Simplifica la ingesta de datos con la nueva API de origen de datos de Python
por Craig Lukasik y Allison Wang
Este blog explora cómo la nueva API de Origen de Datos de Python de Spark agiliza la ingesta de datos de IoT.
Los equipos de ingeniería de datos a menudo se encargan de crear soluciones de ingesta personalizadas para una gran variedad de fuentes de datos personalizadas, propietarias o específicas de la industria. Muchos equipos encuentran que este trabajo de crear soluciones de ingesta es engorroso y consume mucho tiempo. Reconociendo estos desafíos, hemos entrevistado a numerosas empresas de diferentes industrias para comprender mejor sus diversas necesidades de integración de datos. Esta retroalimentación integral nos llevó al desarrollo de la API de Origen de Datos de Python para Apache Spark™.
Uno de los clientes con los que hemos trabajado estrechamente es Shell. Las fallas de equipos en el sector energético pueden tener consecuencias significativas, afectando la seguridad, el medio ambiente y la estabilidad operativa. En Shell, minimizar estos riesgos es una prioridad, y una forma en que lo hacen es centrándose en la operación confiable de los equipos.
Shell posee una gran cantidad de activos de capital y equipos valorados en más de $180 mil millones. Para gestionar las enormes cantidades de datos que generan las operaciones de Shell, confían en herramientas avanzadas que mejoran la productividad y permiten a sus equipos de datos trabajar sin problemas en diversas iniciativas. La Plataforma de Inteligencia de Datos de Databricks desempeña un papel crucial al democratizar el acceso a los datos y fomentar la colaboración entre los analistas, ingenieros y científicos de Shell. Sin embargo, la integración de datos de IoT planteó desafíos para algunos casos de uso.
Usando nuestro trabajo con Shell como ejemplo, este blog explorará cómo esta nueva API aborda los desafíos anteriores y proporcionará código de ejemplo para ilustrar su aplicación.
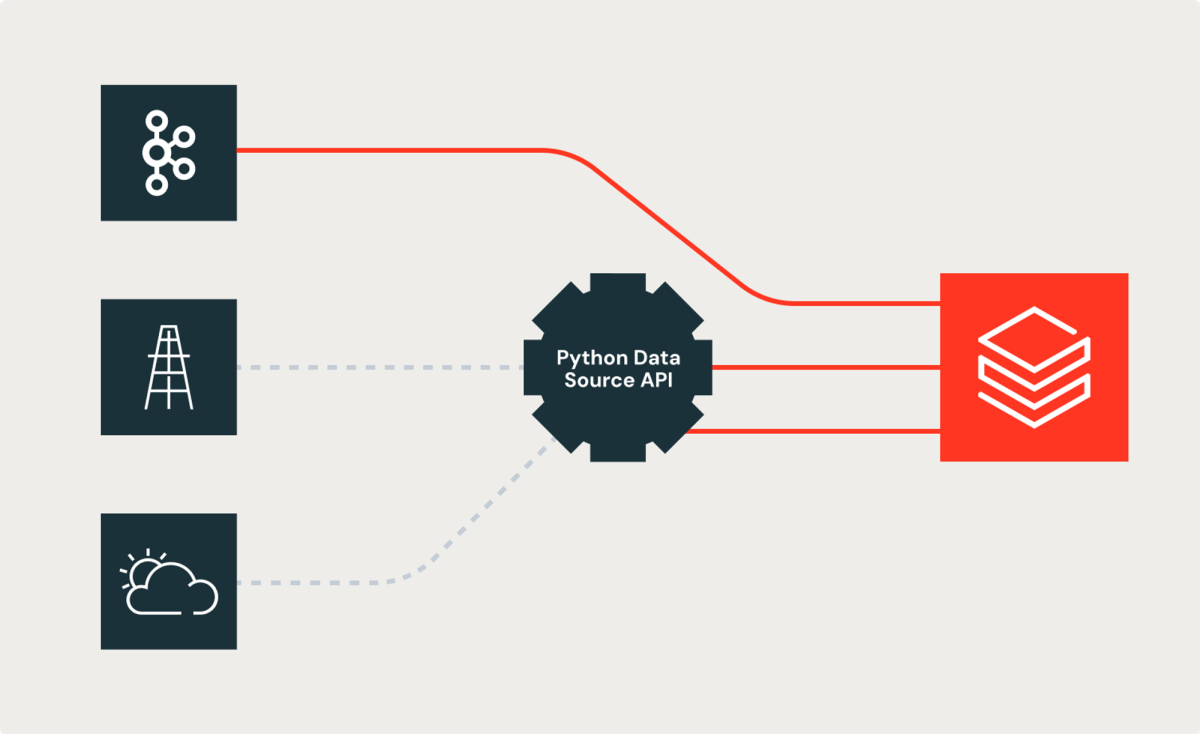
El desafío
Primero, veamos el desafío que experimentaron los ingenieros de datos de Shell. Aunque muchas fuentes de datos en sus canalizaciones de datos utilizan fuentes integradas de Spark (por ejemplo, Kafka), algunas dependen de API REST, SDK u otros mecanismos para exponer datos a los consumidores. Los ingenieros de datos de Shell lucharon con este hecho. Terminaron con soluciones personalizadas para unir datos de fuentes integradas de Spark con datos de estas fuentes. Este desafío consumió el tiempo y la energía de los ingenieros de datos. Como se ve a menudo en organizaciones grandes, tales implementaciones personalizadas introducen inconsistencias en las implementaciones y los resultados. Bryce Bartmann, Asesor Principal de Tecnología Digital de Shell, quería simplicidad y nos dijo: “Escribimos muchas API REST interesantes, incluso para casos de uso de streaming, y nos encantaría usarlas como una fuente de datos en Databricks en lugar de escribir todo el código de conexión nosotros mismos”.
“Escribimos muchas API REST interesantes, incluso para casos de uso de streaming, y nos encantaría usarlas como una fuente de datos en Databricks en lugar de escribir todo el código de conexión nosotros mismos”. - Bryce Bartmann, Asesor Principal de Tecnología Digital, Shell
La solución
La nueva API de origen de datos personalizado de Python alivia el problema al permitir que el problema se aborde utilizando conceptos de programación orientada a objetos. La nueva API proporciona clases abstractas que permiten que el código personalizado, como las búsquedas basadas en API REST, se encapsule y se exponga como otra fuente o destino de Spark.
Los ingenieros de datos quieren simplicidad y composabilidad. Por ejemplo, imagina que eres un ingeniero de datos y quieres ingerir datos meteorológicos en tu canalización de streaming. Idealmente, te gustaría escribir código que se vea así:
Ese código se ve simple y es fácil de usar para los ingenieros de datos porque ya están familiarizados con la API de DataFrame. Anteriormente, un enfoque común para acceder a una API REST en un trabajo de Spark era usar un PandasUDF. Este artículo muestra lo complicado que puede ser escribir código reutilizable capaz de enviar datos a una API REST usando un Pandas UDF. La nueva API, por otro lado, simplifica y estandariza cómo los trabajos de Spark, ya sea de streaming o por lotes, de destino o de origen, funcionan con fuentes y destinos no nativos.
A continuación, examinemos un ejemplo del mundo real y mostremos cómo la nueva API nos permite crear una nueva fuente de datos ("weather" en este ejemplo). La nueva API proporciona capacidades para fuentes, destinos, lotes y streaming, y el ejemplo a continuación se centra en el uso de la nueva API de streaming para implementar una nueva fuente "weather".
Usando la API de Origen de Datos de Python: un escenario del mundo real
Imagina que eres un ingeniero de datos encargado de crear una canalización de datos para un caso de uso de mantenimiento predictivo que requiere datos de presión de equipos en la cabeza del pozo. Supongamos que las métricas de temperatura y presión de la cabeza del pozo fluyen a través de Kafka desde los sensores de IoT. Sabemos que Structured Streaming tiene soporte nativo para procesar datos de Kafka. Hasta aquí, todo bien. Sin embargo, los requisitos comerciales presentan un desafío: la misma canalización de datos debe capturar los datos meteorológicos relacionados con el sitio de la cabeza del pozo, y estos datos resulta que no fluyen a través de Kafka, sino que son accesibles a través de una API REST. Los partes interesadas del negocio y los científicos de datos saben que el clima afecta la vida útil y la eficiencia de los equipos, y esos factores impactan los cronogramas de mantenimiento de los equipos.
Empezar de forma sencilla
La nueva API proporciona una opción sencilla adecuada para muchos casos de uso: la API SimpleDataSourceStreamReader. La API SimpleDataSourceStreamReader es apropiada cuando la fuente de datos tiene un bajo rendimiento y no requiere particionamiento. La usaremos en este ejemplo porque solo necesitamos lecturas de datos meteorológicos para un número limitado de sitios de cabeza de pozo, y la frecuencia de las lecturas meteorológicas es baja.
Veamos un ejemplo sencillo que utiliza la API SimpleDataSourceStreamReader.
Explicaremos un enfoque más complicado más adelante. El otro enfoque, más complejo, es ideal al crear un Origen de Datos de Python consciente de las particiones. Por ahora, no nos preocuparemos por lo que eso significa. En cambio, mostraremos un ejemplo que utiliza la API simple.
Ejemplo de código
El siguiente ejemplo de código asume que la API "simple" es suficiente. El método __init__ es esencial porque así es como la clase lectora (WeatherSimpleStreamReader a continuación) comprende los sitios del pozo que necesitamos monitorear. La clase utiliza una opción "locations" para identificar las ubicaciones para emitir información meteorológica.
Ahora que hemos definido la clase lectora simple, necesitamos integrarla en una implementación de la clase abstracta DataSource.
Ahora que hemos definido el DataSource y hemos integrado una implementación del lector de streaming, necesitamos registrar el DataSource en la sesión de Spark.
Eso significa que la fuente de datos meteorológicos es una nueva fuente de streaming con las operaciones de DataFrame familiares con las que los ingenieros de datos están familiarizados. Este punto vale la pena enfatizarlo porque estas fuentes de datos personalizadas benefician a todo el equipo. Con un enfoque más orientado a objetos, el equipo en general debería beneficiarse de esta fuente de datos si necesitan datos meteorológicos como parte de su caso de uso. Por lo tanto, los ingenieros de datos pueden querer extraer las fuentes de datos personalizadas en una biblioteca de ruedas de Python para reutilizarlas en otras canalizaciones.
A continuación, vemos lo fácil que es para el ingeniero de datos aprovechar el stream personalizado.
Resultados de ejemplo:
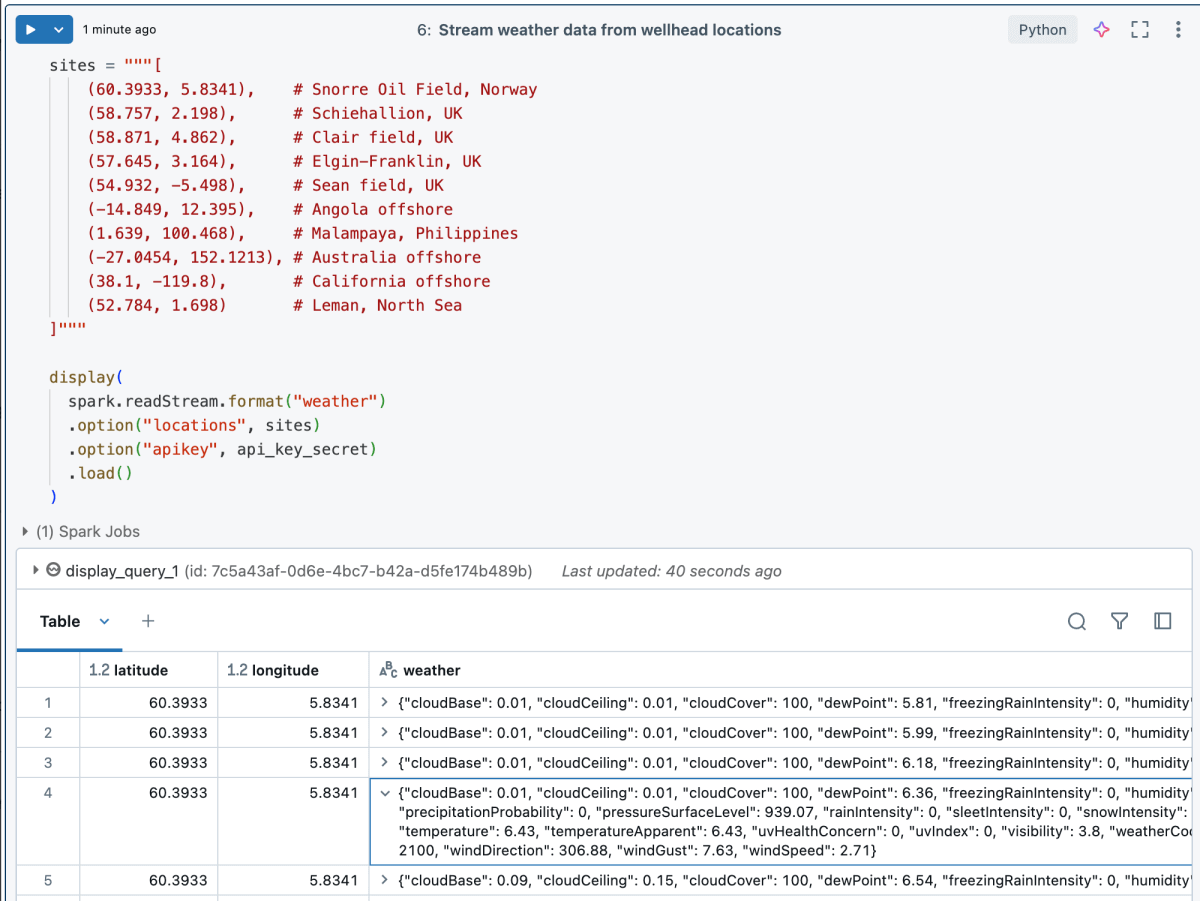
Otras consideraciones
Cuándo usar la API consciente de particiones
Ahora que hemos recorrido la API "simple" del Data Source de Python, explicaremos una opción para la conciencia de particiones. Las fuentes de datos conscientes de particiones le permiten paralelizar la generación de datos. En nuestro ejemplo, una implementación de fuente de datos consciente de particiones daría como resultado que las tareas del trabajador dividan las ubicaciones entre múltiples tareas para que las llamadas a la API REST puedan distribuirse entre los trabajadores y el clúster. Nuevamente, nuestro ejemplo no incluye esta sofisticación porque el volumen de datos esperado es bajo.
APIs de Batch vs. Stream
Dependiendo del caso de uso y de si necesita que la API genere el stream de origen o envíe los datos, debe centrarse en implementar diferentes métodos. En nuestro ejemplo, no nos preocupamos por enviar datos. También deberíamos haber incluido la implementación del lector de batch. Sin embargo, puede centrarse en implementar las clases necesarias en su caso de uso específico.
| fuente | destino | |
|---|---|---|
| batch | reader() | writer() |
| streaming | streamReader() o simpleStreamReader() | streamWriter() |
Cuándo usar las APIs de Escritura
Este artículo se ha centrado en las APIs de Lectura utilizadas en readStream. Las APIs de Escritura permiten una lógica arbitraria similar en el lado de salida de la canalización de datos. Por ejemplo, supongamos que los gerentes de operaciones en el cabezal del pozo quieren que la canalización de datos llame a una API en el sitio del cabezal del pozo que muestre un estado de equipo rojo/amarillo/verde que aproveche la lógica de la canalización. La API de Escritura permitiría a los ingenieros de datos la misma oportunidad de encapsular la lógica y exponer un destino de datos que operaría como los formatos familiares de writeStream.
Conclusión
"La simplicidad es la máxima sofisticación." - Leonardo da Vinci
Como arquitectos e ingenieros de datos, ahora tenemos la oportunidad de simplificar cargas de trabajo de batch y streaming utilizando la API de fuente de datos personalizada de PySpark. A medida que encuentre oportunidades para nuevas fuentes de datos que beneficien a sus equipos de datos, considere separar las fuentes de datos para su reutilización en toda la empresa, por ejemplo, mediante el uso de una rueda de Python.
La API de Fuente de Datos de Python es exactamente lo que necesitábamos. Brinda una oportunidad para que nuestros ingenieros de datos modularicen el código necesario para interactuar con nuestras APIs REST y SDKs. El hecho de que ahora podamos construir, probar y exponer fuentes de datos Spark reutilizables en toda la organización ayudará a nuestros equipos a avanzar más rápido y tener más confianza en su trabajo." - Bryce Bartmann, Asesor Principal de Tecnología Digital, Shell
En conclusión, la API de fuentes de datos de Python para Apache Spark™ es una adición potente que aborda desafíos significativos que antes enfrentaban los ingenieros de datos al trabajar con fuentes y destinos de datos complejos, particularmente en contextos de streaming. Ya sea que utilicen la API "simple" o la consciente de particiones, los ingenieros ahora tienen las herramientas para integrar una gama más amplia de fuentes y destinos de datos en sus pipelines de Spark de manera eficiente. Como demostraron nuestro análisis y el código de ejemplo, implementar y usar esta API es sencillo, lo que permite obtener resultados rápidos para el mantenimiento predictivo y otros casos de uso. La documentación de Databricks (y la documentación de código abierto) explican la API con más detalle, y varios ejemplos de fuentes de datos de Python se pueden encontrar aquí.
Finalmente, no se puede subestimar el énfasis en la creación de fuentes de datos personalizadas como componentes modulares y reutilizables. Al abstraer estas fuentes de datos en bibliotecas independientes, los equipos pueden fomentar una cultura de reutilización de código y colaboración, mejorando aún más la productividad y la innovación. A medida que continuamos explorando y superando los límites de lo que es posible con big data e IoT, tecnologías como la API de fuentes de datos de Python desempeñarán un papel fundamental en la configuración del futuro de la toma de decisiones basada en datos en el sector energético y más allá.
Si ya eres cliente de Databricks, toma y modifica uno de estos ejemplos para desbloquear tus datos que se encuentran detrás de una API REST. Si aún no eres cliente de Databricks, empieza gratis y prueba uno de los ejemplos hoy mismo.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.