Escalamiento de LLM pequeños con NVIDIA MPS
Los modelos pequeños se están volviendo rápidamente más capaces y aplicables en una amplia variedad de casos de uso empresariales. Al mismo tiempo, cada nueva generación de GPU ofrece mucho más ancho de banda de cómputo y de memoria. ¿El resultado? Incluso con cargas de trabajo de alta concurrencia, los LLM pequeños suelen dejar inactiva una gran parte del ancho de banda de cómputo y de memoria de la GPU.
Con casos de uso como la finalización de código, la recuperación, la corrección gramatical o los modelos especializados, nuestros clientes empresariales ejecutan muchos de estos pequeños modelos de lenguaje en Databricks, y estamos constantemente llevando las GPU al límite. El Servicio de Múltiples Procesos (MPS) de NVIDIA parecía una herramienta prometedora: permite que múltiples procesos de inferencia compartan un único contexto de GPU, lo que hace que sus operaciones de memoria y cómputo se superpongan, aprovechando así mucho más el mismo hardware.
Nos propusimos probar rigurosamente si MPS ofrece un mayor rendimiento por GPU en nuestros entornos de producción. Descubrimos que MPS ofrece mejoras significativas en el rendimiento en estos regímenes:
- Modelos de lenguaje muy pequeños (parámetros ≤3B) con contexto de corto a mediano (tokens <2k)
- Modelos de lenguaje muy pequeños (<3B) en cargas de trabajo de solo prellenado
- Motores con una sobrecarga de CPU significativa
La explicación clave, basada en nuestras ablaciones, es doble: a nivel de GPU, MPS permite una superposición significativa de kernels cuando los motores individuales dejan subutilizado el ancho de banda de cómputo o de memoria, particularmente durante las fases donde predomina la atención en modelos pequeños; y, como un efecto secundario útil, también puede mitigar los cuellos de botella de la CPU como la sobrecarga del planificador o la sobrecarga del procesamiento de imágenes en cargas de trabajo multimodales al fragmentar el lote total entre los motores, reduciendo la carga de CPU por motor.
¿Qué es MPS?
El Servicio de Múltiples Procesos (MPS) de NVIDIA es una característica que permite que múltiples procesos compartan una única GPU de manera más eficiente al multiplexar sus kernels de CUDA en el hardware. Como lo expresa la documentación oficial de NVIDIA:
El Multi-Process Service (MPS) es una implementación alternativa y compatible a nivel binario de la interfaz de programación de aplicaciones (API) de CUDA. La arquitectura de tiempo de ejecución de MPS está diseñada para permitir de forma transparente las aplicaciones de CUDA cooperativas y multiproceso.
En términos más simples, MPS proporciona una implementación de CUDA compatible a nivel binario dentro del controlador que permite que múltiples procesos (como los motores de inferencia) compartan la GPU de manera más eficiente. En lugar de que los procesos serialicen el acceso (y dejen la GPU inactiva entre turnos), sus kernels y operaciones de memoria son multiplexados y superpuestos por el servidor de MPS cuando hay recursos disponibles.
El panorama del escalamiento: ¿cuándo ayuda el MPS?
En una configuración de hardware determinada, la utilización efectiva depende en gran medida del tamaño del modelo, la arquitectura y la longitud del contexto. Dado que los modelos de lenguaje grandes recientes tienden a converger en arquitecturas similares, utilizamos la familia de modelos Qwen2.5 como ejemplo representativo para explorar el impacto del tamaño del modelo y la longitud del contexto.
Los experimentos a continuación compararon dos motores de inferencia idénticos que se ejecutan en la misma GPU NVIDIA H100 (con MPS habilitado) con una línea de base de instancia única, utilizando cargas de trabajo homogéneas perfectamente balanceadas.
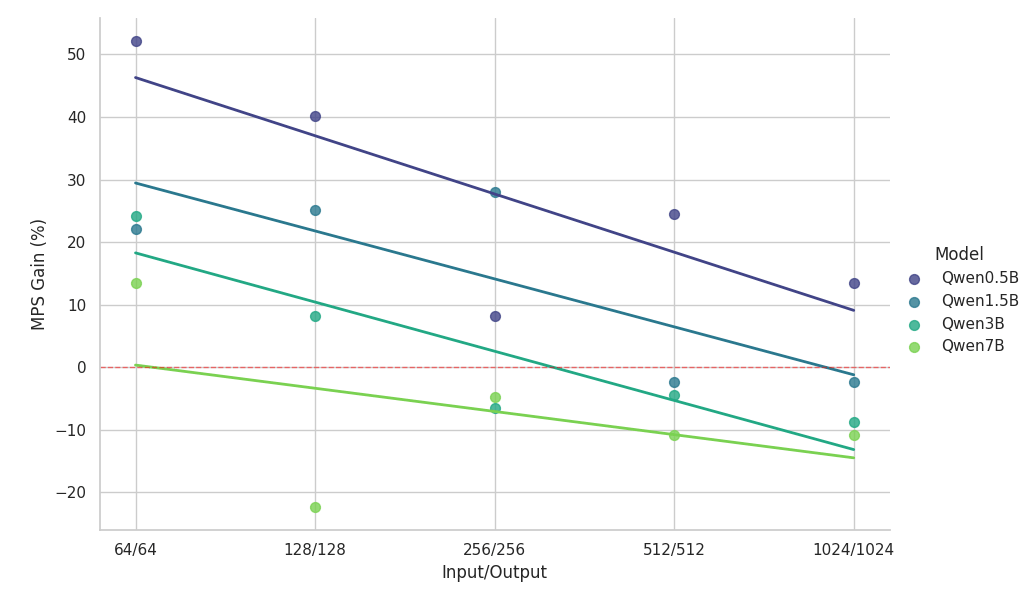
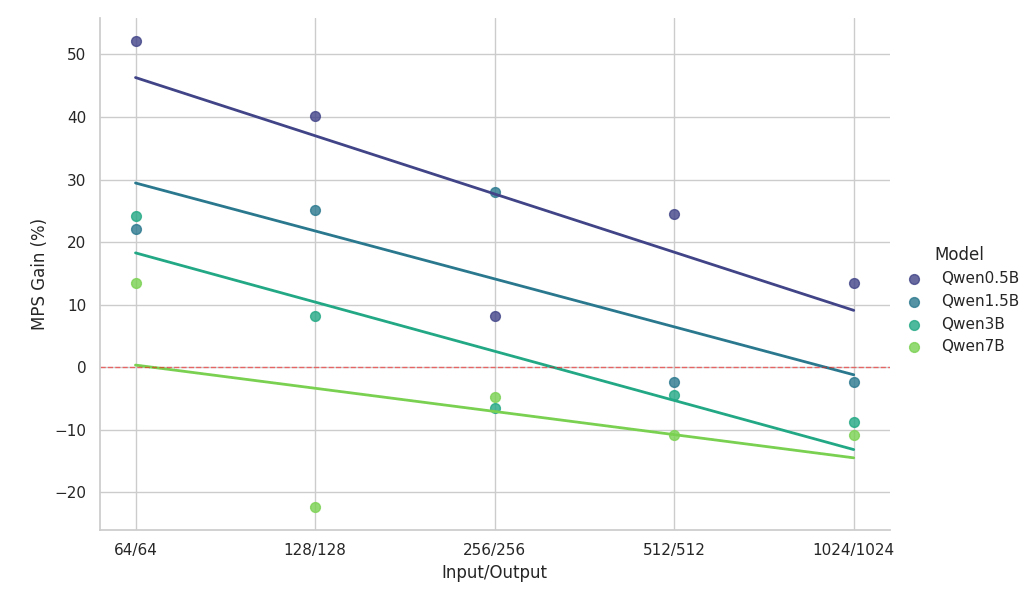{kind=link}
Observaciones clave del estudio de escalado:
- MPS ofrece un aumento del rendimiento de >50 % para modelos pequeños con contextos cortos
- Las ganancias disminuyen de forma logarítmica lineal a medida que aumenta la longitud del contexto, para el mismo tamaño de modelo.
- Las ganancias también se reducen rápidamente a medida que aumenta el tamaño del modelo, incluso en contextos cortos.
- Para el modelo de 7B o el contexto de 2k, el beneficio cae por debajo del 10 % y, con el tiempo, genera una ralentización.
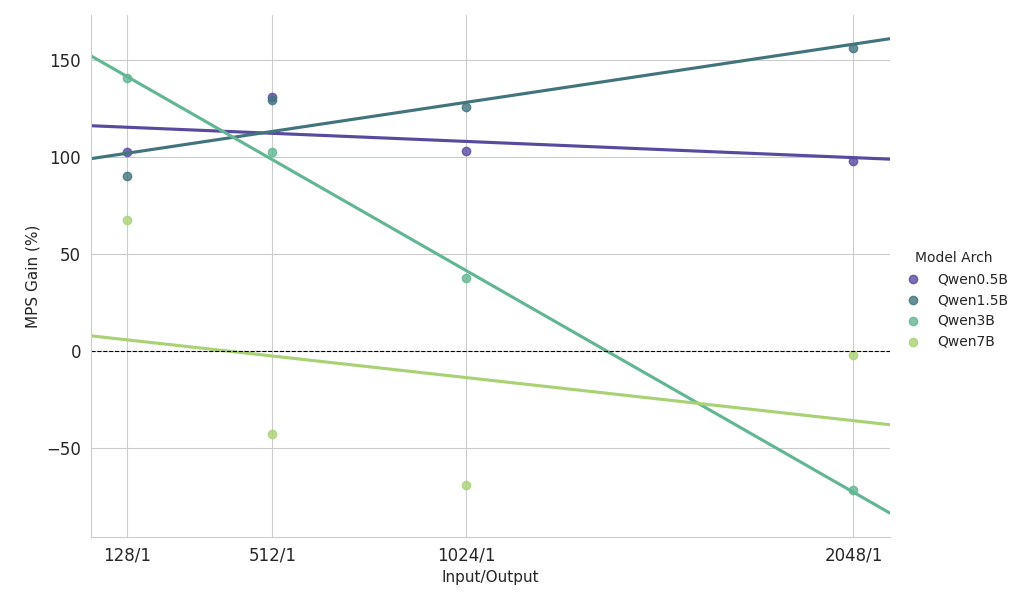
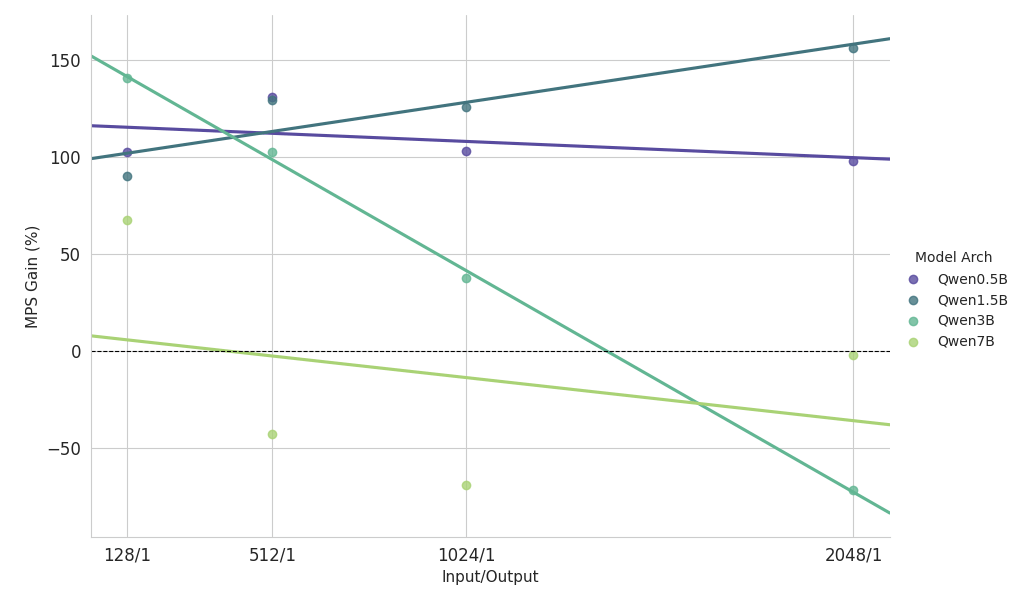{kind=link}
Observaciones clave del estudio de escalamiento sobre una carga de trabajo pesada de prellenado
- Modelos pequeños (<3B): MPS ofrece consistentemente una mejora del rendimiento de más del 100 %.
- Modelos de tamaño mediano (~3B): los beneficios disminuyen a medida que aumenta la longitud del contexto, lo que eventualmente conduce a una regresión del rendimiento.
- Modelos grandes (>3B): MPS no proporciona ningún beneficio de rendimiento para estos tamaños de modelo.
Los resultados de escalado anteriores muestran que los beneficios de MPS son más pronunciados para configuraciones con baja utilización de GPU, modelos pequeños y contextos cortos, lo que facilita una superposición efectiva.
Desglosando los beneficios: ¿de dónde provienen realmente los beneficios del MPS?
Para determinar con exactitud por qué, desglosamos el problema en los dos componentes básicos de los transformadores modernos: las capas MLP (perceptrón multicapa) y el mecanismo de Atención. Al aislar cada componente (y eliminar otros factores de confusión como la sobrecarga de la CPU), pudimos atribuir las ganancias con mayor precisión.
Recursos de GPU necesarios | |||
| N = longitud del contexto | Prellenado (Cómputo) | Decodificación (Ancho de banda de memoria) | Decodificación (Cómputo) |
| MLP | O(N) | O(1) | O(1) |
| Atención | O(N^2) | O(N) | O(N) |
Los transformadores constan de capas de atención y MLP con diferente comportamiento de escalamiento:
- MLP: Carga los pesos una vez; procesa cada token de forma independiente -> Ancho de banda de memoria y cómputo constantes por token.
- Atención: carga la caché KV y calcula el producto punto con todos los tokens anteriores → ancho de banda de memoria lineal y cómputo por token.
Teniendo esto en cuenta, realizamos ablaciones dirigidas.
Modelos de solo MLP (atención eliminada)
Para los modelos pequeños, es posible que la capa MLP no sature el cómputo, incluso con más tokens por lote. Aislamos el impacto del MLP eliminando el bloque de atención del modelo.
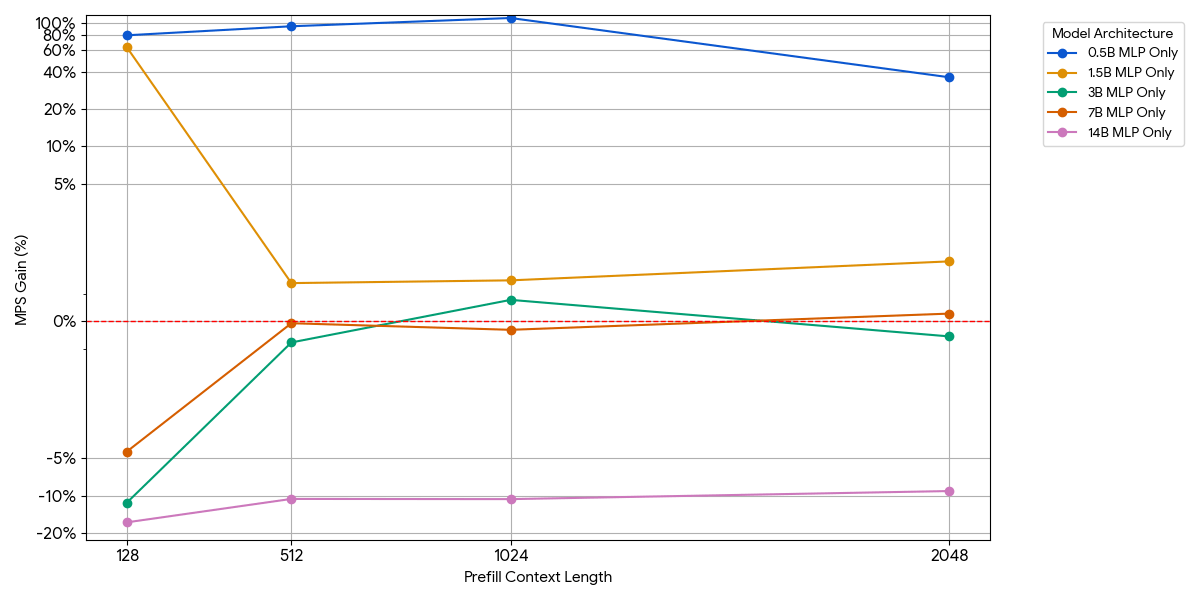
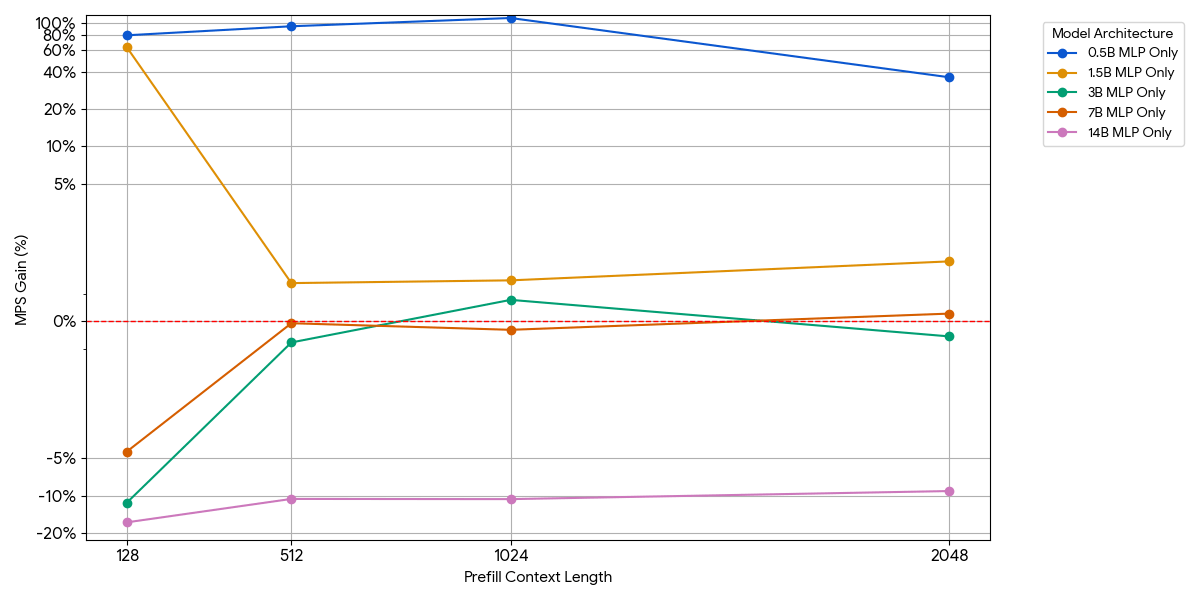{kind=link}
Como se muestra en la figura anterior, las ganancias son modestas y desaparecen rápidamente. A medida que aumenta el tamaño del modelo o la longitud del contexto, un solo motor ya satura el cómputo (más FLOPs por token en MLP más grandes, más tokens con secuencias más largas). Una vez que un motor está limitado por el cómputo, ejecutar dos motores saturados casi no ofrece ningún beneficio: 1 + 1 <= 1.
Modelos de solo atención (MLP eliminado)
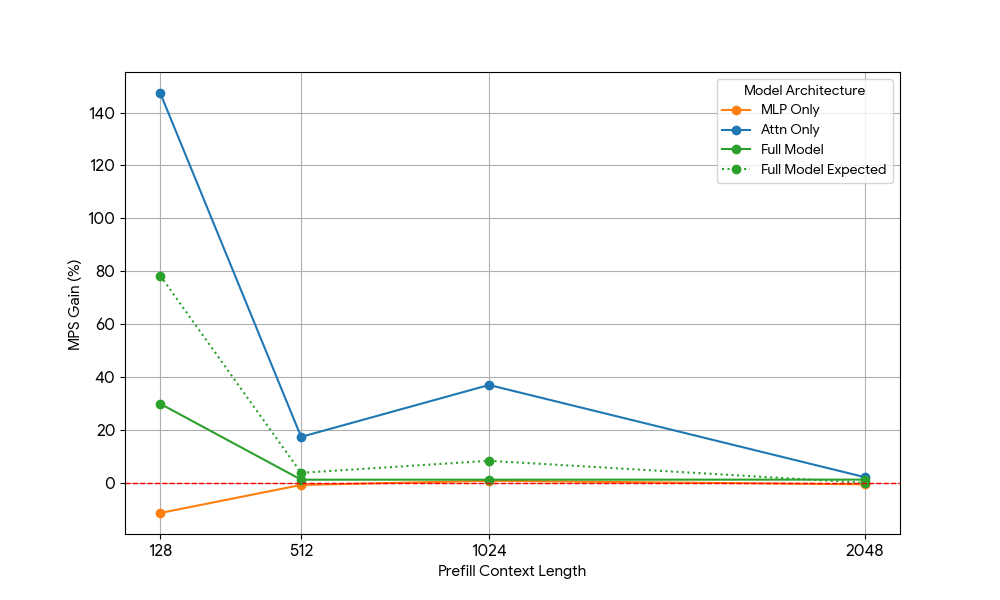
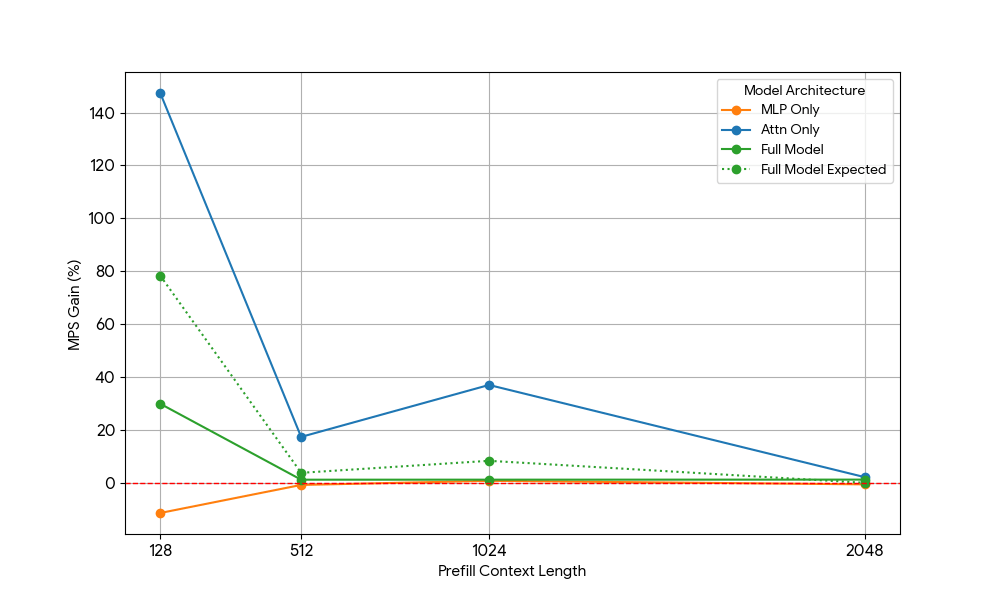
Después de ver ganancias limitadas del MLP, tomamos Qwen2.5-3B y medimos de forma análoga la configuración de solo atención.
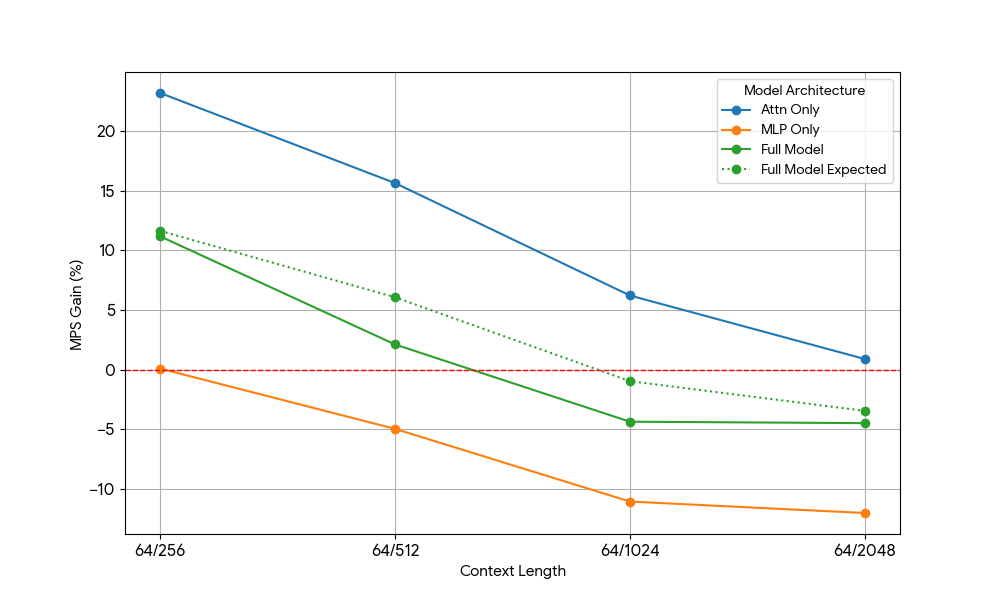
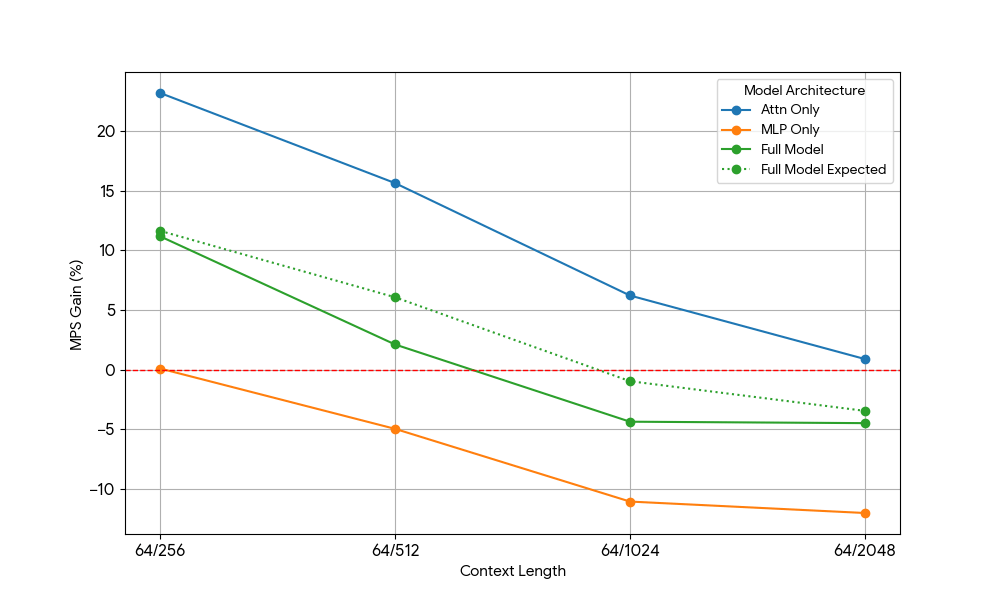{kind=link}
{kind=link}
El resultado fue sorprendente:
- Las cargas de trabajo de solo atención muestran ganancias de MPS significativamente mayores que las del modelo completo, tanto para el prellenado como para la decodificación.
- Para la decodificación, las ganancias disminuyen linealmente con la longitud del contexto, lo que se alinea con nuestra expectativa de que en la etapa de decodificación los requisitos de recursos para la atención crecen con la longitud del contexto.
- Para el prellenado, las ganancias disminuyeron más rápidamente que para la decodificación.
¿La ganancia de MPS proviene únicamente de las ganancias de atención o existe algún efecto de superposición entre Atención y MLP? Para estudiar esto, calculamos la Ganancia Esperada del Modelo Completo como un promedio ponderado de solo Atención y solo MLP, donde las ponderaciones son su contribución al tiempo de reloj (wall time). Esta Ganancia Esperada del Modelo Completo es básicamente la ganancia que proviene exclusivamente de las superposiciones Atención-Atención y MLP-MLP, mientras que no tiene en cuenta la superposición Atención-MLP.
Para la carga de trabajo de decodificación, la ganancia esperada del modelo completo es ligeramente superior a la ganancia real, lo que indica un impacto limitado de la superposición de Attn-MLP. Además, para la carga de trabajo de prellenado, la ganancia real del modelo completo es mucho menor que las ganancias esperadas de seq 128. Una explicación hipotética podría ser que hay menos oportunidades de que el kernel de Atención no saturado se superponga porque el otro motor pasa una fracción significativa de tiempo realizando un MLP saturado. Por lo tanto, la mayor parte de la ganancia de MPS proviene de 2 motores con la atención no saturada.
Beneficio adicional: Recuperación del tiempo de GPU perdido por la sobrecarga de la CPU
Los estudios de ablación anteriores se centraron en las cargas de trabajo ligadas a la GPU, pero la forma más grave de subutilización ocurre cuando la GPU permanece inactiva esperando el trabajo de la CPU, como el planificador, la tokenización o el preprocesamiento de imágenes en modelos multimodales.
En una configuración de un solo motor, estos bloqueos de la CPU desperdician directamente los ciclos de la GPU. Con MPS, un segundo motor puede tomar el control de la GPU cada vez que el primero se bloquea en la CPU, convirtiendo el tiempo muerto en cómputo productivo.
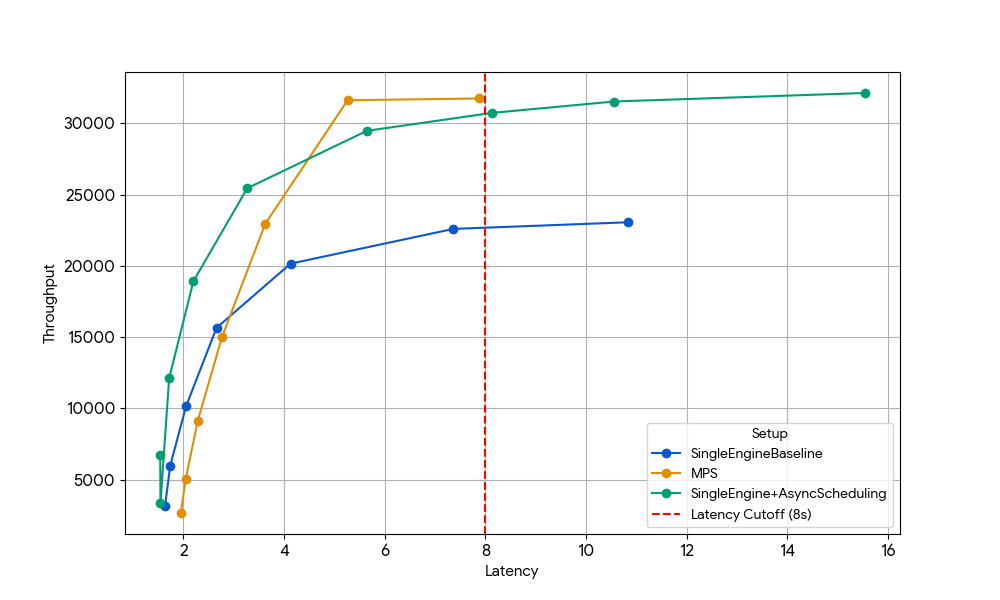
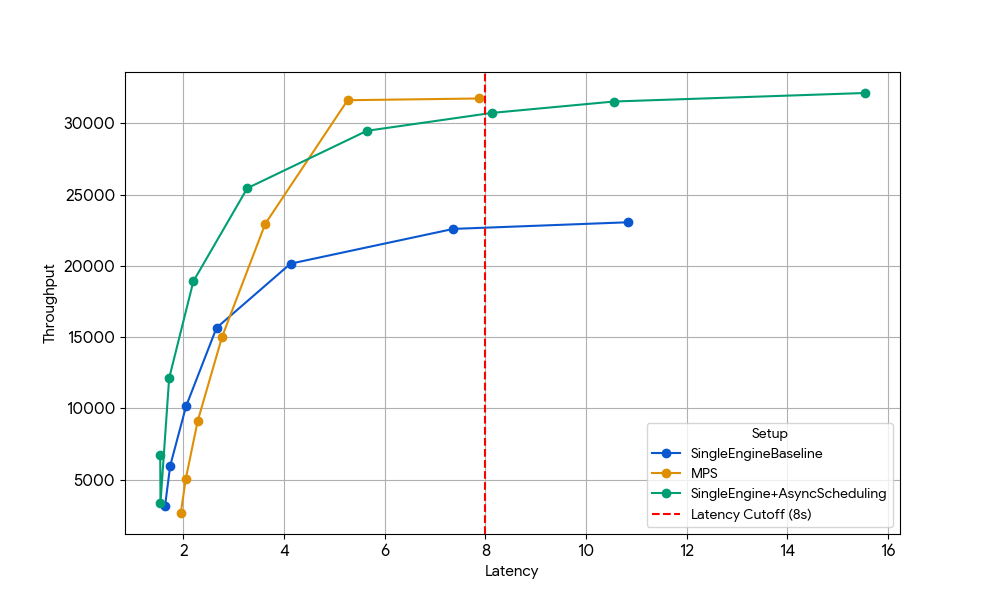
Para aislar este efecto, elegimos deliberadamente un régimen en el que las ganancias anteriores a nivel de GPU habían desaparecido: Gemma-4B (un tamaño y una longitud de contexto en los que la atención y el MLP ya están bien saturados, por lo que los beneficios de la superposición de kernels son mínimos).
{kind=link}
Con una latencia de 8 s, el motor único de referencia (azul) está limitado por la sobrecarga de la CPU del planificador, que se puede solucionar habilitando la programación asincrónica en vLLM (línea verde, +33 % de rendimiento) o ejecutando dos motores con MPS sin programación asincrónica (línea amarilla, +35 % de rendimiento). Esta ganancia casi idéntica confirma que, en escenarios con limitaciones de CPU, MPS puede recuperar esencialmente el mismo tiempo de inactividad de la GPU que elimina la programación asincrónica. MPS puede ser útil, ya que la versión básica de vLLM v1.0 todavía tiene sobrecarga de CPU en la capa del planificador, donde las optimizaciones como la programación asincrónica no están completamente disponibles.
Una bala, no una bala de plata
Según nuestros experimentos, MPS puede generar ganancias significativas para la inferencia de modelos pequeños en algunas zonas operativas:
- Motores con una sobrecarga de CPU significativa
- Modelos de lenguaje muy pequeños (parámetros ≤3B) con contexto de corto a mediano (tokens <2k)
- Modelos de lenguaje muy pequeños (<3B) en cargas de trabajo con mucho prellenado (prefill-heavy)
Fuera de esos puntos óptimos (p. ej., modelos 7B+, contexto largo >8k o cargas de trabajo ya limitadas por el cómputo), los beneficios a nivel de GPU no pueden ser capturados fácilmente por MPS.
Por otro lado, MPS también introdujo complejidad operativa:
- Componentes adicionales: demonio MPS, configuración del entorno del cliente y un enrutador/balanceador de carga para dividir el tráfico entre los motores.
- Mayor complejidad de depuración: no hay aislamiento entre los motores → una fuga de memoria o un error de memoria insuficiente (OOM) en un motor puede corromper o terminar todos los demás que comparten la GPU
- Carga de monitoreo: ahora tenemos que vigilar el estado del daemon, el estado de la conexión del cliente, el balance de carga entre motores, etc.
- Modos de falla frágiles: debido a que todos los motores comparten un único contexto CUDA y el demonio MPS, un único cliente que se comporta mal puede corromper o dejar sin recursos a toda la GPU, lo que afecta instantáneamente a todos los motores coubicados.
En resumen: MPS es una herramienta precisa y especializada, extremadamente eficaz en los regímenes específicos descritos anteriormente, pero que rara vez representa una solución de propósito general. Realmente disfrutamos llevando al límite el uso compartido de la GPU y descubriendo dónde están los verdaderos abismos de rendimiento. Todavía hay una enorme cantidad de rendimiento y rentabilidad sin explotar en toda la pila de inferencia. Si te entusiasman los sistemas de servicio distribuidos o hacer que los LLM se ejecuten 10 veces más baratos en producción, ¡estamos contratando!
Autores: Xiaotong Jiang
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.