La piedra Rosetta de CPS: la biblioteca de Claroty impulsada por IA
Cómo un sistema de IA multiagente en Databricks resuelve la crisis de identidad de CPS
por Ben Hazan, Anton Berlinsky, Ohad Avni, Itay Wagner, Guy Zalcman , Dor Bdolach, Ravid Ariely y Gal Sberro
- La biblioteca de CPS impulsada por IA de Claroty resuelve la crisis de identidad de activos, donde al 88% de los dispositivos CPS les falta un código de producto exacto, automatizando la resolución de entidades en más de 17 millones de activos industriales y sanitarios.
- Un sistema de IA multiagente construido sobre los Agentes Personalizados de Databricks combina agentes de PNL y razonamiento con retroalimentación humana, impulsado por una Arquitectura Medallion en Delta Lake, para convertir señales de dispositivos fragmentadas en una única fuente de verdad determinista.
- El resultado: Solo en el MVP, hemos visto una mejora de más del 25% en la precisión de la atribución de vulnerabilidades y más del 56% de los dispositivos analizados reciben nuevas recomendaciones de seguridad para firmware obsoleto invisible anteriormente.
La Piedra Rosetta de CPS: Dentro de la Biblioteca Revolucionaria con IA de Claroty
Durante décadas, el mundo de los Sistemas Ciberfísicos (CPS, por sus siglas en inglés) —la maquinaria que impulsa nuestras fábricas, hospitales e infraestructuras críticas— ha sufrido una "crisis de identidad" silenciosa. Mientras que un administrador de TI puede identificar fácilmente cada portátil en su red, un equipo de seguridad de OT (Tecnología Operacional) a menudo tiene dificultades para saber exactamente qué se está ejecutando en su planta.
Un informe reciente del equipo de investigación Team82 de Claroty reveló una realidad impactante: el 88% de los activos CPS no transmiten un código de producto exacto, y el 76% utiliza códigos de producto que difieren de los registros oficiales del proveedor. Esta falta de un "certificado de nacimiento digital" hace que la gestión de vulnerabilidades sea casi imposible, ya que los equipos de seguridad se ven obligados a armar manualmente información de recursos inconsistentes.
Para resolver esto, Claroty presentó recientemente su Biblioteca CPS con IA, un motor de mapeo autoritativo pionero diseñado para ser el "traductor universal" para hardware industrial y de atención médica.
En esencia, este es un desafío de Resolución de Entidades (ER) y el propósito del sistema es resolver la crisis de identidad al hacer coincidir y consolidar datos ruidosos del mundo real en una única fuente de verdad. Para lograr una trazabilidad determinista de alta fidelidad, fuimos más allá de los algoritmos de coincidencia estándar, diseñando una arquitectura híbrida que combina métodos ER clásicos probados en batalla con el poder cognitivo de la IA Generativa.
En respuesta a un punto crítico de dolor en la industria, nos asociamos con Databricks a través de su programa GenAI MVP. Esta colaboración aprovecha nuestra oferta especializada y las capacidades de Datos e IA de Databricks para ofrecer una solución definitiva al problema.
Cómo se ve en la realidad
Imagine una situación típica en una fábrica: Claroty xDome encuentra un dispositivo con un número de modelo como 1769-L36ERMS/B utilizando el protocolo CIP. Para una persona o una herramienta de seguridad simple, este es solo un código interno de Rockwell Automation; no está en ninguna base de datos de vulnerabilidades y no sugiere inmediatamente ningún riesgo.
Para proteger este dispositivo, el personal normalmente tendría que averiguar manualmente qué es, lo que implica:
- Buscar en la Web: Buscar en los catálogos de Rockwell para descubrir que este código significa que es un controlador Compact GuardLogix 5370.
- Verificar Vulnerabilidades: Buscar advertencias de CISA para ese nombre, lo que podría señalar CVE-2020-6998 como un riesgo para "versiones 33 y anteriores".
- Confirmar Detalles: Verificar la NVD (Base de Datos Nacional de Vulnerabilidades) para ver si el CPE (Common Platform Enumeration) específico coincide, solo para encontrar una entrada general para "CompactLogix 5370 L3" que puede o no incluir el subtipo "GuardLogix".
Este "trabajo de detective" manual es a menudo donde falla la seguridad. La Biblioteca CPS con IA automatiza todo este proceso. Reconoce instantáneamente el código interno, lo vincula al nombre comercial, identifica las piezas y versiones de firmware específicas, y adjunta los CVE correctos con precisión definida, convirtiendo una cadena confusa de caracteres en una configuración clara y segura en milisegundos.
Resolviendo la Crisis de Identidad con Visibilidad Determinista
La Biblioteca CPS no es solo una base de datos; es un sistema de IA multiagente que permite la remediación de "última milla". Al asociarse con gigantes de la industria, Claroty ha construido un grafo de evidencia que reconcilia datos de red desordenados en una única fuente de verdad.
Avances Clave Incluyen:
- Trazabilidad Determinista: Incluso cuando un dispositivo informa datos mínimos, la biblioteca utiliza inferencia estadística y lógica guiada por el dominio para triangular su identidad exacta.
- Atribución de Vulnerabilidades: Al identificar subcomponentes específicos y árboles de firmware, la biblioteca ha mejorado la precisión en la identificación de vulnerabilidades en un 25%.
- Información Accionable: En pruebas iniciales, el 56% de los dispositivos analizados recibieron recomendaciones de seguridad nuevas o actualizadas para firmware obsoleto que antes eran invisibles para los equipos de seguridad.
Bajo el Capó: El Motor de Inteligencia de Datos de Databricks
Para gestionar un catálogo global de más de 17 millones de activos y sus intrincadas dependencias, Claroty aprovecha la Plataforma de Inteligencia de Datos de Databricks como su columna vertebral unificada. Al adoptar una arquitectura Lakehouse, Claroty elimina los silos de datos tradicionales, permitiendo la ingesta de diversos conjuntos de datos —desde protocolos OT propietarios y llamadas API hasta manuales PDF de proveedores no estructurados— en un entorno único y escalable. Esta base proporciona la computación de alto rendimiento necesaria para ejecutar modelos complejos de inferencia estadística en millones de puntos de datos, asegurando que cada CPS-ID (el nuevo estándar de la industria para la identidad de sistemas ciberfísicos de Claroty) esté respaldado por una rigurosa integridad de datos e inteligencia inter-silos.
Ingeniería de Datos a Escala: El Pipeline Medallion
Alimentando este ecosistema se encuentra una robusta Arquitectura Medallion construida sobre Delta Lake y gobernada en Unity Catalog. El viaje comienza en la capa Bronze, donde las cargas útiles JSON crudas y heterogéneas se capturan en tablas Delta de solo adición. A partir de ahí, a un pipeline de promoción —leyendo desde Delta Change Data Feed (CDF)— aplica dinámicamente un registro de mapeo para transformar la evidencia cruda en un esquema canónico y gobernado. Al utilizar la evolución de esquemas y el viaje en el tiempo de Delta Lake, Claroty mantiene una cadena de custodia inquebrantable; cada registro de activo es rastreable hasta su artefacto crudo original y la versión de mapeo específica que lo clasificó, asegurando una auditabilidad completa incluso en los entornos industriales más sensibles.
Inteligencia Multiagente a través de Agentes Personalizados de Databricks
La parte más sofisticada de este motor híbrido es su uso de los Agentes Personalizados de Databricks. En lugar de depender de un único modelo monolítico, Claroty diseñó un Sistema Orquestado Multiagente, una red sincronizada donde agentes de IA especializados colaboran para interpretar señales complejas.
Para alimentar a estos agentes con contexto confiable, combinamos el análisis estadístico clásico de datos estructurados recopilados de fuentes propietarias con técnicas avanzadas de NLP que extraen señales del ruido inherente en la documentación del proveedor, las hojas de datos técnicas y las fuentes abiertas de la web. Unity Catalog de Databricks proporciona la base de datos gobernada necesaria para unificar estos diversos conjuntos de datos, mientras que los pipelines impulsados por Spark procesan y normalizan la información a escala. Juntas, estas capacidades sintetizan información fragmentada e inconsistente en las respuestas precisas y contextualizadas que los agentes necesitan para ofrecer coincidencias precisas de resolución de entidades.
El sistema se basa en tres componentes principales:
- Agentes NLP: Analizan datos complejos de formato mixto —incluidas cadenas de nombres derivadas de protocolos y marcadores de software oscuros que los modelos estándar a menudo pasan por alto.
- Agentes de Razonamiento: Aplican puntuaciones de confianza y pruebas estadísticas para sopesar la evidencia, discriminando señales de alta fidelidad del ruido para garantizar la integridad de los datos.
- Humano en el Bucle (HITL): Un mecanismo de retroalimentación crítico que marca mapeos de baja confianza para que los expertos los revisen. La salida de estas sesiones se retroalimenta al sistema, reentrenando los modelos para obtener ganancias continuas de precisión.
Innovación a través de las Capacidades de Databricks
El éxito de esta arquitectura radica no solo en los agentes en sí, sino en el ecosistema de extremo a extremo construido sobre Databricks que los impulsa. Aprovechamos toda la amplitud de la plataforma para pasar de MVP a producción con velocidad y confiabilidad:
1. Inteligencia Específica del Dominio a través de Model Serving Para abordar los matices de la atención médica y OT, los embeddings genéricos fueron insuficientes para el nivel de precisión que requerimos. Identificamos que para que el "Traductor Universal" tenga éxito, las arquitecturas RAG genéricas deben evolucionar hacia marcos específicos del dominio. Actualmente, cerramos esta brecha implementando modelos de embeddings médicos de primer nivel como puntos finales personalizados utilizando Databricks Model Serving. Sin embargo, al mirar hacia el futuro, vemos el fine-tuning de estos modelos como el siguiente paso lógico para garantizar que nuestros agentes comprendan los dialectos industriales más oscuros con precisión determinista.
2. RAG Avanzado y Extracción de Información Aprovechamos el Knowledge Assistant para construir sistemas RAG (Retrieval-Augmented Generation) robustos capaces de ingerir grandes cantidades de documentación propietaria. Al utilizar un agente de Extracción de Información, podemos analizar estructuralmente documentos propietarios no estructurados, convirtiendo texto crudo en inteligencia procesable para la Biblioteca CPS.
3. Gestión Completa del Ciclo de Vida con MLflow que sirve como la columna vertebral de nuestro ciclo de vida de desarrollo de ML, proporcionando una plataforma unificada desde la fase inicial de MVP hasta la evaluación rigurosa y el despliegue final.
- Evaluación Continua: Implementamos una estrategia integral de evaluación utilizando "LLM como Juez" junto con sesiones de etiquetado manual. Las capacidades de MLflow nos permitieron evaluar constantemente el rendimiento del modelo para prevenir la deriva conceptual.
- Observabilidad y Monitoreo: En producción, utilizamos las funciones de observabilidad de MLflow para monitorear el estado del agente en tiempo real. Esto incluye el seguimiento del uso de tokens y los costos de infraestructura, la identificación de cuellos de botella de latencia y la detección de posibles errores antes de que afecten a los usuarios. Un área de enfoque estratégico es la eficiencia de costos de nuestros índices de Búsqueda Vectorial. Si bien el rendimiento es de primera clase, la falta actual de un modelo de "escalado a cero" para los puntos finales vectoriales —un matiz particularmente relevante para la naturaleza intermitente y basada en eventos de los datos de seguridad industrial— requiere que diseñemos patrones arquitectónicos específicos para mantener un alto ROI durante los períodos de inactividad.
Al fusionar métodos clásicos de Resolución de Entidades con una estrategia sofisticada y orquestada de múltiples agentes —respaldada por la robusta infraestructura de Databricks— hemos creado una capa de inteligencia auto-mejorable, rentable y altamente precisa. Este sistema finalmente cierra la brecha entre los datos desordenados de la red y la única fuente de verdad, resolviendo la crisis de identidad para la seguridad CPS.
Automatización usando Trabajos, Pipelines y LLM
Para manejar la gran cantidad de información de varias fuentes, Claroty utiliza Trabajos de Lakeflow para orquestar todo el proceso, desde datos brutos hasta una tabla bien estructurada.
Uno de nuestros pipelines orquesta un proceso ETL que analiza CSAF, un aviso de seguridad formateado en JSON, en una estructura tabular. En este proceso, cada paso lee y escribe entradas en una tabla delta dedicada.
En este ETL, y en muchos otros casos de uso, utilizamos LLMs para enriquecer los datos, desde tareas de clasificación y Funciones de IA como ai_query, utilizando varios Puntos Finales de Servicio y MLflow para evaluar las respuestas que obtenemos del LLM, utilizando métricas estadísticas y LLM-como-juez, y monitorear el costo.
Para mantener este pipeline confiable a escala, utilizamos un enfoque de LLM como Juez para calificar continuamente la calidad de nuestras propias salidas de LLM. En lugar de depender únicamente de la verdad fundamental completamente etiquetada —que a menudo falta o es ambigua en los datos CPS del mundo real— dejamos que un modelo juez dedicado revise la respuesta de otro modelo y decida si parece aceptable. El trabajo del juez es simple y conservador: marcar cada resultado como aprobado, parece correcto, fallido, parece incorrecto o desconocido, falta información. Todos estos Jueces se almacenan en una Tabla Delta. Usando este método, nuestros equipos pueden cargar muestras de evaluación, iniciar jueces GenAI personalizados de MLflow y ejecutar evaluaciones estructuradas. Las capacidades nativas de monitoreo GenAI de MLflow nos brindan una forma consistente de monitorear la calidad, comparar versiones y detectar regresiones en muchos casos de uso de LLM, sin construir una pila de evaluación a medida para cada nuevo flujo de trabajo.
Integridad Transaccional con Lakebase
Para que la "Biblioteca" funcione, los datos deben ser consistentes y estar altamente disponibles. Claroty integra Lakebase, una capa de datos transaccional completamente administrada en Databricks. Lakebase se basa en Postgres y proporciona el rendimiento de baja latencia requerido para consultas en tiempo real, manteniendo un enlace perfecto con el Lakehouse más amplio para el procesamiento analítico, permitiendo restricciones estrictas para asegurar que nuestros datos mantengan su alta calidad y asegurando que las asignaciones de activos sigan siendo precisas incluso cuando las configuraciones cambian.
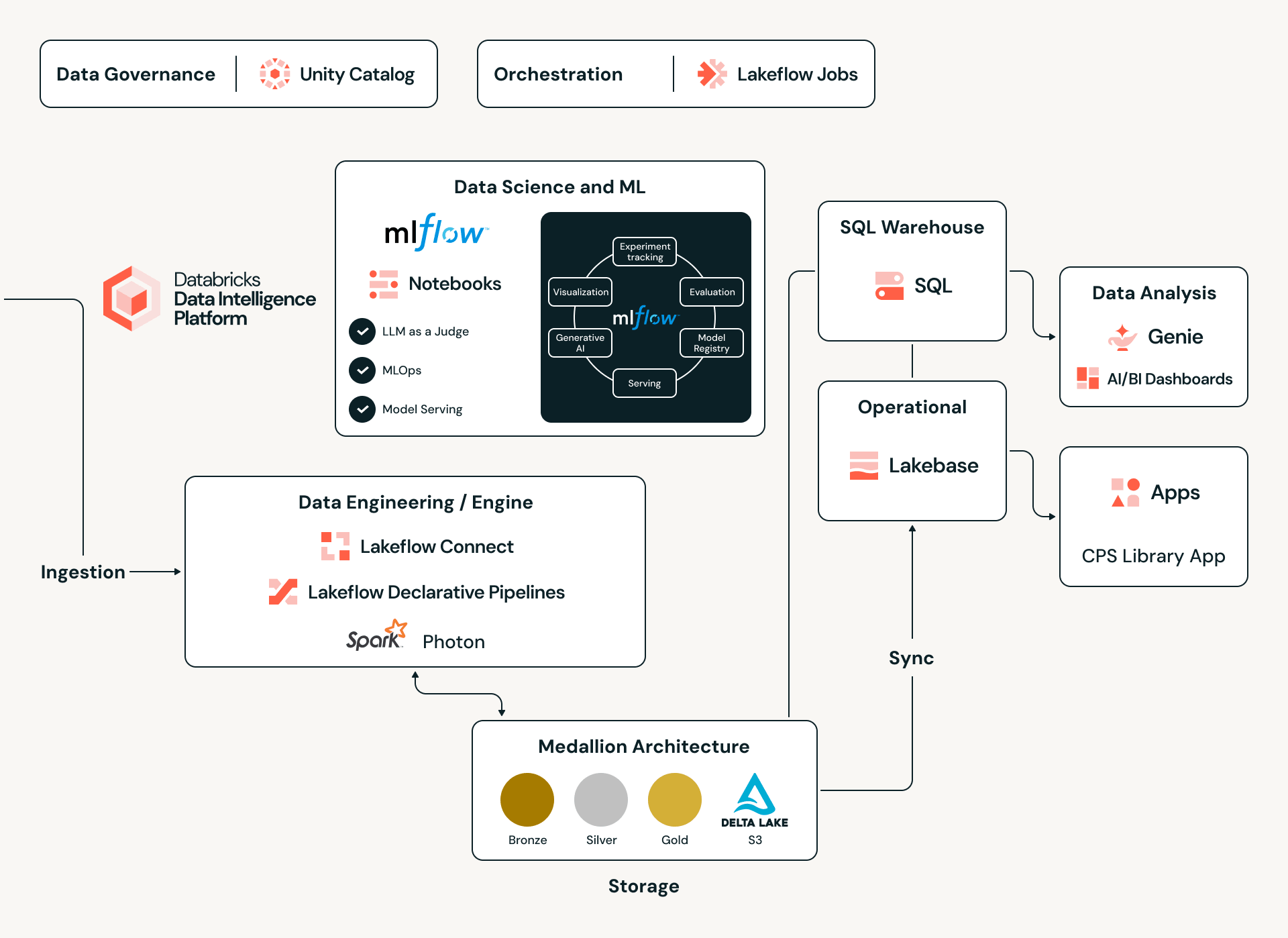
Innovación Rápida con Databricks Apps
Para reunir todas estas ideas, utilizamos Databricks Apps, una capacidad que permite a Claroty crear y desplegar aplicaciones completas intensivas en datos directamente dentro del entorno Databricks. Usando frameworks de UI modernos (como React o Streamlit) para el frontend, y Lakebase, la base de datos OLTP Postgres completamente administrada de Databricks, para cargas de trabajo transaccionales, podemos alojar tanto la lógica de la aplicación como los datos operativos en la misma plataforma que nuestro lakehouse. Esto significa que la aplicación hereda la seguridad, gobernanza y autenticación integradas de la plataforma (a través de Unity Catalog y OAuth), al tiempo que elimina la necesidad de servidores de aplicaciones, bases de datos y pipelines de despliegue separados. Lo que tradicionalmente requeriría unir múltiples pilas tecnológicas y servicios se consolida en una solución única, rentable y robusta.
Human-in-the-Loop a través de Databricks Apps
Si bien nuestros pipelines de IA automatizan el trabajo pesado, la principal necesidad en el campo para crear confianza es la retroalimentación de expertos en la materia (SME) con intervención humana. Con Databricks App y Lakebase, permitimos una vista transparente y un ciclo de retroalimentación "human-in-the-loop" sin interrupciones. Esta interfaz intuitiva permite a los expertos del dominio revisar clasificaciones, corregir y enriquecer entidades, y retroalimentar datos validados y de alta fidelidad a nuestros pipelines de MLflow y migración de I+D, asegurando que el sistema crezca más inteligente y preciso con el tiempo.
El Futuro de la Resiliencia
Al combinar la profunda experiencia de dominio de Claroty en protocolos OT con el poder de la plataforma Databricks, la Biblioteca CPS está estableciendo un nuevo estándar. Ya no se trata solo de ver que un dispositivo existe, se trata de saber exactamente qué es, qué riesgos conlleva y cómo solucionarlo con total confianza.
El liderazgo de Claroty en este espacio fue validado recientemente al ser nombrada Líder en el Cuadrante Mágico de Gartner® 2025 para Plataformas de Protección CPS, posicionada más alta en "Capacidad de Ejecución". A medida que la industria avanza, este enfoque de "primero la identidad" será la base para avanzar en la resiliencia en cada entorno conectado.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.