Publicamos el código abierto de Dicer: el auto-sharder de Databricks
Creación de servicios fragmentados de alta disponibilidad a escala para un alto rendimiento y un bajo costo
por Atul Adya, Colin Meek, Jonathan Ellithorpe, Vivek Jain y Yongxin Xu
- Publicación de Dicer como código abierto: Publicamos oficialmente Dicer como código abierto, el sistema fundamental de particionamiento automático utilizado en Databricks para crear servicios particionados rápidos, escalables y de alta disponibilidad.
- El qué y el porqué de Dicer: Describimos los problemas de las arquitecturas de servicios típicas de hoy en día, por qué se necesitan los particionadores automáticos, cómo Dicer resuelve estos problemas y analizamos sus abstracciones principales y casos de uso.
- Casos de éxito: Actualmente, el sistema impulsa componentes de misión crítica como Unity Catalog y nuestro motor de orquestación de consultas SQL, donde ha eliminado con éxito las caídas de disponibilidad y ha mantenido tasas de acierto de caché superiores al 90 % durante los reinicios de pods.
1. Anuncio
Hoy, nos complace anunciar la publicación como código abierto de uno de nuestros componentes de infraestructura más críticos, Dicer: el particionador automático de Databricks, un sistema fundamental diseñado para crear servicios particionados de baja latencia, escalables y de alta confiabilidad. Está detrás de escena de cada producto principal de Databricks, lo que nos permite ofrecer una experiencia de usuario consistentemente rápida, mientras se mejora la eficiencia de la flota y se reducen los costos de la nube. Dicer logra esto gestionando dinámicamente las asignaciones de particionamiento para mantener los servicios con capacidad de respuesta y resilientes, incluso frente a reinicios, fallas y cargas de trabajo cambiantes. Como se detalla en esta publicación de blog, Dicer se utiliza para una variedad de casos de uso, que incluyen el servicio de alto rendimiento, el particionamiento del trabajo, las canalizaciones de procesamiento por lotes, la agregación de datos, la arquitectura multiusuario, la elección de líder flexible, la utilización eficiente de la GPU para cargas de trabajo de IA y más.
Al poner Dicer a disposición de la comunidad en general, esperamos colaborar con la industria y el mundo académico para avanzar en el estado de la técnica en la creación de sistemas distribuidos robustos, eficientes y de alto rendimiento. En el resto de esta publicación, analizamos la motivación y la filosofía de diseño detrás de Dicer, compartimos casos de éxito de su uso en Databricks y proporcionamos una guía sobre cómo instalar y experimentar con el sistema por su cuenta.
2. Motivación: más allá de las arquitecturas sin estado y con particionamiento estático
Databricks ofrece un conjunto de productos en rápida expansión para el procesamiento de datos, el análisis y la IA. Para respaldar esto a gran escala, operamos cientos de servicios que deben manejar estados masivos y, a la vez, mantener la capacidad de respuesta. Históricamente, los ingenieros de Databricks se basaban en dos arquitecturas comunes, pero ambas presentaban problemas significativos a medida que los servicios crecían:
2.1. Los costos ocultos de las arquitecturas sin estado
La mayoría de los servicios en Databricks comenzaron con un modelo sin estado. En un modelo típico sin estado, la aplicación no retiene el estado en memoria entre solicitudes y debe volver a leer los datos de la base de datos en cada solicitud. Esta arquitectura es inherentemente costosa, ya que cada solicitud implica un acceso a la base de datos, lo que aumenta tanto los costos operativos como la latencia [1].
Para mitigar estos costos, los desarrolladores solían introducir una caché remota (como Redis o Memcached) para descargar trabajo de la base de datos. Si bien esto mejoraba el rendimiento y la latencia, no lograba resolver varias ineficiencias fundamentales:
- Latencia de red: Cada solicitud aún paga el "impuesto" de los saltos de red a la capa de caché.
- Sobrecarga de la CPU: Se desperdician ciclos significativos en la (des)serialización a medida que los datos se mueven entre la memoria caché y la aplicación [2].
- El problema de la "sobrelectura": los servicios sin estado suelen obtener objetos enteros o blobs grandes de la memoria caché solo para utilizar una pequeña fracción de los datos. Estas sobrelecturas desperdician ancho de banda y memoria, ya que la aplicación descarta la mayoría de los datos que acaba de recuperar [2].
El paso a un modelo fragmentado y el almacenamiento en caché del estado en la memoria eliminaron estas capas de sobrecarga al coubicar el estado directamente con la lógica que opera en él. Sin embargo, la fragmentación estática introdujo nuevos problemas.
2.2. La fragilidad del sharding estático
Antes de Dicer, los servicios fragmentados en Databricks se basaban en técnicas de fragmentación estática (por ejemplo, hashing consistente). Aunque este enfoque era simple y permitía que nuestros servicios almacenaran en caché el estado en la memoria de manera eficiente, introdujo tres problemas críticos en la producción:
- Falta de disponibilidad durante los reinicios y el autoescalado: La falta de coordinación con un administrador de clústeres provocaba tiempo de inactividad o degradación del rendimiento durante las operaciones de mantenimiento, como las actualizaciones continuas, o al escalar dinámicamente un servicio. Los esquemas de sharding estáticos no se ajustaban de forma proactiva a los cambios en la composición del backend y solo reaccionaban después de que ya se había eliminado un nodo.
- Split-brain prolongado y tiempo de inactividad durante las fallas: Sin una coordinación central, los clientes podían desarrollar vistas inconsistentes del conjunto de pods de backend cuando los pods se bloqueaban o dejaban de responder de forma intermitente. Esto resultaba en escenarios de "split-brain" (donde dos pods creían que poseían la misma clave) o incluso en la pérdida total del tráfico de un cliente (donde ningún pod creía poseer la clave).
- El problema de la clave activa: por definición, el particionamiento estático no puede reequilibrar dinámicamente las asignaciones de claves ni ajustar la replicación en respuesta a los cambios de carga. En consecuencia, una única "clave activa" sobrecargaría un pod específico, lo que crearía un cuello de botella que podría desencadenar fallas en cascada en toda la flota.
A medida que nuestros servicios crecían cada vez más para satisfacer la demanda, el sharding estático finalmente pareció una pésima idea. Esto generó una creencia común entre nuestros ingenieros de que las arquitecturas sin estado eran la mejor manera de crear sistemas robustos, incluso si eso significaba asumir los costos de rendimiento y recursos. Esto fue aproximadamente en la época en que se presentó Dicer.
2.3. Redefiniendo la narrativa del servicio fragmentado
Los peligros de la fragmentación estática en producción, en contraste con los costos de no tener estado, dejaron a varios de nuestros servicios más críticos en una posición difícil. Estos servicios se basaban en la fragmentación estática para ofrecer una experiencia de usuario ágil a nuestros clientes. Convertirlos a un modelo sin estado habría introducido una penalización de rendimiento significativa, sin mencionar los costos adicionales en la nube para nosotros.
Creamos Dicer para cambiar esto. Dicer aborda las deficiencias fundamentales de la fragmentación estática mediante la introducción de un plano de control inteligente que actualiza de forma continua y asíncrona las asignaciones de fragmentos de un servicio. Reacciona a una amplia gama de señales, que incluyen el estado de la aplicación, la carga, los avisos de terminación y otras entradas del entorno. Como resultado, Dicer mantiene los servicios con alta disponibilidad y bien equilibrados, incluso durante reinicios progresivos, fallas, eventos de autoescalado y períodos de gran desequilibrio de carga.
Como fragmentador automático, Dicer se basa en una larga línea de sistemas anteriores, incluidos Centrifuge [3], Slicer [4] y Shard Manager [5]. En la siguiente sección, presentamos Dicer y describimos cómo ha ayudado a mejorar el rendimiento, la confiabilidad y la eficiencia de nuestros servicios.
3. Dicer: Sharding dinámico para un alto rendimiento y disponibilidad
Ahora, ofrecemos una descripción general de Dicer y sus abstracciones principales, y describimos sus diversos casos de uso. Estén atentos a un análisis técnico detallado del diseño y la arquitectura de Dicer en una futura publicación del blog.
3.1 Descripción general de Dicer
Dicer modela una aplicación que atiende solicitudes (o realiza algún otro trabajo) asociadas con una clave lógica. Por ejemplo, un servicio que ofrece perfiles de usuario podría usar los ID de usuario como sus claves. Dicer fragmenta la aplicación generando continuamente una asignación de claves a pods para mantener el servicio con alta disponibilidad y balanceo de carga.
Para escalar a aplicaciones con millones o miles de millones de claves, Dicer opera en rangos de claves en lugar de claves individuales. Las aplicaciones representan las claves para Dicer usando una SliceKey (un hash de la clave de la aplicación), y un rango contiguo de SliceKeys se denomina Slice. Como se muestra en la Figura 1, una Assignment de Dicer es una colección de Slices que en conjunto abarcan todo el espacio de claves de la aplicación, con cada Slice asignado a uno o más Resources (es decir, pods). Dicer divide, fusiona, replica y reasigna dinámicamente los Slices en respuesta a las señales de estado y carga de la aplicación, lo que garantiza que todo el espacio de claves esté siempre asignado a pods en buen estado y que ningún pod individual se sobrecargue. Dicer también puede detectar claves con mucho tráfico y dividirlas en sus propios slices, y asignar dichos slices a varios pods para distribuir la carga.
La Figura 1 muestra un ejemplo de asignación de Dicer en 3 pods (P0, P1 y P2) para una aplicación fragmentada por ID de usuario, donde el usuario con ID 13 está representado por SliceKey K26 (es decir, un hash del ID 13) y actualmente está asignado al pod P0. Un usuario con alta carga con ID de usuario 42 y representado por SliceKey K10 ha sido aislado en su propio slice y asignado a múltiples pods para manejar la carga (P1 y P2).

{kind=link}
La Figura 2 muestra una descripción general de una aplicación fragmentada integrada con Dicer. Los pods de la aplicación aprenden la asignación actual a través de una biblioteca llamada Slicelet (S para el lado del servidor). El Slicelet mantiene una caché local de la asignación más reciente obteniéndola del servicio de Dicer y observando si hay actualizaciones. Cuando recibe una asignación actualizada, el Slicelet notifica a la aplicación a través de una API de escucha.
Las asignaciones observadas por los Slicelets son finalmente coherentes, una decisión de diseño deliberada que prioriza la disponibilidad y la recuperación rápida por sobre las garantías sólidas de propiedad de claves. En nuestra experiencia, este ha sido el modelo adecuado para la gran mayoría de las aplicaciones, aunque planeamos admitir garantías más sólidas en el futuro, similares a Slicer y Centrifuge.
Además de mantenerse actualizadas sobre la asignación, las aplicaciones también usan el Slicelet para registrar la carga por clave al manejar solicitudes o realizar trabajo para una clave. El Slicelet agrega esta información localmente e informa un resumen de forma asíncrona al servicio Dicer. Ten en cuenta que, al igual que la supervisión de la asignación, esto también ocurre fuera de la ruta crítica de la aplicación, lo que garantiza un alto rendimiento.
Los clientes de una aplicación fragmentada de Dicer encuentran el pod asignado para una clave determinada a través de una biblioteca llamada Clerk (C para el lado del cliente). Al igual que los Slicelets, los Clerks también mantienen activamente una caché local de la asignación más reciente en segundo plano para garantizar un alto rendimiento para las búsquedas de claves en la ruta crítica.

Por último, el Assigner de Dicer es el servicio controlador responsable de generar y distribuir asignaciones basándose en las señales de estado y carga de la aplicación. En su núcleo, se encuentra un algoritmo de sharding que calcula ajustes mínimos mediante divisiones de Slice, fusiones, replicación/desreplicación y movimientos para mantener las claves asignadas a pods en buen estado y la carga de la aplicación general suficientemente balanceada. El servicio Assigner es multiinquilino y está diseñado para proporcionar un servicio de auto-sharding para todas las aplicaciones con sharding dentro de una región. Cada aplicación con sharding atendida por Dicer se denomina Target.
3.2 Amplia clase de aplicaciones mejoradas por Dicer
Dicer es valioso para una amplia gama de sistemas porque la capacidad de afinitizar las cargas de trabajo a pods específicos genera mejoras de rendimiento significativas. Hemos identificado varias categorías principales de casos de uso basándonos en nuestra experiencia en producción.
Servicio en memoria y en GPU
Dicer se destaca en situaciones en las que un gran corpus de datos debe cargarse y servirse directamente desde la memoria. Al garantizar que las solicitudes de claves específicas siempre lleguen a los mismos pods, los servicios como los almacenes de clave-valor pueden alcanzar una latencia inferior al milisegundo y un alto rendimiento, a la vez que se evita la sobrecarga de obtener datos de un almacenamiento remoto.
Dicer también es muy adecuado para las cargas de trabajo modernas de inferencia de LLM, en las que es fundamental mantener la afinidad. Algunos ejemplos son las sesiones de usuario con estado que acumulan contexto en una caché KV por sesión, así como las implementaciones que sirven a un gran número de adaptadores LoRA y deben fragmentarlos de forma eficiente entre recursos de GPU limitados.
Sistemas de control y programación
Este es uno de los casos de uso más comunes en Databricks. Incluye sistemas como administradores de clústeres y motores de orquestación de consultas que monitorean continuamente los recursos para administrar el escalamiento, la programación de cómputo y la multitenencia. Para operar de manera eficiente, estos sistemas mantienen el estado de monitoreo y control localmente, lo que evita la serialización repetida y permite respuestas oportunas a los cambios.
Cachés remotas
Dicer se puede utilizar para crear cachés remotos distribuidos de alto rendimiento, lo que hemos hecho en producción en Databricks. Al usar las capacidades de Dicer, nuestro caché se puede autoescalar y reiniciar sin interrupciones ni pérdida de la tasa de aciertos, y evitar el desequilibrio de carga debido a claves de acceso frecuente.
Partición del trabajo y trabajo en segundo plano
Dicer es una herramienta eficaz para particionar tareas en segundo plano y flujos de trabajo asíncronos en una flota de servidores. Por ejemplo, un servicio responsable de limpiar o recolectar basura de estado en una tabla masiva puede usar Dicer para garantizar que cada pod sea responsable de un rango distinto y no superpuesto del espacio de claves, lo que evita el trabajo redundante y la contención de bloqueos.
Procesamiento por lotes y agregación
Para las rutas de escritura de alto volumen, Dicer permite una agregación eficiente de registros. Al enrutar registros relacionados al mismo pod, el sistema puede agrupar las actualizaciones en la memoria antes de confirmarlas en el almacenamiento persistente. Esto reduce significativamente las operaciones de entrada/salida por segundo necesarias y mejora el rendimiento general del pipeline de datos.
Selección de líder flexible
Dicer se puede utilizar para implementar una selección de líder "suave" al designar un pod específico como el coordinador principal para una clave o shard determinado. Por ejemplo, un programador de servicio puede usar Dicer para garantizar que un único pod actúe como la autoridad principal para gestionar un grupo de recursos. Si bien Dicer actualmente proporciona una selección de líder basada en la afinidad, sirve como una base sólida para sistemas que requieren un primario coordinado sin la gran sobrecarga de los protocolos de consenso tradicionales. Estamos explorando mejoras futuras para proporcionar garantías más sólidas en torno a la exclusión mutua para estas cargas de trabajo.
Encuentro y coordinación
Dicer actúa como un punto de encuentro natural para clientes distribuidos que necesitan coordinación en tiempo real. Al enrutar todas las solicitudes de una clave específica al mismo pod, ese pod se convierte en un lugar de encuentro central donde el estado compartido se puede gestionar en la memoria local sin saltos de red externos.
Por ejemplo, en un servicio de chat en tiempo real, dos clientes que se unen a la misma "ID de sala de chat" se enrutan automáticamente al mismo pod. Esto permite que el pod sincronice sus mensajes y estado instantáneamente en la memoria, lo que evita la latencia de una base de datos compartida o un back-plane de comunicación complejo.
4. Casos de éxito
Numerosos servicios en Databricks han logrado mejoras significativas con Dicer, y a continuación destacamos varios de estos casos de éxito.
4.1 Unity Catalog
Unity Catalog (UC) es la solución de gobernanza unificada para los activos de datos e IA en toda la plataforma de Databricks. Diseñado originalmente como un servicio sin estado, UC enfrentó importantes desafíos de escalabilidad a medida que su popularidad crecía, impulsada principalmente por un volumen de lectura extremadamente alto. Atender cada solicitud requería acceso repetido a la base de datos de backend, lo que introducía una latencia prohibitiva. Los enfoques convencionales, como el almacenamiento en caché remoto, no eran viables, ya que la memoria caché necesitaba actualizarse de forma incremental y mantener la coherencia de las instantáneas con el almacenamiento. Además, los catálogos de los clientes pueden tener un tamaño de gigabytes, lo que hace que sea costoso mantener instantáneas parciales o replicadas en una memoria caché remota sin introducir una sobrecarga sustancial.
Para solucionar esto, el equipo integró Dicer para crear un caché con estado, particionado y en memoria. Este cambio permitió a UC reemplazar las costosas llamadas de red remotas por llamadas de métodos locales, lo que redujo drásticamente la carga de la base de datos y mejoró la capacidad de respuesta. La siguiente figura ilustra el despliegue inicial de Dicer, seguido de la implementación de la integración completa de Dicer. Al utilizar la afinidad con estado de Dicer, UC logró una tasa de aciertos de caché del 90–95 %, lo que redujo significativamente la frecuencia de los viajes de ida y vuelta a la base de datos.

{kind=link}
4.2 Motor de orquestación de consultas SQL
El motor de orquestación de consultas de Databricks, que gestiona la programación de consultas en clústeres de Spark, se creó originalmente como un servicio con estado en memoria mediante sharding estático. A medida que el servicio escalaba, las limitaciones de esta arquitectura se convirtieron en un cuello de botella importante; debido a la sencilla implementación, el escalado requería un re-sharding manual, lo que era extremadamente laborioso, y el sistema sufría caídas frecuentes de disponibilidad, incluso durante los reinicios continuos.
Después de la integración con Dicer, estos problemas de disponibilidad se eliminaron (consulte la Figura 4). Dicer permitió un tiempo de inactividad cero durante los reinicios y los eventos de escalamiento, lo que permitió al equipo reducir el trabajo pesado y mejorar la robustez del sistema al habilitar el autoescalado en todas partes. Además, la función de balanceo de carga dinámico de Dicer resolvió aún más la limitación crónica de la CPU, lo que resultó en un rendimiento más consistente en toda la flota.
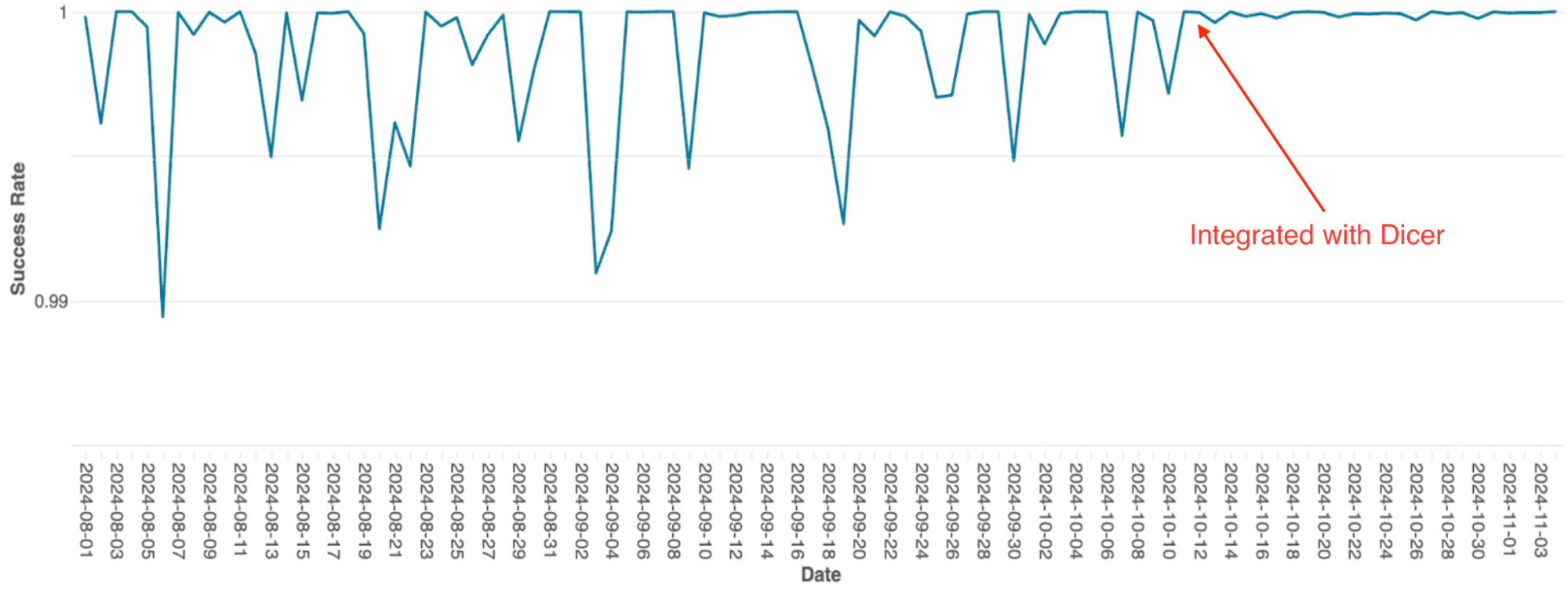
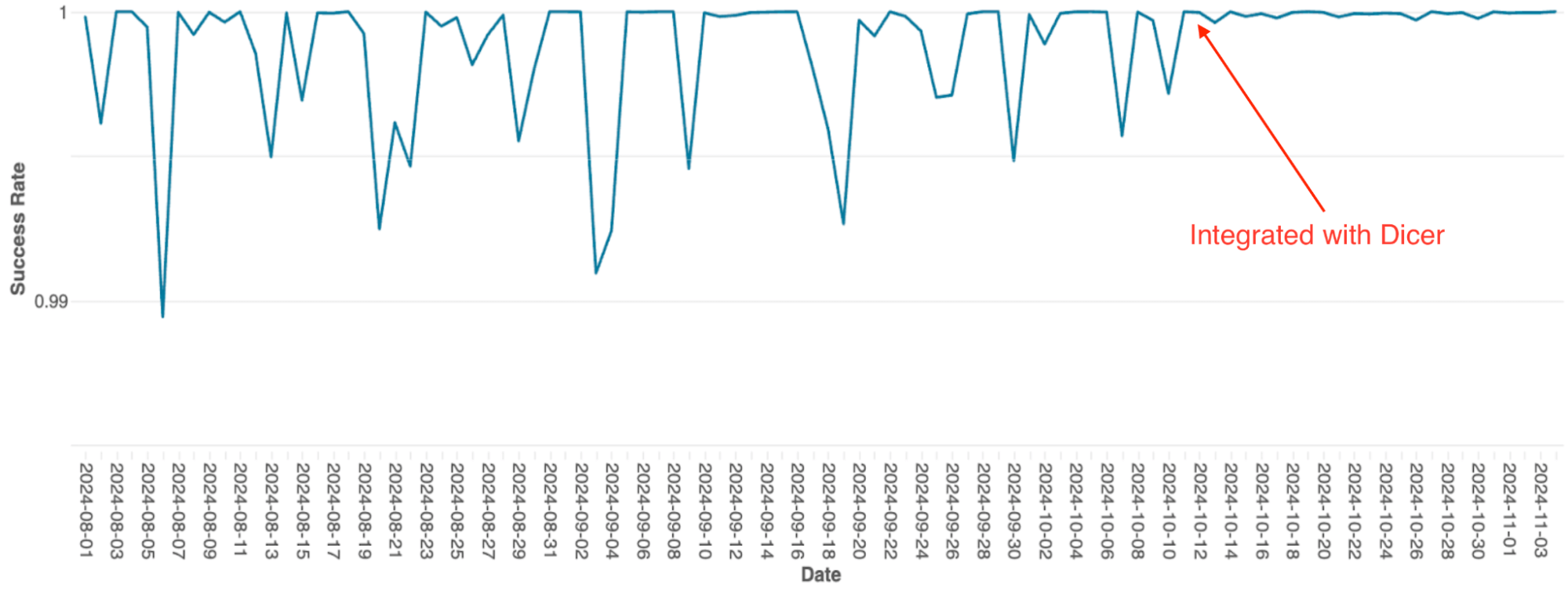{kind=link}
4.3 Caché remoto Softstore
Para los servicios que no están fragmentados, desarrollamos Softstore, un caché distribuido remoto de clave-valor. Softstore aprovecha una función de Dicer llamada transferencia de estado, que migra datos entre pods durante la refragmentación para preservar el estado de la aplicación. Esto es particularmente importante durante los reinicios continuos planificados, donde inevitablemente se produce una gran rotación en todo el espacio de claves. En nuestra flota de producción, los reinicios planificados representan aproximadamente el 99.9 % de todos los reinicios, lo que hace que este mecanismo sea especialmente impactante y permite reinicios sin interrupciones con un impacto insignificante en las tasas de aciertos de caché. La Figura 5 muestra las tasas de aciertos de Softstore durante un reinicio gradual, donde la transferencia de estado preserva una tasa de aciertos estable de ~85 % para un caso de uso representativo, y la variabilidad restante es impulsada por las fluctuaciones normales de la carga de trabajo.
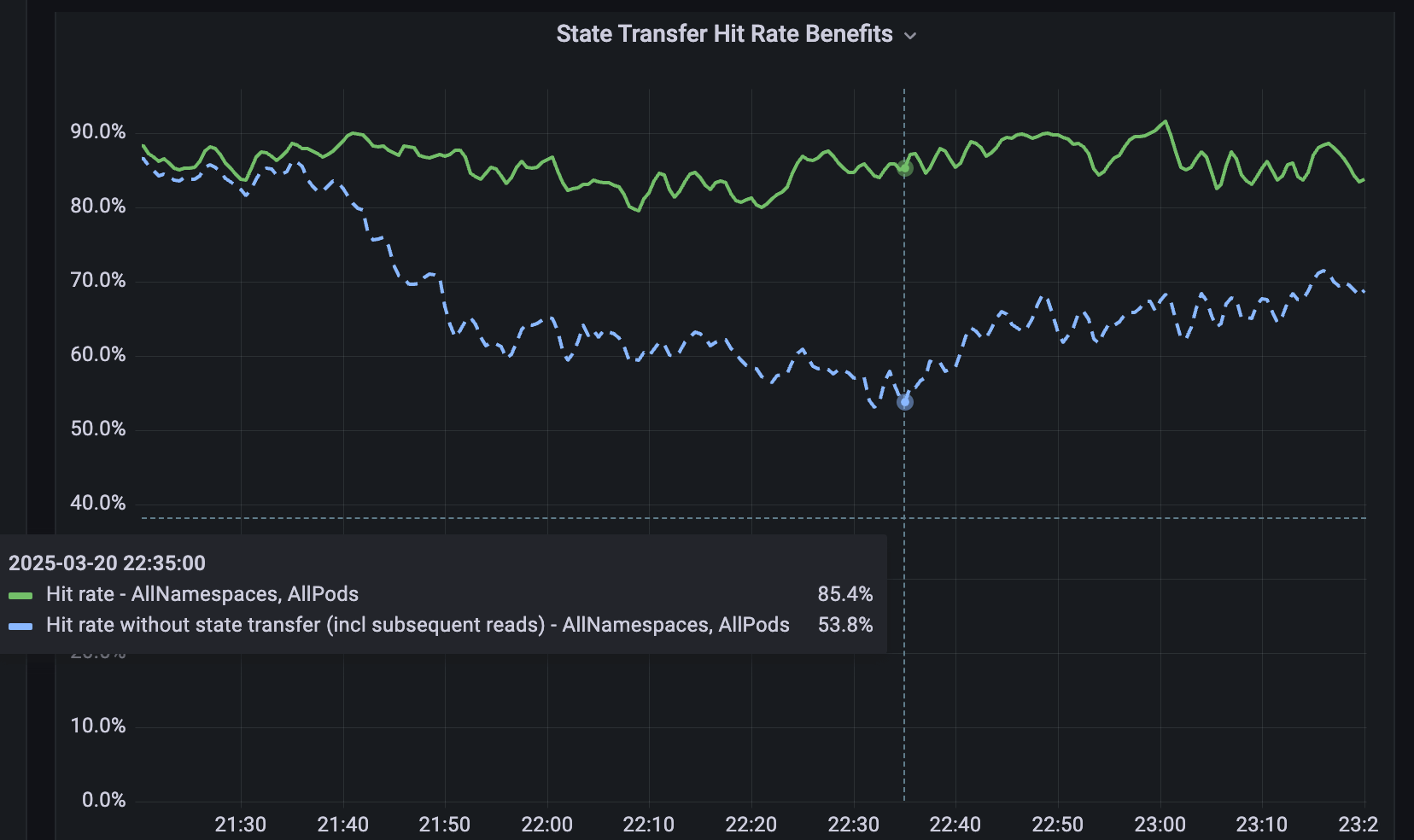
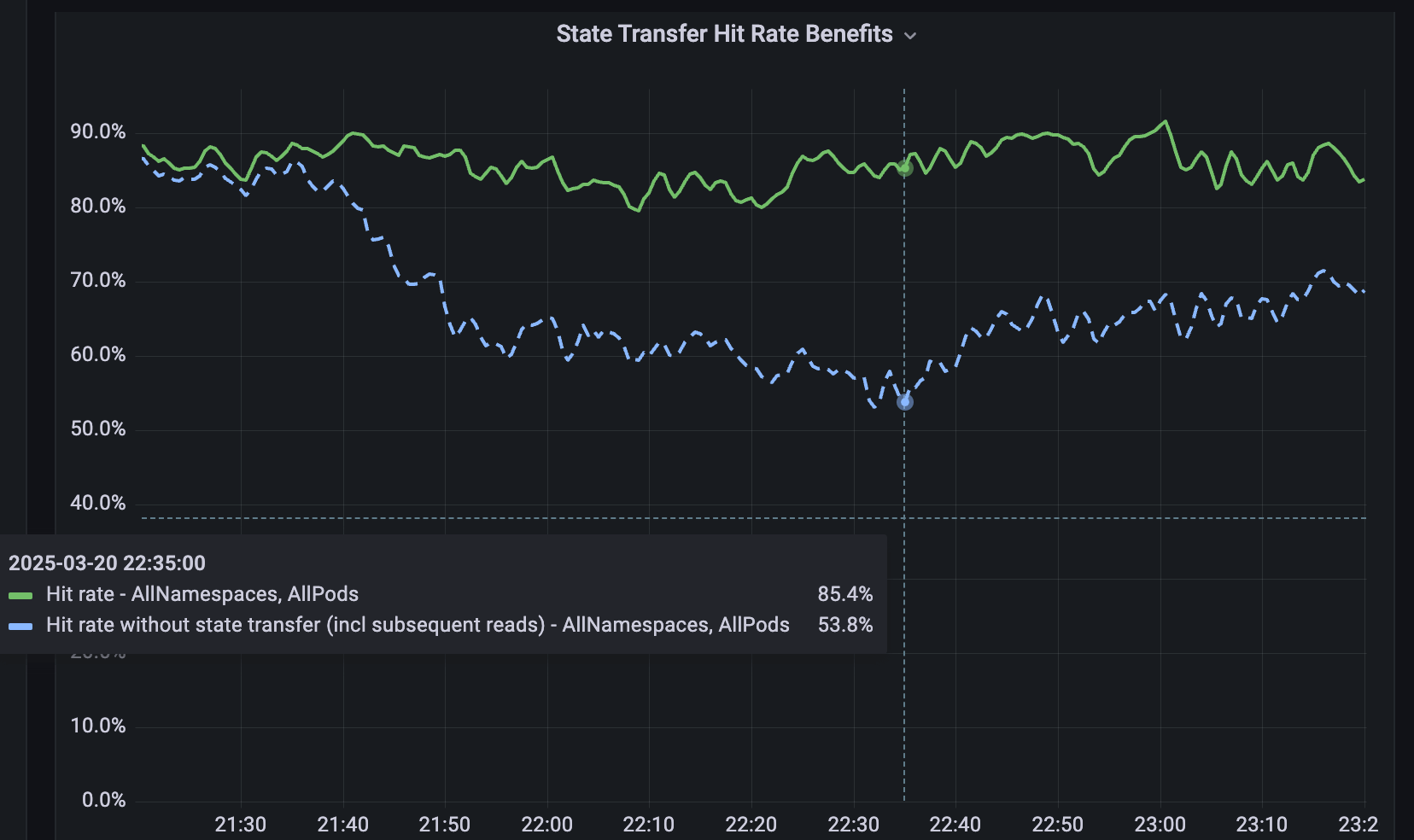{kind=link}
5. ¡Ahora tú también puedes usarlo!
Puede probar Dicer hoy mismo en su equipo descargándolo desde aquí. Se proporciona una demostración simple de su uso aquí, que muestra una configuración de ejemplo de Dicer con un cliente y algunos servidores para una aplicación. Consulte el archivo README y la guía del usuario de Dicer.
6. Próximas funciones y artículos
Dicer es un servicio crítico que se utiliza en todo Databricks y su uso está creciendo rápidamente. En el futuro, publicaremos más artículos sobre el funcionamiento interno y los diseños de Dicer. También lanzaremos más funciones a medida que las desarrollemos y probemos internamente, por ejemplo, bibliotecas de Java y Rust para clientes y servidores, y las capacidades de transferencia de estado mencionadas en esta publicación. ¡Envíanos tus comentarios y mantente atento a las novedades!
Si te gusta resolver problemas de ingeniería difíciles y te gustaría unirte a Databricks, ¡visita databricks.com/careers!
7. Referencias
[1] Ziming Mao, Jonathan Ellithorpe, Atul Adya, Rishabh Iyer, Matei Zaharia, Scott Shenker, Ion Stoica (2025). Reconsiderando el costo de las cachés distribuidas para los servicios de centros de datos. Actas del 24.° Taller de ACM sobre Temas de Actualidad en Redes, 1–8.
[2] Atul Adya, Robert Grandl, Daniel Myers, Henry Qin. Almacenes de clave-valor rápidos: una idea cuyo momento ya pasó. Actas del Taller sobre Temas de Actualidad en Sistemas Operativos (HotOS ’19), 13–15 de mayo de 2019, Bertinoro, Italia. ACM, 7 páginas. DOI: 10.1145/3317550.3321434.
[3] Atul Adya, James Dunagan, Alexander Wolman. Centrifuge: Integrated Lease Management and Partitioning for Cloud Services. Proceedings of the 7th USENIX Symposium on Networked Systems Design and Implementation (NSDI), 2010.
[4] Atul Adya, Daniel Myers, Jon Howell, Jeremy Elson, Colin Meek, Vishesh Khemani, Stefan Fulger, Pan Gu, Lakshminath Bhuvanagiri, Jason Hunter, Roberto Peon, Larry Kai, Alexander Shraer, Arif Merchant, Kfir Lev-Ari. Slicer: Auto-Sharding for Datacenter Applications. Actas del 12.º Simposio de USENIX sobre Diseño e Implementación de Sistemas Operativos (OSDI), 2016, pp. 739–753.
[5] Sangmin Lee, Zhenhua Guo, Omer Sunercan, Jun Ying, Chunqiang Tang, et al. Shard Manager: A Generic Shard Management Framework for Geo distributed Applications. Actas del 28.º Simposio del ACM SIGOPS sobre Principios de Sistemas Operativos (SOSP), 2021. DOI: 10.1145/3477132.3483546.
[6] Atul Adya, Jonathan Ellithorpe. Servicios con estado: baja latencia, eficiencia, escalabilidad — elige tres. Taller sobre Sistemas Transaccionales de Alto Rendimiento (HPTS) 2024, Pacific Grove, California, 15–18 de septiembre de 2024.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.