Repensando el ETL de SQL para plataformas de datos modernas
Reduzca el costo y la complejidad al unificar los pipelines SQL fragmentados en una única plataforma
por Matt Jones y Shanelle Roman
- El ETL SQL fragmentado genera costos ocultos, pipelines frágiles y una resolución lenta de incidentes
- Ejecutar ETL a través de almacenes, orquestadores y herramientas crea una fricción operativa que escala con cada pipeline
- Una plataforma unificada para todo el ETL SQL elimina la sobrecarga de coordinación y permite a los equipos entregar más rápido en un sistema gobernado
SQL es la base del trabajo moderno con datos. Es cómo los ingenieros de análisis definen las transformaciones, cómo los ingenieros de almacenes de datos gestionan las canalizaciones y cómo los analistas exploran y refinan los datos.
Pero si bien SQL en sí está estandarizado, los sistemas utilizados para ejecutar ETL de SQL son todo menos eso.
En la mayoría de las organizaciones, las canalizaciones de SQL se distribuyen a través de una combinación de herramientas: un almacén de datos para la ejecución, un marco de transformación para el modelado, un orquestador para la programación y sistemas separados para la monitorización, el linaje y la calidad de los datos. Cada capa aborda una necesidad específica, pero juntas crean un entorno fragmentado que es difícil de operar y cada vez más difícil de escalar.
A medida que los equipos de datos escalan, esta fragmentación comienza a manifestarse en las operaciones diarias. Las canalizaciones fallan en múltiples sistemas, las dependencias son difíciles de rastrear y la resolución de problemas a menudo requiere saltar entre herramientas que nunca fueron diseñadas para trabajar juntas. Al mismo tiempo, las expectativas aumentan. Se pide a los equipos que entreguen datos más recientes, soporten más casos de uso y se muevan más rápido, sin añadir sobrecarga operativa.
Aquí es donde muchas estrategias de plataformas de datos comienzan a fallar. Incluso cuando las organizaciones invierten en infraestructura moderna, el ETL de SQL a menudo permanece distribuido en múltiples sistemas, arrastrando la misma complejidad y limitaciones.
El desafío no es SQL en sí, sino cómo se implementa el ETL de SQL.
Si el ETL de SQL se diseñara desde cero para la forma en que los equipos trabajan hoy en día, se vería muy diferente. En la práctica, significaría:
- Una única plataforma para ETL
- Soporte para cada profesional de SQL
- Canalizaciones abiertas y preparadas para el futuro
Juntos, estos principios definen un enfoque más simple y duradero para el ETL de SQL, uno que reduce la fragmentación hoy mientras soporta cómo evolucionan las cargas de trabajo de datos con el tiempo.
Ejecute y opere ETL de SQL en una única plataforma
El desafío en el ETL de SQL no es escribir transformaciones, es operar las canalizaciones a medida que abarcan múltiples sistemas.
En la práctica, esto significa coordinar la ejecución en el almacén de datos, la orquestación en un sistema separado y la observabilidad superpuesta después. Mantener las canalizaciones en funcionamiento requiere unir estas piezas: rastrear dependencias, diagnosticar fallas y gestionar reintentos en herramientas que no comparten contexto.
A medida que las canalizaciones crecen en número e importancia, esta coordinación se convierte en una carga operativa significativa.
Una plataforma unificada simplifica este modelo al reunir estas capacidades. Cuando la ejecución, la orquestación, la observabilidad y la gobernanza forman parte del mismo sistema, las canalizaciones se vuelven más fáciles de gestionar por diseño. Las dependencias se rastrean automáticamente y los problemas se pueden identificar y resolver más rápidamente porque el contexto relevante está disponible en un solo lugar.
En Databricks, el ETL de SQL se define y ejecuta dentro de una única plataforma. Las canalizaciones se ejecutan con orquestación incorporada, mientras que el linaje y la observabilidad se capturan automáticamente en cada etapa. Las comprobaciones de calidad de datos y los controles de gobernanza se integran directamente en la ejecución de la canalización en lugar de gestionarse a través de herramientas separadas.
Este enfoque se fortalece aún más con la infraestructura sin servidor y la optimización impulsada por IA. La optimización del rendimiento, la gestión de recursos y el escalado se manejan automáticamente, lo que permite a los equipos centrarse en la entrega de datos fiables en lugar de operar sistemas.
Después de la transición de nuestras canalizaciones de Databricks a la computación sin servidor, HP obtuvo ahorros en la nube de más del 32% y disminuyó el tiempo de ejecución combinado de los trabajos en un 36%. La gestión de infraestructura sin esfuerzo proporcionada por el servidor hizo de esta decisión una elección obvia y estratégica. —Luis Alonso, Jefe de Estrategia y Ingeniería de Datos en HP Marketing
El resultado es una base más optimizada y fiable para el ETL de SQL, una que reduce la sobrecarga operativa al tiempo que mejora el rendimiento y la fiabilidad a escala.
Apoye cómo los equipos realmente construyen canalizaciones de SQL
El ETL de SQL está fragmentado no solo por las herramientas, sino porque los equipos no construyen todas las canalizaciones de la misma manera.
Los ingenieros de análisis, que se centran en definir la lógica de negocio en SQL, a menudo quieren una forma de construir canalizaciones sin gestionar la infraestructura subyacente, con pruebas, control de versiones y dependencias gestionadas automáticamente. Los ingenieros de almacenes de datos tienden a depender de scripts SQL y procedimientos almacenados, a menudo dentro de entornos de ejecución estrictamente controlados. Los analistas pueden crear transformaciones directamente dentro de herramientas sin código o interfaces SQL ligeras.
Muchas plataformas favorecen implícitamente uno de estos enfoques. A medida que las organizaciones crecen, a menudo introducen sistemas adicionales para soportar otras personas, lo que resulta en entornos paralelos que son difíciles de estandarizar y mantener.
Un enfoque más efectivo es estandarizar la plataforma en lugar de la interfaz.
Databricks soporta una variedad de flujos de trabajo de ETL de SQL dentro del mismo entorno. Los equipos pueden ejecutar flujos de trabajo dbt existentes directamente en la plataforma, trasladar SQL de estilo almacén a scripts y procedimientos almacenados, acelerar las cargas de trabajo de BI con Vistas Materializadas en Databricks SQL, definir canalizaciones declarativas que simplifican los flujos de trabajo de producción, o usar herramientas sin código para analistas de negocio construidas en la misma plataforma. Aunque estos enfoques difieren en cómo se autorizan las canalizaciones, comparten el mismo motor de ejecución, modelo de gobernanza y marco de observabilidad.

Esta consistencia permite a las organizaciones soportar múltiples estilos de desarrollo sin introducir fragmentación en cómo se ejecutan las canalizaciones. Los equipos pueden trabajar al nivel de abstracción que se adapte a sus necesidades, mientras siguen beneficiándose del linaje compartido, la monitorización y los controles operativos.
También asegura que los scripts SQL existentes de estilo almacén y los enfoques más nuevos puedan coexistir sobre la misma base. Los equipos no necesitan elegir entre mantener lo que tienen y adoptar nuevos patrones; pueden hacer ambas cosas dentro de un único sistema.
Cada uno de estos flujos de trabajo se refleja en una experiencia de autoría dedicada.
1. Para ingenieros de almacenes de datos que ejecutan scripts SQL y procedimientos almacenados:
Editor SQL para procedimientos almacenados y vistas materializadas
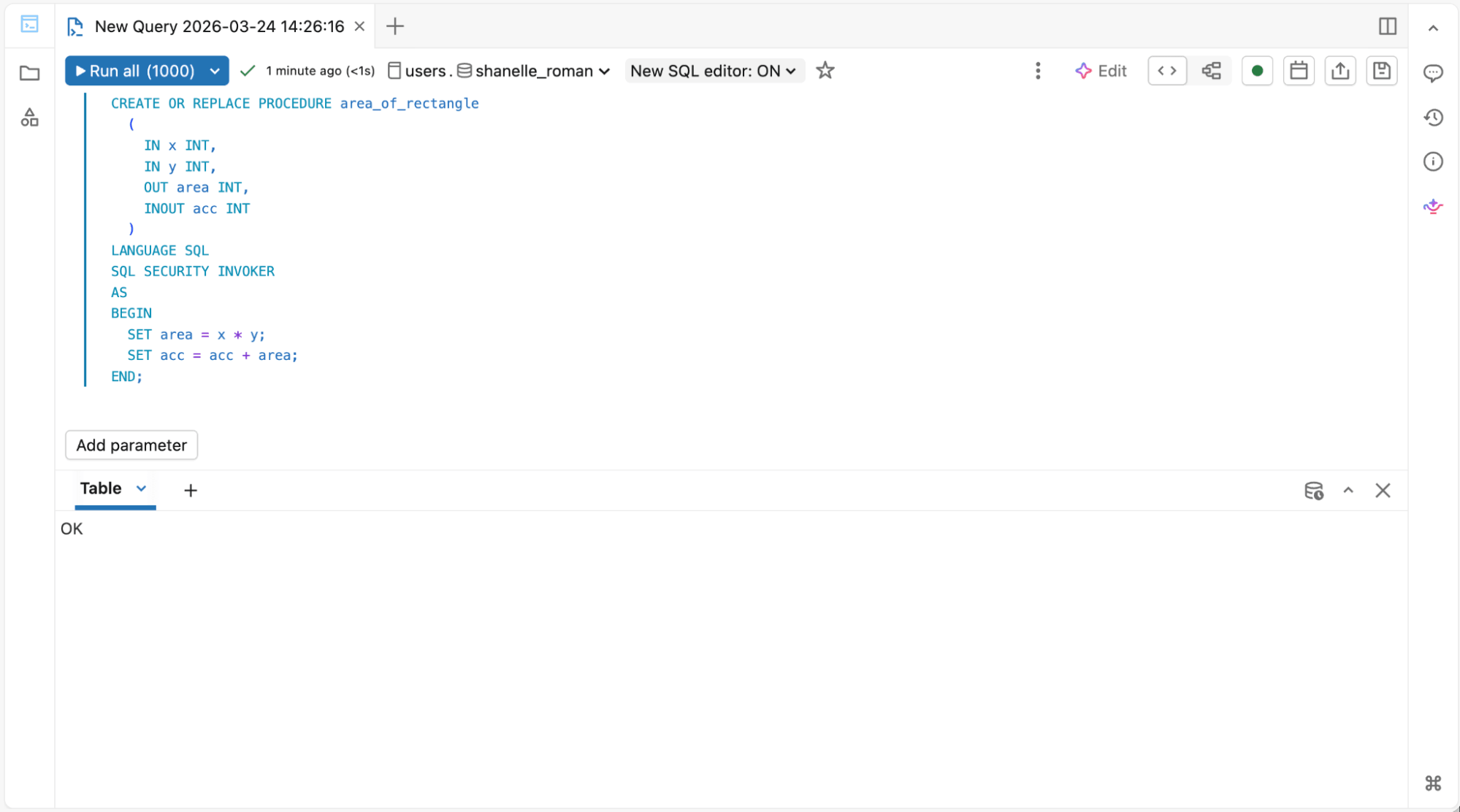
{kind=link}
2. Para ingenieros de análisis que construyen canalizaciones de producción con SQL:
Editor de canalizaciones declarativas de Spark
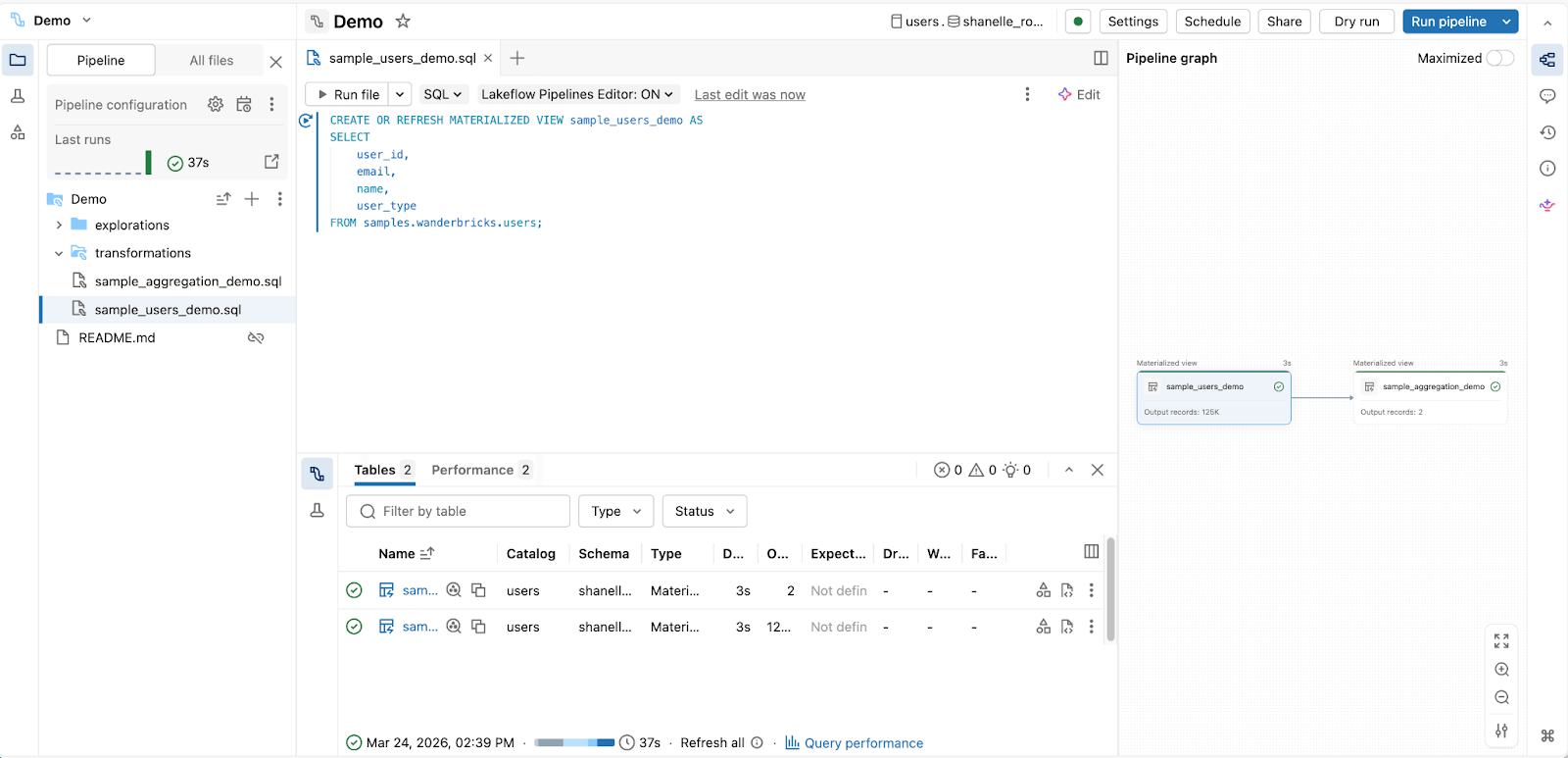
3. Para analistas y usuarios de negocio que preparan datos sin código:
Lakeflow Designer
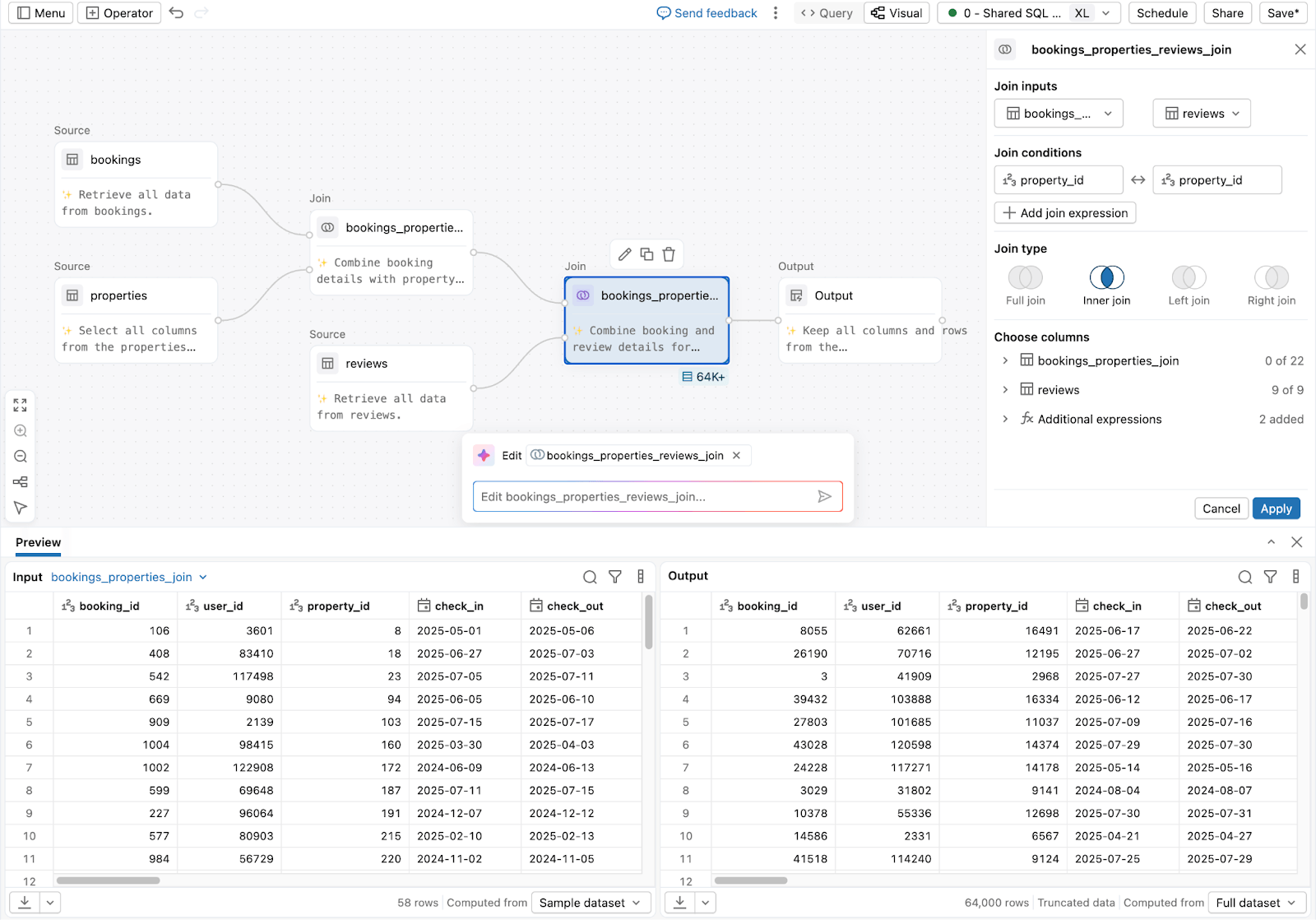
El resultado es un entorno más cohesivo para el ETL de SQL, donde la colaboración mejora y la complejidad operativa no aumenta con la escala.
Construya canalizaciones de SQL que evolucionen con sus cargas de trabajo
A medida que surgen nuevas fuentes de datos, casos de uso en tiempo real y cargas de trabajo de IA, los equipos a menudo se ven obligados a introducir sistemas adicionales o reescribir las canalizaciones existentes, lo que añade complejidad y coste con el tiempo.
Muchas soluciones de ETL de SQL introducen estas limitaciones a través de formatos propietarios, modelos de ejecución fuertemente acoplados o suposiciones sobre cómo se procesarán los datos. Estas limitaciones pueden no ser inmediatamente aparentes, pero tienden a surgir a medida que las organizaciones se expanden a nuevas cargas de trabajo, requieren datos más recientes o soportan un conjunto más amplio de casos de uso.
Un enfoque de ETL de SQL preparado para el futuro prioriza la apertura y la flexibilidad desde el principio.
Databricks construye ETL de SQL sobre formatos de tabla abiertos y ANSI SQL, lo que ayuda a garantizar que las canalizaciones sigan siendo portátiles e interoperables entre sistemas. Esto reduce el riesgo de dependencia del proveedor y permite a las organizaciones mantener el control sobre sus datos y lógica a medida que su arquitectura evoluciona.
Al mismo tiempo, Databricks proporciona un modelo SQL unificado que soporta casos de uso de análisis tanto por lotes como en tiempo real. En lugar de requerir sistemas separados para diferentes cargas de trabajo, el mismo enfoque basado en SQL se puede aplicar a una amplia gama de casos de uso.
Esta flexibilidad permite que las canalizaciones evolucionen junto con la organización. Los equipos pueden seguir ejecutando flujos de trabajo SQL existentes mientras adoptan patrones más avanzados, como el procesamiento incremental o las canalizaciones declarativas, cuando sean necesarios.
La conversión a Vistas Materializadas ha resultado en una mejora drástica en el rendimiento de las consultas, con el tiempo de ejecución disminuyendo de 8 minutos a solo 3 segundos. Esto permite a nuestro equipo trabajar de manera más eficiente y tomar decisiones más rápidas basadas en los conocimientos obtenidos de los datos. Además, los ahorros de costos adicionales han sido de gran ayuda. —Karthik Venkatesan, Gerente Senior de Ingeniería de Software de Seguridad, Adobe
Al evitar restricciones arquitectónicas rígidas, este enfoque proporciona una base estable que puede soportar tanto los requisitos actuales como las demandas futuras sin necesidad de cambios disruptivos.
¿Por qué SQL ETL debería dar forma a su estrategia de plataforma de datos?
Las discusiones sobre plataformas de datos a menudo se centran en dónde se almacenan los datos y cómo se ejecutan las consultas. En la práctica, sin embargo, la efectividad de una plataforma depende tanto de cómo se construyen y mantienen las canalizaciones de datos, como de si se definen de manera abierta e interoperable para evitar el bloqueo a largo plazo.
Si SQL ETL permanece fragmentado en múltiples sistemas, es probable que las organizaciones arrastren la misma complejidad operativa e ineficiencias, incluso después de adoptar una nueva plataforma. Con el tiempo, esto limita el valor de la plataforma y dificulta la escalabilidad de las operaciones de datos.
Un enfoque más efectivo es evaluar qué tan bien una plataforma soporta SQL ETL a lo largo de su ciclo de vida completo: desde el desarrollo y la ejecución hasta la monitorización y la gobernanza. Esto incluye la capacidad de soportar diferentes estilos de trabajo, reducir la sobrecarga operativa y adaptarse a los requisitos cambiantes sin introducir sistemas adicionales.
Databricks aborda estas necesidades combinando la ejecución de SQL, la gestión de canalizaciones, la gobernanza y la optimización dentro de una única plataforma. Este enfoque unificado permite a los equipos construir y operar canalizaciones SQL de manera más eficiente, manteniendo la flexibilidad para soportar una amplia gama de cargas de trabajo.
Conclusión
SQL seguirá desempeñando un papel central en la forma en que las organizaciones trabajan con los datos.
Como resultado, la forma en que se implementa SQL ETL tiene un impacto directo en la efectividad de la plataforma de datos general. Los enfoques fragmentados introducen complejidad y ralentizan a los equipos, mientras que los enfoques unificados simplifican las operaciones y mejoran la escalabilidad.
Para las organizaciones que evalúan cómo evolucionar sus plataformas de datos, SQL ETL es una consideración fundamental. Databricks proporciona un modelo para SQL ETL unificado y a prueba de futuro que reúne la ejecución, la gestión de canalizaciones y la gobernanza dentro de una única plataforma, al tiempo que permanece abierto y adaptable a medida que evolucionan los requisitos.
En la práctica, la mayoría de las organizaciones no parten de cero. La modernización de SQL ETL a menudo se estanca porque el costo y el riesgo de reescribir las canalizaciones de producci�ón son demasiado altos. En lugar de forzar una reconstrucción disruptiva, un enfoque más efectivo es evolucionar de forma incremental: ejecutando primero las canalizaciones existentes, consolidando sistemas con el tiempo y modernizando paso a paso.
Así es como los equipos pueden reducir la fragmentación hoy mientras construyen una plataforma de datos más unificada y a prueba de futuro con el tiempo. Profundizaremos en este enfoque con más detalle en una publicación futura. Mientras tanto, puede leer más sobre cómo construir, ejecutar y escalar canalizaciones SQL en una plataforma lakehouse unificada en este libro electrónico, Una guía para construir canalizaciones ETL con SQL.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.