstica al modelo.
Construir el escalado automático sobre patrones de inferencia de LLM nos salvó de escalar siempre al máximo de réplicas. Para modelos con tráfico ráfaga, el escalado automático mantuvo los recuentos de réplicas cerca de la demanda real, lo que se tradujo en más del 80% de ahorro de GPU en comparación con la provisión estática al máximo.
Fiabilidad en tiempo de ejecución
El enrutamiento y escalado inteligentes proporcionaron una base sólida, pero no evitan fallos a nivel de motor. Sin importar qué motor de inferencia despleguemos (nuestro motor interno u opciones populares de código abierto), surgen casos extremos y contención de recursos a escala de producción. Necesitamos mecanismos para detectar y recuperarse de fallos automáticamente.
Detección y recuperación de fallos silenciosos
Un modo de fallo que encontramos son los bloqueos silenciosos. Las solicitudes que involucran casos extremos (salida estructurada, entradas multimodales) pueden desencadenar errores no manejados en la arquitectura multiproceso de los motores de inferencia, haciendo que los servidores dejen de responder sin mostrar errores.
Detectamos esto con comprobaciones de estado periódicas de caja negra: solicitudes mínimas de extremo a extremo enviadas cuando no se han completado solicitudes reales recientemente. Si una comprobación de estado falla, la sonda de liveness de Kubernetes reinicia el servidor. Esto funciona en todos los motores independientemente de la implementación interna.
Sin embargo, bajo carga alta, las propias comprobaciones de estado pueden agotar el tiempo de espera, lo que hace que la sonda de liveness elimine servidores que están realmente en buen estado. Esto arriesga fallos en cascada. Para resolver esto, asignamos a las solicitudes de comprobación de estado la máxima prioridad de programación, asegurando que se completen incluso bajo carga pesada. Con comprobaciones de estado priorizadas, el ciclo completo de detección de un bloqueo, eliminación del servidor no saludable y recuperación toma menos de 5 minutos. Los fallos falsos de la sonda de liveness se redujeron de varios por semana a cero.
Manejo de carga inesperada de solicitudes multimodales
Cuando llegaron grandes lotes de solicitudes multimodales, vimos picos en las tasas de error y tiempos de espera de una fuente completamente diferente.
Las investigaciones revelaron que las solicitudes ni siquiera llegaban a los procesos principales del motor de inferencia. Servir solicitudes de imágenes es más costoso en recursos que las solicitudes de solo texto, no solo por el codificador de visión adicional que se ejecuta en las GPUs, sino también por el procesamiento de imágenes intensivo en CPU. Para ciertos modelos, el procesamiento de imágenes era extremadamente lento, bloqueando completamente el bucle de eventos.
Mover las operaciones de bloqueo a hilos y procesos separados no resolvió el problema; las solicitudes todavía se acumulaban bajo alta carga de imágenes. Así que analizamos los procesos de Python e hicimos varios descubrimientos:
- Entre todas las operaciones de CPU para imágenes, el procesamiento de imágenes (redimensionamiento y normalización) es 10 veces más lento que otras operaciones como la decodificación base64.
- Algunos modelos de Hugging Face utilizan por defecto el procesador de imágenes basado en PIL, mientras que otros utilizan el procesador basado en Torchvision más rápido.
- En entornos contenerizados, OMP_NUM_THREADS (que controla el número de hilos OpenMP utilizados por Torch para operaciones de CPU) se establece por defecto en el número de vCPUs en la máquina host. En configuraciones multitenant, este es un valor predeterminado deficiente: un host puede tener 192 vCPUs, pero un contenedor solo tiene acceso a 12. El resultado son muchos más hilos en ejecución que núcleos disponibles. Esto lleva el uso de la CPU más allá del límite del contenedor y desencadena la limitación.
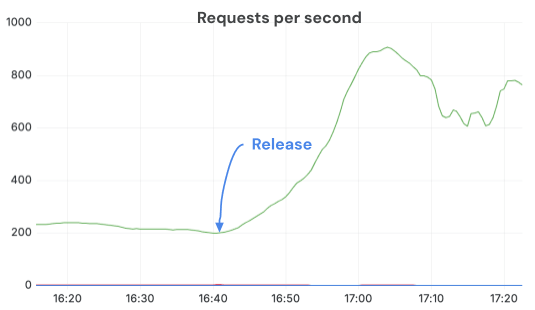
Al cambiar a procesadores de imágenes basados en Torchvision y configurar correctamente OMP_NUM_THREADS, mantuvimos un QPS mucho más alto y aprovechamos al máximo las GPUs. Después de que se implementó la corrección, las solicitudes completadas por segundo aumentaron más de 3 veces con las mismas réplicas y carga. La limitación de CPU desapareció y los servidores funcionaron en un estado mucho más saludable.
Conclusión
Servir LLMs de manera fiable a escala requiere trabajo en todas las capas de la pila de inferencia. Hemos cubierto la infraestructura de escalado automático y balanceo de carga diseñada en torno a las cargas de trabajo de LLM, y mecanismos de tiempo de ejecución que se mantienen estables independientemente del motor o la carga de trabajo. Hay mucho más en la historia: inicio rápido de contenedores, implementaciones seguras en flotas de GPU, gestión de capacidad de GPU entre nubes y regiones. Si estos son el tipo de problemas en los que quieres trabajar, ¡estamos contratando!
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.